基于局部和全局语义融合的跨语言句子语义相似度计算模型
2019-08-05刘承标章友豪蒋盛益
李 霞, 刘承标, 章友豪, 蒋盛益
(1. 广州市非通用语种智能处理重点实验室,广东 广州 510006;2. 广东外语外贸大学 信息科学与技术学院,广东 广州 510006)
0 引言
跨语言句子语义相似度是指计算不同语言句子之间的语义相似程度,它被广泛应用于机器翻译、平行语料库构建、跨语言文本推荐、跨语言信息检索等领域。目前,单语言(尤其以英语为代表的单语言)句子语义相似度度量取得了很大的成功,然而,由于缺乏足够的训练语料,跨语言句子语义相似度研究还存在诸多挑战[1-2]。
传统的句子语义相似度研究工作主要集中在抽取句子的文本特征来计算句子间的语义相似度。如传统使用向量空间模型和n-gram特征的语义相似度计算方法[3-6]、基于句子语法结构特征的方法[7-9]、基于机器翻译的方法[10]以及基于双语词典或平行语料的方法[11-14]等。Tian[15]和Wu[16]的工作通过抽取句子之间丰富的文本特征来表示句子之间的语义信息,取得较好的效果,分别在SemEval 2017[注]http://alt.qcri.org/semeval2017/task1/index.php?id=data-and-tools比赛任务中取得第一名和第二名的成绩。其中,Tian等[15]使用了句对的匹配特征、基于机器翻译的特征、n-gram重合特征、句子序列特征、句法分析特征、句子对齐特征等丰富的文本特征来表示句子的语义信息。Wu[16]的工作则采用了WordNet词典中语义层次树结构中的非重叠信息来计算句子间的语义相似度,并取得了很好的结果。
传统方法使用丰富的文本特征提取句子语义信息从而计算句子之间语义相似度的方法虽然取得了不错的结果,但需要复杂的手工特征抽取。近年来,基于神经网络模型的跨语言句子语义相似度研究工作在无需传统特征的基础上可以获得较好的句子表示并取得较好的结果[17-20]。已有基于神经网络模型的跨语言句子语义相似度研究工作中,主要采用的是基于卷积神经网络或递归神经网络模型的方法,如He等[19]使用卷积神经网络(convolutional neural network,CNN)获取句子的局部语义信息作为句子的表示,最后计算句子间的相似度分数。Mueller等[17]提出使用LSTM网络(long short term memory,LSTM)[21]学习句子的表示,并通过计算句子向量之间的曼哈顿距离得到句子的整体相似度。Zhuang等[18]使用双向门递归单元(Bidirectional Gated Recurrent Unit, BGRU)[22]结合注意力机制对句子生成向量表示,同时结合了平行句对中词对的余弦相似度特征向量作为辅助特征,将句向量和特征向量输入多层感知器得到句子的相似性分数。
已有工作中卷积神经网络可以获得句子的局部信息,但不能较好地获取句子中远距离单词之间的语义相关性。LSTM网络虽然可以获得句子内一定距离内单词的依赖关系,但是它捕捉的是句子内前后单词之间的序列语义关系。而在跨语言句子相似度任务中,由于跨语言训练语料的不足,现有工作主要采用的方法[15-16,19]是将非英语语言翻译为英语,以英语为中间语言,通过将其他语种翻译为英语,然后计算翻译后英语句对之间的语义相似度作为原始跨语言句对的语义相似度。由于翻译结果的误差,可能导致翻译结果中单词语序的不对。例如,例1为SemEval 2017数据集Track4a中西班牙语—英语的一个原始跨语言句对和经过机器翻译后的结果句对。
例1原始句对:
Spanish(source):Unamujeresunbloquedetofucortadoencubospequeos.
English(target):Awomaniscuttingablockoftofuintosmallcubes.
翻译后句对:
English(source):Awomanisablockoftofucutintosmallcubes.
English(target):Awomaniscuttingablockoftofuintosmallcubes.
