基于循环神经网络变体和卷积神经网络的文本分类方法
2019-07-22李云红梁思程李敏奇李禹萱
李云红, 梁思程,任 劼,李敏奇,张 博,李禹萱
(1.西安工程大学 电子信息学院, 陕西 西安 710048;2.国网西安供电公司, 陕西 西安 710032)
当前,互联网发展迅猛,每时每刻都会产生大量的文本信息。其中,如何将蕴含多主题、多字符的长文本进行有效的分类以及管理,进而快速了解长文本信息的价值,是许多研究者关注的焦点。文本分类主要包括文本表示、分类器的选择与训练、分类结果的评价与反馈等工作[1]。其中,文本表示是影响分类结果的关键步骤。词袋模型(bag of word,BoW)在文本表示中应用最为广泛[2],它将文本表示为高维度,高稀疏的One-hot向量。但One-hot向量因未考虑文本的语序和上下词之间的联系,词之间相互独立,导致文本信息大量丢失。为了克服词袋模型文本表示的缺陷,Hinton[3]提出了词向量(distributed representation)的概念。Bengio等[4]通过神经网络模型训练词向量进行文本表示。Mikolov等[5-6]提出建立Skip-gram和CBoW神经网络模型,提升了词向量训练的效率,提高了短语和句子等短文本分类的性能。Le和Mikolov等[7]提出了PV-DM(distributed memory model of paragraph vectors)神经网络模型,考虑了文本的语序信息,将文本表示为定长的句向量或者段落向量,使句子级的文本分类研究成为可能,为本文对长文本分类的特征表示提供了依据。
在文本的分类器训练方面,浅层朴素贝叶斯[8]、支持向量机(SVM)[9]、最大熵模型[10]等机器学习模型在词、短语和句子等短文本分类中被广泛应用。Mikolov等人[11]提出了基于时间序列的循环神经网络(recurrent neural networks,RNN)模型,解决了浅层机器学习模型对关联性强的样本分类效果差,无法学习到类别内信息等问题,改进了文本分类的性能。Chung等人[12]针对RNN网络随着网络层数的增加会面临梯度爆炸或梯度消失的问题,提出了GRU(gated recurrent unit)网络结构,改善了长文本分类的性能。