基于云雾协作模型的任务分配方法
2019-08-01刘鹏飞毛莺池王龙宝
刘鹏飞 毛莺池 王龙宝

摘 要:针对在云雾协作下实现移动用户任务请求的合理分配与调度的问题,提出了一种基于云雾协作模型的任务分配算法——IGA。首先,采用混合编码的方式对个体进行编码,并采用随机的方式产生初始种群;其次设定服务商的花费作为目标函数;然后进行选择、交叉、变异操作产生出符合条件的新个体;最后,根据染色体中的任务请求类型分配到相应的资源节点上,并更新迭代计数器,直到迭代完成。仿真结果表明,在处理移动用户请求时,与传统的云模型相比,云雾协作模型在时延上降低了近30s,服务水平目标(SLO)违规率上降低了约10个百分比,在服务提供商花费上亦有所减少。
关键词:云计算;雾计算;任务分配;任务调度;遗传算法
中图分类号: TP393.027
文献标志码:A
Abstract: To realize reasonable allocation and scheduling of mobile user task requests under cloud and fog collaboration, a task assignment algorithm based on cloud-fog collaboration model, named IGA (Improved Genetic Algorithm), was proposed. Firstly, individuals were coded in the way of mixed coding, and initial population was generated randomly. Secondly, the objective function was set as the cost of service providers. Then select, cross, and mutate were used to produce new qualified individuals. Finally, the request type in a chromosome was assigned to the corresponding resource node and iteration counter was updated until the iteration was completed. The simulation results show that compared with traditional cloud model, cloud-frog collaboration model reduces the time delay by nearly 30 seconds, reduces Service Level Objective (SLO) violation rate by nearly 10%, and reduces the cost of service providers.
Key words: cloud computing; fog calculating; task allocation; task scheduling; Genetic Algorithm (GA)
0 引言
