藏文句子语义块识别方法
2019-08-05色差甲才让加
柔 特, 色差甲, 才让加
(1. 青海师范大学 计算机学院,青海 西宁 810016;2. 青海师范大学 青海省藏文信息处理与机器翻译重点实验室, 青海 西宁 810008)
0 引言
语言不但是人与人之间的沟通工具,而且已成为人与机器交互的手段之一。机器理解语言文字已成为自然语言处理研究的一项重要任务。人类运用语言主要是为了表达“意思”,表达“意思”的最基本单位是句子,句子组成段落,段落组成文章。人与机器交流的最基本单位也是句子。机器理解语义的方法目前有以下三种。
一是利用传统词法分析和句法分析对语义进行分析,也就是把句子分割为词、短语(组块)等不同的颗粒度来解析语义。在词法分析层面上主要应用隐马尔可夫(Hidden Markov Model,HMM)[1]、条件随机场(Conditional Random Fields,CRF)[2]、支持向量机(Support Vector Machine,SVM)[3]、朴素贝叶斯(Naive Bayes)[4]等模型和算法。在句法分析层面上采用了ME[5]、CYK、Earley、Chart[6]等模型和算法,这些研究都依赖于人工提取各种特征,在句子结构和句子成分分析等方面较为有效,但从机器理解词义、句义等角度分析相关度较差且联系不紧密。
二是通过构建各类语义词典对语义进行分析,目前较为成熟的成果有WordNet、 HowNet、CCD、同义词词林等[7-12],这些成果对知识的描述较为准确,但需要耗费很大的成本,且语义覆盖面较小,在实际语义分析应用层面存在着较多困难。
三是利用深度学习方法和理论对语义进行分析,通常把词语表示成向量形式,将词向量作为深度学习模型的特征输入,模型的效果很大程度上取决于词向量的效果[13]。卷积神经网络 (Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Networks,RNN)方法[14]等在机器理解句义方面表现优异,已成为目前语义分析最有效的方法。

本文从藏文自身的语言特性出发,提出了介于词义之上句义之下的一个语义单元,将藏文句子分割为几个或多个块,每个块隐含语法、语义、语用等关联信息,语义块识别是本文的主要研究内容。通过语义块的分割,可降低句义分析的复杂度,使整句先分解后分析,最终得到完整的句义。本方法可弥补以语法为中心的句义研究的不足,在词义消歧、语义角色标注、语义信息损失、降低长句句义分析复杂度等方面具有良好的应用前景。
1 藏文语义块定义
人与人交流时无需先分析语法,后理解语义,人们使用语言的流利度很大程度上取决于记忆库中存储语块的多少,语块在形义关系上比较固定,它整体存储在大脑记忆库中,使用时直接提取[29],语块的积累可以减轻人类大脑对语言处理的负担,节约时间和精力[30],从而满足即时交际的需要,使语言从加工到提取再到使用更加迅速、准确、流利和地道。
机器理解语义是研究自然语言处理的最终目的,目前尚无成熟的技术使机器直接理解句义,人们将“分治”的思想应用到了自然语言处理上,在语法层面上主流的方法是通过词法、短语(组块)、句法等分析手段分析句义。在语义层面上目前分为词义和句义分析,语义块是一个介于词义和句义之间的语义单元。该方法与传统以语法为中心的研究思路不同,可以降低对语法信息的依赖,并可以替代藏文词义消歧、语义角色标注等工作,还在语义分析方面提出了一种新的方法。
1.1 语义块定义
语义块是指将一个句子分割为若干个相对独立的语义单元,长度基于词义之上句义之下;是一种语法、语义、语用关联的预处理手段。各语义块之间非递归、非嵌套、不重叠。它是藏语自然语言理解中浅层句义分析的一个缓冲,也是把整句先分解后分析的一种方法。
1.2 语义块的特点
组块是针对句法分析,语义块是针对句义分析,两者方法不同但都服务于机器理解。我们接受了传统语言学家的研究方法,在自然语言处理方法上以语法为中心的研究已成为主流。其中,短语(组块)分析是浅层句法分析的代表,在英语、汉语、藏语等不同语言的研究中,将注意力集中于组块分析对句法和句义分析的作用。
根据Abney对组块的定义,它是一种语法结构,是符合一定语法功能的非递归短语。每个组块都有一个中心词,组块内的所有成分都围绕该中心词展开,任何一种类型的组块内部不包含其他类型的组块[31]。汉语组块也借鉴了英文的研究方法[32-33]。其中,汉语中比较常见的组块类别有NP、VP、ADJP、ADVP 和MP等,在汉语组块研究中认为序列问题很关键,但虚词和助动词等没有实际意义,所以不在研究目标之内[34]。
组块分析是以语法为中心的浅层句法分析方法,不强调语义和功能,通过组块可简化句子结构,降低句法分析的难度,为完全句法分析提供基础。组块不能覆盖整个句子成分,有些句子成分不属于任何组块,例如,助词和虚词等不属于任何一个组块。
语义块是以语义为中心的浅层句义分析方法,通过词义之上句义之下的一个语义单元来缩短句义长度,注重强调语义和功能,可以降低句义分析难度,为完全句义分析提供基础。语义块覆盖整个句子,尤其藏文虚词不能成为独立的语义块而是属于某个语义块的成分。

