基于基因表达谱预测肿瘤浸润免疫细胞类型及比例的解卷积算法
2019-07-31裴晶晶余彩裙佘玉梅
裴晶晶,余彩裙,佘玉梅
( 云南民族大学 数学与计算机科学学院,云南 昆明 650500 )
肿瘤不仅仅是恶性细胞群,而且是由不同类型细胞组成的复杂生态系统.肿瘤细胞的子代具有无限增殖遗传特性,这种性质不顾正常免疫系统约束,给个体健康造成了致命的危险.肿瘤按是否转移可分为是良性肿瘤和恶性肿瘤.前者可通过手术切除达到治疗的目的,而后者则会在生物体的其它部位形成继发性(转移)肿瘤,散布在身体周围以及其他组织中,以至难以通过简单切除来进行有效的治疗.在针对恶性肿瘤治疗过程中,肿瘤浸润性免疫细胞在肿瘤控制和对治疗的反应中起重要作用[1-3],不同类型的肿瘤细胞的定量可以揭示抗癌应答的潜在机制,并有助于评估抗癌治疗过程中的整体效果,对后续深入治疗起到重要的指导作用.目前,利用流式细胞计数技术可以准确的定量肿瘤组织中免疫细胞的类型及比例,但是该方法需要大量的人力和实验成本.然而,利用计算的方法可以直接推断出复杂组织中的细胞类型及其比例,该策略具有快速、准确的特点,对肿瘤诊断、治疗以及机制的研究具有重要的意义.
目前,针对复杂组织细胞的鉴定和含量的计算方法均是围绕着反卷积策略来进行的.在过去几年中,一些已发表的反卷积算法试图解决逆向解决免疫细胞基因表达谱的任务. 如2010年Shen Orr[4]等提出了一种称为“CSSAM”的算法(微阵列的细胞类型特异性显著性分析),该算法的开发是基于传统的微阵列分析方法而忽略了样本细胞类型的组成.以至于无法准确区分基因表达与不同的细胞类型之间的关系.Buettner等在2015中提出了一种称为“SCLVM”的计算方法(单细胞潜变量模型),它使用潜变量模型来解释寻找新的细胞亚群.该技术允许在未分化的T细胞分化为T辅助细胞的过程中,识别与不同阶段对应的细胞的不可检测的亚群.Renaud Gaujoux已经出版了一个R包,CellMix,其包含了一些已发表的计算反卷积方法[4].纽曼等在2015年发表了一篇论文中展示了一种名为CIBERSORT的新开发工具,该工具通过使用适用于免疫细胞谱系中广泛细胞类型的支持向量机(SVM)算法的变体,其性能优于所有其他方法[5].与早期的算法(通常是线性方法)相比,这是一种全新的反卷积方法.尽管一些已发表的反卷积方法显示出不同表型细胞的一些有望的结果.但是,这些文章中仅限于对特定动物或人体特定部位的测试,如来自肝脏的肿瘤,或者甚至试图对远处相关的免疫细胞进行反卷积[6].这使得对彼此不同的方法进行基准测试变得非常困难.我们需要一种工具能够在性能和结果方面比较相同数据集上的各种技术.这样的数据集应该来自真实的组织,其中存在不同细胞和基因的确切数量,并且还可以掺入肿瘤和噪声以模拟来自肿瘤的真实样品.
1 样本数据准备及数据预处理
我们获取的数据包含2个方面:①真实的组织样本微阵列实验;②真实的组织样本RNA-Seq测序数据(见表1).我们利用上述数据集对本文反卷积算法与其他3种主流算法进行比较.其中对于真实组织来源的数据集,组织样本中细胞混合比例是已知的.另外,我们对采集到的数据作了如下预处理:①对于真实来源的微阵列实验数据,我们以2为底数对探针的信号进行对数转换,并采用R语言中的bioMart包将探针映射到对应的基因上.②对于真实来源的RNA-seq数据,我们将每个样品采用TPM进行标准化,然后将观察到的每个基因的read数目加1,并以2为底数进行对数转化.所有数据(真实组织来源和模拟数据)均采用分位数标准化策略进行归一化,以此消除批次或文库大小带来的差异.
(1)
其中,ni表示基因i的read数目;lj表示基因i的长度.

表1 样本信息表
2 混合样本反卷积方法
2.1 反卷积总体策略
从Venet[9]等开始,许多研究者提供了如何从全部基因表达量估计细胞类型、组织特异性特征以及细胞类型比例的方法.概括来说,根据所需输入数据的不同,这些方法可归纳为两种不同的类型,具体如下:
1) 部分基因表达反卷积方法 该方法需要提供细胞类型特异性特征[5,10-13]或不同细胞类型在特定组织样品中混合比例统计特征[14-15].