隨着网络边缘设备数量的迅速增加,边缘设备产生的数据量越来越大,已经达到了泽字的级别。根据国际电信联盟(International Telecommunication Union-Telecommunication Sector, ITU-T)的报告显示,到2020年,每人每秒将会产生1.7MB的数据[1],显然人类已经进入了大数据时代。集中式的云已经不能高效处理边缘设备产生的海量数据[2]。雾计算是对云计算的延伸,它是在终端节点和远端云之间再扩展的一层,也可以叫边缘网络层。在物联网应用中有些请求的处理并不需要放到远端的云,而是可以直接在距离用户较近的雾端进行处理。图1是一个简单的雾计算架构图[3],底层是物联网设备层,该层由移动终端(如智能手机、平板电脑等)组成,主要用于信息收集;中间层是雾计算层,该层主要是由雾设备(如路由器、网关、小型服务器等)组成,这些雾设备通常具有一定的处理能力来完成部分任务处理;上层是云数据中心层,该层主要是由云服务器组成,云服务器用来分析和处理大量数据。基于这种架构模式,雾计算具有低延迟、移动性支持、位置感知等[2]特征。
雾计算将云提供的服务扩展到网络边缘来提供本地化的服务,这有效满足了移动用户对低时延、移动性支持、位置感知的服务需求(架构如图1);然而移动用户的任务请求并非完全是基于本地化的,也可能需要发送到云端进行处理,为此云雾协作的服务模式应运而生。现有的针对云雾协作服务模式的研究已经取得了一些成果,但是仍然存在不足。首先,当前研究在云雾协作模式下分配任务请求时未能有效判断任务请求的类型;其次,当前研究在分配任务请求时通常采用静态分配资源的方式,未能动态给任务分配资源,而这些不足可能会给用户造成高时延的不良体验。针对此问题,本文提出了基于云雾协作模型的任务分配算法。该算法能够判断任务请求的类型,动态在云雾资源节点上进行分配。在云雾协作模型下分配任务请求时以该算法作为分配策略并以服务提供商花费作为目标函数展开研究。实验结果表明,与传统云模型相比,云雾协作模型在处理移动用户请求时在时延上降低了近30s,服务水平目标(Service Level Objective, SLO)违规率上降低了10%左右,在服务提供商花费上亦有所减少。
1 相关工作
目前基于雾计算的研究还处于发展阶段,关于雾端的任务分配与调度还是一个较新的研究热点。吴翠云等文献[4]中文献4的作者姓名不是这个名字,请调整语句引用,注意在正文中要按照文献的先后顺序进行引用针对物联网检测节点的原始数据如何高效地处理问题,提出“云+雾”的分级运算模式。雾端资源节点接收到原始数据时会判断这些数据是否能够在本地处理完成,若能够在本地处理完成,则采用分布式计算的方式处理数据,最后反馈给被控终端;若不能够在本地处理完成,则将分析处理后的数据交给远端的云服务器,由云服务器再次进行处理,之后将处理结果反馈到雾端,由雾端调整被控终端。Deng等[5]针对云雾计算环境中的能耗和时延问题,提出将能耗和时延问题分为三个子问题并通过现有的优化技术进行解决。第一个子问题是在雾计算子系统中优化功耗和时延,为了解决这个问题,文献[6]中采用了凸优化技术。第二个子问题是一个整数非线性规划问题,致力于在云环境中优化功耗和时延。为了解决这个问题,文献[7]中采用了非线性的整数规划方法。第三个子问题是最小化数据从雾节点到云服务器的传输延迟,针对这个问题,文献[8]中采用了匈牙利方法。Song等[9]提出一个基于图分区的雾计算任务负载平衡机制。根据终端任务请求所需的资源级别将任务分配给单个或多个虚拟资源节点。虚拟资源节点通过图分区向终端用户提供服务。Cardellini等[10]评估了雾计算环境中的分布式服务质量调度器,该调度器主要包括工作监视器、服务质量(Quality of Service, QoS)监视器、自适应调度器。其中:工作监视器负责获取雾节点上计算组件传入和传出的数据;QoS监视器负责估计QoS参数(例如网络等待时间);自适应调度器周期性地运行,负责检查每个计算组件要执行的任务。Oueis等[11]为了提高用户的体验质量,对雾计算环境中的负载均衡问题进行了研究。文献[12]中提出了一种改进的遗传算法(Genetic Algorithm, GA),用于处理雾端的任务调度和减少CPU执行时间,实验结果表明该算法在雾端调度时间紧迫型任务时要优于传统的基本遗传算法(Simple Genetic Algorithm, SGA)。本文与其不同的是初始种群随机生成,采用了不同的交叉变异概率参数以及可以动态地进行任务分配,并提出了一种可应用的实际场景。在雾计算架构中任务调度、管理和操作的目的是为移动用户提供一个高效、低成本的服务。文献[13]中提出一个新的生物启发式优化算法,该算法在问题空间搜索最优解的过程中引入了遗传算法中的选择、交叉操作,这有效扩大了基因的多样性,使得算法具有了更强的全局搜索能力。实验结果表明,在雾端资源节点分配任务请求时该算法能够获得更短的执行时间以及更少的内存消耗。
