基于知识模式挖掘的共同配送知识推荐系统
2019-07-25杨珊珊吕秋子徐庭君王婉婷吴金瑞
杨珊珊,吕秋子,徐庭君,王婉婷,吴金瑞
(哈尔滨商业大学 管理学院,黑龙江 哈尔滨 150000)
1 引言
近年来国内物流行业快速发展,电子商务兴起和其技术广泛运用,配送需求日益增长,但同时,配送成本居高不下,效率低下,交通堵塞状况严重,环境影响较大,“共同配送”这一名词逐渐成为了物流领域的关注焦点。共同配送是一种联合两个及以上商家(企业)的货物,进行共同装载并送至客户手中,追求运输规模化的一种配送形式。合理的配送可以优化整个物流环节,降低配送成本,提高配送效率,有效缓解城市交通拥堵,减轻配送造成的环境负担。
目前,共同配送的研究主要分为三个方面。文献[1]采用最小核心法、GQP、简化的MCRS、Shapley值法和纳什谈判模型等多种模型算法分析了常见分布的成本分配问题,将使合作企业合理分配“共同经济利益”。文献[2]基于多个配送中心开环VRP 方法研究了车辆共享和车辆路径问题。文献[3]通过建立共同配送协同机制,实现各配送主体之间的相互协调,相互合作。其次是为需要共同分配的特定对象提供联合分配解决方案。文献[4]提出了乳制品企业冷链物流的联合分销模式,以提高企业的市场竞争力,促进中国冷链物流的发展。文献[5]针对大小零售商提出了合作货运的模式,运用博弈论对共同配送费用分摊的影响因素进行了研究,改进后的Shapley 价值模型用于为大型零售商之间的联合分销提供建议。三是结合前面一二点即对共同配送具体对象的具体问题进行研究。文献[6]着眼于城市共同配送的生态收益问题,针对共同配送企业联盟间的利益分配问题,采用了基于生态因子的Raiffa 解法,充分考虑生态环境保护下的效益分配。文献[7]基于电子商务的背景,考虑到其对时间限制的时间敏感性,建立了多目标路径选择模型。从上述三方面可看出,共同配送所涉及的问题广泛且复杂,针对共同配送的不同对象和不同的共同配送问题都有着不同的研究方法和解决方案。在这种情况下,把共同配送系统和知识管理系统相结合,对共同配送的局部范围或单一对象的模型构建和算法设计进行有效的集成,通过知识推荐为共同配送研究者提供充分的数据和案例的知识支持,将有利于达到更合理的研究共同配送问题的目的。
如何将共同配送系统和知识管理系统有机结合,并且在考虑到用户学习过程中知识接收的效率情况下,向用户推荐符合自身需要的共同配送知识实例,目前少有学者研究。本文基于知识管理系统在其他领域的运用,结合共同配送的问题复杂多变,知识项间联系不紧密的特点,为促进共同配送知识的资产向企业效益更好转化,提出一种基于知识模式挖掘的共同配送系统知识推荐系统。当研究共同配送的用户通过知识主题对知识库的知识文档进行检索时,这些知识检索行为会以日志的形式保存于知识管理系统中。将共同配送系统和知识管理系统的日志数据进行有效的集成,挖掘出“共同配送实例—知识主题”和“知识主题-学习顺序”两种知识模型。其中运用基于案例的推理(CBR)[8]的方法,对拥有相似的共同配送主题的问题进行识别,挖掘出共同配送实例—知识主题知识模式,并在面对参与者的知识检索时推荐出符合其需求的知识主题。由于用户在通过知识库进行知识检索和学习时会遵循一定的知识模式,因此通过对Markov 模型和序列模式算法的运用,挖掘参与者在学习每个主题时的学习模式,即知识主题学习序列知识模式,并推荐符合参与者学习习惯的知识序列,提高用户对知识接收的效率。
