基于CRF和HITS算法的特征情感对提取
2019-07-23唐莉,刘臣
唐 莉,刘 臣
(上海理工大学,上海 200093)
0 引 言
随着电子商务的迅猛发展,网络购物用户数量不断增加。中国作为全球规模最大的网络零售市场,2017年12月中国网络购物用户规模已达5.33亿,由此产生的网络评论数据呈几何式增长。庞大的评论数据带来的信息超载问题日益严重,海量的评论信息的分析和提炼成为需要解决的首要问题。
文本情感分析采用计算机自动分析在线评论中表达的观点或情感,具有广泛的应用前景,已成为近年来的研究热点。
文本情感分析可以被大致分成特征级、短语级[1]、句子级、文档级[2]。其中特征级情感分析是对产品属性及其对应情感的提取和分析。它一般被分为有监督和无监督学习方法。
无监督学习方法不需要标记数据,但是依赖于利用启发式程序和规则来找到隐藏的结构[3]。常见的无监督学习有频繁模式挖掘[4-5]、语义规则挖掘[6]、话题模型[7]等。有监督学习则需要标记数据来训练和标注。常见的有监督学习方法有隐马尔可夫模型和条件随机场。其中,条件随机场能够使用局部信息进行信息提取,但对于特征词与情感词之间的依赖关系这种信息并不能有效利用。对此,文中首先使用融合“SBV”,“ATT”,“COO”三种依存句法关系的条件随机场对句子中的特征和情感词进行抽取,然后利用已抽取的特征情感词构成一个二分网,最后使用一种基于点互信息的HITS算法来抽取特征和情感词对。
1 相关工作
1.1 无监督学习
基于高频名词通常是真实的特征的想法,Hu等[4]提出使用关联规则挖掘找到高频名词作为候选特征,然后使用剪枝挑选出的结果作为特征。基于这个研究,Popescu等[5]利用名词与产品类别之间的点互信息(PMI)来抽取产品特征。
除了使用频率的方法,利用语义规则提取特征也是一类重要的方法。Zhuang等[8]使用特征情感词之间的出现次数最多的依赖关系抽取电影评论数据集中的特征。Qiu等[9]考虑到句子中词间存在着直接关系和间接关系。直接关系就是两个词之间直接依赖或者都同时依赖同一个词。间接关系则是两个词之间都非直接依赖第三个词。因此,他们提出了基于直接关系的双向传播算法并设计一些规则来抽取语料库中特征和情感词。
此外,还有通过对候选特征排序来提取特征的方法。Eirinaki等[10]认为一个名词与越多的形容词进行搭配,那么这个名词越有可能是一个特征。基于这种想法,他们提出了HAC算法,通过对与名词搭配的形容词进行计数来确定名词的分数,搭配越多形容词的名词分数越高。Yan等[11]和Zhang等[12]分别利用PageRank算法和HITS算法根据候选特征和形容词之间的搭配关系以及共现频率对候选特征进行排序,从而识别特征词。
1.2 有监督学习
条件随机场(conditional random field,CRF)是由John Lafferty于2001年提出,是一种流行的用于结构化预测的概率方法,广泛用于各领域。该模型结构类似于有条件训练的隐马尔可夫模型,并且具有有效的推理算法[13]。
在近年来情感分析任务中,CRFs模型表现优异。在使用条件随机场时,最常使用的结构是线性链CRFs。为了解决长范围依赖关系问题和能够在同一序列上执行多个级联标记任务,Charles等[14]提出了动态条件随机场(DCRF)。它是线性链CRFs的泛化,其将每个时间片都包含一组状态变量和边,并且参数跨时间片绑定。Niklas等[15]为了解决模型的单一领域和跨领域的特征抽取问题,将词、词性、短依存关系、词距以及观点词作为输入特征。
2 基于CRF的特征和情感提取