语义块识别的任务是在不需要深层次语言知识的前提下,通过藏文格助词和语义颗粒度大小简化句义,降低藏文句义分析难度,为完整的句义分析提供基础。语义块分割符合传统句法树分析规律、语义角色标注也可相互转换。同时融合了语法、语义、语用为一体化的语义分析方法。
2 藏文句子语义切分方法
目前机器直接理解句义的方法很少,虽然有一些利用句向量理解句义的方法,但藏文实际效果不理想。藏文句子语义分割包括句子预处理、块标注、语义块识别等三个步骤,如图1所示。其中,语义块识别工作等同于藏文句子语义分割的过程。

图1 句子语义分割方法
2.1 句子预处理工作
2.1.1 藏文分词

2.1.2 识别藏文虚词
藏文句义表达的核心是虚词,虚词限定每个语义块之间的语义功能和关系,所以藏文句子中虚词的功能不可忽略。可通过虚词对相对语义独立的语义块的长度进行界定,无虚词的藏文句子,可通过组块和助动词等功能来界定语义块的长度。
2.2 块标注方法
藏文语义块标注与词性标注的方式相似,但标注的依据需要遵守藏文构词法和藏文文法的虚词匹配规律。一般使用类型数量为4,采用BMES标注方法。
BMES标注方法说明;B: 块开始;M: 块中间;E: 块结束;S: 独立成块。

2.3 语义块识别方法
预处理和标注是语义块识别的前提条件,根据句子的分词和标注结果分析后重新组合后生成一个新的块,就是语义块的识别过程。
2.3.1 标注方向
句子结构不一样,语义块的标注方法也不同,有正向语义标注、反向标注和双向标注三种不同的标注方法。本文主要针对藏文的简单句,句型结构上包括“主语+表语+连系动词”“主语+谓语”“主语+宾语+谓语”“主语+双宾语+谓语”“主语+宾语+宾补+谓语”等五种句型。
2.3.2 重组

