最新商用智能驾驶计算机方案与展望
2019-07-22袁沂
袁沂
(睿驭汽车(北京)有限公司,北京 100015)
主题词:智能驾驶 车载计算机 ASIC GPU FPGA 加速器 深度学习
缩略语
ADAS Advanced Driver Assistance System
(先进驾驶辅助系统)
CPU Centre Processing Units(中央处理器)
GPUGraphics Processing Unit(图形处理器)
FPGA Field-Programmable Gate Arrays
(现场可编程门阵列)
ASIC Application-Specific Integrated Circuit
(专门应用的集成电路)
ODD Operational Design Domain
(设计运行范围)
DDT Dynamic Driving Task(动态驾驶任务)
OEDR Object﹠Event Detection and Response
(物体、事件探测和反应)
ADS Automated Driving System
(自动驾驶系统)
DET Object Detection Engine(目标探测引擎)
TRA Object Tracking Engine(目标跟踪引擎)
LOC Localization engine(定位引擎)
DNNs Deep Neural Networks(深度神经网络)
RISC Reduced Instruction Set Computing
(指令集)
SoC System on Chips(系统级芯片)
LUT Look Up Table(查表法)
DSP Digital Signal Processors
(数字信号处理器)
AD Autonomous driving Domain
(自动驾驶域)
NPU Neuronal network Processing Units
(神经网络处理单元)
VMP Vector Microcode Processor
(矢量微码处理器)
TOPs Trillion Operations Per Second
(每秒万亿次运算)
1 前言
近几年随着深度学习、机器视觉、车联网和传感器等技术的蓬勃发展,使得高级辅助驾驶,甚至全自主无人驾驶汽车的商用化成为可能。目前不同的科技公司都在加紧向这个产业链的相关领域进行持续的科研和产业化投入。其中,既有大力推广云服务的Google、Uber、Baidu等互联网翘楚,也有老牌的通用、造车新锐、特斯拉(Tesla)等这样的整车制造商,更没有缺席像Inter、NVIDIA这样的半导体巨头。为了实现更高级的辅助和自动驾驶,厂商们将各种最新科技集合到一台汽车终端上,并陆续推出了不同技术路线的自动驾驶平台和服务方案。
互联网公司将更希望占据在业务整合上的顶端优势,通过高精度地图云服务和强大的无线网络,构建一个人与车、车与车、物(基础设施)与车之间的有机互连,以提供一个安全智能化的自动驾驶方案。整车厂商则更着眼于当前相对成熟的技术,通过集成各种传感器和装载高性能的本地计算机,并通过产品的快速迭代实现从高级辅助驾驶到全自动驾驶的快速进化。而已经投身相关领域的各半导体公司,作为车载超级计算机和硬件加速器的提供商,其技术路线之竞争则愈演愈烈,从未停止。
本文将从原理框架、性能对比和商用实例三个角度,对三种主流自动驾驶加速器方案GPU、FPGA和ASIC进行论述和对比,以对未来的技术方向进行有依据的预测。
2 背景介绍
2.1 自动驾驶汽车分级
根据SAE美国机动车工程师协会最新发布的标准SAE J3016TMJUN2018,从驾驶员参与车辆驾驶控制的程度,将其分为6个等级,即从Level 0到Level 5[1]。