以上研究工作更多考虑的是任务在调度过程中的时延、能耗、网络延迟等问题,并没有考虑更多服务质量的问题。文献[14]中针对用户任务请求在虚拟机上的分配问题,提出一种资源分配算法,该算法的思想是当用户请求到达时优先将请求分配到能够满足用户需求的最小空间上处理,目的是减少空间浪费以及服务等级协议(Service-Level Agreement, SLA)违规。文献[15]中针对用户在多维QoS方面的需求,提出QBD-Sufferage(请补充QB-Sufferage的英文全称Quality of service Deadline-Sufferage)算法,该算法在传统Sufferage算法基础上引入了效益函数和QoS约束。实验结果表明QBD-Sufferage算法要比传统Sufferage算法获得更高的效益值。文献[16]中指出QoS约束对于雾计算来说非常重要,其约束指标主要包括时间、可靠性、连接性、网络带宽、存储容量。
2 问题陈述
2.1 问题陈述
在雾计算架构下移动用户的成本开销与CPU的执行时间成正比,所以为了减少移动用户的成本开销,则需要通过优化雾资源节点上的任务分配来减少CPU的执行时间。在雾计算环境中任务请求分配与调度本质上是一种优化类问题,很难在问题空间中搜索到全局最优解。随着资源节点和终端任务请求数的急剧增加,传统的任务分配与调度算法已经不能够很好地满足实际应用的需求,一些群智能分配算法逐渐被引入,常见的群智能算法有遗传算法、模拟退火算法、蚁群算法等。本文中使用了遗传算法的相关知识。传统遗传算法作为一个经典的任务分配算法能够有效地在雾端资源节点上分配任务请求,但是容易出现早熟现象,陷入局部最优[17],无法在问题空间搜索到较好的分配结果。
2.2 遗传算法
SGA主要特点是直接对结构对象進行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则[18],即通过对生物繁殖和进化过程中染色体的选择、交叉、变异等操作的模仿来完成对问题空间最优解的寻找[19]。SGA的整体流程如图2所示。
SGA具有如下特点。
1)并行性。SGA与其他优化算法最大的不同在于求解过程。SGA在求解过程中是从问题空间中的一个解集开始而并非一个单一的解,因此SGA具有一定的并行性以及搜索的随机性。
2)自适应性。SGA在求解的过程中根据适应度函数值的大小来决定个体进化的概率,适应度值越大个体被保留下来的概率越大,适应度值越小个体被保留下来的概率越小,因此SGA具有一定的自适应性。
3)易扩展性。SGA是其他改进遗传算法的原型和基础,经过简单改进便可以和其他算法结合使用,因此SGA具有很强的易扩展性。
4)简单性。SGA模仿生物遗传进化的思想,易于理解,因此便于应用在大量实际问题求解的过程中。
SGA虽然具有很多优点,但是也存在一些待改进的地方。一方面,算法在寻找简单函数最优解的过程中易出现“早熟现象”即局部收敛现象;另一方面,算法在迭代过程中易出现大量冗余迭代。
3 基于云雾协作模型的任务分配方法
3.1 算法思路
针对上述问题,本文在传统遗传算法的基础上作了进一步研究,提出了基于云雾协作模型的任务分配算法——IGA(Improved Genetic Algorithm)。IGA在基本遗传算法SGA基础上作了进一步优化。该任务分配算法在SGA中引入了请求类型判断策略,在变异操作之后对任务请求类型进行判断。该算法会根据任务请求的类型,动态地将任务请求分配到云雾资源节点上。
