搜索引擎结果展示效果自动评价方法
2019-07-20张辉马少平
张辉,马少平
(清华大学 计算机科学与技术系,智能技术与系统国家重点实验室,北京100084)
搜索引擎作为访问网络信息资源最重要的工具,在人们的工作、学习和生活中发挥着至关重要的作用。搜索引擎根据用户提交的查询内容,返回搜索引擎结果页面(search engine results page,SERP),它通常包含1个典型的搜索结果列表,每条搜索结果包括标题、摘要和网址等文本信息,随着搜索引擎技术的发展,也可能包含图片、视频、投票等更多的信息[1]。SERP可以看作原始文档的“文摘”(abstract),“摘要”(summary)或者“片段”(snippet),用户对于原始文档一无所知,只能根据看到的搜索结果进行阅读、认知和判断。因此,搜索结果的质量直接影响用户的搜索交互过程[2-3]。为吸引用户有限的注意力,引导用户关注更重要的内容,搜索引擎往往采用突显技术,比如增加插图、图标、文本标记或可视化等[4-5]。以往的研究大都集中在评价搜索结果文本内容质量,还没有学者评价搜索结果文本呈现方式效果。本文研究重点为在确定的查询和搜索结果的情况下,宏观和微观自动化评价不同展示策略(方式)的优劣,力图关注搜索结果评估的多个方面,如内容、展现形式、丰富搜索结果质量评估体系的完备性;根据用户调查和访谈,提出视觉力、信息力和有效力这3个维度的结果展现效果评价体系,且这3个维度并不局限于特定的查询和领域。实验显示该方法,在传统文本搜索结果的展示效果评价方面,与人工标注结果和用户A/B实验结果具有较高一致性,因此该方法具有较强的可操作性;另外,使用定序回归分析模型(ordinal logistic regression model,OLRM)分析和研究这3个维度的重要性。
1 相关研究
本文搜索结果示例如图1所示,调查用户阅读这条搜索结果时所记住的内容,询问他们认为这条搜索结果是否与查询“认知能力”相关,并且询问是否会点击这条结果。调查显示:当以图1(a)显示搜索结果时,95%用户认为这条结果与查询相关并且会点击它,记住最多的3 个词语为“认知能力”“筛选”和“信息”,而当以图1(b)显示搜索结果时,只有40%用户认为这条结果与查询相关并点击它,记住最多的3个词语是“荒岛”“金币”和“参赛者”。可以看出,即使相同的文本内容,采用不同的文本突显技术,所展示的效果以及带给用户的感受是不同的,并影响用户判断相关性和获取信息。
对搜索结果摘要质量评估的研究由来已久,将生成搜索结果摘要的过程看成原始文档生成自动文摘的过程,并将文本自动文摘评价方法应用到该领域。主要包括2种方法:一是直接与人工形成的标准文摘进行对比,同时评价该文摘内容的完整性和语句连贯性,现在应用广泛的为LIN等[6-7]提出的ROUGE 方法;二是面向任务的评价,把搜索结果摘要放在1个具体的搜索任务中,比较不同搜索结果摘要的具体表现,测试其对用户搜索行为或者满意度的影响[8-9]。这2种评价各有优缺点,在评价搜索结果文本内容的质量方面,可以综合运用。