Level 0:无自动驾驶,驾驶员必须独立完成驾驶的全部操作任务;
Level 1:驾驶辅助,自动驾驶系统和驾驶员可以分享对汽车运行的控制,自动驾驶系统在设计运行范围内(ODD)可以持续的执行动态驾驶(DDT)任务,包括纵向和侧向运行控制,但不能同时进行纵向和侧向控制,驾驶员需要完成其余的设计运行范围内的汽车运行控制,如在限定路段可实现自动巡航,驾驶员需保持对车辆的控制并完成如车道变换等任务(驾驶员双手不可以离开方向盘)。
Level 2:部分自动驾驶,自动驾驶系统在设计运行范围内(ODD)可以持续的执行动态驾驶(DDT)任务,包括同时进行纵向和侧向运行控制,自动驾驶系统可以在限制路段完全控制方向盘、加速和制动踏板。同时,驾驶员保留对车辆的控制权(驾驶员双手不可以离开方向盘)。驾驶员要保持对车辆周围物体和事件探测和反应(OEDR)。
Level 3:有条件自动驾驶,自动驾驶系统(ADS)在ODD持续执行全部的动态驾驶任务(DDT),即ADS可以完全接管驾驶控制权。当驾驶员被系统要求介入驾驶控制的时候,驾驶员必须要介入控制(在限定路段,如封闭高速路开启自动驾驶模式,驾驶员可以释放方向盘),包括其它车辆出现故障时驾驶员能做出适当的反应。
Level 4:高级自动驾驶,ADS系统在限定路段可以完全接管驾驶控制权,持续完成ODD范围内的动态驾驶任务(DDT),驾驶人员对动态驾驶任务不需要进行响应,可继续实施自动执行动态驾驶任务,当需要时驾驶员要对ADS进行干预。
Level 5:全自动驾驶,自动驾驶系统可以在全路段、路况条件下执行动态驾驶任务(即不限ODD),无需驾驶员介入,当需要时驾驶员要对ADS进行干预。
这6个级别通常被定义为L-0无自动驾驶,L-1辅助驾驶,L-2部分自动驾驶,L-3有条件自动驾驶,L-4高级自动驾驶,L-5全自动驾驶。
在这里举例说明,Tesla的Auto-pilot 2.5功能是介于L-2和L-3之间的自动驾驶模式,并未达到L3的要求,从法规角度驾驶员的双手是不可以离开方向盘的。
2.2 自动驾驶原理简述
自动驾驶系统属于一种“端到端”的控制系统,即系统需要对输入进行实时处理和响应(输出)。从安全性和商用性的角度来看,该系统对响应速度、可预测性、能耗效益等方面有严格要求。当前最广泛采用的自动驾驶系统,其输入是从车上多种不同类型传感器获取的周围环境空间量化的物理信息和视觉数据流,在自主行驶过程中不断传递给车载计算机。数据再通过结构化和流程化的算法实现对车辆周围环境和物体的感知、定位和跟踪。标定数据再通过熔合算法建立一个厘米级精度的实时3D地图,并结合顶层的平面地图导航应用,制定车辆行进路线和运动轨迹。并最终控制车辆行驶的执行机构,实现精确运动和紧急情况快速反应。Shih-CHieh Lin总结了当今全球最先进的自动驾驶系统[2],如图1。
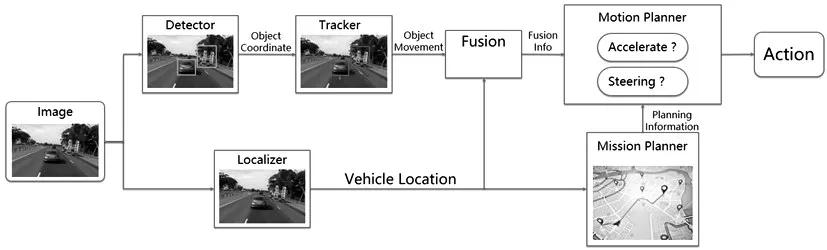
图1 确定车辆行进路线和运动轨的自动驾驶系统[2]
图1 是一种基于摄像头图像传感器的端到端自动驾驶方案。首先,车辆摄像头获取连续帧图像,其数据流同时提供给系统内的物体识别引擎(Detector Engine)和物体定位引擎(Localizer Engine)。识别引擎用算法提取图像中的相关物体,如车辆、行人、标志标线或其他基础设施等。后续的跟踪引擎(Tracker Engine)会对识别出的物体进行持续跟踪。与此同时,定位引擎会根据前后帧图像的相关性来判定车辆自身位置是否变化,并通过量化算法确定相对位置,进而实现车辆的自我定位。定位信息和周围物体信息经过融合后,一个包含各种物理环境数据的3D坐标空间在融合引擎(Fusion)中建立起来。接下来的车辆动作规划程序(Motion Planner)根据空间环境情况,制定行驶路径,优化行驶动作,并通过行车控制器对车辆的方向机、加速器和制动器进行一系列的操纵,完成车辆的行进、转向和控速等运动组合。