预处理、块标注和重组是藏文句子语义分割的基本步骤,也是语义块识别的工作过程。是否能准确地识别语义块,是藏文句义分析和机器理解中一个不可忽视的基础性研究工作。
3 藏文句子语义块自动识别方法
本节介绍将以上工作交给机器,及机器如何识别语义块的过程。分词是短语结构分析、组块分析、句法结构分析、句义分析等藏文信息处理研究的核心技术。藏文句义分割过程类似于藏文分词,按不同句子结构对句子中的语义进行分割。本文主要应用BiLSTM+CRF和ID-CNN+CRF模型对藏文句义进行分割,并需要识别藏文语义块。
3.1 藏文句子语义块识别模型
序列标注问题在浅层机器学习任务中是一个比较成熟的技术,随着深度学习在自然语言处理中的广泛应用,目前主流的序列标注学习框架是双向长短时记忆循环神经网络(Bidirectional Long Short-Term Memory ,Bi-LSTM)模型和空洞卷积神经网络(Iterated Dilated CNN,ID-CNN)模型。本文利用这两个模型对藏文语义块进行识别,并对比两个模型的优势。
3.1.1 双向长短时记忆循环神经网络(Bi-LSTM)模型
目前序列块识别或者标注算法上表现最好的是Bi-LSTM算法[35-39],本文选择该模型对藏文句子按顺序读取(从句首的第一个词开始,从左往右递归)和逆序读取(从句尾的第一个词开始,从右往左递归)得到两套不同的隐层表示,然后通过向量拼接得到最终的表示。图2是一个双向LSTM+CRF层的模型,在LSTM输出层后再增加CRF层,加强了文本间信息的相关性,针对序列标注问题,每个句子中的每个词都有一个标注结果,对句子中第i个词进行高维特征抽取,通过特征学习到结果标注的映射,得到特征到任意标签的概率,利用这些概率,可得到一个最优序列结果,这个结果就是藏文句子分割后块与块之间重新组合生成语义块的过程,也可以认为是语义块识别的过程,如图2所示。
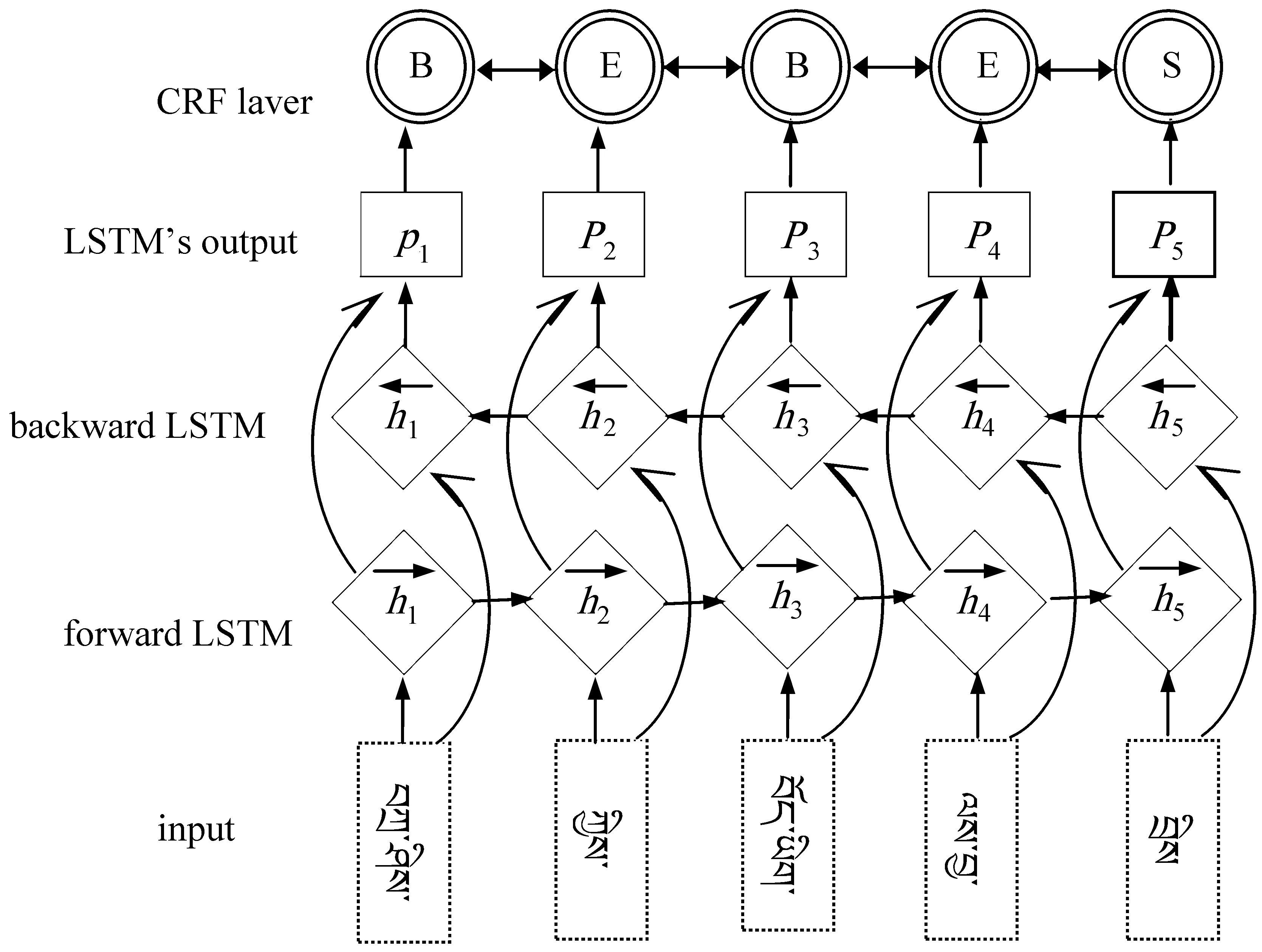
图2 BILSTM+CRF模型识别语义块
每个块可以看成词嵌入的一种特征学习,未标注数据使用Word2Vec工具来转换词向量,在生成词向量过程中设置不同的维度,然后词嵌入特征为双向LSTM,对输出的隐层加一个线性层,然后再加一个条件随机场(CRF)就得到本文实现的语义块。
藏文词向量的表示可以是预训练的,也可以在训练模型中随机生成,输入双向LSTM之前加入dropout进一步提升模型效果。Bi-LSTM 层的输出维度是标签的长度,相当于每个词hi映射到tag的发射概率值;设Bi-LSTM的输出矩阵为P,其中Pi,j代表词hi映射到tagj的非归一化概率。对于CRF来说,假定存在一个转移矩阵A,则Ai,j代表tagi转移到tagj的转移概率。对于输入序列x对应的输出tag序列y,定义如式(1)所示。