3.2 云雾协作模型
本文以大型赛事活动为例来讲述传统云模型和云雾协作模型的区别。在大型赛事活动中,移动用户的查询请求更多倾向于赛事活动相关内容或者赛事活动周边的超市、餐馆等信息。假设赛事活动现场的移动用户发出查询请求,若使用传统云计算服务模型[20]来处理移动用户请求,那么活动主办方首先需要将赛事活动相关信息上传到远端的云服务器,然后移动用户和云数据中心建立一个长距离的通信连接,最后检索内容、处理请求。若使用图3云雾协作服务模型[20]来处理移动用户请求,则可以有效缩短通信距离。活动主办方可以在大型赛事活动内部署本地站点,预先缓存本地的内容,通过这种方式移动用户可以享受高速率的本地连接而无需和远端的云进行通信,除非移动用户的查询请求不能基于本地化的雾实现时,才需要和远端的云进行通信。本地站点即本地雾计算信息系统,它可以通过部署在赛事活动现场不同地方的雾服务器共同形成。不同地方的雾服务器可以预先缓存特定内容,然后通过WiFi为移动用户提供精确的基于位置的服务。
在使用图3所示的云雾协作服务模型处理移动用户请求时,可以给移动用户带来两个直接的优势:
1)通过雾系统处理用户本地请求可以降低服务延迟;
2)通过本地连接查询内容的方式可以降低使用带宽的成本。
3.3 云雾协作模型下任务分配
以上面提到的大型赛事活动为例,移动用户的任务请求倾向于是赛事活动的相关信息或者活动现场周边的商店、餐馆等信息,但也可能是非本地化的查询请求,需要和远端的云进行通信,那么采用图3所示的云雾协作服务模型处理移动用户请求的步骤如下:
1)移动用户提交任务请求到近端雾计算资源节点。
2)雾计算资源节点提交任务请求相关参数到远端云数据中心资源管理节点。
3)云数据中心资源管理节点根据任务请求相关参数以及分配策略判断移动用户的请求类型,若请求类型是本地化的查询请求,则将任务请求分配到近端雾计算资源节点;否则分配到远端云计算资源节点,最后找到最优任务请求分配结果。
4)云数据中心资源管理节点将最优任务请求分配结果反馈到雾端。
5)雾端根据最优分配结果将非本地的任务请求发送到云数据中心。
6)雾计算资源节点根据最优分配结果执行本地化的任务请求。
7)云计算资源节点根据最优分配结果执行非本地化的任务请求。
8)云数据中心将任务请求执行结果反馈到雾端。
9)雾系统汇总处理结果,响应移动用户。
任务请求分配模型如图4所示。
3.4 任务分配算法
基于云雾协作模型的任务分配算法包括以下9个部分,各部分的规则设计如下。
1)对个体进行编码。本文采用文献[21]中的编码方式,染色体的长度等于任务请求数量的两倍。如果任务的请求数目为m,则每一条染色体的有2×m个基因。其中前m个基因表示雾计算资源节点情况,后m个基因表示任务请求的分配顺序。假设一条染色体为51234521234567,则任务请求和雾计算资源节点之间的对应关系如表1所示,从表1中可以看出终端任务请求1和6分配到了雾计算资源节点5上,任务请求2分配到了雾计算资源节点1上,任务请求3和7分配到了雾计算资源节点2上,任务请求4分配到了雾计算资源节点3上,任务请求5分配到了雾计算资源节点4上。
2)初始种群生成。该算法中的初始种群采用随机的方式生成,并且根据约束条件选择有效方案。假设初始种群g(0),设定迭代计数器i=0,g(i)表示第i代种群。具体约束条件参考以下两个方面:
①不能将所有任务请求分配到同一个雾计算资源节点上,造成严重负载不均。
②同一个任务请求不能被分配到不同的资源节点上处理,但是一个资源节点上可以处理多个任务请求。
生成初始种群的伪代码如下。
3)計算个体适应度值。在雾计算架构下移动用户任务请求分配过程中,适应度函数是评价群体进化方向的关键,也是执行遗传算法“优胜劣汰”的主要依据。这里以服务提供商的花费作为目标函数。