而路径规划(Mission Planner)软件使用网络地图(Google或Baidu地图等),结合实时交通信息和GPS技术,规划从当前位置到终点的全径路线。且在车辆偏离导航路线时,告知动作规划控制器,修正或者重新制定新的路线。
上述流程可以看作一个最基本的通过机器视觉和深度学习算法实现自动驾驶的模型。但实际上最新的L2以上的自动方案需要包含前向窄角远焦摄像头、前向中距摄像头、前向广角近焦摄像头、左前和右前广角摄像头、左后和右后广角摄像头,以及后看摄像头等多个以上的图像传感器来实现360度的环境探测,并且还需要多个毫米波和超声波雷达提供周围物体的精度距离,包括角度和速度等信息需要输入融合引擎,以支持高精度3D地图的建立和控制动作的准确性,进而确保行驶安全(图2)。由此,可以看出吞吐和处理如此海量的传感器数据(特别是摄像头的图像数据)对自动驾驶计算机的处理能力挑战可谓空前。即使是现在最优化的算法和硬件架构,系统不可避免的产生一定的延时。基于人车安全的要求,自动驾驶系统响应的延时要求是非常苛刻的。随着高级自动驾驶技术的发展,对自动驾驶计算机的各种性能提出了极大的挑战,高性能的车载计算机技术也推动了自动驾驶汽车的发展。
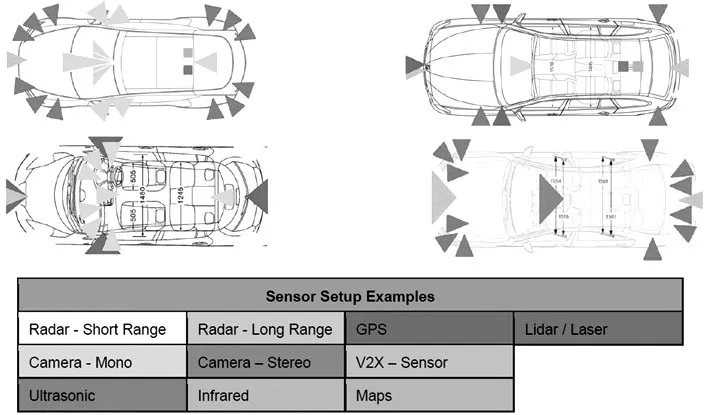
图2 智能驾驶汽车感知系统[3]
3 自动驾驶系统性能要求
3.1 自动驾驶系统的性能约束
对于自动驾驶系统主要有4个约束项目:
(1)计算机性能约束;
(2)可预测性延迟约束;
(3)散热性能约束;
(4)电力功耗约束。
3.1.1 AD计算机性能约束
自动驾驶计算机的性能主要体现在系统对实时路况的响应速度上。系统必须能参与交通,比如对路上的标牌、地标和标线的识别,对突发情况的处理,避让行人、车辆或其他物体。以摄像头为例,其响应速度体现在每秒钟输入给计算机的帧率上。典型的驾驶员放开加速踏板要用960 ms,踩死刹车要用2.2 s,用方向盘避让物体反应平均在1.64 s[4],最快的专业赛车手在紧急状况下的反应也需要100 ms~150 ms以上[5]。所以自动驾驶对摄像头刷新率的最低需要是不能小于10帧/s。为了应对不断变化的交通环境,对每个相关帧从获取到分析,再到决策控制,其总延时不能超过这个帧周期,这样才能保障相邻帧图像的分割处理,同时不产生控制延迟或者决策覆盖等问题。
基于以上可以做一个小计算,如果一个自动驾驶系统有8个1 080×1 920分辨率的8 bit RGB摄像头,每秒要10帧。系统共8个摄像头,这个计算机需要1 080×1 920×3×8×10×8=3.8 Gb/s的数据吞吐和处理能力。这还不包括其他传感器或更高的帧率要求的情况。
所以在响应时间约束和处理数据数量级的要求下,选择一个处理能力符合要求的硬件系统是实现自动驾驶计算性能的关键之一。
3.1.2 可预测性延迟约束
在自动驾驶各种数据处理和运算中,机器视觉算法占用系统资源最大,而对周围物体的识别DET、跟踪TRA和自身定位LOC占用了车载计算机99.4%的算力[2]。在摄像头捕获连续帧图像的同时,计算机几乎全力在做各种运算处理。无论采用什么硬件平台和串行还是并行架构,从一帧图像输入到执行动作,都会产生尾延迟。车辆周围的环境、物体、气候状况是极为多样和随机的,所以评估一个系统的可预测性的处理延迟,可以定义为平均延迟和统计上的99.99%占比可能性的可测延迟两个参数[2]。比如,一个系统执行TRA算法时,其平均延迟可能是50 ms,但是其99.99%占比时,其延迟可能要到达近300 ms[2]。从上文定义的自动驾驶汽车响应速度来讲,300 ms显然高于100 ms的基本要求[2]。这就是对车载自动驾驶计算机执行一系列算法时的可预测性约束评估。
