PCA 中两种数据缺失处理方法的比较
2019-08-05左航
左航
(国网郑州供电公司,河南 郑州 450000)
第一种方法称为基于均匀性分析的数据缺失被动(MDP)方法。第二种方法是加权低秩近似法(WLRA)。2 种方法对人为生成的不完全数据进行分析,并用平均同余系数对原始完整数据进行参数恢复能力检验。
1 2 种方法的介绍

B 为n ×t 矩阵,C 为m ×t 矩阵,D 为按降序排列的奇异值的t ×t 对角矩阵。设Br,Cr和Dr表示B、C 和D 对应于r 广义奇异值的部分。

并且

获得上述解决方案至少有2 个不同的标准:一个是

uj是权的r 元素向量,和表示任意矩阵Y。
另一个是

1.1 缺失数据被动(MDP)
通过文献概括(4)推导出MDP 方法:
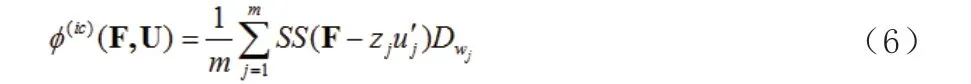

其中:

简化最小化过程。上述最小化问题为

F 服从于(7)。改为
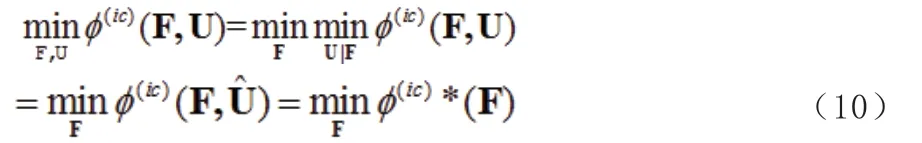
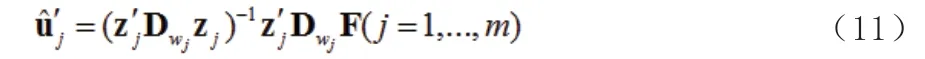
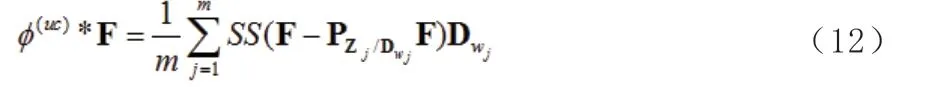
其中:
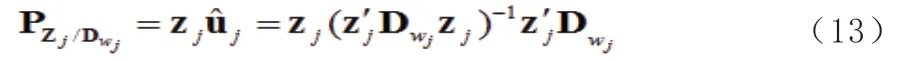
(12)写成:

其中

(14)相对于(7),F 的最小化等价于

(16)通过广义本征方程得到

1.2 加权低阶逼近(WLRA)

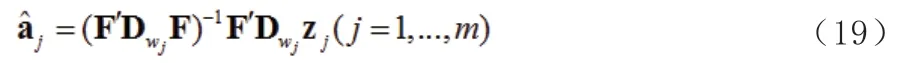
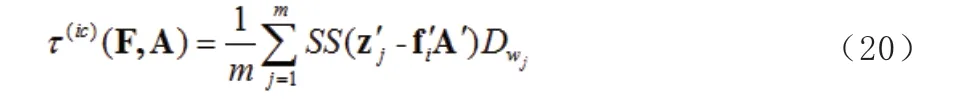
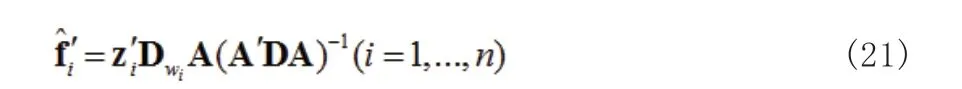

2 实证研究
MCAR 条件下的食物和癌症数据:数据集是文献[10]编译的一个小数据集。规定的比例(10、20 和30)随机(MCAR)初始完整数据。首先将PCA 应用于原始完整数据,发现第一个我们的组分占总变异的70.8、14.1、6.2 和5.3。
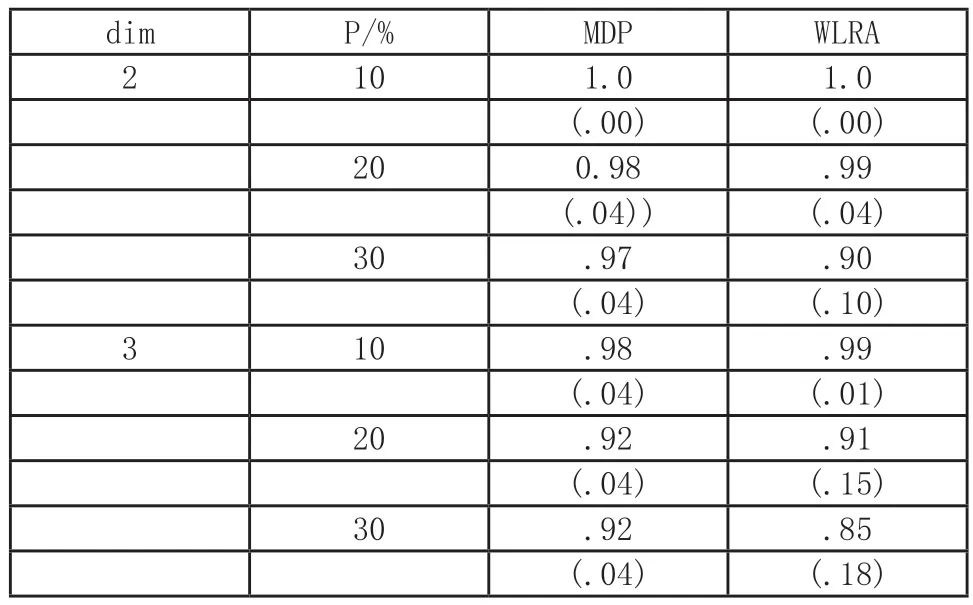
表1 食品和癌症数据组分负荷恢复:同余系数的均值和标准差(括号内)
有2 个具有经验意义的组成部分,一个是强的,另一个是相对弱的。决定检查1 ~3 的组分数量。表1 总结了主要结果。表中的第一列表示提取组分的维度。第二列表示删失率。接下来的两列显示了2 种方法获得的组分负荷一致性系数的平均值和标准差。少量组件和低删失率的回收率极佳。随着维数和删失率的增加,恢复率下降。然而2 种方法的恢复恶化率并不一致。
3 结语
本文考察了它们的参数恢复能力,作为缺失数据比例、解的维数和删失中非随机性程度的函数。在MCAR 情况下,当数据的维数和缺失比例较小时,所有方法都能很好地工作。随着这些因素的增加,它们的性能下降,但使用 WLRA 方法时,恶化速度往往更快。可以提供的一个一般性建议是,都应保持组件数量尽可能减少。高维解往往会增加提取弱分量的机会,这总是不利于参数恢复。