2 系统设计
图1显示了共同配送知识推荐系统的体系结构图,它从两部分完成知识推荐。第一部分为用户通过知识库进行主题知识检索,其访问的数据日志在知识管理系统中,并与共同配送系统中的日志数据相结合,通过数据抽取、转换、加载,形成描述共同配送实例—知识主题的案例库,再结合新案例上下文特征,基于案例推理(CBR)用于分析新旧实例,并在案例库中找到类似于新案例的历史案例,推理出用户所需的知识主题。第二部分是利用马尔可夫模型等算法来读取用户在知识库中学习知识时遵循的知识模型,并推荐符合用户认知习惯的最佳知识序列。再结合第一部分的知识主题,共同完成共同配送知识的推荐。
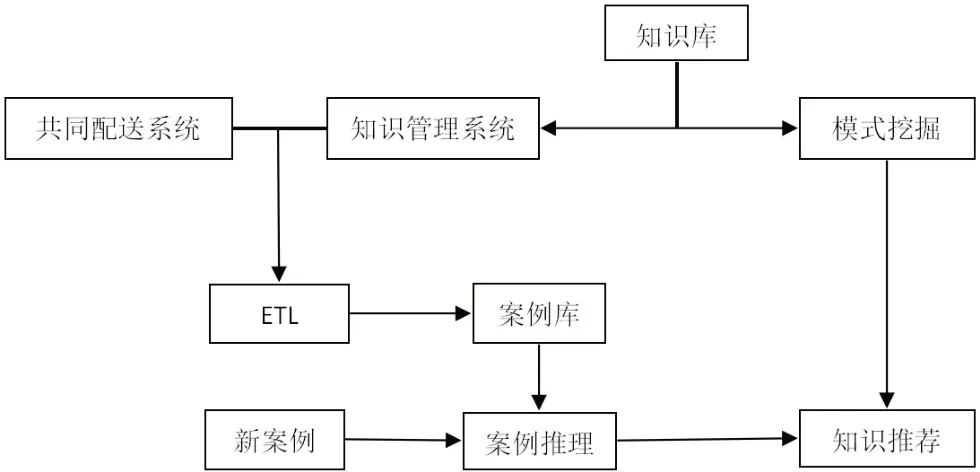
图1 共同配送知识推荐系统模型图
2.1 共同配送管理系统
共同配送管理系统以日志的形式解决所有共同配送问题的流程记录,其中每条数据对一个共同配送问题(或任务)进行记录,称作共同配送实例。实例数据包括诸如目标代码、用户ID、角色、任务和实例描述等信息,见表1。“实例叙述”用文本形式描述用户需学习的共同配送知识,成为共同配送实例建模的重要信息。

表1 共同配送问题日志
2.2 知识库与知识管理系统
在用户用知识库进行知识学习时,其每条访问数据包括问题编码、用户ID、知识序列和访问时间以日志的形式记录到知识管理系统中。例如用户C2成本分析师在成本核算时遇到了“成本分摊”问题,依次学习了m1、m2 等知识项,见表2。通常情况下,知识管理系统和共同配送管理系统相对独立,知识管理系统并没有记录共同配送问题代码等信息。为了向共同配送员工提供充分的知识支持,发挥两个系统的作用,本文对知识管理系统和共同配送管理系统进行了系统层次的集成,使知识管理系统能够记录参与者在访问知识库时处理的问题代码。

表2 学习行为日志
2.3 日志数据集成
在进行知识管理系统和共同配送管理系统的日志数据集成之前,需要对数据进行预处理工作:
(1)数据抽取:处理数据源的异构问题并统一数据存储。
(2)数据的清洗和转换:解决数据的质量问题[9],集中控制数据、清洗数据的冗余、数据的异常值等。
把知识管理系统和共同配送系统的对象编号与用户ID 作为双主键,对共同配送和知识学习日志的数据进行集成后对知识主题标注。知识管理系统使用元数据记录每个知识项目所属的知识主题。对于未进行知识主题分类的知识库,可以使用隐式Dirichlet 分布(LDA)、聚类和其他文本挖掘算法自动抽取知识主题[10]。
2.4 创建案例库
共同配送系统与知识管理系统的历史数据集成信息及对应解决方案会存储在共同配送案例库中,为新的共同配送问题提供指导和解决思路。用户角色和实例文本描述将成为上下文信息,用户学习时知识项被标注的知识主题作为对应问题解决案例,建立共同配送实例—知识主题案例库。
3 基于案例推理的知识推荐
基于案例推理(CBR)是智能仿真领域的重要推理方法,最早起源于美国耶鲁大学Roger Schank教授在1982年出版的专著《Dynamic Memory》。案例推理在过程决策、法律案例、医学诊断、知识管理、故障诊断和计算机辅助设计等领域得到了广泛的应用。该方法的基本思想是基于人的认知过程,在面对新问题时,通过新旧问题对比,为类似的历史问题匹配解决方案,纠正老问题的解决方案,并输出新的解决问题的方法。本文结合共同配送系统和知识管理系统的数据进行建模,求出与新问题相似度最高的历史案例集合,基于案例推理的方法确定用户对新问题的知识主题的需求。
