基于多尺度多任务卷积神经网络的人群计数
2019-08-01曹金梦倪蓉蓉杨彪
曹金梦 倪蓉蓉 杨彪

摘 要:在智能監控领域,实现人群计数具有重要价值,针对人群尺度不一、人群密度分布不均及遮挡等问题,提出一种多尺度多任务卷积神经网络(MMCNN)进行人群计数的方法。首先提出一种新颖的自适应人形核生成密度图描述人群信息,消除人群遮挡影响;其次通过构建多尺度卷积神经网络解决人群尺度不一问题,以多任务学习机制同时估计密度图及人群密度等级,解决人群分布不均问题;最后设计一种加权损失函数,提高人群计数准确率。在UCF_CC_50和World Expo10数据库上进行了评估,验证了自适应人形核的有效性。实验结果表明:所提算法比最新算法Sindagi等的方法(SINDAGI V A, PATEL V M. CNN-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway, NJ: IEEE, 2017: 1-6)原稿描述算法不准确,需具体写至某个算法,因为没有相关算法的缩写词,只有用文献的具体内容来表达了,这两个文献是指代文献[18]和[17]吧?请明确。回复:正确。在UCF_CC_50数据库上平均绝对误差(MAE)数值和均方误差(MSE)数值分别降低约1.7和45;与Zhang等的方法(ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 589-597)相比,在World Expo10数据库上所提算法的MAE值降低约1.5,且在真实公共汽车数据库上仅0~3人的计数误差,表明其实用性较强。
关键词:人群计数;多尺度;多任务学习;卷积神经网络;自适应人形核;加权损失函数
中图分类号: TP391.4; TP18
文献标志码:A
Abstract: Crowd counting has played a significant role in the field of intelligent surveillance. Concerning the problem of scale variation, non-uniform density distribution and partial occlusion of crowds, a method of crowd counting using Multi-scale Multi-task Convolutional Neural Network (MMCNN) was proposed to solve existing challenges in crowd counting. Initially, a novel adaptive human-shaped kernel was used to generate a density map which described the population information, and the partial occlusion was eliminated. Then, scale variation was handled through constructing a multi-scale convolutional neural network and non-uniform density distribution was resolved by the multi-task learning mechanism, which simultaneously estimate the density map and density level