薛涛等人[13]将卷积神经网络(convolutional neural network,CNN)用于文本处理,通过共享权重提升了文本分类器的性能。Collobert和Weston等人[14]将词向量和多层一维卷积结构用于自然语言处理。Kim等人[15]进一步优化了CNN结构,提出了动态窗口与词向量频道结合的方法改进文本特征的提取,在文本分类任务中取得了良好的效果。
综上所述,现有文本分类研究集中在短语、句子等短文本分类,专门针对长文本分类的研究较少。本文针对长文本的分类问题,考虑到长文本的语序对长文本分类的影响,提出基于循环神经网络变体GRU和卷积神经网络(CNN)的BGRU-CNN混合模型,经SogouC和THUCNews长文本中文语料集的测试取得了较好的分类效果,提高了分类性能,验证了论文提出混合模型对长文本分类的有效性。
1 长文本分析及句子表示方法
1.1 长文本特性分析
在文本分类研究中,文本内容的长度一般没有明确的定义,它只是一个相对概念,但是,其对分类的效果与速度会产生较大的影响。互联网上的网络评语、微博等都属于短文本,新闻文本、科技论文等都属于长文本。以本文实验采用的THUCNews和SogouC和数据集为例,其文本长度分布分别如图1和图2所示。
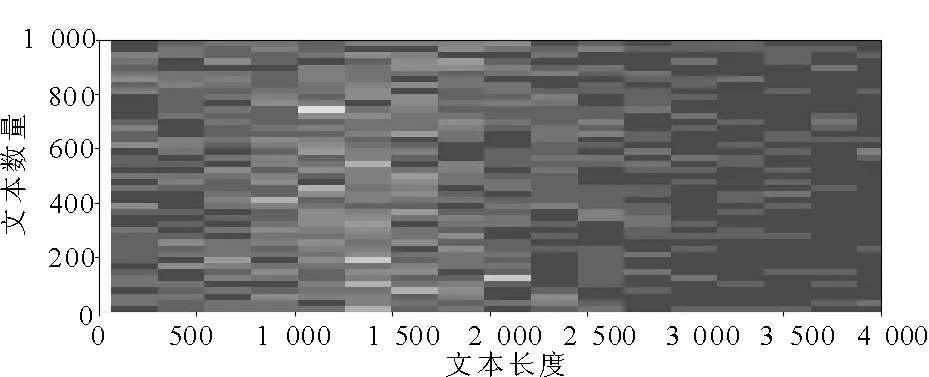
图1 THUCNews文本长度Fig.1 THUCNews text length

图2 SogouC文本长度Fig.2 SogouC text length
从图1可见,THUCNews数据集文本长度在500~2 000之间占到了绝大多数。从图2可见,SogouC数据集文本长度在500~1 500之间占到了绝大多数。因此,从总体来看,本文采用的两个数据集都属于长文本。长文本相较于短文本而言,会围绕主题进行更多的补充性说明和描写,如“本次调查结果表明”,“几天之后”等。另外,长文本句子结构完整,语法规范,常常包含许多转承关系的词语,如“新华网深圳3月3日电”,“据统计”等这些与主题相关性小的句子,会使分类时产生比较大的分析代价。
1.2 文本特征表示