对于SERP 展示的研究主要集中在页面要素布局、大小以及排列方式。对于用户搜索行为的影响,一般通过设置受控的用户实验或者真实的用户搜索日志数据进行研究分析[10-12]。这些研究集中在宏观的整体SERP显示策略,而没有重点研究单条搜索结果的展示策略。以往的研究就是针对不同的突显策略下,单条搜索结果的展示形式对用户搜索过程的影响。对于同样的文本内容,选择不同的突显策略,将会对用户搜索过程产生极大的影响,SERP或者Snippet中突显比例过高或者数量过多,都会降低用户满意度和搜索效率[13]。
搜索结果摘要的评价不仅包括内容的评价[14-16],而且包括展示形式的评价,这样才能真实反映1个结果,与用户的实际感受和认知相一致。该问题目前面临2个方面的挑战:一是科学和明确地定义“好的结果”非常困难,本文的研究采用组合评价的思想,假设内容评价和展示方式评价之间相互独立,将搜索结果的评价划分为内容的评价和基于相同内容的展示方式评价;二是搜索结果摘要的评价是与具体查询任务相关,必须是在查询和原始文档都确定的情况下,才能进行评价,当没有用户查询时,其评价便失去意义。本文将搜索结果的评价分为2步,在内容评价的基础上,基于相同内容开展搜索结果展示效果的评价,虽然与最终的整体评价还有一定的距离,但是它是目前可行的方案。
2 评价体系及自动评价算法
用户受控实验或者人工标注都要耗费大量的人力和物力,人们期待能够有自动的评价算法,计算并比较2种不同搜索结果。本文总结前人工作中与搜索结果摘要展现效果相关的因素,然后进行用户众包调查和标注,最后,根据用户调查和标注的结果与经常使用搜索引擎的实际用户和专业的网页设计者进行访谈,确定影响搜索结果摘要呈现方式的15 个因素,如表1所示。

图1 文本搜索结果示例Fig.1 Example of a snippet
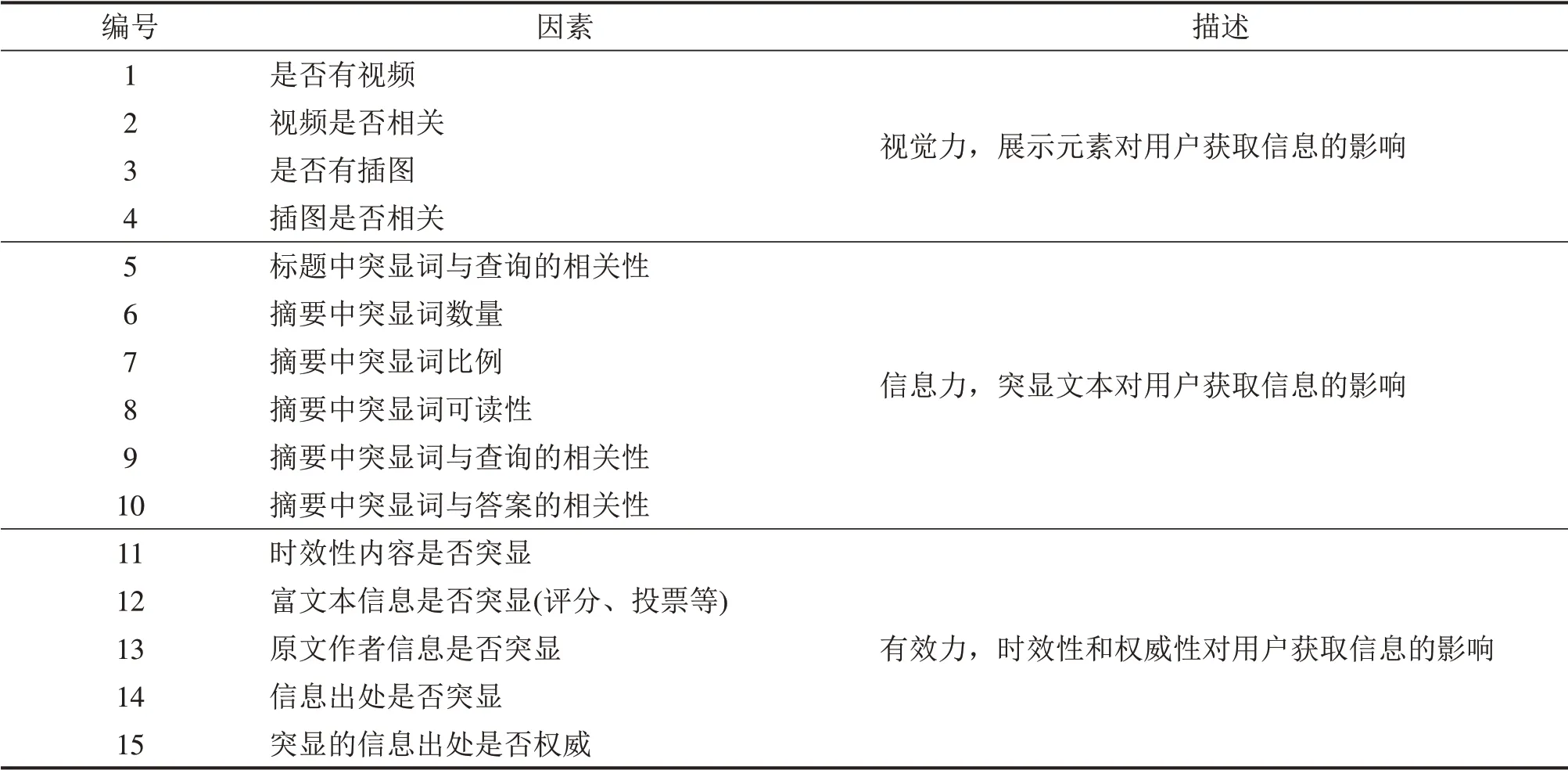
表1 搜索结果展示效果评价体系Table 1 Snippet presentation evaluation system
以往的研究成果和本文开展的用户标注结果显示:用户认为搜索结果中含有相关的视频或插图、合适的文本突显比例、丰富的文本突显信息以及可信的数据来源能够增加用户的阅读和认知体验,提高信息的检索效率。
对于搜索结果,当查询和搜索结果内容都确定时,2 条结果的展示差异主要源于突显策略的差异。目前商用搜索引擎在搜索结果文本展示方面,通常采用查询词标红的突显策略,可以将这1个策略作为参照基准。评估展现形式的优劣,一种方法是对比参照基准,进行人工标注或者用户受控实验,定性地评估;另一种方法是根据表1提出的影响因素,计算其展示效果得分,自动化定量地评估。
