梯级水库短期优化调度模型的精细化与GPU并行实现
2019-07-24纪昌明马皓宇吴嘉杰俞洪杰
纪昌明,马皓宇,吴嘉杰,俞洪杰,彭 杨
(华北电力大学可再生能源学院,北京 102206)
1 研究背景
梯级水库优化调度通过对入库径流进行调节以实现水电站的效益增长,一般分为中长期优化调度与短期优化调度,受限于当前水文与气象预报技术的发展水平,中长期优化调度仅具有规划意义,能指导水电站实际运营的只有短期优化调度[1]。而近几十年的研究中,短期优化调度的理论与实际间的差距一直存在[2],其主要原因在于为满足发电计划制定的时效性要求,以往的研究中人为引入了一系列策略以简化计算模型,从而将计算时长降至可接受范围内,但这也导致所得计划在实际运行中出现偏差,而水电站出力的近似计算是造成偏差的主要原因[3]。为简化厂内经济运行,电站的出力可通过恒定出力系数的出力方程或忽略机组振动区的等微增率法计算获得,而这种简化计算方式将导致可用的水资源在时空分配上的不合理,通常不为水库操作人员所接受。故本文构建同时考虑水库优化调度与水电站优化运行的精细模型,通过经典算法—动态规划(DP)[4-6]的二重嵌套形式,求解给定规模与离散精度下的优化调度方案。
DP 在求解精细模型时将面临更为严重的“维数灾”问题,如何处理该问题成为计算的关键。“维数灾”本质上是程序计算量与内存占用量的指数型增长,水库调度领域中许多学者仅针对前者提供了解决方案,主要分为两类:(1)算法改进,通常需牺牲解的全局最优性以提高计算效率:冯仲恺等[7]为缓解“维数灾”问题,结合均匀试验设计提出均匀动态规划;史亚军等[8]提出一种基于灰色系统预测方法的离散微分动态规划,以求解梯级水库群优化调度问题;纪昌明等[9]为解决传统动态规划在处理水库群联合优化调度时面临的约束处理机制选择和计算时间长的问题,引入映射思想,基于映射和集合论知识构建可行域搜索映射模型;(2)CPU 并行加速,通常需花费高昂的成本以构筑计算集群:万新宇等[10]在分析传统串行动态规划算法计算特点的基础上,建立基于主从模式的并行动态规划模型;Li等[11]利用高达350核的高性能CPU计算系统,实现了对等并行模式下的并行动态规划;蒋志强等[12]基于.NET4 并行拓展库,构建了时段间、时段内离散组合间以及两者混合模式下的并行多维动态规划算法。
区别于上述的研究成果,本文为全面且妥善地处理“维数灾”,首先针对极少提及的内存占用量增长问题,采用数据压缩与数据库技术以减轻程序运行对计算机的内存负担;其次针对重点研究的计算量与计算时间问题,采用在水动力模拟与分布式水文模型中已广泛应用[13-15],而在水库调度中未引进的图形处理器(GPU)并行加速[16],以大幅降低程序的运行时间。最后以潘口、小漩两库联合调度为研究实例,验证所提模型、算法及优化策略的科学与实用性。
2 精细优化调度模型
本文选择“以水定电”作为精细优化调度模型中各电站的运行模式,即未来一个调度期内,在各库调度期初末库容、各电站调度期初机组状态、各阶段区间径流已知的前提下,同时考虑水库调度的库容、下泄流量等约束与水电站运行的机组振动区、启停机耗水等约束,寻求最大化梯级系统总发电量的运行方式。
2.1 目标函数