条件随机场是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场[16]。假设X=(X1,X2,…,Xn)和Y=(Y1,Y2,…,Yn)都是随机变量,X是需要标注的观测序列,Y是X对应的标记序列。P(Y|X)是条件随机场所要构建的条件概率模型。无向图G=(V,E)表示由Y构成的马尔可夫随机场。
即:
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)
(1)
对任意节点v成立,则P(Y|X)为条件随机场。式1中,w~v表示节点v与节点w是无向图G=(V,E)中的邻居节点。Yv和Yw是节点v与w对应的随机变量[13]。
文中主要使用线性链条件随机场。线性链条件随机场中,随机变量X=(X1,X2,…,Xn)和Y=(Y1,Y2,…,Yn)都是线性链表示的随机变量序列,它可以被表示为:
P(Yi|X,Y1,…,Yi-1,Yi+1,…,Yn)=P(Yi|X,Yi-1,Yi+1),i=1,2,…,n
(2)
在情感分析任务中,特征情感词的提取可被看作为一个序列标注问题,因此可采用线性链CRF模型。下文中描述用作CRF模型输入的特征。
2.1 分词与词性标注
词与词性是在自然语言处理任务中经常被使用到的特征。这两个特征是将句子中当前词与该词的词性作为特征,两者对于特征和情感词的提取有相当大的影响。
对于句子的分词和词性标注都是通过哈尔滨工业大学开发的LTP(HIT-SCIR,Http://www.ltp-cloud.com/)。
2.2 依存句法关系
另外,文中使用了依存句法关系作为特征。依存句法关系的提取同样使用的是LTP。保留了三种特征、情感词间经常存在的依存句法关系,分别是定中关系(ATT)、平行关系(COO)和主谓关系(SBV)[17]。
2.3 特征模板
文中采用CRF++0.58工具包来执行模型的训练和标注。使用CRF++工具包需要设计特征模板。特征模板将从特征集中提取特征并添加到模型中。文中基于上述语言相关特征设计了特征模板。
表1展示了标注特征和情感词使用的模板。

表1 标注特征和情感词使用的特征模板
其中,t表示当前词的标记,w表示词本身,pos表示对应词的词性,dp表示对应词的依存关系标注。
3 评价特征和情感词对抽取
使用依存关系是提取特征-情感词对的一种常用方法,但是使用依存关系提取的特征-情感词对的效果依赖于句子语法表达的正确性以及依存关系的人工选择。为了避免以上问题,文中利用MHITS算法[17]来提取特征情感词对,其考虑了特征和情感词间的共现频率,以及特征与情感各自的重要性。
为了使用MHITS算法对特征-情感词对的值进行计算,首先需要构建特征-情感词二分网络。上阶段使用CRF提取的特征词和情感词分别作为网络中的权威节点fi和枢纽节点sj。在测试数据集中,同一句话中出现的任意两个特征词和情感词之间都存在着一条边eij。边eij的权重wij、权威节点的值p(fi)和枢纽节点的值p(sj)都使用MHITS算法进行计算。MHITS算法具体如下:
初始步:对于在全部数据集中特征词与情感词在同句话中出现过的词对的权重为其共现频次。其余网络中边的权重wij的初始值为1。
迭代过程:
权威(特征)节点:每个权威节点都更新为与其相连的枢纽节点的边权之和。
(3)
枢纽(情感)节点:每个枢纽节点更新为与其相连的权威节点的边权之和。
(4)
边权:边连接的权威节点和枢纽节点的点互信息。
(5)
其中,k表示当前的迭代次数;T表示权威节点fi连接的枢纽节点的集合;U表示枢纽节点sj连接的权威节点的集合;F表示所有权威节点的集合;S表示所有枢纽节点的集合。
第一轮迭代中网络的边权是根据特征词与情感词之间共现频率计算两者之间的点互信息,然后更新特征和情感节点的值,之后的每一轮都是根据上一轮的值计算边权和节点的值。