词向量是目前广泛使用的文本特征表示的方法,长文本分类时,因其句子数、段落数多,仅用词向量难以表达复杂的文本语义,且训练耗时过长,结果不理想。因此,本文结合词向量生成模型,采用PV-DM模型,使用无监督的方法生成文本的段落向量,结构如图3所示。
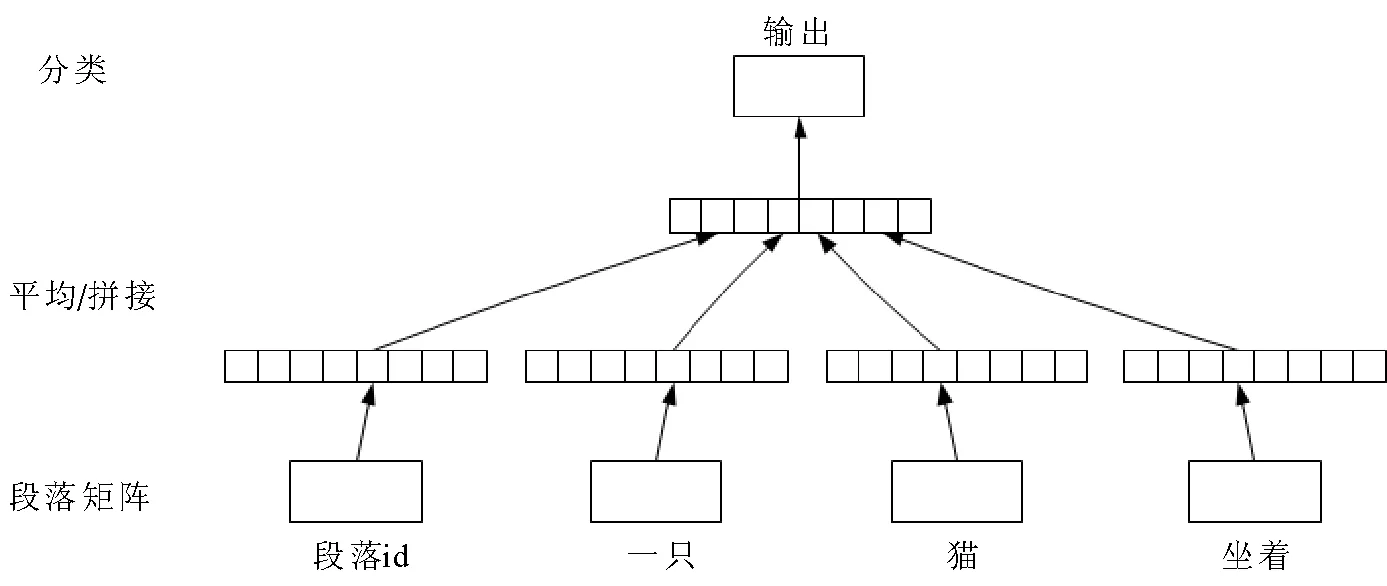
图3 PV-DM模型结构Fig.3 PV-DM model structure
通过图3建立PV-DM模型获得句向量的表示。文本通过神经网络训练得到词向量W,将词向量W与段落矩阵D拼接在一起。把词向量序列w1,w2,…,wr所在段落标为dm,则模型的目标最大化平均对数表示为
(1)
使用Softmax分类器进行分类工作,表示为
(2)
其中,yi的计算公式为
y=b+Uh(wt-1,…,wt+k,dm)。
(3)
式(3)中,U,b分别为Softmax分类器的权重和偏置,h由W和D拼接构成。新增段落id可以被看作新的词,每预测一个词,就使用该词所在段落的段落id作为新增加的输入。在一个文本的训练过程中,段落id保持不变,共享着同一个段落矩阵。使用随机梯度下降法训练所有参数,训练结束后得到定长的实向量,即段落向量(本文称为句向量)。
将长文本中长度各异的句子表示为定长的句向量,可以进行句子级的文本分析,提高了长文本分析的速度。
2 BGRU-CNN混合模型的构建
2.1 建立BGRU-CNN模型
BGRU-CNN混合模型的整体结构如图4所示。BGRU-CNN混合模型的输入为文本T,经过循环层捕捉句子上下文信息,卷积层提取文本的关键特征,输出为文本T属于类别k的概率。
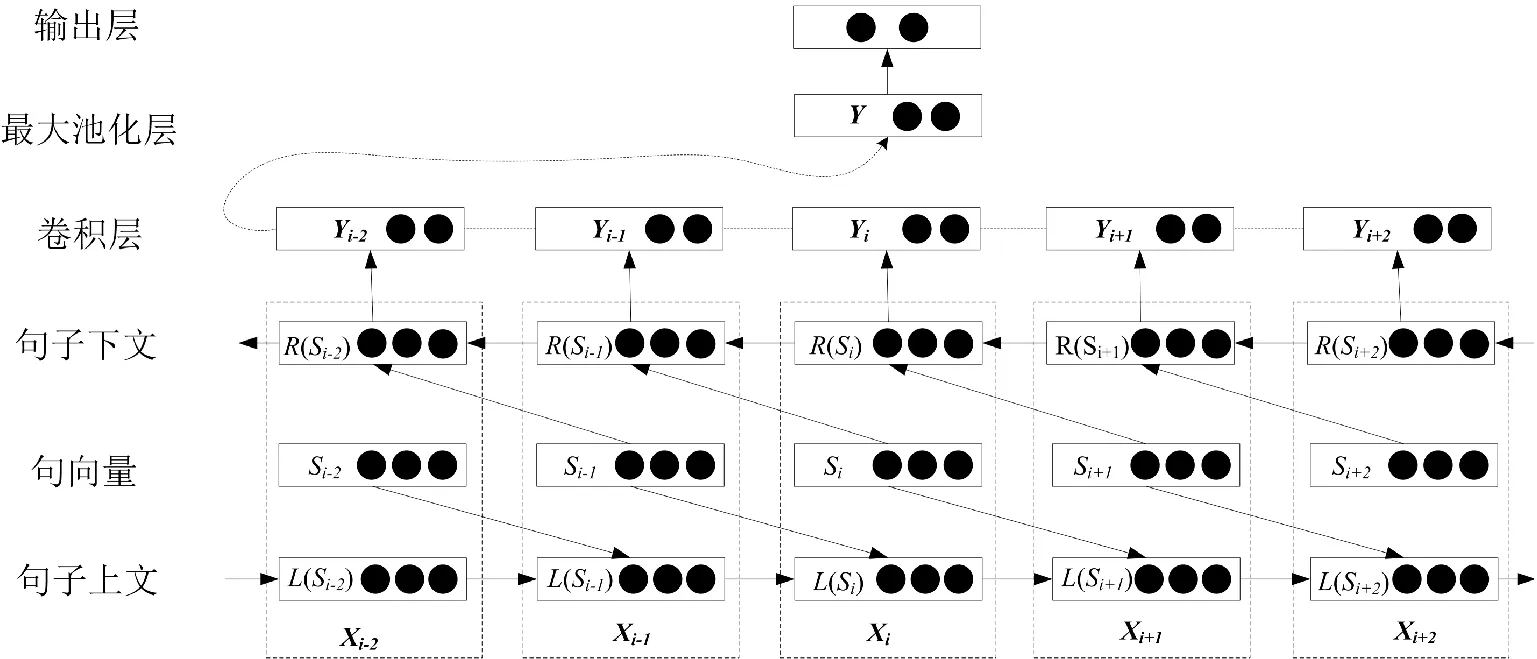
图4 BGRU-CNN模型架构Fig.4 BGRU-CNN model
1)循环层
采用双向循环结构捕获第i个句子Si上文L(Si)和句子下文R(Si)的信息,计算方式为
L(Si)=f(Wl,L(Si-1)+Wsl,e(Si-1)),
(4)
R(Si)=f(Wr),R(Si+1)+Wsr,e(Si+1))。
(5)
式(4)中,e(Si-1)表示句子Si-1的句向量,L(Si-1)表示句子Si-1的上文信息,Wsl表示Si句子和Si-1句子语义信息组合的权阵,Wl为隐藏层的转换权阵。f为激活函数。