我们可以看到西班牙语翻译为英语后,句子单词的语序发生了错误,A woman在语义上被错误翻译为A woman is...tofu。如果使用LSTM网络获得句子中长距离关系,可能会因为序列的不正确导致语义上的不正确。基于以上两点,受已有工作的启发[23-25],本文提出了基于局部信息和全局信息融合的跨语言句子语义相似度计算模型,其主要动机是通过自注意力机制获得句子内的远距离单词之间的语义相关信息,并将句子的平均词向量作为句子的最后一个单词拼接到句子末尾作为初始输入,尽可能获取句子的全局信息。同时结合门卷控积神经网络获得句子的局部n-grams信息,分别对卷积操作使用最大池化和对自注意力机制操作使用平均池化,并将结果进行拼接后获得句子的最终语义表示。本文的模型结构如图1所示,在得到两个句子的语义表示后,通过两个语义表示向量的差值和乘积运算获得句子对之间的差异信息和相似信息,最后通过全连接层和softmax函数得到句子对的相似度分数。
本文在SemEval 2017和STS Benchmark[注]http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark两个数据集上进行了实验测试,结果表明本文所提出的模型具有较好的实验结果,获得了在SemEval 2017数据集上无任何特征工程的神经网络模型的最好结果。

图1 本文模型结构图
1 基于门控卷积神经网络和自注意力机制的跨语言文本语义相似度计算模型
1.1 句子输入编码
为了尽可能获得句子的全局信息,本文模型的输入包括两个部分,一部分是原始句子中每个单词的词向量,另一部分是句子中每个单词词向量的平均值。
设句子最大长度为L,对于输入模型的句子,若句子长度length
(1)
1.2 句子局部信息抽取
为了捕获句子的局部特征信息,本文仍然采用卷积神经网络机制。这是因为卷积神经网络具有较好的获取句子局部语义信息的能力,尤其具有获取句子n-grams语义信息的优点。不同于前人的工作,本文使用门控卷积神经网络(gated convolutional neural network,GCNN)[26]更好地捕获句子的局部语义信息。
假设待计算的句子为S,门卷积神经网络采用两个结构一致(即卷积核数和窗口大小都一致)的独立卷积结构,其中一个用sigmoid函数激活,另外一个不加激活函数,最后将它们逐位相乘,得到最终的输出S′,其计算方法如式(2)所示。
S′=conv1(S)⊗σ(conv2(S))
(2)
为了更好地捕获句子的局部信息,我们使用了不同卷积核大小的卷积块对句子进行卷积。如图1所示,我们分别使用了卷积核窗口为1、2和3三个卷积块对句子进行卷积,每个卷积核的数量均为300。然后分别使用长度为3的最大池化操作,并对三个卷积块池化的结果进行了拼接,从而得到句子的局部语义信息表示。
1.3 句子中长距离语义相关信息抽取
在跨语言句子语义相似度计算过程中,经过翻译过后的语言句子单词的词序可能会不准确,但是其单词信息往往是正确的。受已有工作的启发[23-25],考虑到自注意力机制可以获取句子中不同单词对之间的语义相关关系,并且这种关系不受单词的语序和句子中单词所在位置的影响,因此本文采用自注意力机制来捕获句子中长距离单词的相关语义关系。
类似Vaswani等的工作[25],我们并行使用多个头对句子的输入进行自注意力(Self-attention)操作。假定得到句子的输入编码(如1.1节描述)矩阵S′∈(L+1)×d,则对句子的Self-attention计算如(3~5)所示。其中L表示句子的长度,d表示句子中单词的词向量维度,S′T表示输入句子编码矩阵S′的转置。