式中:E*为调度期内梯级水电站的最大发电量;t、i分别为时段编号和水库(水电站)编号;T、n分别为调度期阶段数和水库总数;Ni,t为t阶段i库对应的电站最优出力,其计算过程如图1所示,水库调度决策阶段平均泄流Ri,t,由此推得阶段平均水头Hi,t,将两者作为水电站运行的输入,而电站通过决策本阶段投入运行的机组与机组间的流量分配,以最大化电站出力,该过程表示为Ni,t=φi(Hi,t,Ri,t);Δt为单位阶段长度。
2.2 约束条件
(1)水库调度约束。水量平衡约束:
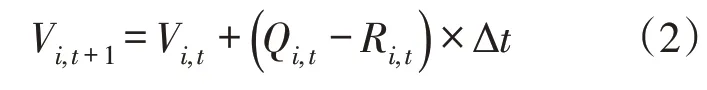
式中:Vi,t、Vi,t+1分别为t阶段和(t+1)阶段i库的阶段初库容;Qi,t、Ri,t分别为t 阶段i 库的阶段平均入流和泄流值。
库容约束:
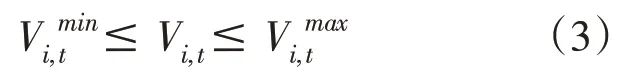
下泄流量约束:

边界约束:

式中:Vi,start、Vi,end为i库给定的调度期初末库容。

图1 出力计算简图
(2)水电站运行约束。发电流量约束:

出力约束:

机组振动区约束:

机组启停机耗水约束:
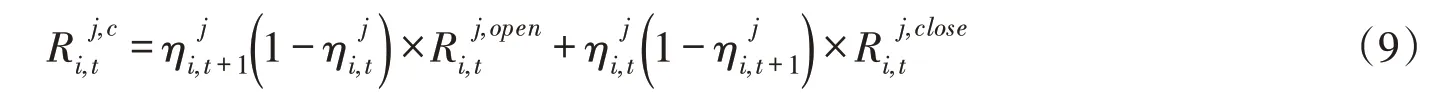
边界约束:

2.3 模型求解该模型为二重嵌套优化结构,在调度领域也属于相当复杂的模型,其外部结构(水库调度)逐阶段决策本阶段的下泄流量,将泄流值与推得的阶段平均水头作为内部结构(水电站运行)的输入,内部结构决策该阶段电站的机组组合和流量分配,在可用流量与工作水头确定下优化电站输出,并将最大出力及相应的机组组合与流量分配返回至外部结构。为保证计算结果的质量,选择动态规划作为求解算法,针对该模型结构使用二重嵌套DP,同时进行水库优化调度与厂内经济运行。
对于外部结构,通常按1 h或15 min划分调度期(1 d),将水库优化调度转化为多阶段决策问题。假设各阶段各库的库容均划分为M级,则梯级水库任意阶段的状态组合数为Mn,记t阶段初组合号为pt(pt∈[1,Mn])的梯级水库蓄水状态的n维向量为外部结构的DP计算流程图如图2所示,其具体的求解步骤如下:
(1)顺序递推计算。由调度期初逐阶段向后递推至调度期末,对于某阶段t的阶段末状态组合号pt+1,其对应的蓄水状态向量为Vt+1(pt+1),遍历所有可能的阶段初状态Vt(pt),由式(11)求得对应于pt+1的最大累积效益及相应的最优转换机组组合与流量分配并保存计算结果。当阶段末所有组合号对应的计算均完成后,令t=t+1,进行下阶段计算直至最后一个阶段的计算完成。