然后,通过式(6)将上文信息L(Si)、句向量e(Si)和下文信息R(Si)拼接,构成文本特征向量xi作为循环层的输出。
xi=[L(Si),e(Si),R(Si)],
(6)
双向循环结构输出的文本特征向量xi学习了文本上下文的语序信息,作为卷积层的输入,进一步提取文本语义特征。
2)卷积层
在循环层获取文本特征向量xi后,使用CNN网络进行特征yi的提取,计算方式为
yi=f(ω·xi:h+b)。
(7)
其中,卷积核用ω∈Rhk表示,h和k分别表示卷积核的窗口高度和宽度,用来对循环层的输出xi进行卷积。xi:h表示输入特征向量第i行到第h行的特征值。b为偏置,f为激活函数。获取所有yi后,通过式(8),构建关键特征图Y。
Y=[y1,y2,…,yn],
(8)
然后使用最大池化层来确定文本的最佳特征,计算方式如式(9)所示,
y=max(yi),i=1,2,…,n。
(9)
得到最佳特征y,将这些特征输入分类层分类。分类层采用dropout方式将最佳特征y连接到Softmax分类器中。dropout算法随机将最佳特征y按一定比例置0,其他没有置0的元素参与运算。由于每一次输入特征向量后,置0的方式都是随机的,因此网络权重参数每一次都得到了更新。直到所有样本都被训练完成。因为每次网络权重参数都不相同,dropout算法将神经网络变成了多种模型组合,有效地防止了过拟合,提升了模型预测的精度。
Wc和bc分别表示Softmax分类器的权重参数和偏置项,通过dropout产生的向量记为cd,则其输出O的计算方式为
O=Wccd+bc,
(10)
最后,预测文本属于第k类的概率的计算方式如式(11)所示。其中,Ok表示输出向量O中的第k个元素,N表示类别数。
(11)
2.2 BGRU-CNN模型循环层计算节点
论文对长文本进行分类, 在一篇长文本中, 往往包含十几甚至几十个句子, 以当前句子为中心, 中距离或者长距离句子的语序与当前句子所要表达的语意相关。 而RNN网络采用的计算节点无法很好地处理这种依赖, 未能完全学习长文本句子语序特征, 因此, 将RNN网络的计算节点替换为GRU计算节点, 使模型学习到更完整的长文本句子语序特征。 图5为所采用的GRU结构, GRU网络节点通过重置门r和更新门z对输入信息进行处理。t时刻的激活状态ht计算方式如式(12)。