2) 完整的去卷积方法 该方法直接从异质样本的全部基因表达数据中估计细胞、组织特征和比例[9,16-18].
本文提出的反卷积算法是基于部分基因表达反卷积策略,是一种半监督的卷积方法.需要提供参考细胞的表达信息,通过所有基因在不同细胞类型中的表达情况推断出具有细胞特异性表达的基因.并以特异性表达基因为基础,对混合样本进行反卷积.推断混合样本的细胞类型和比例信息.具体流程策略如图1所示:

2.2 细胞特异性表达基因的鉴定
构建具有细胞特异性表达的基因表达谱矩阵是后续去卷积算法的基础,即在去卷积之前过滤掉非特异性或者特异性较弱的基因[19-22].具体而言,使用细胞特异性基因表达谱矩阵具有如下优点:①减少内存和计算层面上的消耗,加快了运行时间;②高信噪比-筛选出具有高信噪比的细胞特异性表达基因,提升了算法的有效性和灵敏度.目前半监督卷积策略鉴定细胞特异性表达基因的主流策略是等方差或者异方差的t-test. 本文提出一种新的鉴定细胞特异性表达基因的策略,具体过程如下:
1) 计算出每个基因在不同样本中的平均表达量
(2)
2) 去除冗余的背景信号
(3)
3) 拟合高斯分布,估计出高斯分布的参数μ,σ
①高斯分布的概率密度:
(4)
②对数似然函数:
(5)
③被估计的参数为
(6)
(7)
④鉴定细胞特异性表达的基因
(8)
其中,K表示参考细胞样本的数目,N表示基因的数目,gij表示第i个基因在第j个样本中的表达量,Si表示第i个基因在所有样本中最大的信号,μ和σ是高斯分布的2个参数.
2.3 细胞特异性表达基因可靠性分析
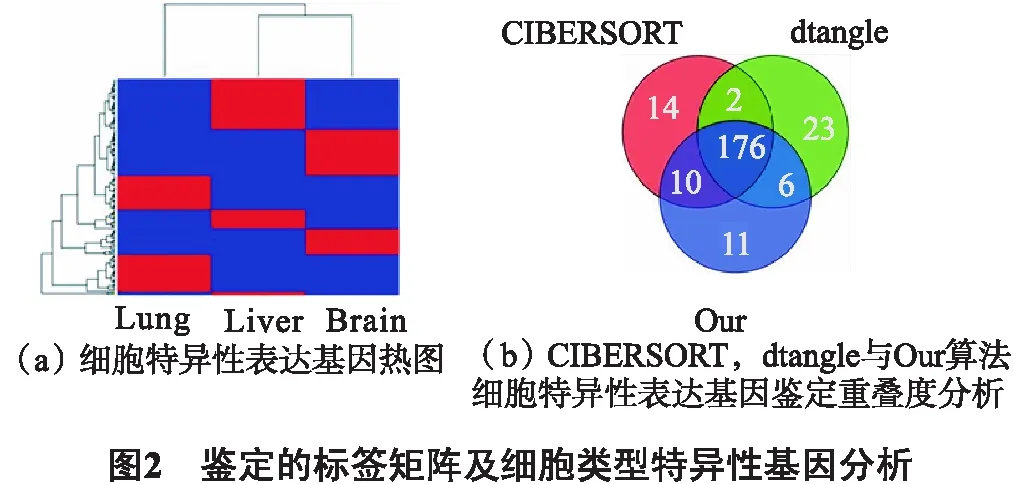
为了验证细胞特异性表达基因鉴定算法的可靠性,以GSE19830数据集作为实例,该数据中包括来自组织Lung、Liver、Brain 3种不同的细胞类型.利用数据集提供的参考样本推断出标签矩阵,并对矩阵中包含的细胞特异性基因进行了分析.结果显示所鉴定的基因在不同的组织中具有明显不同的表达模式,表明我们给出的鉴定标签矩阵的策略是有效的(见图2(a)).另外,进一步分析了不同算法鉴定出标签基因的重叠程度.结果显示文中的算法鉴定出的标签基因与CIBERSORT[7]和dtangle[8]鉴定具有高重叠度(见图2(b)).
2.4 反卷积算法
针对混合样本去卷积问题常被建模成带有约束条件的二次规划或者LARSOR回归问题,尽管CIBERSORT[7]提出了一种基于SVM的全新去卷积算法,但是其本质仍然是回归的问题.在此,提出了一种基于逐步回归的去卷积策略,这一策略的优势在于逐步剔除不显著的变量,该方法在现有文献中未见报道.另外,在文章中所涉及到的加粗字母均表示向量.