3.1 共同配送案例建模及相似度分析
在共同配送知识学习过程中,由于有着相似问题的共同配送参与者的任务要求和所需要的知识相似,所以案例建模是通过上下文用户角色信息和实例文本描述完成的,能够对新旧问题的相似程度进行较为准确的评估。
共同配送案例用e表示;用户角色信息和实例描述分别用x、y表示,两者关系用(x,y)表示;两个案例之间的相似度表示为Scm(e1,e2),用户角色的相似程度表示为sc mX(x1,x2),实例描述的相似度表示为sc mY(y1,y2);由于是用户角色和实例描述两个因素共同评价案例相似度,因此需要设a(0<a<1)为权重因子,来衡量二者对结果的影响程度。下面给出案例相似度模型:
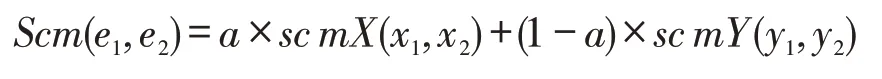
该公式中a值越大,角色的类似程度权重越大,推理更偏向用户本身的知识背景;相反,a值越小,实例描述的类似程度权重越大,推理更偏向于寻求类似的历史案例。
对于角色之间的相似度,可以用该角色参与某任务的次数来衡量。如路径规划师在选择路径时需要与成本分析师一起考虑共同配送成本核算的问题,成本核算作为一个任务,二角色之间参与该任务的次数就可以决定其相似程度。给定共同配送问题日志L和共同配送任务集TK,角色x参与任务的次数为t(t∈TK),记作frequency(x,t)。角色x表示为向量1,f2,...,fn>,其中fi=frequency(x,ti)。给定角色x1和x2的相似度:
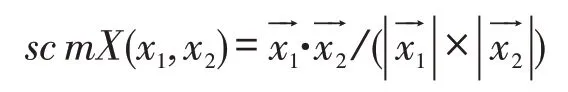
由于用户在进行知识检索时通常以文本的形式获得知识支持,因此对于实例描述之间的相似度,主要是评估问题间语义相似程度,可以使用文本挖掘。如路径规划师通过阅读路程计算方法综述文档来选择最合理的路程计算模型。首先利用开源的自然语言处理工具StanfordNLP对实例描述进行句法分析、去停顿词、词干化、标记语句组成结构等预处理操作,然后采用词频—逆向文档频率(TF-IDF)算法模型对共同配送的实例进行模型建立:
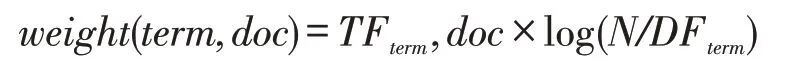
最后定义问题相似度。
3.2 确定知识需求
基于案例推理的方法,新旧问题角色和实例描述的相关信息被用来确定所需要的知识主题。
本文运用K近邻的思路对案例进行推理。在案例库中寻求与目标样本—新问题相近(相似度最大)的K个邻居样本—历史案例,使用相似度加权预测出各个新问题所对应的解决方案,即用户对知识主题的需求:
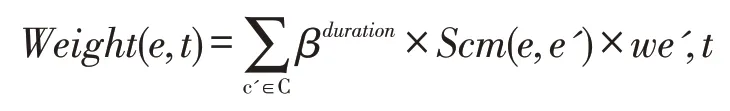
式中:E为K个最相似案例的集合,Scm(e',e)为案例相似度权重,为案例e'的时间权重;W表示在案例e的问题解决案例中此知识主题的个数;0<β<1为衰减因子,duration表示案例e'发生事件和目前的时间间隔(单位:年),时间愈久,权重愈小。在共同配送过程,知识的更新速度比较快,对用户进行新的知识方案推荐能更好地对共同配送员工进行知识支持,需要考虑到历史案例与当前的时间间隔。本文进行了实验并设置K=10,β=0.8。