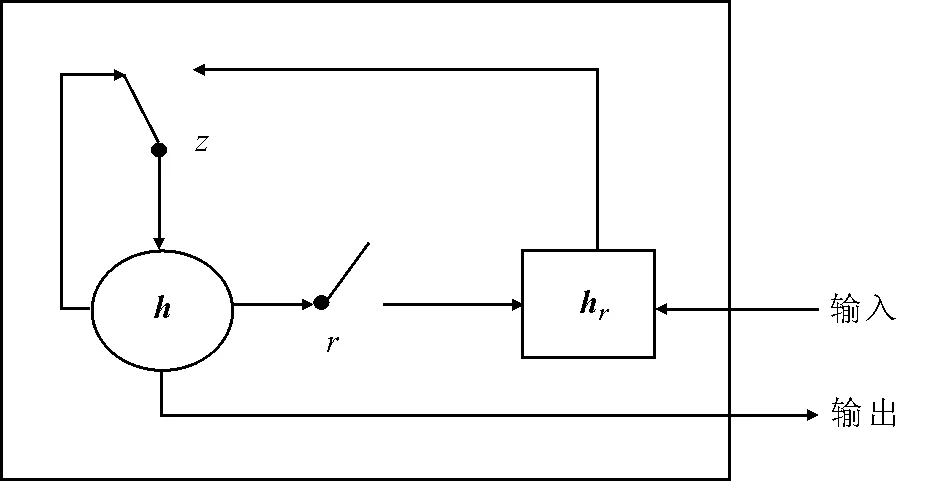
图5 GRU计算节点Fig.5 GRU computing node
ht=(1-zt)⊗hc+zt⊗ht-1,
(12)
ht-1是t-1时刻的激活状态,与ht呈线性关系,⊗表示向量矩阵对应元素相乘,zt表示t时刻更新门的状态,计算方式为式(13)。t时刻激活状态hc的计算方式如式(14),重置门rt的计算方式如式(15)。
zt=σ(Wzxt+Uzht-1),
(13)
hc=tanh(Wxxt+U(rt⊗ht-1)),
(14)
rt=σ(Wrxt+Urht-1)。
(15)
σ为sigmoid函数,xt是t时刻该节点输入的句向量,Wz,Wx,Wr和Uz,U,Ur是更新门z、当前候选的激活状态hc和重置门r要训练的权重参数。更新门z和重置门r都使用了σ函数,将两个门的输出都限定在[0,1]之间。hc使用r来控制包含过去时刻信息的上一个激活状态的流入,如果r近似于0,那么上一个激活状态将被丢弃,因此,r决定了过去有多少信息被遗忘。ht使用z来对上一个激活状态和候选状态进行更新,如果z近似于0,那么ht不会被更新,z可以控制过去激活状态在当前t时刻的重要性。
通过GRU计算节点更新门和重置门的设置,改善RNN在学习长文本语序时,无法很好地处理中远距离句子依赖的问题,学习到更加完整的上下文语序特征。
2.3 训练BGRU-CNN模型

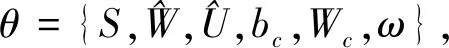
(16)
经过神经网络训练,找到最小代价的θ,如式(17)所示,

(17)
其中,D为训练的文档集,p(classT|T,θ)表示文档T在参数θ下属于目标类别classT的概率。在实验中采用随机梯度下降方法训练BGRU-CNN模型,则θ的更新式为
(18)
其中,α为学习率。如果α太小,导致网络收敛速度太慢,太大会导致无法收敛。经过多次实验验证,α设置为0.01时效果最好。
3 实验过程
实验采用THUCNews,SougouC中文语料库进行文本分类任务,对提出的BGRU-CNN模型进行评估。
3.1 数据集
1)THUCNews数据集