of crowds. Further, a weighted loss function was proposed to improve the accuracy of crowd counting. Evaluations in UCF_CC_50 and World Expo10 datasets revealed the effectiveness of the proposed adaptive human-shaped kernel. The experimental results show that, compared with the method proposed by Sindagi et al. (SINDAGI V A, PATEL V M. CNN-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway, NJ: IEEE, 2017: 1-6), the Mean Absolute Error (MAE) and Mean Squared Error (MSE) of the proposed method in UCF_CC_50 dataset is decreased by 1.7 and 45 respectively. Compared with the method proposed by Zhang et al. (ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 589-597), the MAE of the proposed method in World Expo10 dataset is decreased by 1.5. Simultaneously, evaluations in practical bus videos with an error of approximately 0-3, which verifies the practicability of the proposed counting approach.
Key words: crowd counting; multi-scale; multi-task learning; Convolutional Neural Network (CNN); adaptive human-shaped kernel; weighted loss function
0 引言
在智能监控领域,利用计算机技术进行人群计数对公共安全具有重要意义,譬如可以控制密集场景下的人群数目,防止发生拥挤或踩踏事件,并提供安全预警。此外,计数技术也可用于车辆计数从而进行交通疏导,估计水中微生物数目以分析水质状况等。
现有的人群计数方法通常分为检测计数、聚类计数和回归计数[1]三类。前两种方法适用于稀疏场景下人群计数,但多数场景(如图1所示)都存在严重遮挡、尺度不一、密度分布不均匀等问题(图像均从基准数据库中选择得到)。尽管许多研究人员对基于回归的人群计数进行了广泛的研究,但在特征表示和回归模型方面仍然存在缺陷。近年来,随着深度学习的快速发展,越来越多的人致力于通过卷积神经网络(Convolutional Neural Network, CNN)自动提取图像有效特征。
本文提出的多尺度多任务卷积神经网络(Multi-scale Multi-task Convolutional Neural Network, MMCNN)能够较好地解决人群分布不均、人群尺度不一等问题。本文的创新性主要体现在:1)提出一种新颖的自适应人形核,生成更符合人群特点的密度图;2)提出一种多尺度卷积神经网络预测人数,结合多任务学习机制解决尺度不一、人群分布不均等问题;3)提出一种加权损失函数,增强估计密度图的准确性,提高人群估算精度。