在最开始的共同配送案例推理过程中,也许不能获得足够量的相似案例作为推理的根据,这时用SVM、多决策树综合技术等分类算法预测新案例数据的类别,辅助CBR的知识推理过程。
3.3 案例存储处理
系统投入运行后,历史案例持续存储中的知识积累将导致案例库中增加大量类似案例或重复案例,降低案例推理的效率。
设案例库U=(e1,...,ei,...,ej),i∈[1,j],ei为某历史案例,目标案例g与ei的相似度是ri属于[0,1],s是专家定义的一个阈值,存储案例有以下几种情况[11]:
(1)任何si=0,i∈[1,j],新案例与案例库中≥所有的案例不匹配,那么新的案例可以被添加到案例库。
(2)存在si=1,i∈[1,j],新案例与某历史案例完全相似,则新案例不加入案例库。
(3)所有si<0,i∈[1,j],这时新案例可以加入到案例库。
(4)存在si>0,i∈[1,j],把拥有max(si)的历史案例的解决方案修改成新案例的解决案例。
通过基于案例推理的方法,我们推断用户需要面对新问题所需的不同加权知识主题。为了提高用户接收知识的效率,本文就用户在学习时的学习模式进行挖掘,推荐出符合用户学习习惯的知识序列。
4 知识学习模式挖掘
用户在学习过程中一般会遵循一定的知识模式[12]。如果你正在学习新知识,你通常会遵循从浅到深的学习模式。本文从用户访问知识库日志数据过程中采用Markov模型和序列模式算法挖掘知识工作者的学习模式,为用户提供更合理的知识推荐。
4.1 面向主题的Markov模型
马尔可夫模型(Markov)是苏联数学家马可夫于1906年至1912年提出的统计模型。它使用概率数学分析方法研究自然过程,并广泛应用于各种预测领域。本文运用Markov模型与个性化知识推荐相结合,经知识项之间的转移关系,考虑到参与者在学习时知识主题的聚集性,运用知识库的元信息把知识学习日志按主题归类,构建基于主题的Markov模型,从而提升知识推荐的有效性。
4.1.1 知识序列的知识主题归类。用户通过知识库搜索学习行为日志(TL)记录了其每一条访问行为,见表2。每条数据包括用户在寻求共同配送解决方案依次学习的知识序列,记为<m1,m2,...,mn>,n为序列长度。将这些知识序列基于知识库的元信息分为多个知识子序列,将每个子序列的知识项归类到同一个知识主题中,并按照一定的学习顺序排列。将知识库中知识项合集用T表示,知识主题的合集用L表示。对于每个知识主题,得到相对的知识序列子集TLtl。
4.1.2 状态与知识跳转关系。在m阶Markov模型中,知识序列中的一个状态用m-state表示。给出序列<m1,m2,...,mn>,m阶Markov模型的第j个状态为<mj,mj+1,...,mj+n-1>,1≤j≤n-m+1。例如,知识序列s'=<m1,m2,m3>,一阶Markov算法的状态集为{m1,m2,m3>,二阶Markov算法的状态集为{<m1,m2>,<m2,m3>}。
跳转关系是在用户学习行为中,一种知识项跳转自另一种知识项的时序关系。将这种跳转关系记作mj→mi,表示用户在学习知识项mj之后转向mi的学习。对于起始的知识项,源状态mj表示成。上述序列s'中存在跳转关系→m1,m1→m2,m2→m3,<m1,m2>→m3}。