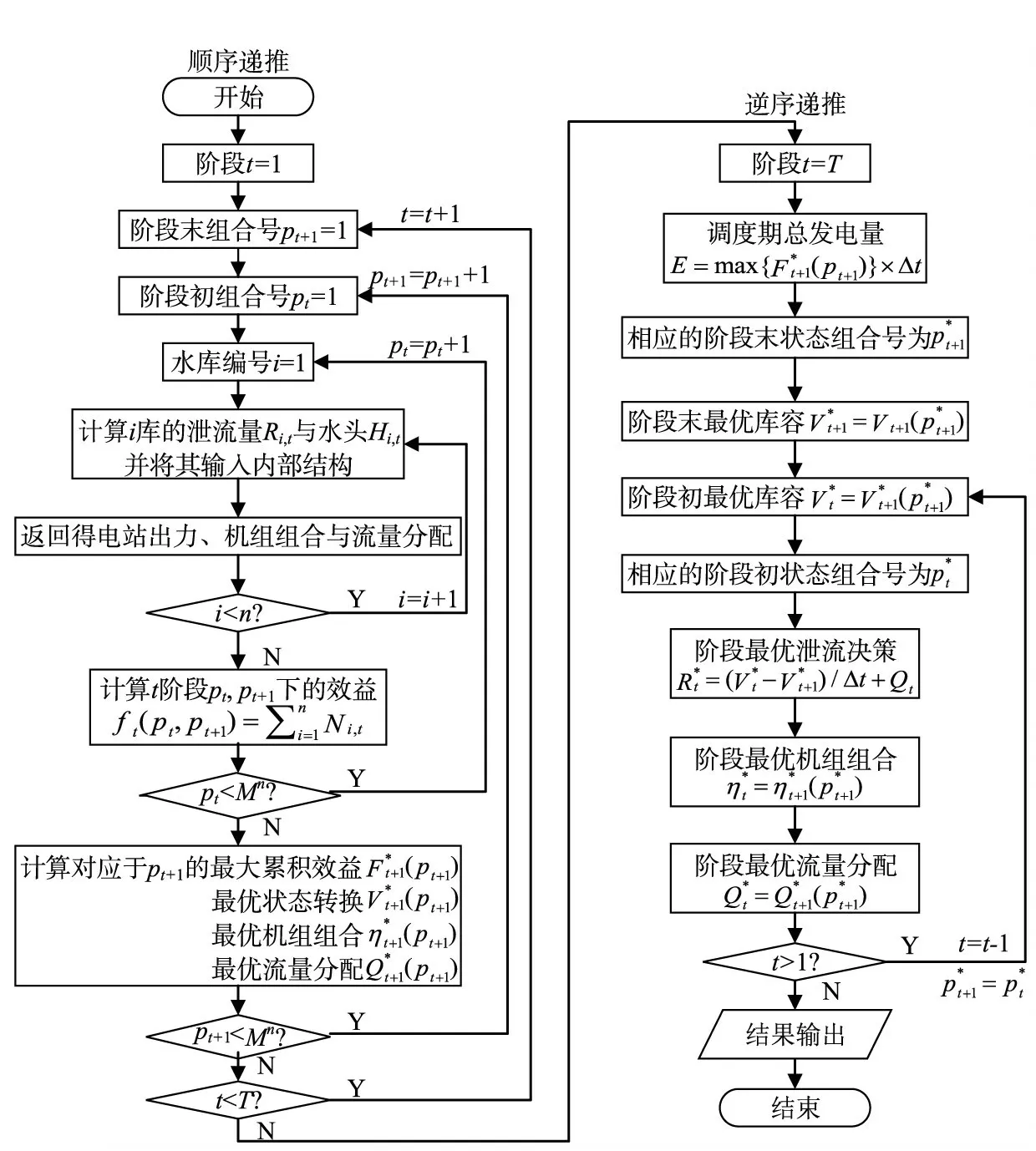
图2 外部结构的DP计算流程
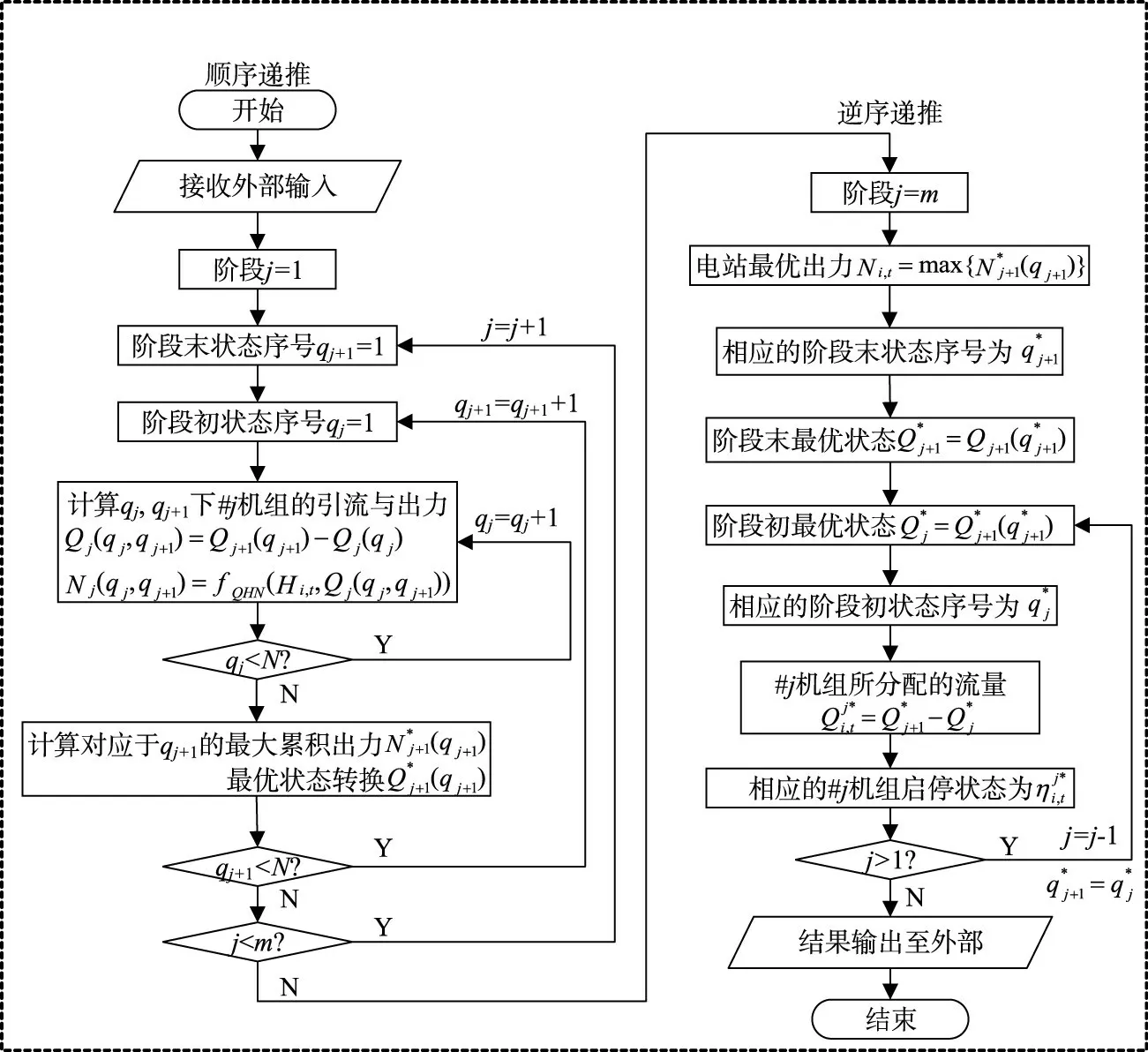
图3 内部结构的DP计算流程
(2)逆序递推计算。由调度期末逐阶段向前递推至调度期初,根据所保存的推得梯级系统的调度期总发电量E及相应的各阶段泄流蓄水状态机组组合流量分配最后将计算结果输出。
对于内部结构,本文在机组流量优化分配的过程中寻找恰当的机组组合方案,而不采用先确定投运机组再进行固定机组间流量分配的传统分层求解方式。按机组编号将每台可运行机组作为阶段变量,从而将厂内经济运行转化为多阶段决策问题。假设各阶段的状态(机组累积引流)均划分为N级,记j阶段初序号为qj(qj∈[1,N])的累积引流状态为Qj(qj)。内部结构的DP计算流程图如图3所示,具体的求解步骤如下:
(1)顺序递推计算。由阶段1(1机组)逐阶段向后递推至阶段m(m机组),对于某阶段j的阶段末状态序号qj+1,其对应的累积引流为Qj+1(qj+1),遍历所有可能的阶段初状态Qj(qj),由式(12)求得对应于qj+1的最大累积出力及相应的最优转换并保存计算结果。当阶段末所有状态序号对应的计算均完成后,令j=j+1,进行下阶段计算直至最后一个阶段的计算完成。
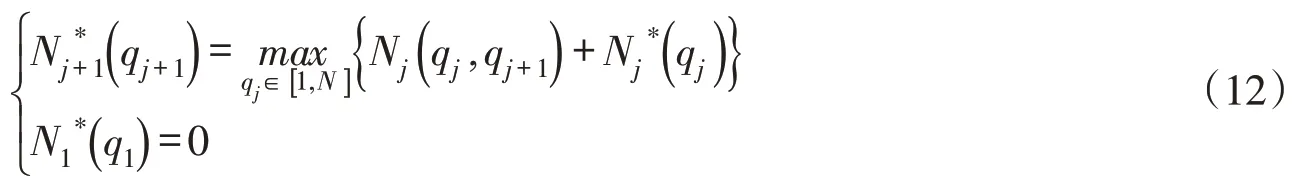
(2)逆序递推计算。由阶段m逐阶段向前递推至阶段1,根据所保存的与推得电站优化出力Ni,t及相应的流量分配与机组组合最后将计算结果返回至外部结构。
3 求解算法性能优化
3.1 嵌套DP 算法性能分析本节从计算时间和内存占用量这两个最为关键的性能参数入手,对求解精细优化模型的嵌套DP算法进行分析。首先对计算时长进行估计,算法推求精细模型的计算量集中在外部结构顺序递推的多重嵌套循环处,假设该循环任意(t,pt+1,pt)下的迭代步的运行时间均为Δτ,则整个模型的计算时间τ为:

接着对算法实现所需的内存大小进行估计。算法在计算过程中主要保存4种变量,其存储形式如图4所示(梯级系统调度期初末的库容状态固定,故相应的状态组合号p1,pT+1∈{1}):
本文所涉及的代码均通过C语言进行编写,浮点型变量通常定义为双精度类型(double),占据8个字节,整型变量通常定义为普通类型(int),占据4个字节。故算法运行的内存占用量RAM为:

由上述分析可得,嵌套DP的时间复杂度为O(TM2n),空间复杂度为O(TMn),时空复杂度均呈指数型增长,这即是“维数灾”出现的原因,同时也说明对“维数灾”的处理包括减少计算时间与缩减内存占用两方面,下面将针对这两方面进行算法优化。
3.2 基于数据压缩与数据库技术的内存占用缩减以往的水库调度研究通常仅着眼于算法求解时间方面的优化,通过算法改进减少计算量或通过CPU多核并行提升计算速度,使得模型计算时间满足相应要求,而针对算法内存空间方面却几乎没有提出相应的优化方案,且时间方面优化策略的实现往往增加了算法的空间复杂度,当问题规模较大或模拟精度较高时,计算机很容易出现内存瓶颈问题。由于实际问题的计算规模与离散精度等条件是未知的,故时空两方面的问题均需考虑,本节将通过数据压缩与数据库技术,对3.1节所提的算法主要变量的存储规模进行有效缩减,在不影响计算结果的前提下减少程序运行中的内存占用,优化后的变量存储形式如图5所示:

图4 主要变量存储形式

图5 优化后的变量存储形式
上述算法内存占用量优化的实现,一方面基于数据压缩技术,在不损失有效信息的前提下完成存放变量的数组降维,另一方面基于数据库技术,将逆序递推计算才使用到的数据先存储至计算机外存,以实现内存负担向外存的转移。同时将浮点型变量均定义为单精度类型(float),其仅占据4个字节,能在保证结果精确性的前提下减少内存占用并提升计算速度(CPU与GPU的单精度浮点计算能力均优于双精度)。优化后程序运行的内存占用量RAM′为:

3.3 基于OpenACC的GPU并行加速近年来GPU并行加速技术发展迅速且已相对成熟,在硬件方面GPU的单精度浮点计算能力达到同期CPU的10倍以上,在软件方面NVIDIA等公司已发布较为完善的并行编程标准CUDA和OpenACC。在水利计算上,GPU并行通常用于加速水动力学模型或分布式水文模型的求解,取得了较好效果[16],而在梯级水库优化调度中尚无文章明确实现GPU并行,故本节提出基于OpenACC标准的GPU并行嵌套DP,以期较以往的CPU并行进一步提升算法的计算效率。
OpenACC 是一种以编译器导语形式实现的GPU 并行标准[17-19],其可对复杂的C或Fortran 代码加速。该标准中CPU称为主机(host),GPU称为设备(device),并行的目的是将原本由主机负责的计算稠密区域卸载至设备上多线程执行以提升运行速度,其基本步骤为:分配设备内存→将计算所需数据传至设备内存→设备进行并行计算→将计算结果传至主机内存→释放设备内存。本节利用kernels构件创建并行区域,在区域内利用loop 构件实现外部顺推计算的嵌套循环并行化。算法的并行流程如图6所示,其主要步骤为:
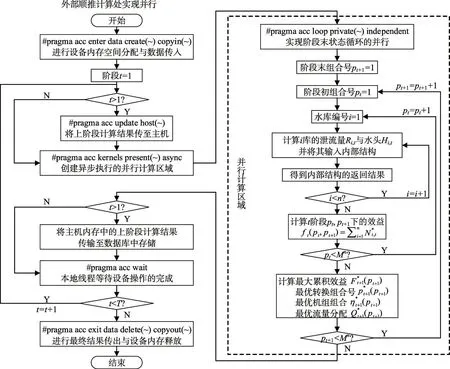
图6 算法并行化流程
(1)调用函数的处理。算法中水位与库容间的值转换、由下泄流量推求下游水位等功能已封装为函数形式,通过调用特定的函数满足相应的计算要求,但在并行计算区域内设备无法直接调用主机端存储的函数,需添加routine导语以支持区域内自定义函数的调用。
具体的实现方式为:在被调函数定义与声明的紧邻上方添加#pragma acc routine seq,定义处的导语告知编译器创建该函数的设备例程,声明处的导语告知编译器该函数可被设备端单线程直接调用。
(2)数据管理。主机内存与设备内存通常是完全分离的,这就导致主机与设备间必须进行数据传输,将主机内存中存储的计算所需数据传至设备内存以供并行计算使用,将设备内存中存储的计算结果传至主机内存以供逆序递推计算使用。然而频繁的大规模数据传输将消耗大量时间,为减少耗时需尽可能降低数据传输的量与次数,故本节利用enter data/exit data创建非结构化数据区域以减少数据传输耗时。在并行计算开始前,添加enter data导语为设备内存中存储的变量分配空间,并将尾水位流量曲线、机组动力特性曲线等基础数据传入;在并行计算结束后,添加exit data导语将并行计算的最终结果传回主机,之后释放设备内存。
具体的实现方式为:在外部顺推计算的嵌套循环前,添加#pragma acc enter data create(变量列表)copyin(变量列表),一次性完成主要变量的内存分配与数据传入;在嵌套循环后,添加#pragma acc exit data copyout(变量列表)delete(变量列表),一次性完成计算结果的传回与内存释放。
(3)循环并行化。嵌套DP的计算量集中在外部顺推计算的嵌套循环处,故应将该循环纳入并行计算区域以多线程执行。由于嵌套循环最外层的阶段循环具有顺序依赖性,因此选择对阶段末状态循环实现并行。通过kernels导语创建包含阶段末循环的并行计算区域,并在该导语中添加present子语以告知编译器所列变量已存在于设备内存,以此防止重复的数据操作;通过loop 导语指示编译器在阶段末循环处并行,并在该导语中添加private子语与independent子语,前者用于创建循环计算所使用的中间变量在设备各线程中的私有副本,以此防止竞态错误,后者用于告知编译器该层循环的迭代步间不存在数据依赖,满足并行化要求。
上述操作具体的实现方式为:在嵌套循环的阶段循环内,添加#pragma acc kernels present(变量列表),并通过{}将阶段末循环及其内层循环包含在内;在阶段末循环的紧邻上方,添加#pragma acc loop private(变量列表)independent,以实现阶段末循环的并行化。
(4)主机与设备的计算重叠。3.2节中为减轻计算机的内存负担,将部分数据传输至外存的数据库中存储,当内存占用优化后的算法实现GPU并行时,则要求外部顺推计算在每个阶段的并行计算结束时,将该阶段需存至数据库中的计算成果先由设备内存传输至主机内存,再转至主机外存中,这些数据操作将增加程序的非计算耗时。故本节先是通过update 导语将阶段计算结果由设备传至主机;接着为减少耗时,利用async子语创建异步队列,以实现主机数据传输与设备并行计算的同时执行,避免计算资源的浪费,同时将数据传输的时间开销隐藏于并行计算之下;最后利用wait 导语使主机线程等待设备操作的完成,防止程序出错。
上述操作具体的实现方式为:在外部顺推计算的阶段循环内,添加#pragma acc update host(变量列表),将设备计算得出的上阶段计算成果与传至主机内存;在kernels导语中添加async 子语以将并行计算操作压入异步队列中执行;在并行区域后,将主机内存中的传至数据库,之后添加#pragma acc wait以等待设备操作的完成。
4 实例分析
堵河作为汉江上游南岸的一级支流,位于湖北省西北部,全长354 km,总落差500 余米。潘口与小漩水电站位于堵河干流的上游河段,开发任务以发电为主,梯级水电站的基本参数如表1所示。本文以该梯级系统的日优化调度为研究对象,选取2016年12月某日为调度期,以15 min为阶段时长将该日划分为96段。梯级系统的运行模式为“以水定电”,故系统调度期初末的库容状态、调度期初的机组启停状态及调度期各阶段的入库流量均为该日实际值,算法的模拟精度设置为:潘口各阶段库容的离散点数M1=600;小漩各阶段库容的离散点数M2=100。
实例研究所使用的软硬件配置为:软件方面,利用C 语言进行代码编写;选择同时支持OpenMP、MPI 与OpenACC 并行标准的PGI 编译器(PGI Professional Edition18.10)实现编译。硬件方面,选择Windows 10 操作系统;使用的CPU 型号为Intel Xeon E5-4640 v4,主频2.1 GHz,物理内核数12;使用的GPU型号为NVIDIA Tesla K80,CUDA核心数4992。