4)终止条件判断。当进化代数达到规定迭代次数I时,输出结果;否则转到步骤5)。
5)选择操作。在本算法中通过一种选择操作,将优良个体的特性遗传到下一代个体中,以体现“优胜劣汰”的原则,该算法中的选择操作采用了一种基于轮盘赌算法的方式来进行。具体步骤如下。
①根据适应度函数公式计算出所有个体适应度值,累计求出适应度值总和。
②计算出每个个体即每个染色体被选择的概率,概率公式如式(1)所示:
其中:pi代表每个染色体的被选择概率, f代表适应度计算公式,M代表染色体个数。
③将每个概率值组成一个区域,所有概率值之和为1。
④随机产生一个(0,1)区间上的随机数,根据该随机数出现在上述哪个概率区来确定哪个个体被选中。
例如,假设轮盘被分成了四份,第一个个体所占的比例为24%,第二个个体所占的比例为23%,第三个个体所占的比例为18%,第四个个体所占的比例为35%,则第一个个体构成的区间是(0,0.24],第二个个体构成的区间是(0.24,0.47],第三个个体构成的区间是(0.47,0.65],第四个个体构成的区间是(0.65,1)区间表达仍不规范,如在等于0.24时,属于哪个区别,请用闭区间来表示,类似于“(0,0.24]”、“(0.24,0.47]”的表达。四处均要修改这四处遗漏了区间表达,请用开闭区间来彼此区分。对于四个区间的修改,依次分别为:(0,0.24],(0.24,0.47],(0.47,0.65],(0.65,1)。。如果随机产生的随机数为0.23,那么该次选择的个体是第一个;如果随机产生的随机数为0.28,那么该次选择的个体是第二个,以此来确定个体被选中的次数,更加直观的描述如图5轮盘所示。
6)交叉操作。交叉操作是实现基因重组的主要手段,类似于生物学有性繁殖的过程,使不同的个体基因片段相互交换,产生新的个体。本文针对不同的队列采用不同的交叉方式,每个队列会产生对应的一个新的个体,最后把两个队列对应的新个体合并,形成一个完整的新个体。其中资源队列采用单点交叉,交叉点位置随机产生;任务队列采用部分匹配交叉,随机产生交叉点。对于新产生的个体检查是否符合约束条件,如果不符合则摒弃,重新进行交叉,直至新个体满足约束条件。
交叉操作伪代码如下。
7)变异操作。基因突变是实现染色体内部基因改变的有效手段。与交叉操作类似,针对不同的队列采用不同的变异方式,最后把两个队列产生的新个体合成一个完整的新个体,并对新个体进行约束条件的检查。如果不符合约束条件则摒弃,重新进行变异操作,直至新个体符合约束条件。其中资源队列采用的变异方法为随机操作,即随机选取变异的基因位置,让其等位基因来替换;任务请求队列采用的变异方法为设定发生变异基因的位数Z(Z为整数),随机选取变异点,以变异点为起点,对其随后的Z个基因采用完全排列组合方式产生出新个体。
变异操作伪代码如下:
8)请求类型判断。判断变异后染色体后半部分任务请求的类型,若请求类型是近端相关内容,则将相关请求分配到近端雾计算资源节点;否则分配到云计算资源节点。
9)更新迭代计数器。迭代计数器i=i+1,转到步骤3)。
3.5 目标函数
云雾协作模型下的任务分配是指在一个特定的云雾环境中,根据一定的分配策略,尽可能地满足移动用户的需求,同时最小化服务提供商的花费。本文算法中的目标函数主要考虑的是服务提供商的花费,该花费主要包括云雾计算资源节点处理终端任务请求的花费和SLO违规时的惩罚两个方面。SLO作为SLA具体可测量的特征,包括可用性、响应时间、质量等,它可以量化服务提供商的服务水平。SLO违规率越低,则用户满意度越高。
1)SLO违规惩罚函数。设Penalty此处遗漏了一个字符,请补充表示发生SLO违规的总惩罚花费,则违规惩罚函数定义如式(2)所示:
其中:k表示因为服务超时而发生SLO违规的请求序号,tstopk表示第k个请求的实际响应时间,tdeadlinek表示第k个请求在SLO规定中的请求截止响应时间,q表示发生SLO违规的请求总个数,γk表示第k个发生SLO违规的请求基本惩罚,η表示因发生超时而导致的单位时间惩罚。
2)云雾计算资源节点花费函数。设vm表示云雾计算资源节点处理请求的总花费,则云雾计算资源节点花费函数定义如式(3)所示:
其中:n表示云端和雾端虚拟资源的类型总个数,Pvmi, j表示类型为i的虚拟资源节点中序号为j的虚拟资源节点运行的单价成本,vmci表示第i个类型的计算资源处理请求的总花费,ti, j表示类型为i的虚拟资源节点中序号为j的虛拟资源节点处理请求所花费的时间,Mi表示类型为i的虚拟资源节点的个数。
综上有服务提供商总花费函数。设cost表示服务提供商总花费,则总花费函数定义如式(5)所示:
3.6 判断策略
基于云雾协作的任务分配算法在变异操作之后判断终端任务请求类型,若请求类型是基于位置感知的近端相关内容,则将相关请求分配到近端雾计算资源节点进行处理;否则分配到云计算资源节点进行处理。具体任务请求判断策略如下。
判断变异后染色体的后半部分任务请求类型,请求类型分为两种。
1)若请求类型是本地的雾端请求,则进一步判断其对应的资源节点,如果对应的资源节点是雾端资源则不作处理,如果不是雾端资源,则将该资源节点突变为能够使得当前雾端完成时间最短的雾资源节点。
2)若请求类型是非本地的云端请求,则进一步判断其对应的资源节点:如果对应的资源节点是云端资源则不作处理;如果不是云端资源,则将该资源节点突变为能够使得当前云端完成时间最短的云资源节点。
例如,对于变异后的染色体
其中前六位数中的1、2、3、4、5表示五个资源,设4、5表示雾端资源,1、2、3表示云端资源,后面六位数1、2、3、4、5、6表示六个任务请求,设1、2、3、4表示雾端任务请求,5、6表示云端任务请求。
对于上面的染色体X,任务请求和资源节点的对应关系如表2所示,任务请求1分配到了云资源节点1上,任务请求2分配到了雾资源节点5上,任务请求3和6分配到了雾资源节点4上,任务请求4分配到了云资源节点3上,任务请求5分配到了云资源节点2上。显然有些雾端的任务请求并没有被分配到雾端资源节点上,所以对于没有被分配到雾端的任务请求让其对应的云端资源节点突变为能够使得当前雾端完成时间最小的资源节点。对于没有分配到云端的任务请求以同样的方式处理。
4 实验及其结果分析
4.1 实验设置
仿真实验环境设置:仿真软件CloudSim3.0.2;处理器Intel core i5-4210M CPU @2.60GHz;内存12GB;操作系统Windows 10旗舰版;开发工具MyEclipse8.5、JDK1.7.0_15;开发语言Java。
终端任务请求由系统模拟产生,其个数设置为100~1000,长度设置为500~15000MI。资源节点数设置为6,其中4个为云计算资源节点,2个为雾计算资源节点,云计算和雾计算资源节点参数如表3,表3中单价参考文献[22]来设置。违规基本惩罚设置为2,单位时间惩罚设置为5。IGA各参数设置如表4所示。
4.2 实验结果
本文对传统云模型下采用的IGA任务分配算法CLOUD-IGA、轮询调度算法(Round-Robin Scheduling Algorithm,RRSA)CLOUD-RRSA以及云雾协作模型下采用的该任务分配算法FOG-IGA进行仿真实验。首先作了FOG-IGA、CLOUD-IGA以及CLOUD-RRSA的时延对比实验;其次作了FOG-IGA和CLOUD-IGA的SLO违规率、服务提供商花费对比实验。其中IGA在传统云模型下分配任务请求时不考虑任务请求类型判断。为了实验结果的有效性,CLOUD-IGA分配策略和FOG-IGA分配策略均以10次运行结果的平均值作为最终实验结果。
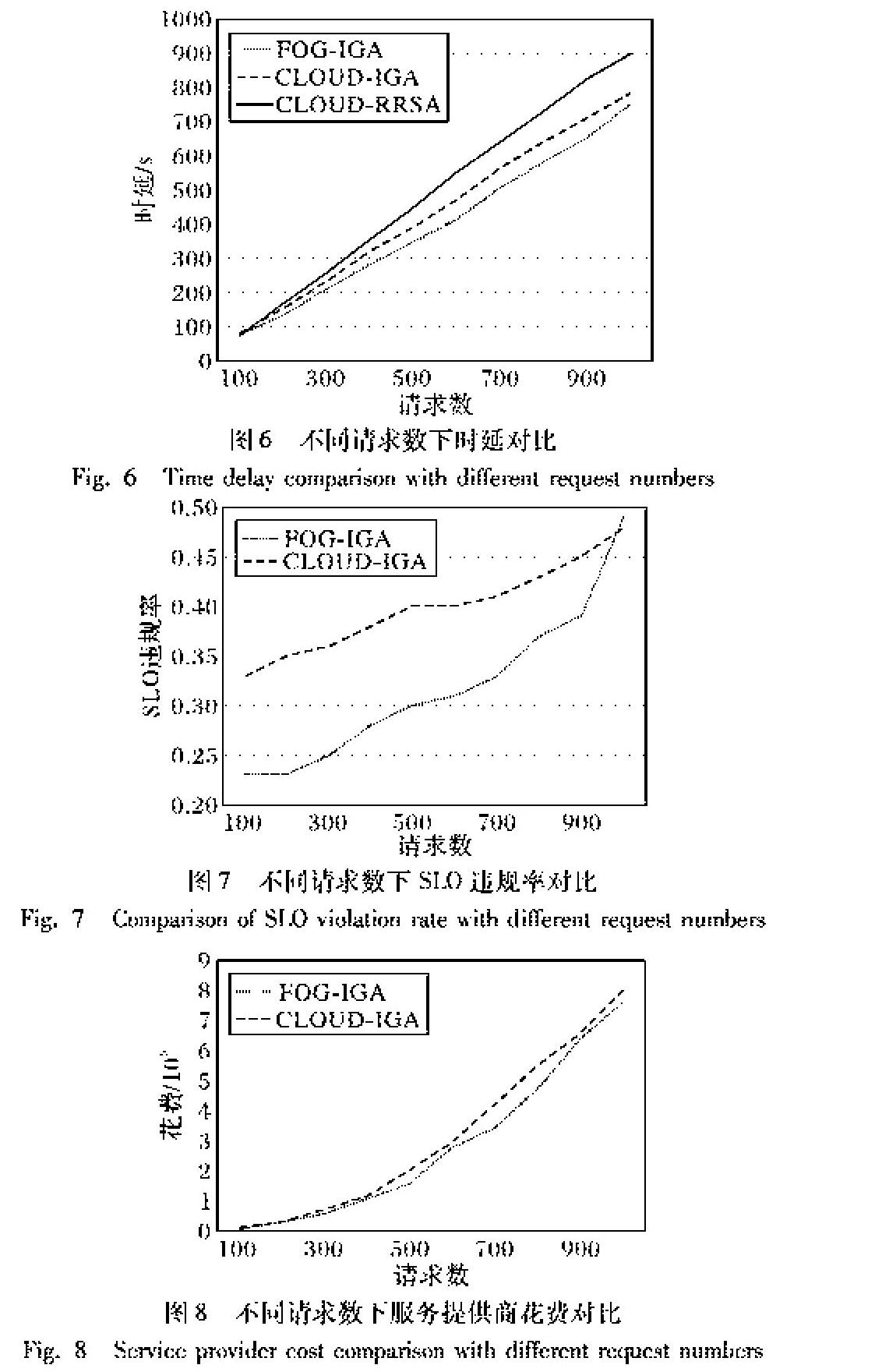