当获得句子内容表示S′后,使其与参数矩阵W1i进行点乘操作,从而执行投影操作,得到矩阵S′W1i,对句子内容表示矩阵的转置与参数矩阵W2i进行点乘执行投影操作得到矩阵S′TW2i,然后对两个投影S′W1i和S′TW2i执行矩阵相乘操作,从而得到反映句子内各单词之间语义相关性的矩阵S′W1i×S′TW2i,最后使用softmax函数对其进行正则化,然后与经过投影的原始句子输入S′W3i执行点乘操作获得句子最后的语义表示,这一语义表示很好地反映了句中远距离单词之间的相关关系。这里的i表示Self-attention中的第i个头,W1i,W2i,W3i表示第i个头的参数矩阵。Self-attention使用不同的头来捕获不同 的相关语义关系。式(3~5)中的h表示Self-attention使用的并行Attention的个数,W0为参数矩阵,用于对所有h个头输出结果最后做一次投影。
1.4 句对的语义相似度表示
使用1.1~1.3节所描述的方法分别获取句子的局部信息和句子中远距离单词之间的语义相关信息,最后对这些信息分别执行最大池化操作和平均池化操作,然后对池化的结果进行拼接,得到句子的最后语义表示。模型中,我们采用了K最大池化操作,目的是为了保留每个特征映射中前k个特征元素,减少池化过程中语义信息的丢失。拼接后的句子的语义表示包含了句子中的局部信息、全局信息以及句子中不同单词之间的语义相关性信息。
为了计算两个句子的语义相似度,类似于Shao的工作[20],我们分别对两个句子的最终语义表示执行按位减操作(取绝对值)和按位乘操作,然后进行拼接从而获得两个句子的语义相似度的表示对,其计算如式(6)所示。将句子的语义相似度表示输入两个全连接层,最后输入softmax函数得到两个句子表示的语义相似度概率分布。
(6)
其中,source表示每个句子对中的第一个句子,target表示每个句子对中的第二个句子。⊖表示元素对应相减,⊗表示元素对应相乘。
2 实验
2.1 实验数据
本文实验选取了SemEval-2017和STS Benchmark两个数据集对模型进行测试。其中,SemEval-2017评测数据包含单语言和跨语言句子对共7种类型,涉及语种包括阿拉伯语、英语、西班牙语、土耳其语等。与评测中其他队伍一样,我们采用谷歌翻译[注]https://translate.google.com将其他语言的句子均翻译为英语。同时,我们类似于前人的工作,使用SemEval 2012~SemEval 2015比赛数据[注]http://ixa2.si.ehu.es/stswiki/index.php/Main_Page中的所有英文句对一共13 191对数据作为模型的训练数据。STS Benchmark数据是STS 任务中在2012—2017 年的英文评测数据集上抽取得到的训练集、开发集和测试集。所用数据集的详细信息分别如表1和表2所示。数据集中,每个句对都被标注了0~5的相似度得分,0表示两个句子在语义上几乎不相关,5表示两个句子在语义上几乎等同。为了更好地比较实验在不同数据集上的结果差异,我们还对SemEval 2017评测数据集和STS Benchmark中不同数据的句对平均句长进行了统计,结果如表1和表2所示。可以看到,在SemEval-2017评测数据集中,除了Track4b的平均句长为19.23外,其他Track的数据集句对的平均句长在7.74~8.7之间。这是因为,Track4b数据集是来自机器翻译的测试数据,数据的来源领域不同,且测试集中句子长度也长于一般的普通句子。

表1 SemEval-2017评测数据

表2 STSBenchmark数据
2.2 实验设置
实验参考了Tian等的工作[15]中使用的paragram[注]https://drive.google.com/file/d/0B9w48e1rj-MOck1fRGxa ZW1LU2M/view词向量[26],实验中词向量的维度设置为300,句子长度设定为30。每个门控卷积神经网络卷积块的卷积核设定为300,卷积池化操作中的k设置为3。Self-attention中设置了8个头,每个头的参数矩阵均设置为16维。全连接层中,第一个全连接层神经元节点个数为900,第二个全连接层的输出节点数为6。