1 前人工作
传统人群计数方法分为三种:通过检测计数、通过聚类计数和通过回归计数。
检测计数方法,通过检测场景中的每个个体实现人群计数[2]。由于检测完整个体比较耗时,且易受遮挡影响,Gao等[3]根据检测到的人头数目估算人数,而Luo等[4]建立头肩模型估计人数。尽管基于局部部位检测计数的方法对人群遮挡具备鲁棒性,但在复杂背景中精度不高。聚类计数方法[5]通过将人群聚类估计场景中人群数量。例如,Rao等[6]提出一种使用运动线索和层次聚类估计人群密度的方法。虽然聚类计数方法易于实现,但该方法需要从密集光流中提取可靠的运动模式,计算过程耗时。
与上述两种方法不同,回归计数方法旨在学习特定特征和人群计数之间的直接映射[7],因此能在较为混乱的环境下进行人群计数。姬丽娜等[8]使用尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)进行人群数量估算,Hashemzadeh等[9]基于关键点获取多种特征组合,估计人群数量。此外,Shafiee等[10]提出一种新颖的低复杂度、尺度归一化的移动梯度直方图(Histogram of Moving Gradient, HoMG)。这些手动提取的特征在稀疏的人群中获得较好的表现,但不适用于人群密集场景。
近年来,卷积神经网络(Convolutional Neural Network, CNN)在目标检测、语义分割等领域取得巨大的成功。对于人群计数,CNN同时训练人群密度和人群数目两个相关目标[11-13]。此外,Sheng等[14]使用CNN计算密集属性特征图,构建局部感知特征获取空间上下文信息和人群的局部信息。Kang等[15]則提出一种带辅助信息的自适应卷积神经网络。与上述专注于向网络添加补充信息不同,一些研究人员侧重于网络结构改进。时增林等[16]提出一种空间金字塔池化网络进行人群计数。Zhang等[17]则设计了简单、有效的多列卷积神经网络,从不同人群密度和角度准确估计静止图像中的人群数目。受其启发,Ooro-Rubio等[12]提出Hydra-CNN,估计不同尺度下人群密度图。除了人群尺度不一之外,人群分布不均是影响计数性能的另一重要问题。Sindagi等[18]提出了级联多任务卷积神经网络,同时估计密度等级和密度图,而Marsden等[19]提出ResnetCrowd模型,同时预测人群数目、密度图、计数类别等。
因此,深度卷积神经网络能较好地解决不同尺度、人群分布不均情况下计数不精确的问题。以下将详细介绍提出的方法,通过尝试多种改进策略解决当前拥挤人群计数不准确的问题,并在多个通用数据库上验证该方法的有效性。
2 多尺度多任务卷积神经网络
2.1 基于自适应人形核的密度图
高斯核(如图2(a)所示)常用于对标记点进行卷积,生成密度图,该方法适用于描述细胞或细菌等圆形物体的密度分布。Zhang等[11]认为人体形状更接近于椭圆形,但是在不同尺度场景下,人体形状存在较大差异。人群密度较稀疏时,人体形状可以看成一个圆形与椭圆的叠加(如图2(b)所示),但其无法描述人群存在严重遮挡时的情况,因此,针对不同密度人群提出一种新颖的自适应人形核(如图2(c)所示),并通过对标记点进行卷积生成更贴合真实场景的人群密度图,具体方法如下。