通过设置不同的终端请求数来比较FOG-IGA、CLOUD-IGA以及CLOUD-RRSA的时延。实验结果如图6所示。
观察图6可以发现随着终端请求数的变化,与CLOUD-IGA和CLOUD-RRSA方法相比,FOG-IGA在时延上具有优势。主要是因为FOG-IGA将本地化的请求分配到了近端雾计算资源节点上进行处理,而CLOUD-IGA和CLOUD-RRSA完全将用户请求分配到远端的云进行处理,没有判断用户请求的类型,所以在时延上较高。在云端分配任务请求时CLOUD-IGA整体优于CLOUD-RRSA,主要是因为该算法模拟了生物遗传和进化机制,在问题空间中通过多次迭代搜索到了较好的分配结果。FOG-IGA和CLOUD-IGA在时延上并没有很大的差距,主要是因为雾端资源节点的处理能力相对较弱,但其接近终端用户的特点对于处理本地化的请求还是具有一定优势。
实验2 SLO违规率及服务提供商花费对比实验。
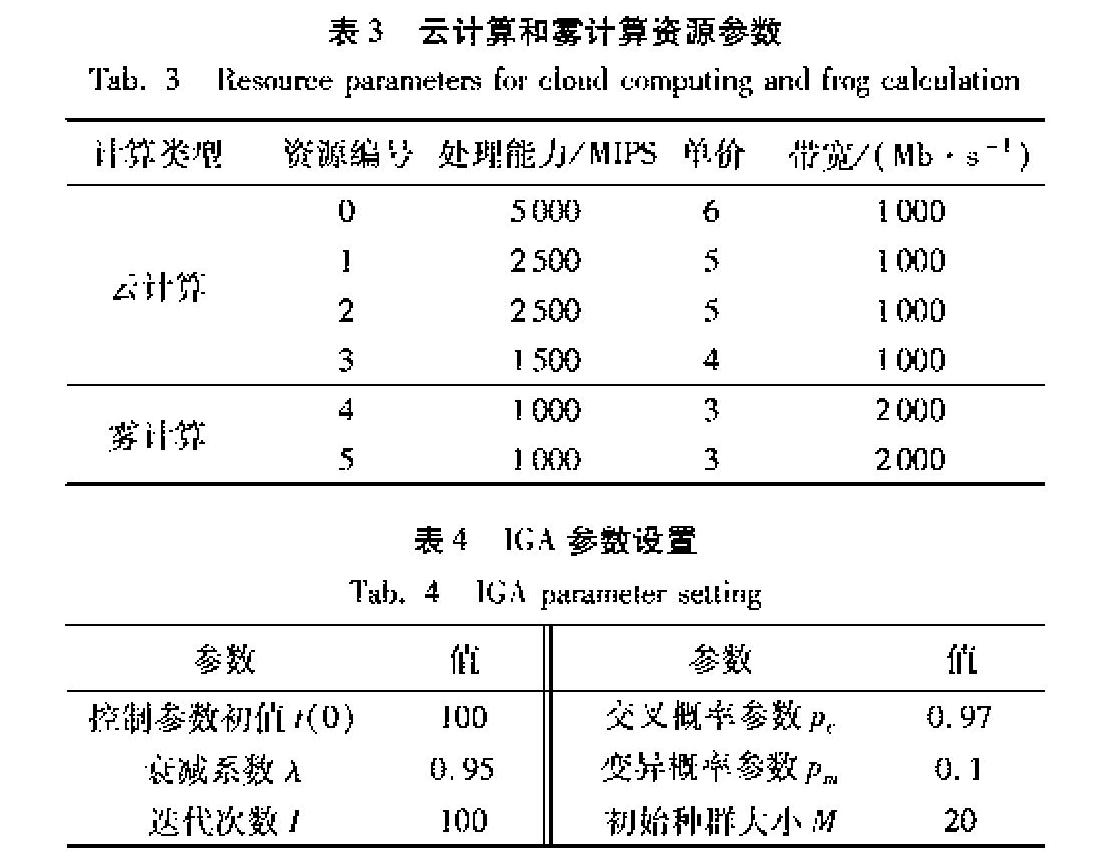
通过设置不同的终端请求数来比较FOG-IGA和CLOUD-IGA的SLO违规率以及服务提供商花费。实验结果如图7~8所示。
从图7可以看出,FOG-IGA在违规率方面整体上低于CLOUD-IGA,主要是因为FOG-IGA在分配任务请求时考虑了用户请求的类型,将本地化的请求分配到了近端雾资源节点,非本地化的请求分配到了远端云资源节点,这有效缩短了响应时间,所以降低减少了SLO违规;但是在任务请求数达到1000时SLO违规率突然变高,可能原因是本地化的请求较多,而雾资源节点处理能力不足,导致部分任务请求不能在规定时间内完成。CLOUD-IGA在SLO违规率上较高,主要是因为该分配策略没有判断任务请求的类型,完全将用户请求在距离用户较远的云端进行分配,增加了响应时间。
从图8可以看出,FOG-IGA在服务提供商花费方面整体上也低于CLOUD-IGA,主要原因有两个:
1)该分配策略整体违规率较低,在服务提供商花费函数中违规率越低,SLO违规时的惩罚就越少;
2)雾端资源节点单位时间的费用较低,该分配策略将本地化的任务请求分配到了近端雾资源节点。
文中服务提供商的花费主要包括云雾资源节点处理终端任务请求的花费和SLO违规时的惩罚两个方面,而FOG-IGA有效降低了这两个方面的花费,所以在总花费上有所降低。
综合上述实验结果可见,雾端资源节点对于处理一定量的本地化请求具有明显优势,但是随着本地化任务请求数的增多其优势可能会不那么明显,甚至不如远端的云。
5 结语
本文针对移动用户的不同请求在云雾资源节点上的分配问题,提出了基于云雾协作的任务分配算法。在云雾协作模型下分配任務请求时以该算法作为分配策略展开研究。仿真实验结果表明在处理移动用户请求时,与传统云模型相比,云雾协作模型在时延上降低了近30s,SLO违规率上降低了约10个百分比,在服务提供商花费上亦有所减少。
参考文献 (References)
[1] The World Telecommunication Standardization Assembly. ITU.WTSA-16: setting the standard[R]. Yasmine Hammamet: WTSA-16, 2016: 1-9.
[2] CHIANG M, ZHANG T. Fog and IoT: an overview of research opportunities[J]. IEEE Internet of Things Journal, 2017, 3(6): 854-864.
[3] SARKAR S, MISRA S. Theoretical modelling of fog computing: a green computing paradigm to support IoT applications[J]. IET Networks, 2016, 5(2): 23-29.