4.1.3 面向主题的Markov模型。为使得知识项的推荐更加具有连贯性和准确性,需通过在知识序列子集TLtl上单独使用Markov模型,训练出面向主题的知识学习模型。系统需要根据用户的学习行为,基于上下文信息预测学习者在当前学习状态下最有可能学习的下一个知识项。用Qj表示用户的当前学习状态,最有可能学习的下个知识项为mi,则P(mi|Qj)为在Qj学习状态下,下一个学习知识项mi的跳转概率。使用最大似然估计,跳转概率P(mi|Qj)的计算方法为:
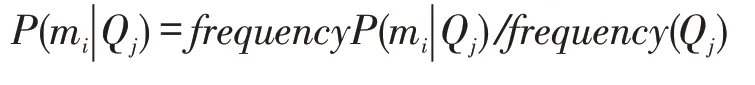
由于阶数m变大,Markov算法中会加入更多的上下文信息,预测的有效性会相应提高,同时数据出现的分散问题会使得预测的覆盖率下降。采用1阶模型和2阶模型线性插值的方法,能使有效性和覆盖率之间存有一定平衡,即:
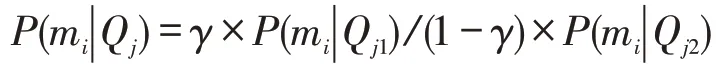
式中设权重因子γ=0.5,即两个模型的预测平均值。
4.2 频繁知识序列挖掘
在序列模式挖掘领域中有两种经典算法:GSP算法(Generalized Sequential Patterns)和PrefixSpan算法(Prefix-project Sequential Patten Mining)。由于PrefixSpan 模型不会有候选数列,且扫描原始数据时对原始数据库进行分割,在分散和紧凑的数据集中都可以使用更高效的挖掘序列模型。因此本文运用PrefixSpan算法挖掘面向各个知识主题的频繁序列模式。
在对知识主题的频繁序列挖掘时,在已给出的知识主题tl下,在知识序列集合TLtl中挖掘频繁序列。设M=<m1,m2,...,mp>为包含p个知识项的集合;一个知识序列S为知识项集的有序集合,记为序列元组S=<k1,k2,...,kn>,各个元素ki为知识集M的子集。定义序列X=<k1,k2,...,ki>S的子序列,S是X的超序列,序列X在S中的数量称为X的支持度,记为Support(X)。给定一个正整数minSupport表示最小支持阈值,如果Support(X)≥minSupport,则称序列X是频繁序列。
4.3 知识项预测
输入挖掘得到的频繁序列模式,匹配用户当前的知识学习顺序,并预测学习者接下来可能学习的知识项。序列sa=<m1,m2,...,mn>表示参与者a最近学习的n条知识项组成的知识序列,KH=<h1,h2,...,hi>表示挖掘的频繁序列模式集,pren(h)表示序列p的n项前缀。设知识序列sa与模式h匹配,当h的长度为n+1时,pren(h)为sa的子序列,第n+1条知识项成为备用的推荐知识。将推荐的可靠性,定义成序列h和前缀序列pren(h)的支持度比率:
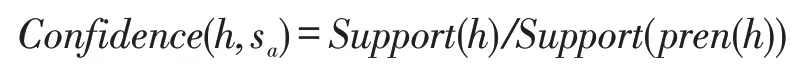
推荐区域推荐给学习者的知识项的可靠性需要大于阈值minConfidence(h,sa)。
5 结束语
本文提出了一种基于知识模型挖掘的联合分布式知识推荐系统,记录了学习者在知识库中的学习行为。通过上下文信息对共同配送系统和知识管理系统日志进行集成,并使用案例推理的方法寻找相似的共同配送历史案例,挖掘出用户所需的知识主题;通过面向主题的Markov模型,挖掘出符合用户学习习惯的知识序列,完成知识推荐。在日志集成过程中,本文使用的上下文信息为角色信息和实例描述,但在实际的共同配送方案设计过程中,需要考虑的上下文信息更为复杂,因此在未来的研究过程中需要考虑更多的共同配送元素。