1) 逐步回归的主要思路:逐步回归是以常规的线性回归策略为基础,考虑的全部自变量对响应变量的作用大小,将作用不显著的变量剔除.以此保证预测方程的显著性.
2) 去卷积算法过程:
①建立混合样本基因表达量与细胞特异性表达基因表达量之间的线性关系.
E(Y|X)=β0+X·βT,
(11)
其中,Y表示细胞特异性表达基因在混合样本中的表达量,E(Y|X)为目标期望值;β0,β为待估参数.X为参考细胞样本对应的细胞特异性基因的表达量.
②向后剔除:即将所有变量均放入模型,然后尝试将其中一个自变量从模型中剔除,看整个模型解释因变量的变异是否有显著变化,之后将使解释量减少最少的变量剔除;此过程不断迭代,直到没有自变量符合剔除的条件.
③计算混合细胞可能的细胞类型的相对丰度.另外,需要说明的是,如果βi<0,则令βi=0
(12)
2.5 结果比较与分析
文中收集了4个具有真实比例的数据集(表1),其中包含93个芯片样本数据和54个RNA-Seq测序数据的样本.这些混合样本对应的不同细胞真实比例的信息是已知的.利用这些数据来测试本文算法,并与CIBERSORT进行比较,结果显示本文算法的测试结果与真实细胞的比例具有较好的一致性.其中图中的点越靠近对角线,表明与真实结果越接近.
通过图3可以看出,Our算法在GSE5350与PRJEB8231数据集中的预测结果与真实比例之间的相关系数高于CIBERSORT(图3(b)和(d)),尽管在GSE19830和GSE64098中相关系数低于CIBERSORT, 但是仍表现出不错的预测性能(图3(a)和(c)).为进一步分析Our算法与其他算法的比较情况,引入了DSA[23]和dtangle[8]进行了更进一步的比较分析.通过表2可以看出,Our算法在GSE5350和PRJEB8231 2个测试集中表现性能排第1,在GSE19830和GSE64098中尽管仅排第3,但仍优于DSA算法的性能.

表2 多个算法解卷积结果比较

数据集CIBERSORTdtangleDSAOurRankGSE198300.9920.9910.9620.9763GSE53500.9700.9650.9120.9731GSE640980.9940.9890.9750.9883PRJEB82310.8890.8980.7520.9021
3 肿瘤免疫浸润细胞组分应用
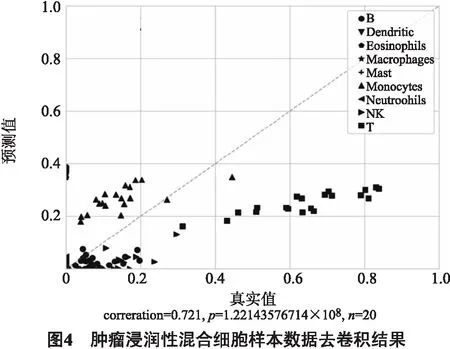
为了进一步探讨本文去卷积算法在肿瘤浸润性免疫细胞混合样本的有效性,我们从 https://github.com/gjhunt/dtangle 下载了20个肿瘤浸润性细胞混合样本,该数据集包含了多个不同的免疫细胞类型,分别是:B、Dendritic、Eosinophils、Macrophages、Mast、Monocytes、Neutrophils、NK、Plasma、T. 且这些样本具有真实的不同细胞类型的混合比例信息.我们利用本文提出的算法对这些样本进行解卷积,并将去卷积后预测比例与真实比例进行比较.
通过图4可以看出,我们提出的算法在分析肿瘤免疫浸润性细胞比例中具有不错的预测效果,混合样本去卷积预测结果与真实细胞的混合比例具有高一致性,显示了该算法的有效性和可靠性.
4 结语
提出了一种基于逐步回归模型对混合细胞样本去卷积新算法.该算法主要包含如下2个方面:①鉴定具有细胞特异性的基因,该过程首先计算每个基因在不同参考细胞中的前景信号,然后将每个基因在不同样本中的最强信号拟合高斯分布并通过最大似然方法估计相应的参数,最后将落在Si>μ+3σ的基因作为具有细胞特异性表达的基因.②利用具有细胞特异性表达的基因对混合样本去卷积,该过程采用逐步回归的策略,过滤掉与模型拟合不显著的协变量.我们利用4个数据集共147个样本对该算法进行测试,并与CIBEROSRT、DSA、dtangle进行比较,结果显示我们的算法具有不错的解卷积能力.最后我们将算法应用于20个肿瘤浸润性混合样本数据,结果显示我们的算法在对免疫浸润定量的过程中,具有不错的准确性能.