[4] 北京物联远信息技术有限公司.一种面向物联网的雾计算架构:中国,201511019375.3[P].2016-05-25. (Beijing Wulianyuan Information Technology Co., Ltd. A fog computing architecture for the Internet of Things: China, 201511019375.3 [P].2016-05-25.)
[5] DENG R, LU R, LAI C, et al. Optimal workload allocation in fog-cloud computing towards balanced delay and power consumption[J]. IEEE Internet of Things Journal, 2016, 3(6): 1171-1181.
[6] HE J, CHENG P, SHI L, et al. Time synchronization in WSNs: a maximum-value-based consensus approach[J]. IEEE Transactions on Automatic Control, 2014, 59(3): 660-675.
[7] LI D, SUN X L. Nonlinear Integer Programming[M]. Berlin: Springer, 2006: 70-82.
[8] KUHN H W. The Hungarian method for the assignment problem[J]. Naval Research Logistics, 2010, 52(1): 7-21.
[9] SONG N N, GONG C, AN X S, et al. Fog computing dynamic load balancing mechanism based on graph repartitioning[J]. China Communications, 2016, 13(3): 156-164.
[10] CARDELLINI V, GRASSI V, PRESTI F L, et al. On QoS-aware scheduling of data stream applications over fog computing infrastructures[C]// Proceedings of the 2015 IEEE Symposium on Computers and Communication. Piscataway, NJ: IEEE, 2016: 271-276.
[11] OUEIS J, STRINATI E C, BARBAROSSA S. The fog balancing: load distribution for small cell cloud computing [C]// Proceedings of the 2015 IEEE 81st Vehicular Technology Conference. Piscataway, NJ: IEEE, 2015:1-6.
[12] 韩奎奎,谢在鹏,吕鑫.一种基于改进遗传算法的雾计算任务调度策略[J].计算机科学,2018,45(4):137-142.(HAN K K, XIE Z P, LYU X. A fog computing task scheduling strategy based on improved genetic algorithm[J]. Computer Science, 2018,45(4): 137-142.)