其中人群密度分布核包含两项:头部为归一化二维核函数Nh,身体部分为双变量正态分布Nb。Pb表示行人身体位置,对于第i个点(一个点表示一个人),Pb由Ph的位置与当前人所处位置密度决定,即Pb=Ph+Di×Mp,Mp为场景透视图的像素值,Di表示第i个点与其最近的10个(邻近像素点的个数选择主要是通过实验试凑的方式完成)。实验通过对与其最近的6、8、10、12个点分别计算平均距离,结果表明当取10个相邻点时,获取的人群密度图更贴合真实人群密度图,最终统计出来的人数更加贴近真实值(在标准数据库上得到了更低的平均绝对误差)。相邻点之间的平均距离,由式(2)计算得到:
其中:dij表示第i和第j个点之间的距离,Di通过max{dij}归一化,dij越小表示场景越密集。
为较好地表示行人轮廓,Nh项设定方差σh=0.2Mp,对于Nb项,σx=(0.6-Di/2)Mp,σy=(0.2+Di/2)Mp。对于稀疏人群,图像中个体的密度图如图2(b)所示;而对于密集人群,图像中个体的密度图如图2(c)所示。如果给定场景不存在透视图,则基于像素的垂直位置粗略估计密度图。为确保密度图中密度值总和的积分等于原始图像中的总人群数量,整个分布通过场景实际人数Z进行归一化。
2.2 改进的多尺度多任务卷积神经网络
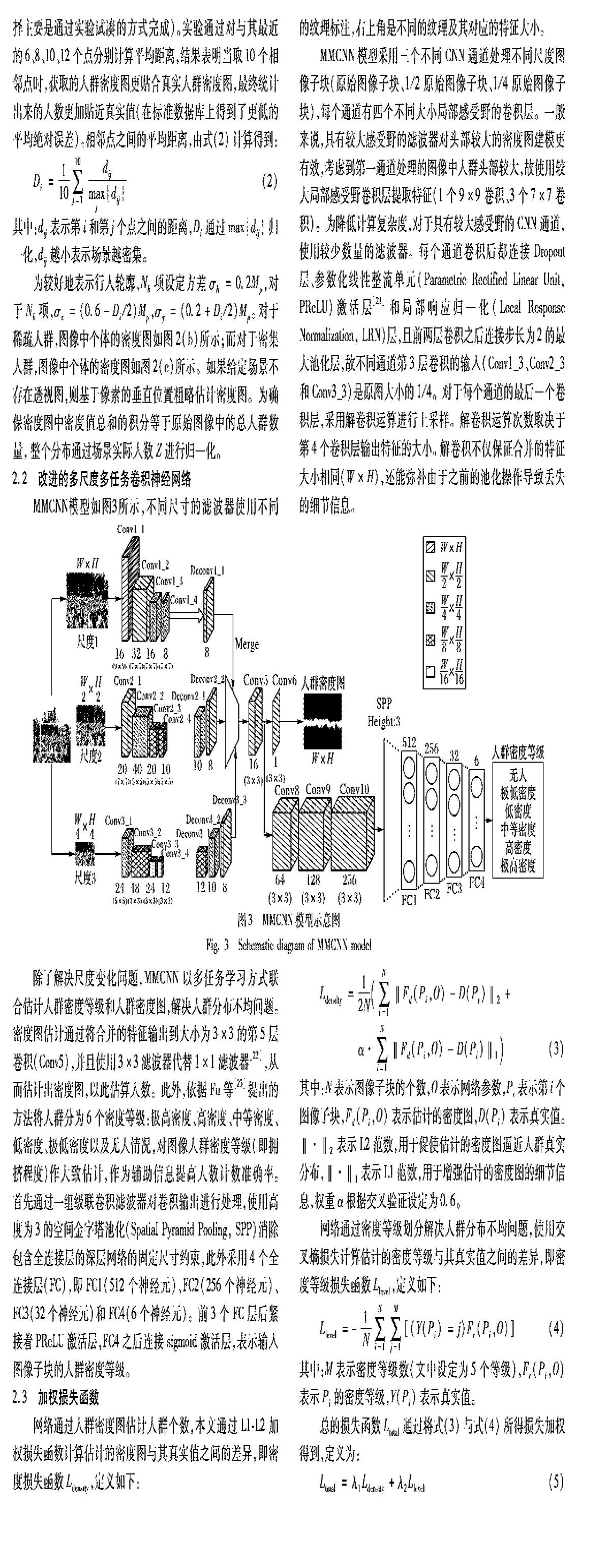
MMCNN模型如图3所示,不同尺寸的滤波器使用不同的颜色纹理标注,右上角是不同的纹理及其对应的特征大小。
MMCNN模型采用三个不同CNN通道处理不同尺度图像子块(原始图像子块、1/2原始图像子块、1/4原始图像子块),每个通道有四个不同大小局部感受野的卷积层。一般来说,具有较大感受野的滤波器对头部较大的密度图建模更有效,考虑到第一通道处理的图像中人群头部较大,故使用较大局部感受野卷积层提取特征(1个9×9卷积、3个7×7卷积)。为降低计算复杂度,对于具有较大感受野的CNN通道,
使用较少数量的滤波器。每个通道卷积后都连接Dropout层、参数化线性整流单元(Parametric Rectified Linear Unit, PReLU)激活层[21]和局部响应归一化(Local Response Normalization, LRN)层,且前两层卷积之后连接步长为2的最大池化层,故不同通道第3层卷积的输入(Conv1_3、Conv2_3和Conv3_3)是原图大小的1/4。对于每个通道的最后一个卷积层,采用解卷积运算进行上采样。解卷积运算次数取决于第4个卷积层输出特征的大小。解卷积不仅保证合并的特征大小相同(W×H),还能弥补由于之前的池化操作导致丢失的细节信息。
除了解决尺度变化问题,MMCNN以多任务学习方式联合估计人群密度等级和人群密度图,解决人群分布不均问题。密度图估计通过将合并的特征输出到大小为3×3的第5层卷积(Conv5),并且使用3×3滤波器代替1×1滤波器[22],从而估计出密度图,以此估算人数。此外,依据Fu等[23]提出的方法将人群分为6个密度等级:极高密度、高密度、中等密度、低密度、极低密度以及无人情况,对图像人群密度等级(即拥挤程度)作大致估计,作为辅助信息提高人数计数准确率。首先通过一组级联卷积滤波器对卷积输出进行处理,使用高度为3的空间金字塔池化(Spatial Pyramid Pooling, SPP)消除包含全连接层的深层网络的固定尺寸约束,此外采用4个全连接层(FC),即FC1(512个神经元)、FC2(256个神经元)、FC3(32个神经元)和FC4(6个神经元)。前3个FC层后紧接着PReLU激活层,FC4之后连接sigmoid激活层,表示输入图像子块的人群密度等级。
2.3 加权损失函数
网络通过人群密度图估计人群个数,本文通过L1-L2加权损失函数计算估计的密度图与其真实值之间的差异,即密度损失函数Ldensity,定义如下:
其中:N表示图像子块的个数,O表示网络参数,Pi表示第i个图像子块,Fd(Pi,O)表示估计的密度图,D(Pi)表示真实值。‖·‖2表示L2范数,用于促使估计的密度图逼近人群真实分布,‖·‖1表示L1范数,用于增强估计的密度图的细节信息,权重α根据交叉验证設定为0.6。
网络通过密度等级划分解决人群分布不均问题,使用交叉熵损失计算估计的密度等级与其真实值之间的差异,即密度等级损失函数Llevel,定义如下:
其中:M表示密度等级数(文中设定为5个等级),Fc(Pi,O)表示Pi的密度等级,Y(Pi)表示真实值。
总的损失函数Ltotal通过将式(3)与式(4)所得损失加权得到,定义为:
其中,λ1与λ2分别表示密度损失函数与密度等级损失函数的权重,由于估计人群密度图为多任务学习中的主要任务,而估计人群密度等级为辅助任务,因此本文令λ1=0.7,λ2=0.3。
2.4 训练及测试细节
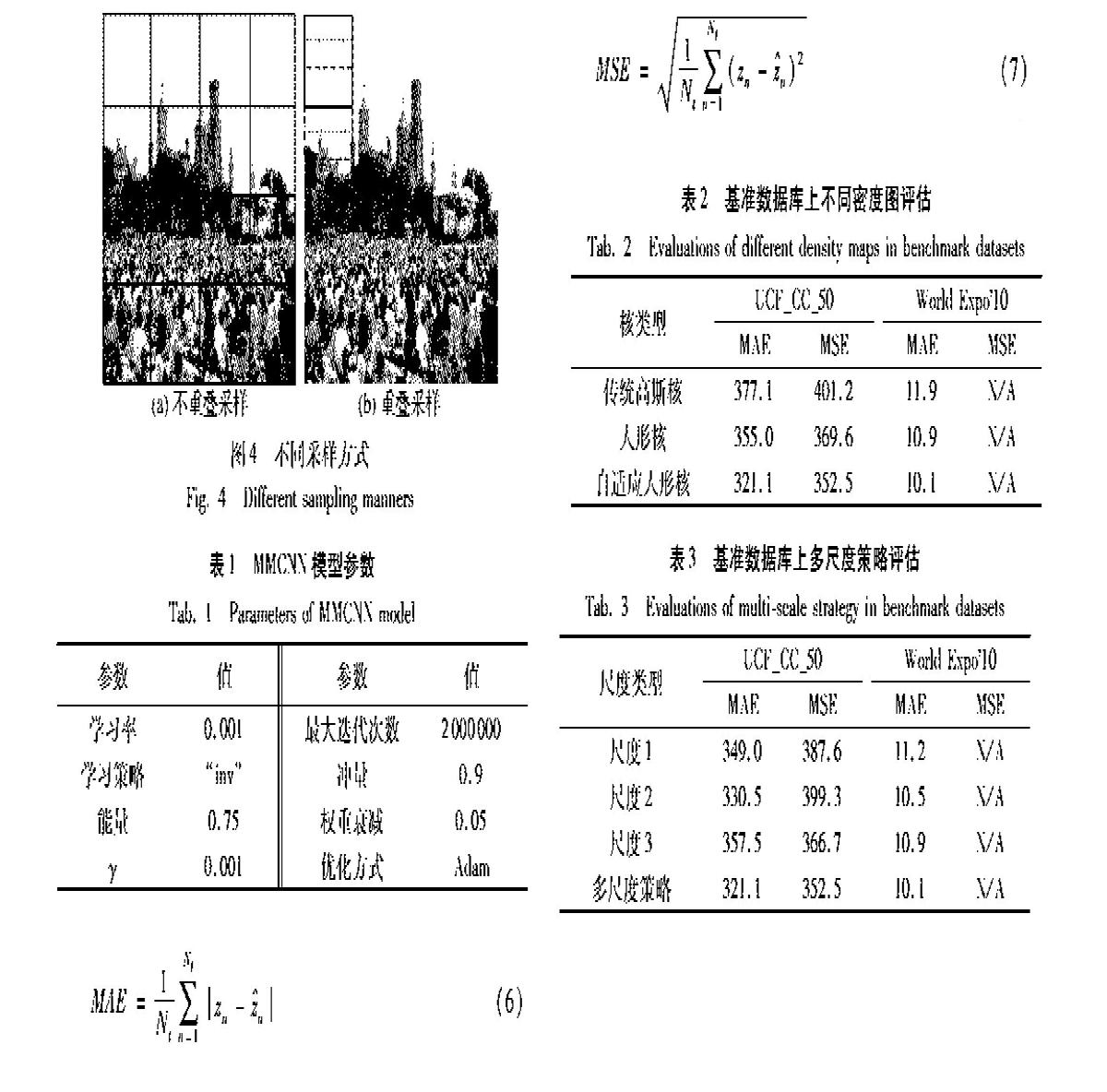
训练阶段对人群图像进行不重叠采样,因为重叠采样存在过多冗余信息,容易导致模型泛化能力差[18]。通过将人群图像等分为16个图像子块(如图4(a)所示),对每个图像子块,计算其密度图以及人群密度等级。最后将所有图像子块和对应的真实标记同时输入网络,以多任务学习的方式进行训练。
测试阶段以相同步幅对输入图像进行重叠采样(如图4(b)所示)。依次采样黑色方框、红色点线框、黄色虚线框内的图像子块,以此类推(每两个图像子块之间的步长设为10个像素点)。将所有图像子块的密度图叠加获得整张图像的密度图,对于重叠部分,将该处密度值除以重叠次数进行归一化。
训练及测试阶段均通过对整张人群图像的密度值进行积分求和计算全局人群数量。需要注意的是,人群总数是一个小数,而非整数。
2.5 参数设置
模型使用Ubuntu系统下Caffe框架及CUDNN5.1、CUDA8.0在配备有i7-7700K CPU、NVIDIA GTX 1080 GPU的台式机上运行,显卡显存为8GB。由于显存不够大,在训练阶段设定batchsize为16,为提高模型拟合速度,使用常数项为0.9的冲量,并通过常数项为0.05的权重衰减控制模型过拟合。表1详细地列出了模型的参数。MSRA用于每个卷积层的初始化。
3 实验结果分析
3.1 评价指标
实验中采用平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error,MSE)两个指标评估不同方法的有效性,指标定义如下:
其中:Nt是测试图片个数,zn是第n张图片中真实的人数,n是第n张图片中估计的人数。总的来说,MAE表明估计的准确性,而MSE表明估计的鲁棒性。
3.2 数据库
采用两个基准数据库验证网络的有效性,并通过对真实场景下公交车上的人数估算验证网络的实用性。
1)UCF_CC_50数据库。该数据库由Idrees等[24]提出,包含50幅图像,由于图中人数变化很大而且多数图像人群密集,故具有较大挑战,人数由94到4543人不等。
2)World Expo10数据库。该数据库由Zhang等[17]提出,包含来自2010年上海世博会的108个摄像机拍摄的1132个视频序列,人数由1到253人不等。
3)公交车视频。该数据库包含来自公交车上前后两个固定摄像头拍摄的7个监控视频,共计近15000幅图像,人数由0到25人不等。
3.3 模型评估
3.3.1 自适应人形核有效性测试
不同核函数在公共数据库上的计数结果如表2所示。显而易见,自适应人形核比其他核函数有较好的效果,尤其在拥挤的UCF_CC_50数据库上效果显著。
