蒙特卡罗临界计算能量偏倚的最佳源偏倚方法
2019-07-15潘清泉饶俊杰
潘清泉,饶俊杰,王 侃
(清华大学 工程物理系,北京 100084)
反应堆临界问题[1]以求解keff为特征,即求解中子输运方程的特征值。反应堆理论中,keff被看作相邻计算代的子代中子数和父代中子数的比值,其中不同计算代以裂变反应区分。蒙特卡罗(MC)临界计算采用裂变源迭代法[2],用当前代产生的裂变源作为下一代的初始源,即下一代各裂变源区抽样产生的源粒子数与当前代在该裂变源区产生的裂变中子数正相关,可表示为ni=Npi,N为每个计算代的总中子数,ni为某计算代第i号裂变源区所需抽样产生的源中子数,pi为第i号裂变源区产生源中子的概率。如果同时考虑源中子的空间分布和能量分布,则ni,E=Npi,E,ni,E为某计算代第i号裂变源区抽样产生的能量为E的源中子数,pi,E为第i号裂变源区产生能量为E的源中子的概率。可见,传统的临界计算在抽样每个计算代的源中子时,在空间分布和能量分布上均采用了比例抽样法。该抽样法能反映真实的中子输运物理过程,但计算所得的总体方差在数学上并未达到最优化。同时,物理上的连贯性必定带来数学上的相关性,故MC计算代之间存在较大的相关性,使得计数器结果和keff的估计值存在方差低估计现象[3]。
为实现源中子在空间和能量上的最优化分布,消除方差低估计现象,并减少计算方差,计算中主要存在两个问题:1) 在MC临界计算的每一计算代中,在某一裂变源区某一能量区间中应该抽样产生多少源中子才能使得总体方差最小;2) 在MC临界计算的每一计算代中,源中子在空间和能量上怎样分布才能实现数学最优化。
为此,本文研究MC临界计算的能量偏倚的最佳源偏倚方法。该方法基于传统的最佳源偏倚方法,以香农熵诊断[4]和组统计[5]方法为基础,在消除计算代之间相关性的同时,通过最佳分层抽样法[6]实现堆用MC程序RMC临界计算时,每个计算代的源中子在空间和能量上的最佳分布,从而达到全局减方差[7]的计算效果。
1 理论模型
在数理统计学[8]的随机抽样法中,分层抽样法得到了广泛关注。当总体样本由差异明显的几部分组成时,为使样本更客观地反映总体情况,通常将总体按照不同的特点分成层次分明的几部分,然后按照各部分在总体中所占的比例进行抽样,这种抽样法称为分层抽样法。分层抽样法是通过改变概率分布,把整层抽样变为分层抽样,把整层概率分布变为分层概率分布,从而达到降低方差的计算效果。
传统的MC方法进行临界计算时采用了裂变源迭代法,用当前代产生的裂变中子源作为下一代的初始源,即在空间和能量上进行了分层抽样,并采用了比例分层抽样法。通过拉格朗日乘子法[9]或Schwarz不等式[9]可推导出最佳分层抽样法,使计数器的总体方差最小。
但是,在RMC程序中使用最佳分层抽样法时需提前知道待求的方差信息,导致方法失效,所以最佳分层抽样法就像是零方差理论,只能无限接近,并不能真正实现[10]。在保证计算代之间不相关的前提下,用上一代的方差信息近似当前代的方差信息就可解决这一问题。为实现计算代之间不相关,需在RMC程序临界计算过程中消除方差低估计现象。本文从通用性和可靠性的角度出发,选择了组统计方法,并根据香农熵诊断确定出了简单有效的组统计长度。