3.1.3 散热性能约束
一般工业标准的电子元件额定工作环境温度上限为85℃,而车载电子元件则要求到105℃[6]。因为发动机舱的电控单元ECU需要忍耐这种极限环境。可是对于普遍的工业级计算机其工作环温是不可超过75℃。这就意味着当前无论那种自动驾驶计算机平台都只能设置在乘员舱,即车上环境温度一般在60℃以内。
同时因为巨大的计算量会使半导体处理器持续发热,所以用散热装置为芯片降温是非常必要的。通过导出芯片表面热量,确保处理器内部结温在安全范围可控。这样才能保证自动驾驶计算机的安全运行,防止处理错误,甚至系统崩溃导致的行车安全问题和事故。
散热约束聚焦在这两个方面,一是保证芯片工作的环境温度,二是将大功率IC(如处理器、功率放大器等)降温。当前汽车上散热设计是个非常重要而独立的系统,而自动驾驶计算机多采用个体风冷或中央水冷系统。
同时,散热也是需要电能和制造成本,而这又与下文所述的电力功耗约束产生了矛盾。在后续章节,会讨论不同硬件平台的功耗,实例说明散热方法。
3.1.4 电力功耗约束
对于汽油轿车,其发电机工作时典型功率消耗在1~2 kW[7]。如果增加一个400 W左右的自动驾驶计算机负载,它每加仑汽油行驶里程会减少3.23%[8]。而对于执行L4及以上自动驾驶功能的插电式新能源汽车(PHEV),其自动驾驶计算机也会使单次充电的行驶里程减少11.5%[2]。对于电动车,续驶里程参数非常重要,是消费者选择电动车品牌时的重要指标。而不同结构自动驾驶平台其功耗差异非常大,计算能力、散热和功耗之间的平衡是未来硬件平台协调发展的主题。
3.2 不同平台的算法和性能差异
在对比不同自动驾驶硬件方案之前,可以先简单讨论一下当前自动驾驶的几个重要算法。从软件定义硬件的思路,反应了要解决一个实际的应用,首先要确定软件架构,采用何种算法,然后基于特定算法,从性能和成本的角度设计出相对平衡的硬件执行结构和配置。
自动驾驶技术是要实现一种端到端的控制系统。一端是从周围环境获取各种物理信息的传感器,一端是根据系列运算做出决策和动作执行的机构。中间则是对各种传感器数据进行组织和融合,进而重构一个空间地图,为决策和动作提供依据。
自动驾驶的主要任务包括对周围物体探测(DET)、跟踪(TR)、自身相对位置的定位(LOC)、以及3D地图融合(Fusion)、动作的规划和任务的规划。尽管近年来对其算法不断优化,但DET、TRA和LOC仍然占用整个系统85.9%~99.4%的计算资源。
其中DET和TRA可以采用最新的DNNs(Deep Neural Networks)算法,而特征提取(Feature Extraction,FE)算法则是LOC的基础。其中DNNs算法在通用计算机上有非常大的延迟,比如DET的性能约束要求延迟不能大于100 ms[2],但是通过特定测试,传统多核计算机还是要消耗7 734 ms。即便是相对接近约束条件的LOC FE算法也高出最低标准近200 ms,在294 ms以上[2]。这可以看出多核通用CPU是无法支撑商用的自动驾驶方案的。究其原因,是因为传统计算机都是基于单线程任务的,即使采用多核CPU,也仅是×2、×4、×8之类的倍增。但深度学习需要计算处理模型偏向于多层网络阵列结构,是对大规模的并行结构的需求。这是传统CPU,包括X86、RISC结构无法适应的。就像人们要玩高渲染要求的3D游戏一样,需要通过加一块高性能的显卡一样,最好的解决方案就是给自动驾驶计算机也加一块有强大并行处理能力的加速器,即采用CPU+加速器(Accelerator)的硬件结构。