3.3.2 多尺度策略有效性测试
如表3所示,通过对网络三个通道的不同尺度与多尺度改进策略在公共数据库上的计数结果比对,不难发现,多尺度策略比单一尺度具有明显的改进效果。
3.4 UCF_CC_50数据库评估
一些典型的密度估计结果如图5所示。图5中第一行表示原始人群图像,第二行表示密度图真实值,第三行表示估计的密度图。总的来说,估计的密度图大致接近真实密度图的分布和强度(真实密度图由公共数据库提供的标签值生成),表明构建的网络在剧烈的尺度变化和不均匀密度分布下同样可以预测拥挤人群的数量。图5(a)真实值1566人,估计值1525人;图5(b)真实值1543人,估计值1823人;图5(c)真实值3406人,估计值2807人。不难发现,图5(c)中估计密度图与真实值有明显的偏差。通过比较原图发现某些特定区域人群过于模糊,导致网络无法有效捕获信息。
在UCF_CC_50数据库上与其他方法的实验结果对比如表4所示。Zhang等[17]通过三个不同的CNN通道学习不同大小的特征;Ooro-Rubio等[12]采用多尺度非线性回归模型解决尺度不一问题,但无法适应人群分布不均的场景,鲁棒性较差;Sindagi等[18]提出级联多任务卷积神经网络,同时估计密度等级和密度估计,取得较低的MAE值;本文方法不仅考虑尺度问题,同时使用多任务学习方式联合人群密度等級划分与密度图估计,并以一种新颖的自适应人形核模拟密集、稀疏场景下的人群分布,生成更贴合真实场景的人群密度图,故在MAE值和MSE值上均达到最较佳性能。
3.5 World Expo10数据库评估
一些典型的密度估计结果如图6所示。图6(a)真实值24人,估计值30人;图6(b)真实值214人,估计值220人;图6(c)真实值74人,估计值79人。图6(a)中错将栏杆检测为行人,表明该网络未能将背景与前景区分,这也是今后工作的重点之一。
在World Expo10数据库上与其他较新方法的实验结果对比如表45所示。本文提出的网络受Zhang等[11]的启发,在多列CNN网络[17]基础上添加多任务学习机制,取得更小的MAE值,达到目前方法最较优性能。
3.6 真实公共汽车数据库评估
公共汽车数据库人群图像示例如图7所示。
某场景下预测人数与真实人数对比如图8所示。显然网络能基本预测真实场景下人群个数,误差约0~3人。通过观察可以发现,真实场景下的视频转换获得的图片清晰度较差且背景干扰较大,且在车尾摄像头拍摄的场景下由于车后半部分台阶影响,存在严重的遮挡。尽管实验中对图像的透视畸变进行矫正[26],但对车尾台阶上的人仍不太适用,这也是今后工作的重点之一。
4 结语
本文提出一种自适应人形核模拟不同密度情况下的人群分布状况,与传统核函数对比,表明自适应人形核更能生成贴合真实场景人群分布的密度图。通过采用三个不同通道处理不同尺度样本,解决了尺度不一问题;以多任务学习联合估计密度图与人群密度等级,解决了人群分布不均问题;然后利用一种加权损失函数提高估计的密度图的精度,进而提高了人群预测准确率;最后,在基准数据库上与较新的人群计数方法进行了对比。实验结果表明本文方法具有较高的计数性能,同时在真实公共汽车数据库上预测人数,验证了该方法的实用性良好。
参考文献 (References)
[1] RYAN D, DENMAN S, SRIDHARAN S, et al. An evaluation of crowd counting methods, features and regression models [J]. Computer Vision and Image Understanding, 2015, 130(C): 1-17.