采用Adam算法[27]优化模型,学习率为0.001。实验参考已有工作[15-16,20]所使用的评测指标,采用皮尔森相关系数(Pearson correlation coefficient,PCC)作为评测指标,batch size设置为128。实验采用相对熵作为损失函数,损失函数如式(7)所示,其中,P(x)为系统预测分值,Q(x)为人工评定的分值。
(7)
2.3 实验结果与分析
为了验证本文模型的有效性,我们选取SemEval 2017 任务1前三名方法作为我们的基准方法,分别是第一名Tian等的工作[15]、第二名Wu等的工作[16]和基于神经元网络方法的Shao的工作[20]。这三个基准方法所对应的模型分别是ECNU[15]、BIT[16]和HCTI[20]。
ECNU模型该模型采用联合学习方法,分别训练基于传统特征的机器学习模型和基于神经元网络的模型,两个模型共同决定最终结果。其中传统特征方面分别抽取了基于翻译和对齐等方法的34种句对匹配特征以及基于词袋、语义依存等33种单句特征,并将这67种特征归一化后使用随机森林等多个机器学习算法进行回归建模。在神经网络模型方面,该模型分别以句子的平均词向量、平均词向量投影、深度平均网络(deep average network, DAN)[28]以及LSTM网络作用于句子词向量得到单个句子的最终语义表示,然后对两个句子进行相乘和相减,通过全连接得到句对的分数。
BIT模型该模型基于WordNet计算句子中词语的概念信息熵,将得到的句子信息熵结合对齐特征以及词向量模型分别进行相似度计算。
HCTI模型该模型将跨语言句对中的词共现、数字共现和词性等特征融入词向量中,以此为输入使用卷积神经网络进行卷积和池化后作为句子的最终语义表示,然后对两个句子进行相乘和相减,通过全连接得到句对的分数。
为了说明本文提出的模型的有效性,本文还比较了单独使用卷积神经网络(CNN)、单独使用门控卷积神经网络(GCNN)以及使用GCNN+Self-attention组合的实验结果对比。
2.3.1 SemEval 2017数据集的实验结果
首先我们在SemEval 2017数据集上进行了实验,实验结果如表3所示。从表3可以看出,本文提出的纯神经网络模型方法(GCNN+Self-attention)在Track1~Track6共7个Track上的Primary指标上超出第二名Wu等工作[16]中提出的BIT模型2.35个百分点,超出第三名Shao等工作[20]中提出的HCTI神经网络模型4.26个百分点。
另外我们发现,在SemEval 2017数据集上,本文方法低于第一名Tian等工作[15]提出的ECNU模型2.92个百分点。对此我们分析,ECNU模型融合了具有丰富传统特征的多个机器学习方法以及多个神经网络方法,并采用联合学习得到最优结果。从该结果可以看出,传统丰富的特征,如面向跨语言句子相似度的句对匹配特征等可以较好抽取到句对之间的相关语义信息,如基于机器翻译的词对齐特征、句子依存句法特征、句子n-grams特征、句子对齐特征等。然而ECNU模型使用了67个句对匹配特征和单个句子的特征,其手工抽取特征的代价较高。而本文方法无需任何手工特征,只需要预先训练好的词向量作为输入,相比ECNU模型简单高效。另外,由于SemEval 2017数据集中的跨语言训练数据相对纯神经网络模型来说,数据量较少,这也可能导致神经网络模型的结果没有达到最优。整体而言,本文模型相比已有的纯神经网络模型方法取得了最好的结果。
同时我们发现,数据集的句子长度对模型的结果具有较大影响。SemEval 2017评测数据集中,Track4b的平均句长为19.23,远高于其他6个Track数据集的句子长度。同时Track4b数据集的来源领域不同,使得所有模型在Track4b上的模型效果不佳。其中,HCTI[20]模型在该数据集上效果不佳的原因,我们认为这可能是因为单纯简单的CNN模型对于捕获较长句子的语义表示效果不佳。而BIT[16]模型所采用的方法对句对本身的质量要求较高,而Track4b数据集中,由于句子较长,机器翻译结果质量不佳,导致BIT模型在该Track上的结果不太好。本文模型由于从多个方面捕捉到了句子的语义信息,一定程度上消除了机器翻译所导致的句对质量不佳或语序不对所带来的影响,在Track4b数据集上,本文模型分别高出HCTI模型和BIT模型10.09个百分点和13.85个百分点。ECNU模型[15]对Track4b数据集采用了两种操作模式,一种和BIT、HCTI以及本文模型一样,该数据集整体翻译为英语句对,在这种模式下的结果为28.89[15]。另一种是整体翻译为西班牙语句对,这种模式下的结果为33.63。