1.1 最佳分层抽样法
系统特征值keff及其标准偏差在MC临界计算的所有活跃代中进行统计,并对所有活跃代的结果求平均值。keff有3种估计方法,分别为碰撞估计法、吸收估计法和径迹长度估计法,3种估计值通过统计相关性进行组合得到无偏的keff及其标准偏差。
设f(x)为区域D上的概率密度函数,考虑下列数学期望的计算:
(1)
其中:R为响应函数乘以概率密度函数的积分值;g(x)为响应函数;x为某一样本值;E[g]为数学期望。
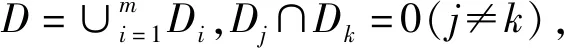
(2)
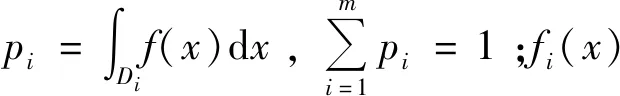
(3)

(4)
这样把区域D上的积分转化为m个子区域的积分之和。
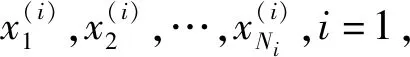
(5)
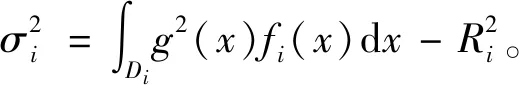
(6)

(7)
在每一计算代中,由于Ni的计算表达式中涉及待求量σi,因此式(7)很难被直接应用。但使用RMC程序进行临界计算时,通过非活跃代的计算完成源收敛后,当前代的σi可由上一代的σi近似,故在临界计算过程中,可采用这种方法实现最佳分层抽样。即每个计算代在进行裂变源抽样时可采用最佳源偏倚因子对源中子进行偏倚,由比例抽样:
ni=piN
(8)
变成最佳分层抽样:
(9)
相应的最佳源偏倚因子εi为:
(10)
为同时对源中子的空间位置和能量进行基于最佳分层抽样法的源偏倚,相应的能量偏倚的最佳源偏倚因子变为:
(11)
其中:εi,E′为某计算代第i号裂变源区能量为E′的最佳源偏倚因子;σi,E′为该计算代第i号裂变源区能量为E′的计算方差;pj,e为该计算代第i号裂变源区产生能量为e的源中子的真实物理概率。
从式(11)可知,统计方差大的区域会被多抽样,统计方差小的区域会被少抽样。因此基于最佳分层抽样法的源偏倚方法不仅可实现全局减方差的计算效果,还能在一定程度上展平全堆方差的分布。但上述关于分层抽样法推导的前提是每个计算代的中子数足够大,同时计算代之间相互独立,故为了实现能量偏倚的最佳源偏倚方法,需采用组统计方法来消除方差低估计的现象。
1.2 组统计方法
(12)
(13)
(14)

(15)
(16)
其中,CR[l]称为l代滞后协方差:
CR[l]=E[(xi-E[xi])(xi+l-E[xi+l])]=
cov[xi,xi+l]
(17)
其中,cov[xi,xi+l]为第xi和第xi+l代之间的协方差。
可见,方差低估计仅取决于活跃代间的间距l,与活跃代位置i无关。在MC源迭代过程中,每代裂变源分布总是来自于上一代的裂变源分布,即裂变源迭代之间存在正相关性,因此CR[l]的符号为正,于是得到:
(18)
一般而言,方差低估计问题对keff影响较小,但对通量分布和功率分布等局部计数器影响较大,这是因为裂变源分布的相关性对计数器的影响更为直接。系统占优比越高,则源迭代之间的相关性越强,从而导致方差低估计现象越显著。