同时从配置的角度,主要是从采用单核CPU转向采用多核CPU。还有CPU能提供的最大工作时钟或运算速率需要加强。加速器采用的方案也很重要,目前FPGA方案还是基于嵌入式SoC的内嵌硬核IP加速器。同时还要根据软件的要求来评估内存的容量和速度等参数。
当今有三种主流的“自动驾驶”或是说“深度学习”硬件加速器的方案和它们的实现方法,即GPU图形加速器、FPGA可编程逻辑门阵列和专用的深度学习“神经网”络嵌入式ASIC加速器,他们都在并行处理方面有自己的独特的技术诀窍。
既然是加速器,它们是执行专有的算法,极大的提高系统在处理感知、跟踪和定位等运算的速度,进而达到自动驾驶苛刻的性能约束要求。从CPU分类角度,既有支持MIPS+Accelerator的厂商,如Intel的Mobileye EyeQx,也有ARM+Accelerator的厂商高通最新的8195系列(2018年),还有Intel的Xeon+FPGA Accelerator的自动驾驶解决方案。当然Tesla Model3的Auto-pilot 2.5采用的是Nvidia DRIVE PX2的自动驾驶平台的定制版本,即Parker CPU+Pascal GPU,它属于ARM+Accelerator的范畴。Tesla的Auto-pilot 2.5从功能上属于L2到L3的过度产品,是增强版的ADAS高级自动驾驶辅助系统,由于在任何情况下,驾驶员的双手不能离开方向盘,所以不能算是自动驾驶的范围。表1是全球最新的自动驾驶加速器方案。
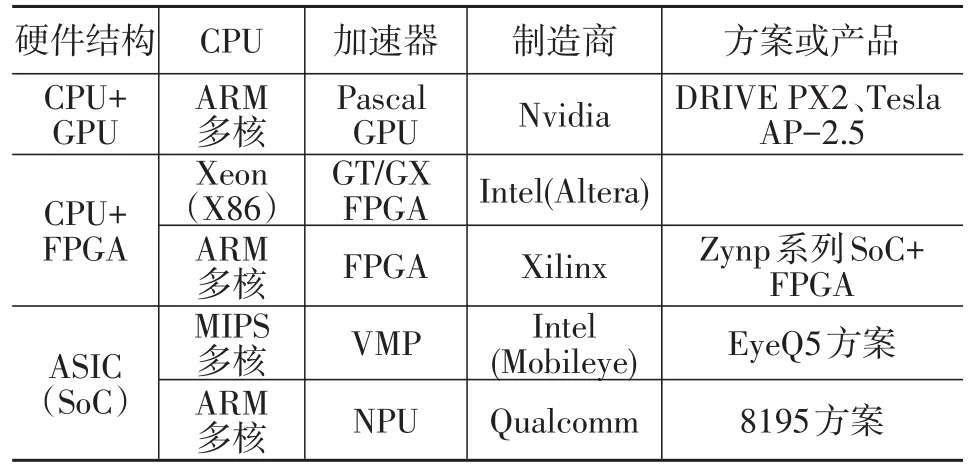
表1 全球最新的自动驾驶加速器方案
从表1可以看出,从加速器的角度,可以分为基于CPU+GPU专用图形加速器的自动驾驶平台、CPU+FPGA现场可编程逻辑门阵列的加速器的自动驾驶平台和基于ASIC化的NPU神经网络处理器的多核处理器的SoC自动驾驶硬件平台。
对应不同的硬件平台,其处理探测(DET)、跟踪(TRA)和定位(LOC)的算法库也不同,如表2所示。

表2 加速器平台算法库[2]
针对DET和TRA算法,虽然说FPGA和ASIC的逻辑都采用硬件化的深度神经网络单元,但是其电路的实现方法是不同的。定制化的ASIC采用的多个DNNs固化的电路,而FPGA是采用可重复配置的内部逻辑DNN IP核。而GPU作为通用的图形处理器,其应用首先要基于有由GPU厂商提供的算法库或基于原厂库的第三方程序。从开发者的角度来说,GPU自动驾驶平台的主要工作重心是应用的开发与机器学习的样本库的积累。如果原厂,如Nvidia,能提供大量成熟的样本库,甚至直接导入大量的成熟的样本库,其平台的成熟度和开发周期短的优势就非常明显。这就是在特斯拉Model系列车型中已经大量采用GPU的Auto-pilot 2.5的原因。虽然距离L3的自动驾驶还有半代,但是已经是大量出货的落地产品,而且在客户的实际路上行驶过程中,其样本库会进一步扩充和完善。但是GPU有一个致命的弱点,就是为了实现L3级的应用中其功耗极大,高至200~300 W以上。如果加之为给GPU降温的风扇或水冷设备的功耗,单就油耗或电动车的行驶里程也是一个巨大的挑战。同时,GPU平台的整车成本也非常高,例如,Tesla从Auto-pilot 2升级到Auto-pilot 2.5,为了满足GPU的散热要求,将低成本的风冷器升级成水冷系统。虽然说自动驾驶模块仅是其整车水冷系统的一个节点。但是为了满足这个要求就,就要升级这车的冷却系统,其成本压力可谓不小。