THUCNews数据集是根据新浪新闻RSS订阅频道2005—2011年间的历史数据筛选过滤生成,划分了14个不同的类别,包含了74万篇新闻文稿。实验选取其中的12个类别作为分类标签,每个类别标签选取8 000篇文本,共计96 000篇文本。
2)SogouC数据集
SogouC数据集来自搜狐新闻2012年6~7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据。实验选取10个类别作为标签,每个标签300篇文本,共计3 000篇文本。
3.2 实验测试
采用Tensorflow平台对论文提出的模型进行实验测试,该平台集成了多种深度学习模型,如CNN,RNN和LSTM等。由于实验数据集未进行训练集、验证集、测试集的划分,所以对本次实验的数据集按照7∶2∶1的比例进行划分,具体如表1所示。
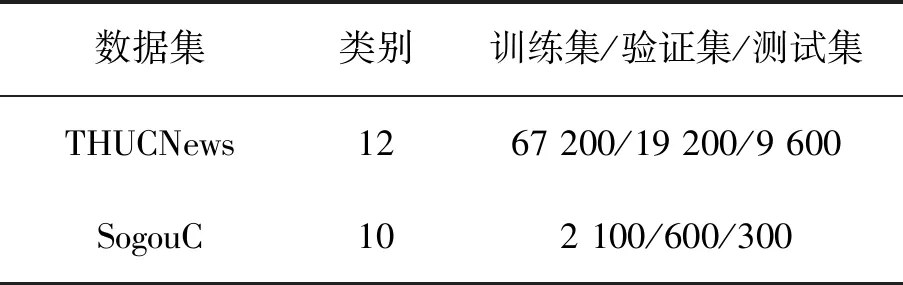
表1 数据集划分Tab.1 Data set partition
1)数据集预处理
采用wiki百科中文语料集,通过PV-DM模型训练句向量,句向量维度为300维。对数据集采用jieba中文分词进行预处理,对数据集进行分词,去除停用词,标点符号。
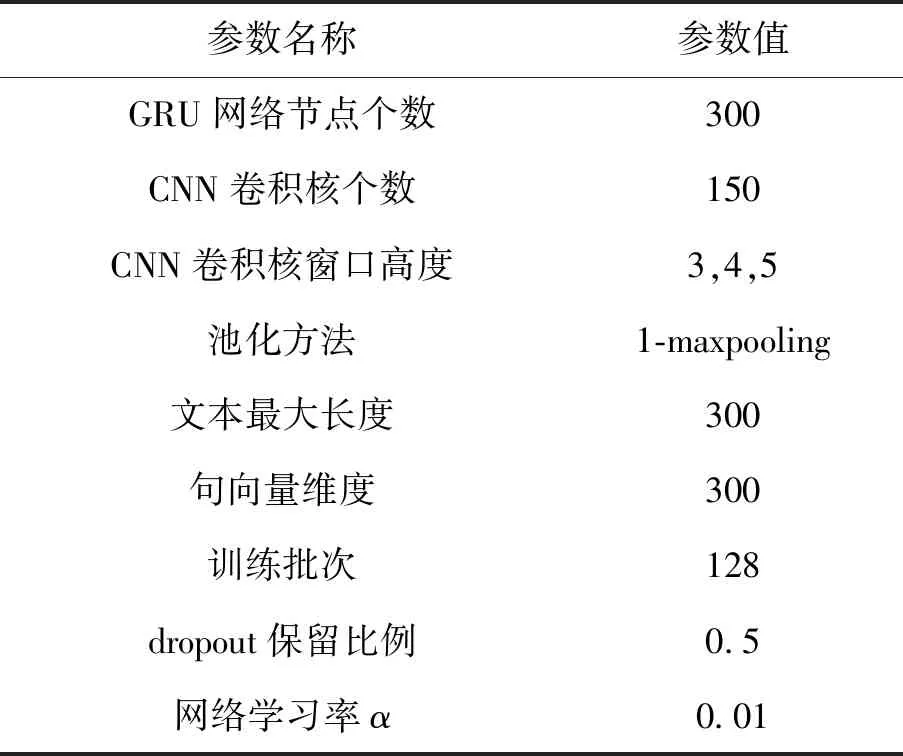
2)实验参数设置
BGRU循环网络的隐层节点数设置为600,学习率为0.01,BGRU的隐层状态作为CNN卷积层的输入;CNN卷积网络模块的卷积核窗口大小设置为3×150,4×150,5×150;选择relu作为激活函数。池化层通过采样,选择最佳特征;Softmax层采用L2正则项防止过拟合,参数为0.2;dropout参数设置为0.5。具体实验参数设置如表2所示。
采用文本分类常用评估指标准确率(P)、召回率(R)和F1值对BGRU-CNN模型的有效性进行验证。令TP,FN,FP和TN分别代表正阳性、假阴性、假阳性和正阴性的分类数量,则评估指标的表示如式(19)所示,
(19)
3.3 实验结果与分析
将BGRU-CNN模型与CNN,LSTM,GRU,B-LSTM,B-GRU这5个文本分类模型在THUCNews数据集和SogouC数据集上采用表2的超参数进行文本分类任务。通过准确率、召回率及F1值等评估指标进行结果分析,证明了BGRU-CNN模型的有效性。