表1 梯级水电站基本参数
4.1 精细模型与传统模型对比本节分别构建梯级水电站的传统优化模型与精细优化模型,两者的区别在于水电站出力的计算方式不同:传统模型分别采用恒定出力系数的出力方程和忽略机组振动区的等微增率法计算电站出力,前者标记为传统模型1,后者标记为传统模型2,两者的外层水库优化调度均通过DP求解;精细模型则将出力计算作为一个多阶段优化决策问题,通过本文所提的嵌套DP求解。
表2为3个模型在计算条件相同的情况下求解所得的计划发电量与模拟发电量,其中计划发电量为模型求解所得的日发电效益的理论值,模拟发电量为模拟实际中调度人员按流量执行调度方案所得的日发电效益的仿真值。由表2 可以看出:(1)传统模型1 和2 的计划发电量分别为175.93万kW·h与174.97万kW·h,均高于模拟发电量的158.10万kW·h与157.35万kW·h,其原因在于传统模型的调度计划在实际执行中,原本未计量的机组启停机耗水将消耗电站的发电水量,且为防止机组在振动区工作,须对未考虑振动区约束的机组运行方式进行调整,因此传统模型发电量的模拟值均低于理论值;(2)精细模型的计划发电量与模拟发电量相同,均为170.53万kW·h,其原因在于精细模型的出力计算充分考虑了机组的启停机耗水与振动区约束,故所制定的调度计划贴合实际;(3)传统模型的计划发电量虽高于精细模型的计划发电量,但其模拟发电量均低于精细模型的对应值,其原因在于本文所提出的精细模型将实际生产中需考虑的调度规则作为模型的约束条件,通过二重嵌套优化同时进行厂间与厂内的水量优化分配以尽可能发掘出梯级系统的发电效益,并利用嵌套DP保证求解结果的质量。
4.2 GPU 并行与CPU 并行对比4.1 节中的对比实验证明了精细优化模型及其求解算法的有效性,之后的计算均针对精细模型并使用嵌套DP进行求解。本节首先测试3.2节中提出的基于数据压缩与数据库技术的内存占用缩减策略的效果,通过诊断工具检测该策略引入前与引入后的程序运行的内存占用情况,检测结果显示引入后程序的内存占用量较引入前减少了99.5%,缩减幅度显著,表明了所提空间优化策略的科学与有效性。
接下来通过不同的并行方式实现内存占用优化后算法的并行加速,并对加速效果进行比较。CPU 并行分别通过OpenMP 与MPI 实现,GPU 并行通过OpenACC 实现,并行化均是针对外部顺推计算嵌套循环的阶段末状态循环层。需要注意的是阶段末循环的不同迭代步的计算量可能相差很大,这意味着采用静态调度的任务分配方式可能导致严重的负载不均进而影响加速效果,故本节中的3种并行方法均采用动态调度的方式以平衡负载从而保证并行效率。
基于OpenMP的CPU并行通过parallel导语创建多线程并行计算区域,通过for导语实现循环的并行化,在for导语中添加schedule(dynamic)子语以选择动态调度的任务分配方式;基于MPI的CPU并行选择master/worker 模式以实现动态调度下的多进程并行计算,其中master 进程负责计算任务向worker 进程的分配与管理,worker 进程负责处理计算任务并将计算结果返回至master 进程;基于OpenACC的GPU并行的流程详见3.3节,其默认为动态调度方式。对于同一研究实例,内存占用缩减后的算法的串行版本与3种并行版本的结果如表3所示,为保证对比实验的公平性,已尽可能挖掘出上文所列配置下的3种不同并行方法的最优结果,表3中所列的计算时长为相应并行手段下的最短时长,加速比为最优加速比。