对于评价体系中视觉力中的每个因素,如果结论为“是”,计1分,否则计0分。本文的研究重点是纯文本搜索结果的展示效果,统一采用没有视频和插图的搜索结果,视觉力得分都为0,可以忽略不计。对于信息力,若查询或答案包含多个词语,则计算平均相关性。相关性计算采用Word2Vec算法(https://code.google.com/p/word2vec/)基于SogouT 数据集(http://www.sogou.com/labs/dl/t-e.html)训练得到词向量,相关性为词向量的余弦相似度得分。如果不知道答案或答案为空,则此项为0分。合适的标红比例和数量能够吸引用户注意力但不会让用户产生困扰,它应该是一个区间,在区间内取1分,否则取0分。根据用户标注的结果,本文采用的标红数量区间为[2,7],标红比例区间为[10%,20%]。突显内容的可读性可以采用中文词语的难度等级、单字词的数量以及非汉字字符的数量计算,并且进行(0,1)归一化处理,其中难度等级依据《汉语水平词汇与汉字等级大纲》,对于未收录词语和汉字,按最高难度等级计算。对于有效力,如果结论为“是”,计1分,否则计0分。其中权威性为该网站的流量排名,并进行(0,1)归一化处理。最后,对3个维度得分进行加权平均,本文选用的加权系数都为1/3,最终得到单条搜索结果的展示效果得分。对于图1中的2种展示,计算其展示效果得分分别为0.23和0.07,图1(a)所示的突显内容与查询更相关并且可读性更强。
3 实验结果和分析
3.1 实验数据
中文搜索用户提交查询多以关键词为主,而且93.15%的查询少于3 个[17]。选取NTCIR Imine[18]中的12 对共24 个中文查询,包括2 对(4 个)导航类查询(navigational tasks,NA),2 对(4 个)事 务 类 查 询(transactional tasks,TR)和8 对(16 个)信 息 类 查 询(informational tasks,IN),每对任务的查询需求类似,难度相当。搜索结果来自于Google 搜索引擎,去除SERP 中含有图片、视频等的垂直结果,仅选取包含纯文本的前10 条结果,最终得到24 个查询和对应的240个搜索结果。
将Google 搜索引擎展示的搜索结果作为对比基准,记为P1。为与P1进行对比,人工标注另一种搜索结果的展示方式,记为P2。本文提供给用户查询任务说明、查询以及无任何文本突显效果的搜索结果,让用户根据任务需求和查询的理解,标注重要的、对于完成搜索任务有价值的、该被突显的词/短语。每条搜索结果邀请10名用户标注,若某个词语被4名以上用户标注为突显词,这个词语就会被突出显示。这么设定则是为了与Google 突显策略保持相近的标红比例。
3.2 影响因素重要性分析
为分析不同维度对搜索结果呈现效果的影响程度,实验要求标注用户对P2策略下240个搜索结果的呈现效果进行总体打分以及对信息力和有效力特征分别打分(视觉力维度得分全部为0),分数为0~3 共4级(其中3 表示呈现效果非常好,0 表示呈现效果极差)。共邀请4名标注者,标注者之间的平均kappa系数为0.507,这是一个中等一致的结果[19]。