FPGA和ASIC从内部电路角度,都是实现某种专用功能的组合或者时序逻辑的硬件电路。ASIC是为了实现这个逻辑而定制化的半导体电路,它是专用且高效的设计。而FPGA是由数量巨大的LUT(查表)小逻辑单和DSP构成的阵列网络。从逻辑实现的效率来讲,ASIC更高,从功耗上说,FPGA内部逻辑是类似RAM动态存储器结构,需要保持上电,加上逻辑效率相对低,占用的电路资源和消耗的电流更多。这样在功耗和散热方面FPGA比ASIC要求更多。但是即使这样,FPGA和ASIC的热功耗也远低于GPU。甚至Mobileye的eyeQ5号称可以在10 W的功耗下实现L4级自动驾驶。但是Mobileye现在只做到L2~L3的商用化应用[9]。
当前在自动驾驶业内,没有一种硬件架构和深度学习算法被认为是最优的,还有很多没有解决的问题。这样FPGA的可重复配置,逻辑设计非常灵活的优势就有了一定的窗口期。而且多传感器融合,需要一种能提供灵活接口的计算机结构,这些都是ASIC在短期内阻碍其大规模的投入量产和芯片迭代的原因。所以,从商业化角度,自动驾驶平台的ASIC化是目标,而GPU和FPGA因为各种局限,在不久的将来会最终会让渡于ASIC。同时FPGA有助在现阶段测试和验证各种算法和结构,为最终自动驾驶平台的ASIC化提供非常有力的积累,在L3以上的自动驾驶应用上有一定的空间和需要。
4 不同厂商技术方案应用实例
当前全球有4套3种不同方案的L2~L3自动驾驶计算机平台技术应用,具体说明各自的硬件架构特点和外围传感器配置。
(1)Tesla的Auto-pilot 2.5 GPU加速器方案;
(2)Xilinx的ZNYQ ultrascale+FPGA加速器方案;
(3)Qualcomm 的 8195和 Mobileye EyeQ4 ASIC SoC平台。
4.1 GPU加速器及典型方案
Tesla采用了Auto-pilot 2.5 GPU加速器方案,Auto-pilot 2.5车载计算机是Model系列车型中的ADAS/AD自动驾驶的核心部件。它是继2016年10月推出Auto-pilot 2.0车载超级计算机后,应用深度学习和高级辅助驾驶功能的最新升级版本。因为特斯拉是最早将L2~L3的高级辅助驾驶作为标准配置的整车厂,作为商用化产品,其采用了当时能力和成熟度最高的Nvidia英伟达CPU+GPU方案。Auto-pilot 2.5对外围传感器特别是摄像头的数量进行了缩减,同时双GPU方案的功耗和散热对于纯电汽车也是增加了负荷。同时,Auto-pilot 2.5也分两个版本,针对Model X和Model S采用的风冷散热系统,而Model 3采用水冷方式,这极大的提高了Auto-pilot的可靠性,但是整车成本压力相应增加。
Auto-pilot有8个环视摄像头和一个车内监视摄像头,详见表3和图3(根据逆向工程整理)。

表3 Auto-pilot 2.5自动驾驶系统配置
这8个摄像头构成了360度无死角的环视图像采集。车内的摄像头主要是监视驾驶员防止疲劳驾驶等突发情况。
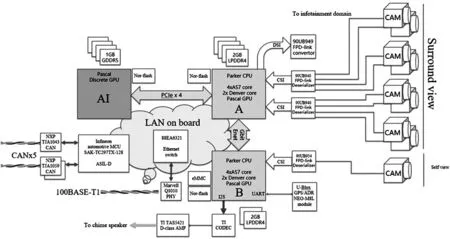
图3 Auto pilot 2.5自动驾驶系统架构
首先,Parker CPU A单元和GPU构成了深度学习基本模组。行驶过程中,8个摄像头图像流,通过2个HUB多端口转发器输入给了Parker A。作为媒体处理器,Parker A可以将CSI接口标准的图像数据进行转码生成位图流,通过PCIe高速接口传递给AI芯片(GPU),进行DET识别、TRA跟踪、LOC定位和FRUZE融合等算法计算。而各种专业应用及导航路径规划等程序则在Parker B的CPU上运行。Parker A和Parker B两个CPU的分工可以从其外围模组的功能得到佐证。比如GPS模块接到了Parker B上,说明其需要执行较高层级的任务应用,如路径规划导航。而如警报和提示音的音频编解码器也连接在Parker B上,说明人机交互应用会在这颗处理器上执行。对于Parker A它更多是为GPU提供数据预处理功能,GPU专注于深度学习算法,作为加速器它不直接提供类似摄像头之类的多媒体接口。所以从架构上看Parker A+GPU更多执行Accelerator(加速器)之功能,而Parker B则执行上位机的任务。