表2 3种模型的计算结果 (单位:万kW ·

表3 实测最优结果对比
由表3的计算结果可以看出,OpenACC 实现的GPU 并行的加速效果最优,可将算法的求解时间由串行的167.37 min压缩至4.27 min,取得39.20的最大加速比,而OpenMP与MPI实现的CPU并行仅将计算时间缩短为19.31 min 与23.18 min,得到8.67 与7.22 的加速比。因并行计算所使用的CPU 与GPU处于同一价位,故可得在硬件成本相近时,GPU的并行计算能力远高于CPU。通过上述分析可以得出,GPU并行较CPU并行更适合作为梯级水库优化调度模型的加速策略。
5 结论
本文为缩减水库优化调度的理论与实际间的差距,提出了精细至电站机组负载分配的优化调度模型,同时考虑水库优化调度与厂内经济运行并通过二重嵌套DP进行求解,针对“维数灾”问题,提出了基于数据压缩与数据库技术的内存占用缩减策略以降低算法的空间复杂度,提出了基于OpenACC的GPU并行策略以减少算法的计算时间。最后以潘口小漩梯级水库为研究实例,进行精细模型与传统模型、优化算法内存与未优化算法内存以及GPU并行与CPU并行的对比分析,计算结果表明:本文所构建的精细模型较传统模型更贴近电站的实际运行情况;所提出的嵌套DP能保证精细模型求解结果的质量;所提出的内存占用缩减策略能有效减轻算法对计算机的内存负担;首次引入水库调度领域的GPU并行较传统的CPU并行更适合作为优化调度大规模计算的并行加速策略。