使用式(1)所示的OLRM模型[20]对评价体系的2个维度和总得分的关系进行分析。
logit(Overall≤j)=α+β1X1+β2X2(1)
式中:Overall为总体呈现效果得分;j为呈现效果的所有可能得分常数,取值为[1,3];X1和X2分别为信息力和有效力维度特征;α为截距;β为每个特征的系数,该系数越大,则表示该特征对总得分的影响越大。表2所示为对4 名标注者的标注结果进行模型拟合的结果,其中β为不同维度特征拟合出来的系数,p为显著性水平,p越小,说明对应维度特征的贡献越显著。
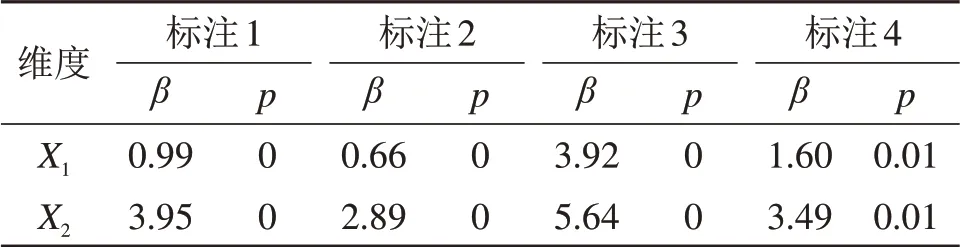
表2 标注结果回归分析Table 2 Regression analysis of annotated results
对于拟合出的模型,人们主要关心的是不同维度特征对应β相对大小。值得注意的是,不同的标注者拟合的β之间不能直接进行比较。从表2可以看出:特征对应的p均小于0.01,说明这2 个维度特征对搜索结果最终呈现效果均有显著影响;其对应的β均为正值,说明这些特征与呈现效果是正相关的。信息力特征的β较高,说明结果文本标题和摘要内容的突显效果相比于信息来源和作者等附加信息是更加重要的特征。
为了进一步分析15 个特征的重要性,利用一种简单打分的方法,采用式(2)计算得分G来衡量单个特征k的区分能力。
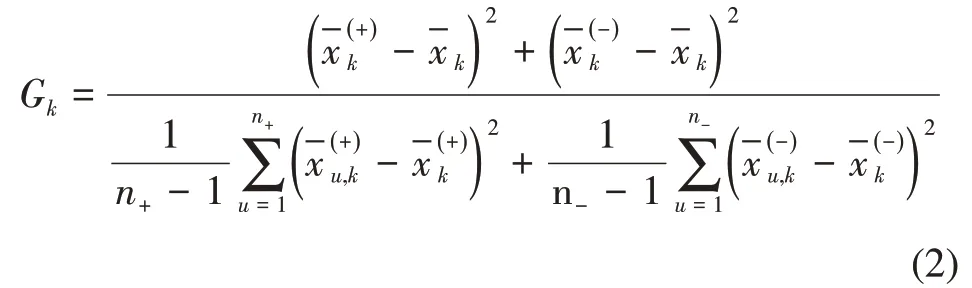
计算所有特征的G如表3所示,特征编号与表1一致。从表3可以发现:共计有8个特征具有一定的区分能力,打分最高的3 个特征属于信息力的维度,分别为标题突显词与查询的相关性、摘要中突显词的数量以及摘要中突显词与查询的相关性。
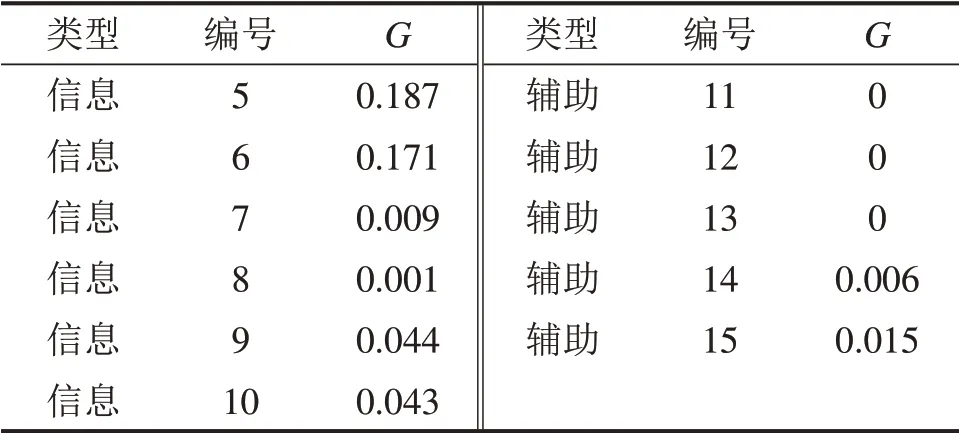
表3 特征参数的影响力GTable 3 InfluenceG score of characteristic parameters
3.3 与人工评测的一致性对比
将24 个查询和240 个搜索结果形成10 份调查问卷,每份问卷对应24个问题,如图2所示。每个问题对应一个查询和同一个搜索结果的2 种不同展示形式,邀请众多用户进行人工评测,选择对哪种显示方式更加满意。对方式一和方式二的选项进行了随机设置。
对每个问卷,收集100 个使用搜索引擎超过3年且学历为本科以上的用户数据,这样对应每一个查询(搜索结果),都有100个人工评测的满意度。