于此同时车辆行驶的控制命令需要透过车载微控制器通过CAN总线发给执行控制器,如动力电机、转向控制器和制动控制器等。
4.2 FPGA加速器及典型方案
Xilinx采用了ZNYQ ultrascale+FPGA加速器方案。
虽然GPU作为深度学习加速器在ADAS和L3级自动驾驶系统市场上已经暂露头角,也被一些大的厂商采用,但是其200~300 W的功耗和苛刻的散热要求,一直被自动驾驶业界所诟病。随着L3以上的自动驾驶平台需求与日俱增,GPU的算力和功耗之间的矛盾越来越突出。预计特斯拉在其下一代自动驾驶平台将会采用其专为自己设计的专用车载计算机处理器。但是其实一直以来,另一位有力的竞争者从未停止对自动驾驶领域的窥探。它就是有在应用上极为灵活的可编程逻辑器件中的FPGA现场可编程逻辑门阵列。FPGA设计的灵活性在自动驾驶和深度学习领域有一定的优势。
第一:当前的深度学习都是基于DNN深度神经网络或CNN卷积神经网络,它对矩阵化的并行计算有非常高的要求,FPGA硬件化的并行结构优势明显。
第二:当前深度学习的算法的优化和迭代非常频繁,如果不是基于软件的平台,就需要硬件有可重构或灵活配置的能力,FPGA恰好以此为基本特性。
第三:由于所有的逻辑是并行处理的,不同于CPU需要提高其时钟频率提高运算能力,所以其功耗较GPU大大降低,在几十瓦的水平。
第四:其丰富IO和内部IP资源,可以灵活的集成各种传感器物理接口和大带宽总线。实现分布式处理器的互联。
图4就是基于Xilinx最新的FPGA Zynq-ultrascale+的自动驾驶计算机方案。
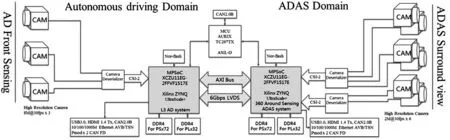
图4 最新的FPGA Zynq-ultrascale+的自动驾驶系统构架[10]
如图4所示,虽然3个前向摄像头(远、中、近)布置给AD自动驾驶计算提供输入,而360环视6个摄像头布置用于ADAS计算输入。但是融合(Fusion)算法是在一个FPGA中实现的,ADAS环视摄像头可以将物体动态特征通过AXI总线转递给AD域FPGA,并进行3D地图的建立。如果FPGA的内部资源允许,这6个摄像头也可配置在FPGA上。而SoC+PFGA架构中的SoC已经集成在FPGA芯片里。这也是FPGA行业的一个趋势,为了缩短开发产品周期,将嵌入式系统和FPGA的可编程逻辑网格结合。FPGA的逻辑作为整个系统的一个组件,在操作系统的统筹下执行特定的工作。对于L3以上的自动驾驶方案,除了摄像头之类的图像传感器,77/79G毫米波雷达、超声波雷达、甚至激光雷达都需要丰富的接口,FPGA厂商一般会直接提供如CAN、LIN或以太网等接口的硬核IP或软核IP。从散热角度,风冷系统完全可以保证其工作安全的结温要求。
但是FPGA某些性能在自动驾驶领域广泛的应用中仍有不足,需要持续改进。从行业来说FPGA的开发专业性更高,需要专业使用Verlog HDL或VHDL硬件描述语言进行系统集成,即使很多基于FPGA的深度学习算法都是由第三方提供的。还有不同于GPU的深度学习算法库都是由厂商提供,基于GPU的自动驾驶功能实现主要集中在应用层软件开发,FPGA的底层代码开发量非常大,需要很长期的积累,门槛较高。
4.3 ASIC加速器及典型方案