(1)
对输入序列x所对应的每个输出tag序列y计算这个分数,选择出分数最大的一个作为最终的输出tag序列。可以看出优化目标为maxs(x,y),优化方法为动态优化算法。
3.1.2 空洞卷积神经网络(ID-CNN)模型
考虑RNN不能并行计算,虽然RNN能够解决长时问题,但句子较长时,句尾对句首的依赖依然会损失很多句义信息。为弥补不足我们利用CNN进行建模,但普通CNN有一个劣势,就是卷积之后,末层神经元可能只得到了原始输入句义中的一部分信息。所以本文采用文献[40-41]提出的Dilation卷积。该模型识别过程如图3所示,主要以藏文词向量、卷积层、池化层、全连接层等为基础,添加了条件随机场。藏文分词后的每个词转化为对应的词向量矩阵。藏文分词后词的颗粒度大小不同导致句子长度不一致,为了解决此问题,以最长的藏文词为准,长短不足的句子两端补充占位符,使得所有词向量矩阵大小一样。形式上,对于1维的输入序列x∈n和卷积核f: {0, …,k-1}→,空洞卷积运算F可以定义为式(2)。
(2)
其中,d为扩张系数,k为卷积核大小。扩张系数控制每两个卷积核间会插入多少零值,当d=1时,空洞卷积就会退化为一般的卷积运算。使用较大的扩张系数允许输出端的神经元表征更大范围的输入序列,因此能有效扩张。最后卷神经积网络输出结果上再加一个条件随机场(CRF)就得到本文实现的语义块。
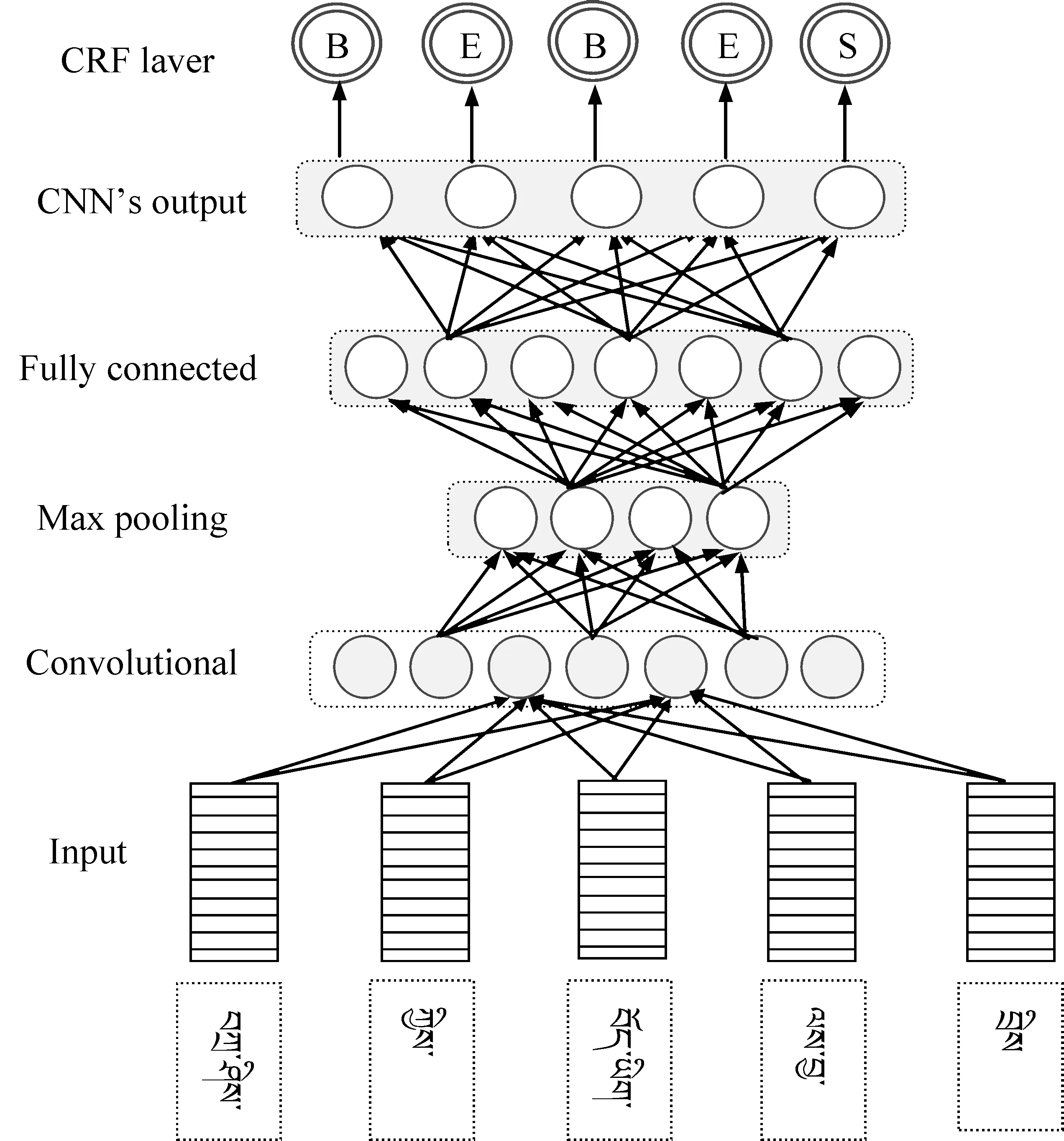
图3 ID-CNN+CRF模型识别语义块
4 实验结果与分析
目前由于未发现藏文语义块研究方面的相关报道和数据,因此,没有适合的基准(Baseline)对比本文的实验结果。从整体来看,识别效率高于一般的分词和短语的识别率。
4.1 实验数据
实验数据主要来源于人工整理和藏文电子书,构建了共有102 358句子的藏文句库。其中,实验过程 中训练数 据 集 为 92 358,测试数据 集 为10 000。实验数据为藏文简单句,句子类别为陈述句,句型结构上包括“主语+表语+连系动词”“主语+谓语”“主语+宾语+谓语”“主语+双宾语+谓语”“主语+宾语+宾补+谓语”等内容。从句子长度而言,最短句子为5个藏文词,最长的句子为22个藏文词。实验模型的超参数设置具体数值如表1和表2所示。
4.2 实验结果
在两种不同模型中设置了相同的超参数,对词向量维数(embedding)、学习速率(rate)、分类器隐藏层节点数(hidden)这三个主要参数对语义块识别的影响进行了分析。