算法在不断迭代中收敛,最终结果会趋于平稳。根据MHITS算法计算的边权的值对(特征-情感)对进行排序,边权值大于某个阈值的节点对会被保存在最终列表中。
4 实验设置与结果分析
为了验证算法的有效性,使用京东商城上的评论数据进行实验。
4.1 实验数据
实验数据是Liu等[17]使用的评论数据集中的三种商品,分别是华为手机、洗面奶以及羽毛球拍,见表2。

表2 数据集
4.2 评价指标
文中使用精确率(P)、召回率(R)、F指标(F1)去评估模型的质量。精确率计算的是模型提取的所有特征或情感中正确的特征-情感词对的比例。召回率计算的是模型提取的正确的特征-情感对占评论中所有特征-情感词对的比例。F1指标是精确率和召回率的调和平均值。
其计算公式分别为:
(6)
(7)
(8)
其中,TP表示真正例,即模型提取出的正确的特征-情感词对;FP表示假正例,即模型提取出来的错误的特征-情感词对;FN表示假负例,是模型未能提取出来的评论中的特征-情感词对。
4.3 实验结果
文中首先使用融合词、词性和依存句法关系的线性链CRF提取特征和情感词。特征模板使用表1中序号1-7的模板。然后在CRF标注的情感词和特感词构建特征-情感网络并运行MHITS算法。对比的方法分别是:
依存关系:对评论进行句法分析后提取符合“SBV”,“ATT”,“COO”关系的特征情感对。具体的提取规则有5种,可分为“SBV”,“ATT”两个大类。具体提取的规则见表3。
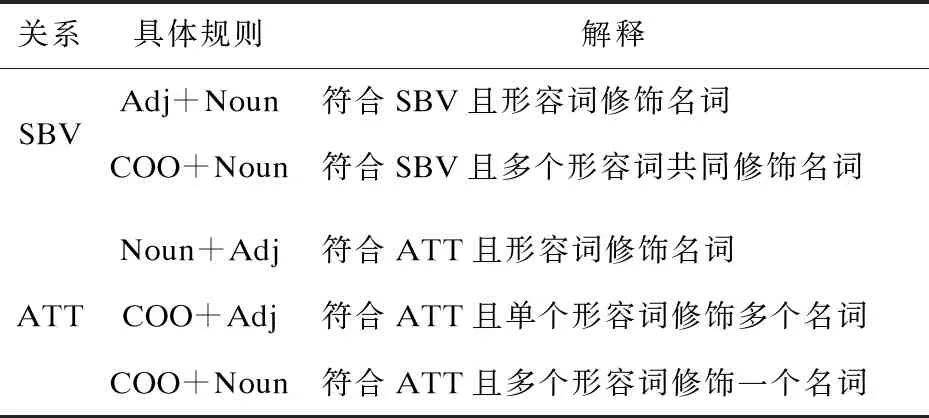
表3 提取特征情感词对的规则
依存+CRF:在使用CRF标注特征情感词后利用“SBV”,“ATT”,“COO”关系抽取特征-情感词对。
HITS+CRF:使用CRF标注的特征和情感词构建二分网,然后使用Zhang等提出的基于二分网的HITS算法对特征和情感词组成的词对进行排序[12]。
MHITS+CRF:使用CRF标注的特征和情感词构建二分网,然后使用MHITS算法对特征和情感词组成的词对进行排序。
实验使用排序的最佳阈值为在评论上的最高F值。最终在三个数据集上的结果如表4所示。
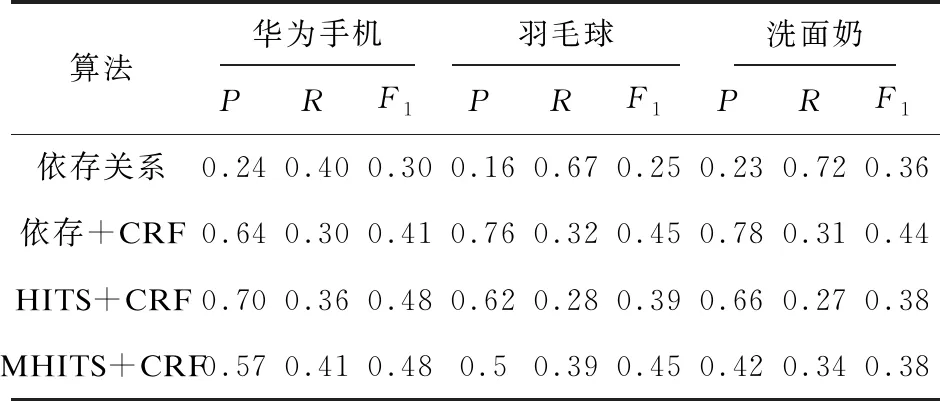
表4 在华为手机、羽毛球和洗面奶 数据集上的比较结果
从表4中可以看出,使用依存+CRF和HITS+CRF提取特征-情感词对具有较高的准确性,但召回率比较低。而仅使用依存关系则具有较高的召回率,准确率非常低。MHITS+CRF算法在准确率和召回率上都表现中等。
从表5可以看出,MHITS+CRF的平均F1值相对较高。
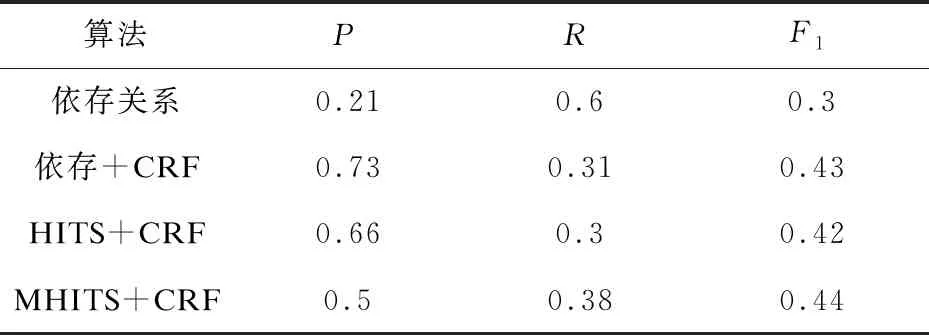
表5 在全部数据集上的平均值
通过比较依存关系和依存+CRF两种方法可以看出,使用CRF提取特征和情感后再使用依存关系提取特征情感对能够显著提升提取特征和情感对的效果。MHITS+CRF与依存+CRF、HITS+CRF方法比较之下,准确率较低,但是召回率较高。另外,由于MHITS算法考虑词对的共现频率,最终F1值稍高于使用HITS算法排序的结果。
5 结束语
文中提出了一种两阶段的特征-情感词对提取方法。首先使用CRF模型,融合词、词性、依存句法关系三种文本特征对评论文本中的特征和情感词进行识别,然后使用MHITS算法对特征-情感词对进行提取。实验结果表明,相较于基准方法,该方法在特征-情感词对的提取上取得了一定的效果。但该方法也存在一定的不足:使用的是有监督的CRF模型,需要预先标注大量的数据;会受到数据量大小的影响,特别是对于数据量小和特征与情感词少的评论效果较差。因此,下一步的改进方向是减少数据量大小对方法的影响。