表3 SemEval-2017数据集上的实验结果(%)
2.3.2 STS Benchmark数据集的实验结果
本文还在STS Benchmark数据集上进行了测试,实验结果如表4所示。从表4中可以看出,本文模型相比现有的基于神经网络的HCTI模型[20]高出1.7个百分点,同时在测试集上相比第二名相差0.8个百分点。但是,在开发集上,本文方法相比第二名高出1.3个百分点,同时接近第一名的结果。
实验中我们还对比了使用经典CNN和使用GCNN以及使用GCNN+Self-attention的实验结果。从表3和表4可以看出,在SemEval-2017和STS Benchmark两个数据上,使用GCNN均比单纯简单使用CNN具有一定的提升,这说明GCNN确实通过门控制操作一定程度上提升了有效信息的获取。而使用GCNN+Self-attention的结果在两个数据集上均取得最好的结果,这说明使用Self-attention后捕获到了句子中长距离单词之间的语义相关性,一定程度上提升了句子的语义表示能力,从而提升了句对之间的语义相似度计算准确性。
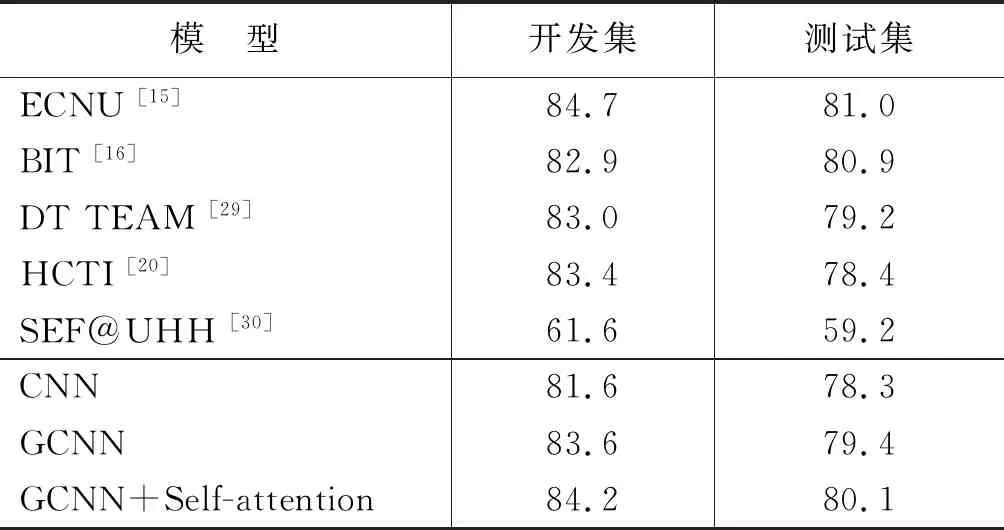
表4 STS Benchmark数据集上的实验结果(%)
2.4 案例分析
为了能够更好地解释本文的模型,我们以一个实际例子来阐述Self-attention所学习到的语义关系。我们将Self-attention分别对翻译后句子“Awomanisablockoftofucutintosmallcubes.”(该句原始的西班牙语为:Unamujeresunbloquedetofucortadoencubospequeos.)和目标英语句子“Awomaniscuttingablockoftofuintosmallcubes.”所学习得到的语义信息进行分析,结果如图2所示,图2(a)表示翻译后的源句,图2(b)表示目标句。其中,图2中的箭头表示词与词之间的相关性,箭头的颜色深浅则代表词对之间语义的相关程度,颜色越深表示两个单词之间的语义相关性越强。
在图2中,我们可以看到翻译后的源句中存在语序错误,这导致翻译结果的语义存在错误(结果为A woman is...toufu.)。虽然翻译结果的单词语序不正确,但是我们可以看到,Self-attention机制依然学习到了正确的语义相关关系。例如,翻译后源句中的tofu和block、cut、cubes语义关联较强,而cut和woman、block、tofu、into语义关联较强。而在目标句中,cutting和woman、block、into、cubes语义关联较强,而tofu和cutting、cubues语义关联较强。这表明虽然源句由于翻译导致语序错误,但是两个句子中单词之间的语义关联依然是相似的,这使得源句和目标句的语义相似度计算结果依然可以正确得到。

图2 Self-attention在错误翻译句对上的学习效果
3 相关工作
传统句子语义相似度研究主要采用基于特征工程的方法,包括:基于词的语义的方法,如宋彦等[6]提出的基于n-gram特征的语义相似度计算方法;基于句法结构的方法,如黄洪等[9]提出的使用句子依存句法特征来计算句子之间的相似度;基于知识库的方法,如闫红等[13]使用HowNet词典抽取句子中的特征信息,从而得到句子之间的相似度;基于语料库的方法,如Guo等[14]提出的基于语料库使用潜在语义分析方法提取句子的特征信息,从而计算句子之间的语义相似度。传统基于句子结构特征或词典和语料库方法的计算方法存在语义稀疏或语料不充分等问题。