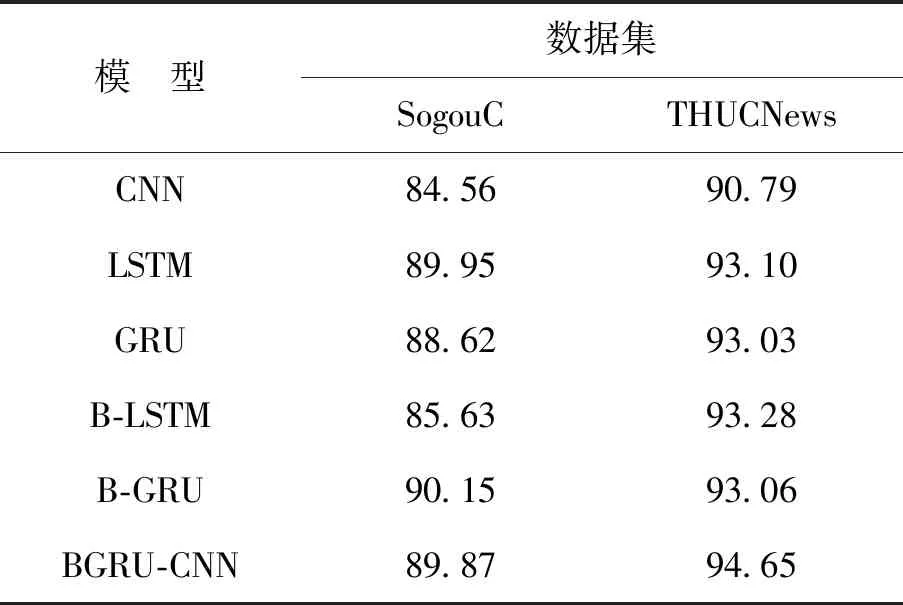
表3 数据集分类准确率Tab.3 Classification accuracy of data sets %

表4 数据集分类召回率Tab.4 Data set classification recall rate %
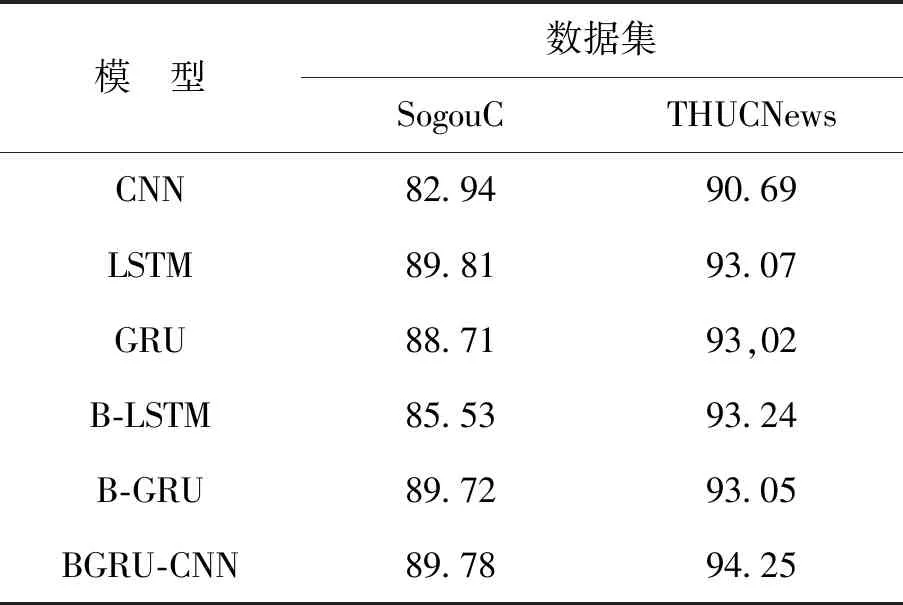
表5 数据集分类F1值Tab.5 Data set classification F1 value %
通过表3~5的实验结果可以得出:
1)BGRU-CNN模型与CNN模型的分类结果进行比较。BGRU-CNN模型评估指标均高于CNN模型,得出了GRU模型对文本语义的学习提高了文本分类的结果。
2)BGRU-CNN模型与LSTM,GRU,B-LSTM模型的分类结果进行比较。在SogouC数据集中,BGRU-CNN模型评估指标接近LSTM模型,高于其他两个模型。在THUCNews数据集中,B-LSTM模型评估指标高于其他3个模型,得出了双向循环GRU网络结构提高了文本分类的结果。
3)BGRU-CNN模型和B-GRU模型的分类结果进行比较。在SogouC数据集中,BGRU-CNN模型的分类准确率低于B-GRU模型,但其召回率和F1值却高于B-GRU模型。在THUCNews数据集中,BGRU-CNN模型的评估指标均高于B-GRU模型,得出了BGRU-CNN模型通过卷积层学习到了更深的文本特征,提高了文本分类的结果。
4 结 论
论文将提出的BGRU-CNN模型应用于中文文本分类,通过中文数据集SogouC和THUCNews进行模型评估,验证了BGRU-CNN模型的有效性及优越性。在相同超参数下,将BGRU-CNN模型与CNN,LSTM,GRU,B-LSTM,B-GRU等模型进行对比实验,表明BGRU-CNN学习了文本的语义信息,卷积层优化了循环层提取的文本序列特征,提取了文本关键特征。以后的研究将以此为基础,一方面通过改进卷积层的结构,使其动态提取多个关键文本特征;另一方面,计算相对于超参数的梯度,使用梯度下降进行超参数的优化。通过以上两方面对文本分类模型进行优化,展开进一步的研究。