Gelbard等[5]最早提出使用组统计方法来减少MC方差低估计,MC21程序采用了该方法。组统计方法的基本思路是将多个活跃代归并为1组,然后以组为单位统计keff或计数器的均值和方差,其具体实现过程如下。
首先假设MC计算共有N个活跃代,按照每组M代进行归并,则共得到N′=N/M组计数。每组计数可表示为:
(19)
其中:xi为第i个活跃代计数;yj为第j组计数。
然后,以组为单位统计物理量的平均值和方差:
(20)
(21)
显然,裂变源分布在组之间的相关性弱于其在代之间的相关性,因此组统计方法可减轻裂变源相关性所引起的方差低估计问题。当每组粒子代数M足够大时,方差低估计偏差可忽略不计。
在组统计方法中,关键是确定每组的粒子代数M,即组长度。一般而言,源迭代过程中裂变源分布的相关性越强,则意味着源分布需经历更多的代数才能消除之前的源分布的影响,与之相对应地,所需的组长度M越大。通过计算占优比,可定性判断源分布相关性的强弱,对组长度M的选择有一定指导意义。在RMC程序中实现的是另一种很简便的方法:
M≈Ninact
(22)
其中,Ninact为源收敛所需的非活跃代数。
MC源收敛速度和方差低估计程度均是由源迭代裂变源分布的相关性决定的。裂变源的相关性越强,则源收敛速度越缓慢,同时方差低估计现象也越明显。MC非活跃代的源收敛过程意味着初始源分布与真实源分布的偏差通过M≈Ninact代的误差传递后被基本消除。同样地,在MC活跃代中,某一裂变源分布的影响在经历M≈Ninact代后可认为忽略不计。直接使用非活跃代数确定组统计方法中的组长度M,是符合MC计算的实际情况的。
1.3 香农熵诊断
在反应堆物理历史上很长一段时间内占优比作为计算收敛速度的重要判断标准,但后期研究表明收敛的判断除keff的收敛判断外,还需包括裂变源分布的收敛判断,且实际上裂变源分布的收敛要慢于keff,即当裂变源收敛时keff一定收敛,但keff收敛还不能判断源迭代是否己达到收敛。对于MC临界计算,应评估keff和裂变源的收敛性。2005年,Ueki等[4]将信息学领域中用于衡量信息量的香农熵概念和方法引入到MC粒子输运方法中,作为临界计算收敛诊断的方法,当熵收敛后,源分布也就收敛。香农熵目前已作为一种具有显著优势的源收敛诊断方法,在RMC等程序中得到应用。
香农熵源收敛诊断方法的核心思想是将每个迭代周期中裂变源中子分布信息用香农熵进行宏观度量,通过观察临界迭代计算中香农熵随代数变化情况来方便地观察裂变源分布的收敛趋势,当源分布趋于平稳时,香农熵收敛于一稳态值。裂变源分布的香农熵定义为:
(23)
其中:H(si)为香农熵;si为第i代的裂变源分布;B为空间网格划分的编号。
2 计算流程