针对传统特征抽取方法所带来的问题,近年来研究人员提出了基于神经网络模型的句子语义相似度计算方法。Mueller等[17]提出了基于MaLSTM模型的句子相似度计算方法,该模型将句子切分成由Word2Vec[28]表示的词向量,并经过LSTM网络得到句子向量,通过计算句子向量之间的曼哈顿距离得到句子的整体相似度。Zhuang等[18]使用递归神经网络并结合注意力机制生成句向量,同时还结合了平行句对中词对的余弦相似度特征向量,通过联合句子向量和特征向量输入多层感知器得到句子的相似性分数。He等[19]将卷积神经网络应用到句子相似度的计算上,该模型通过两个不同的卷积核以及三种不同的池化操作多角度提取句子中的特征信息生成句向量,计算句向量之间相似性度量值并经过全连接层后输出句子的相似性分数。
在SemEval 2017年的评测任务中,Shao等[20]使用卷积神经网络对句子建模,抽取句子中的词共现、数字共现和词性等特征,将特征向量与词向量拼接后的向量作为输入,增加句子的语义信息,同时对于卷积后的句向量采用求差和乘积的方法分别获取句子之间的差异信息以及相同信息,最后通过全连接的方式得到句子之间的相似性分数。Wu等[16]针对句子相似度计算任务设计了三个实验方案,他们首先基于WordNet计算句子中词语的概念信息熵,通过在同一个概念向量空间中得到句子的相似度,更深层次地考虑句子的语义信息,其次他们又将得到的句子信息熵结合对齐特征以及词向量模型分别进行相似度计算,最终确定信息熵和Word2Vec的结合方法效果最好,该方法同时考虑词语的表征信息和句子的深层语义信息,但词向量模型所包含的句法结构信息甚少,直接影响句子的相似度计算。Tian[15]等结合传统特征工程和深度学习的方法,提高句子相似度计算的整体性能,在传统特征工程方面,他们提取n-gram、序列、句法、基于翻译和对齐等34种句对匹配特征以及词袋、语义依存、词向量等33种单句特征,并将这67种特征归一化后用于回归建模;在深度学习模块,他们将预处理后的词向量通过深层平均网络和LSTM神经网络得到句向量,输入全连接层得到句子相似度分数,最终联合传统特征工程的分数得到句子之间的整体相似度分数。该方法结果虽然超出其他研究方法,但其67种特征抽取的工程复杂度也相对较高。
虽然现有基于神经网络的跨语言句子语义相似度模型取得了较好的效果,但现有模型中CNN网络和LSTM网络对语序错误句子的语义学习捕获到的可能依旧是错误的语义信息。基于此,本文提出了基于GCNN+Self-attention机制的模型结构,目的在于学习到句子的局部和全局语义信息,以及句子中不同单词之间的相关语义信息,并通过拼接融合得到最后的向量,用于句子的最后语义表示。在两个不同数据集上的多个实验表明,本文提出的思想和模型取得了较好的性能。
4 结论
跨语言句子语义相似度计算在跨语言摘要、跨语言平行句对抽取等多个任务中具有重要的应用。本文针对现有的基于神经网络模型的跨语言句子语义相似度计算方法中存在的问题,提出了基于局部和全局信息融合的跨语言句子语义相似度计算模型。
首先在句子输入时,将句子中的所有单词平均词向量作为反映句子全局信息的向量加入到句子的最后,以此来获取句子的全局信息部分。在此基础上,分别使用门控卷积神经网络学习句子的局部信息,使用自注意力机制学习句子中远距离单词之间的语义相关关系,最后通过最大池化和平均池化得到的结果拼接后得到句子的最后语义表示。
该方法得到两个句子的语义表示后,通过句子语义向量的差值运算和相似度运算并拼接输入到全连接层,最后通过softmax得到句子的语义相似度概率分值。模型分别在SemEval 2017评测任务和STS Benchmark数据集上进行了实验测试,结果表明本文提出的模型超出了SemEval-2017评测任务的第二名成绩,同时也是基于纯神经网络模型的最好结果,证明了我们所提方法的有效性。