表1 基于BiLSTM+CRF 语义块识别率 (%)

表2 基于IDCNN+CRF语义块识别率 (%)
4.3 结果分析
本文中语义块的识别是核心内容,通过实验发现语义块在句义分析中优于传统的词法分析和句法分析,因为语义块隐含语法,语义、语用一体的功能,可以降低词汇歧义问题,可替代语义角色标注等工作,又符合藏文句法分析树的标记方法。另外,在藏文句子中,除句尾动词固定外、其他语义块可随机变换序列,一句藏文可以生成几十个或几百个甚至上千个成分相同、语序不同但句义完全相同的句子[42]。
4.3.1 句型结构与模型的关系
藏文句子结构与汉语或英语存在着明显的差异,汉语是主谓宾(SVO)结构,藏文是主宾谓(SOV)结构。其中,藏文句义中虚词的语义功能非常突出。藏文句子中主谓不可缺而宾语可省略。若句中有施动格和拉格等虚词,并有几个或多个语义块组成时,语序可以发生变化,但不影响句义。例如,



4.3.2 词义消歧
4.3.3 语义角色标注

4.3.4 存在问题与不足

5 总结与展望
从自然语言理解角度看,改变以往仅语法为中心的研究思路,寻求机器理解自然语言的新方法、新思路是研究者孜孜追求的目标。藏文语义块识别研究为藏文句子语义分析理论和藏文语义理解理论的发展提供了一个新的研究思路。
本文采用神经网络与传统CRF模型相结合的方法研究和识别藏文语义块,对于空洞卷积神经网络与双向长短时记忆循环神经网络来说,这两个方法都没有占据绝对的优势,各有相应的优点。语义块识别是句子语义分割的基础工作,通过此方法可提高机器理解语义、消除词的歧义、标注语义角色等问题的能力。