Qualcomm开发了8195和Mobileye开发的EyeQ4 ASIC SoC平台。CPU+GPU、CPU+FPGA和嵌入式的ASIC自动驾驶平台是一种异构计算机,就是将某一部分的特定任务放在专用的子处理器上,加速器其执行运算,这样来最大限度的提高计算机的整体性能和效率。Qualcomm的8195和Mobileye EyeQ4都是在内嵌深度学习处理器的嵌入式SoC平台基础上开发的,从内部结构来说并没有太大的差异。不同于FPGA和GPU+CPU这种异构计算机,嵌入式的有非常高效的内部总线,将CPU、内存和深度学习处理器链接起来。而CPU和FPGA通过复杂的外部总线与CPU进行对传,而且还不能与CPU共享内存,系统的复杂性和成本都更高。
同时GPU和FPGA都是通用器件,并不是专为深度学习来设计的,其运行效率比ASIC低很多,为了实现相同的任务,以上两种加速器的系统时钟频率也远高于AISC的专用处理器,自然功耗和发热也就高一个数量级。从官方获取的信息EyeQ4的满载功率在5 W以内,支持L3级的自动驾驶。
图5和图6展示的分别是Qualcomm的8195车载计算机和Intel的Mobileye EyeQ4自动驾驶计算机处理器的系统构架。

图5 Qualcomm 8195车载计算机系统构架[11]
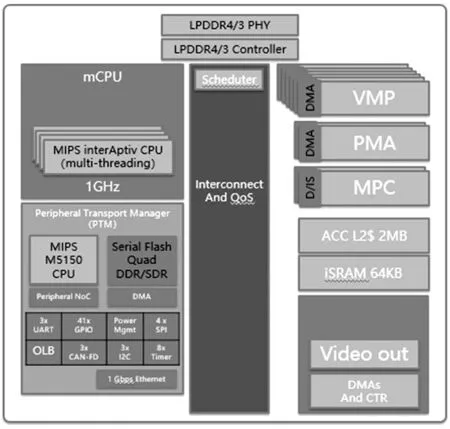
图6 Intel的Mobileye EyeQ4自动驾驶计算机系统构架[12]
从图5可以看出8195采用的是8核的ARMv8 CPU和一个NPU神经网络处理器,而EyeQ4采用的是4核MIPS CPU和6核的相量微码处理器VMP负责深度学习。
从图5~6我们还可以看出2种计算机都提供了丰富的外设接口,支持8路以上的环视摄像头Camera接口,毫米波雷达CAN接口和LIDAR激光雷达100 M以太网接口等。但是考虑到探测、跟踪和定位都需要占用深度学习处理器,CPU的对NPU或VMP的管理有特殊的要求,也限制了当前SoC自动驾驶计算机的能力。
4.4 最新各方案执行自动驾驶的功效对比
表4是多种加速器架构的自动驾驶计算机性能,其中有最为抢眼的是Tesla近日发布的FSD自动驾驶平台,其最高到144 TOPs性能可支持L4+自动驾驶功能。相比GPU加速器方案的Xavier的250 W功耗,FSD在100 W以内的功耗优势明显。从单位功率算力角度,ASIC方案普遍较GPU和FPGA有较大优势。

表4 加速器架构的自动驾驶计算机性能
5 结束语与展望
随着自动驾驶汽车技术的繁荣发展,对自动驾驶计算机会提出了更高、更苛刻的要求,包括更高计算速度的优异性能、更低的能耗、更苛刻的应用环境和更低的成本。同时,随着计算机的发展,自动驾驶计算机的竞争将大力推进自动驾驶汽车的发展,按照全球主机厂的日程实现L4~L5级自动驾驶。因为GPU开发更快,FPGA结构更灵活,ASIC成本功耗效益最高。但是随着深度学习硬件的持续发展,在可预见的未来ASIC将占领L4~L5级自动驾驶计算机市场的较大份额,随着全球自动驾驶技术竞争的加剧,汽车强国将在这一领域处于领先地位,这将大力促进相关半导体厂商的研发和投产速度。从商用化的角度,自动驾驶计算机会做的更便宜和功耗更低,从而全面促进自动驾驶汽车和智慧移动出行社会的实现。
这里还要考虑一个非常重要的背景,就是车联网和5G的全面覆盖,因为新的商业模式,特别是共享汽车和多种个性化的云服务才是自动驾驶和智慧移动出行生态的最大亮点和推动力量。在此之前的几年里,GPU、FPGA这样的硬件加速器方案还会继续存在,其技术路线还会在不同的整车和科技公司向前延展。但是殊途同归,最终的ASIC化的自动驾驶方案一定会融合了前辈的优势和技术积累,并在商用化之路上走到最后。
未来,人类驾驶员这个角色将会成为历史,就像伴随1886年第一辆汽车的诞生、第一位驾驶员的出现一样,具有人工智能的自主驾驶计算机会在不久的未来逐步取代人类驾驶员,机器驾驶员的时代一定会到来,人们可以期待未来人类社会的移动出行会出现翻天覆地的变化。