[2] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part-based models [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[3] GAO C, LIU J, FENG Q, et al. People-flow counting in complex environments by combining depth and color information [J]. Multimedia Tools and Applications, 2016, 75(15): 9315-9331.
[4] LUO J, WANG J, XU H, et al. Real-time people counting for indoor scenes [J]. Signal Processing, 2016, 124: 27-35.
[5] ANTIC B, LETIC D, CULIBRK D, et al. K-means based segmentation for real-time zenithal people counting[C]// Proceedings of the 2009 16th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2009: 2565-2568.
[6] RAO A S, GUBBI J, MARUSIC S, et al. Estimation of crowd density by clustering motion cues [J]. The Visual Computer, 2015, 31(11): 1533-1552.
[7] CHAN A B, LIANG Z S J, VASCONCELOS N. Privacy preserving crowd monitoring: counting people without people models or tracking[C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2008: 1-7.
[8] 姬丽娜,陈庆奎,陈圆金,等.基于GPU的视频流人群实时计数[J].计算机应用,2017,37(1):145-152.(JI L N, CHEN Q K, CHEN Y J, et al. Real-time crowd counting method from video stream based on GPU[J]. Journal of Computer Applications, 2017, 37(1): 145-152.)
[9] HASHEMZADEH M, FARAJZADEH N. Combining keypoint-based and segment-based features for counting people in crowded scenes[J]. Information Sciences, 2016, 345: 199-216.
[10] SIVA P, SHAFIEE M J, JAMIESON M, et al. Scene invariant crowd segmentation and counting using scale-normalized Histogram of Moving Gradients (HoMG)[J]. ArXiv Preprint, 2016, 2016: 1602.00386.
[11] ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 833-841.
[12] OORO-RUBIO D, LPEZ-SASTRE R J. Towards perspective-free object counting with deep learning[C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 615-629.
[13] HU Y, CHANG H, NIAN F, et al. Dense crowd counting from still images with convolutional neural networks[J]. Journal of Visual Communication and Image Representation, 2016, 38: 530-539.
[14] SHENG B, SHEN C, LIN G, et al. Crowd counting via weighted VLAD on dense attribute feature maps[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 28(8): 1788-1797.
[15] KANG D, DHAR D, CHAN A B. Crowd counting by adapting convolutional neural networks with side information[J]. ArXiv Preprint, 2016, 2016: 1611.06748.
[16] 時增林,叶阳东,吴云鹏,等.基于序的空间金字塔池化网络的人群计数方法[J].自动化学报,2016,42(6):866-874.(SHI Z L, YE Y D, WU Y P, et al. Crowd counting using rank-based spatial pyramid pooling network[J]. Acta Automatica Sinica, 2016, 42(6): 866-874.)
[17] ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 589-597.
[18] SINDAGI V A, PATEL V M. CNN-based cascaded multi-task learning of high-level prior and density estimation for crowd counting[C]// Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway, NJ: IEEE, 2017: 1-6.
[19] MARSDEN M, MCGUINNESS K, LITTLE S, et al. ResnetCrowd: a residual deep learning architecture for crowd counting, violent behaviour detection and crowd density level classification[C]// Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway,NJ:IEEE, 2017: 1-7.
[20] ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 589-597.
[21] ZEILER M D, RANZATO M, MONGA R, et al. On rectified linear units for speech processing[C]// Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2013: 3517-3521.
[22] WANG T, LI G, LEI J, et al. Crowd counting based on MMCNN in still images[C]// Proceedings of the 2017 Scandinavian Conference on Image Analysis. Berlin: Springer, 2017: 468-479.
[23] FU M, XU P, LI X, et al. Fast crowd density estimation with convolutional neural networks [J]. Engineering Applications of Artificial Intelligence, 2015, 43: 81-88.
[24] IDREES H, SALEEMI I, SEIBERT C, et al. Multi-source multi-scale counting in extremely dense crowd images[C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 2547-2554.
[25] KANG D, MA Z, CHAN A B. Beyond counting: comparisons of density maps for crowd analysis tasks — counting, detection, and tracking [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2017, PP(99):1-1.
[26] 覃勛辉,王修飞,周曦,等.多种人群密度场景下的人群计数[J].中国图象图形学报,2013,18(4):392-398.(QIN X H, WANG X F, ZHOU X, et al. Counting people in various crowed density scenes using support vector regression[J]. Journal of Image and Graphics, 2013, 18(4):392-398.)