对于240个搜索结果,根据调查问卷,若更多的用户满意P1,则P1记1分,而P2记0分;否则P1记0分,P2记1分。若两者人数相同,则都记1分。对于对于240个搜索结果,利用自动评价算法,得到P1和P2展示效果得分,若P1>P2,则P1记1分,P2记0分;否则P1记0分,P2记1分。若两者人数相同,则都记1分。计算自动算法得到的结果与人工评测得到结果的相关性系数,P1策略下Spearman 系数为0.853,P2策略下Spearman 系数为0.859,说明利用本文提出的自动算法以达到与人工评测相近的水平。
每个查询有SERP的10 个搜索结果,用户对于SERP的满意度采用10个结果的算数平均满意度,统计结果如图3所示。
平均47%用户满意P2的展示方式,满意P1的用户仅有24%,而另外29%用户认为两者区别不大。对应24个查询任务SERP,用户更满意其中18个使用P2展示策略的SERP,4 个使用P1展示策略的SERP,而另外2 个SERP 使用2 种展示策略给用户的感觉差别不大。从图3可以看出:对于搜索引擎而言,P2比P1更好。但是对于某一任务来说,哪种策略更好是不确定的,这也说明展示效果与查询任务相关。

图2 满意度人工评测调查问卷示例Fig.2 An example of satisfaction questionnaire
3.4 与用户A/B测试实验一致性对比
本文开发的实验用搜索引擎可以完成正常的搜索功能,同时记录用户的鼠标交互数据。本文共邀请12 个参与者完成2 种展示的对照实验,每人完成24个查询,其中12个查询采用P1展示而另外12个采用P2展示。采用希腊拉丁方法和随机序列的方法,保证每个任务以相同的概率展现给用户,对于每种展示下的每个任务,可以收集到6个用户的搜索数据,统计结果如表4所示,其中,∇代表下降且统计显著性指标p<0.1。相比于P1的展示策略,P2展示策略下,用户阅读摘要的时间更短,并且点击次数、长度和最大排名都明显减少,说明用户花费更少的时间就能获得满意的结果,极大地提高搜索效益。因此,P2是比P1更好的突显策略。这与人工评测和自动评测得到的结论相一致。
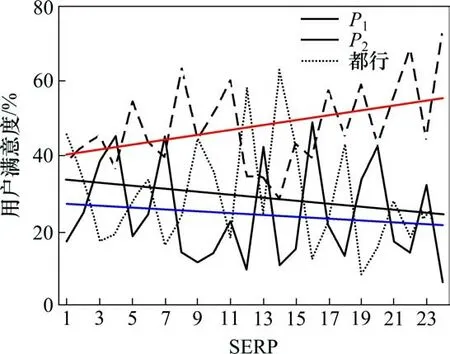
图3 SERP满意度统计结果Fig.3 SERP satisfaction statistics results

表4 用户A/B测试实验结果Table 4 User A/B test experimental results
4 结论与展望
1)在信息需求飞速增长的时代,建立适合搜索引擎实际应用环境的搜索结果评估体系与自动评估算法成为信息检索领域的重要研究课题。本文提出一个综合考虑视觉力、信息力和有效力这3个维度共15个指标的搜索结果展示效果评价体系,该体系具有较强的可操作性,与人工标注结果和用户A/B实验结果取得了相一致的结论;使用逻辑回归模型拟合结果显示,信息力和有效力都对搜索结果的展示效果有显著影响,且信息力的影响更大。
2)搜索结果的展示效果的评估是一个复杂的任务,它与实际查询任务类型、领域和信息需求都紧密相关,下一步将结合查询任务的领域和类型,完善评价体系;提取合适的客观特征,实现搜索引擎结果展示效果的自动评价。