能量偏倚的最佳源偏倚方法建立在香农熵诊断和组统计方法的基础上。对于某一特定算例,首先需通过香农熵诊断确定出组统计的长度M,然后在MC临界计算中设置组统计参数。在裂变源迭代法计算过程中,每完成1次组统计就会得到各裂变源区在各能量区间内的方差信息σi,E。然后,所需的当前代方差信息由上一代的方差信息近似得到,根据式(11)计算出各裂变源区在各能量区间内的最佳源偏倚因子。在保证每个计算代中子总权重守恒的基础上,对抽样得到的裂变源中子在空间和能量上进行偏倚。假设某个裂变源区在某能量区间内的最佳源偏倚因子为εi,E,则可通过简单的轮盘赌与分裂实现最佳源偏倚。

(24)
其中,ωbias和ωbank分别为源偏倚后的粒子权重和存库的粒子权重。
以上的处理方式并不会改变每个计算代裂变中子的总权重,但实现了源中子在空间上的最佳分布。具体的计算流程如下:1) 在RMC程序的输入文件中设置能量分箱;2) 采用香农熵诊断确定组长度M;3) 设置好组统计的参数,开始临界计算;4) 用组统计的方差信息计算最佳源偏倚因子;5) 对粒子的空间位置和能量进行偏倚;6) 回到第4步,更新最佳源偏倚因子;7) 迭代计算,直到计算收敛。能量偏倚的最佳源偏倚方法的计算流程如图1所示。
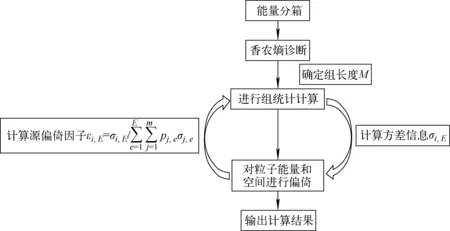
图1 能量偏倚的最佳源偏倚方法的计算流程
3 数值验证
选择典型17×17的压水堆组件[12]进行临界计算。燃料棒是密度为10.196 g/cm3的UO2,锆合金的密度为6.550 g/cm3。几何建模采用17×17的栅元划分,共有289个网格。为更好地展示能量偏倚的最佳源偏倚方法对方差的展平功能,边界条件选择了真空边界条件。组件的几何结构如图2所示。

图2 典型压水堆组件的几何结构
首先对粒子进行能量分箱,本次计算采用C5G7模型[13]的能量分箱,共划分了7个能量区间(单位MeV),从小到大依次为:[0.0,1.3×10-7],[1.3×10-7,6.3×10-7],[6.3×10-7,4.1×10-6],[4.1×10-6,5.56×10-5],[5.56×10-5,9.2×10-3],[9.2×10-3,1.36],[1.36,10]。对该组件进行香农熵统计,每代50 000个源中子,共进行了550个非活跃代的香农熵统计,计算结果如图3所示。由图3可看出,经过十几次非活跃代的迭代过程,组件的源分布基本达到收敛,故组统计方法选择了组长度M=20。
然后使用RMC程序对该组件进行能量偏倚的最佳源偏倚方法进行计算,计算条件为50个非活跃代,2 010个活跃代,其中组统计的长度M=20,所以程序进行了98次组统计计算。本文同时也进行了每代统计(M=1)的最佳源偏倚方法计算。作为对比,使用RMC程序进行了比例抽样法的临界计算,也即未进行最佳源偏倚方法的计算。
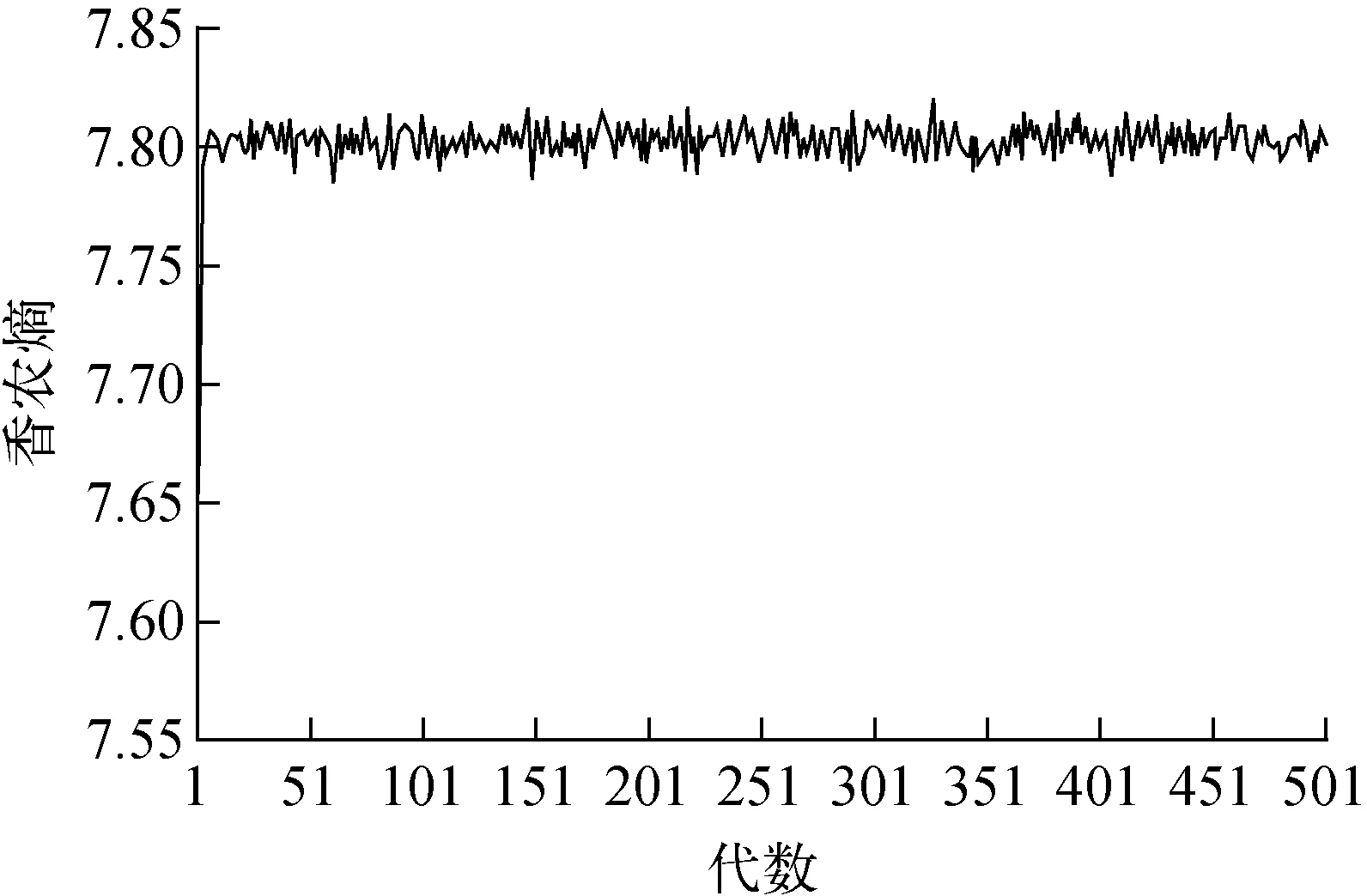
图3 典型压水堆组件香农熵统计的计算结果
能量偏倚的最佳源偏倚方法可实现全局减方差的计算效果,为更好地量化描述全局减方差的效果,本文选择如下参考量[11]。
平均相对偏差:
(25)
平均品质因子:
(26)
相对偏差标准差:
(27)
其中:N为计算结果的个数;Rei为第i个计算结果的统计相对偏差;T为计算时间。
表1列出压水堆组件能量偏倚的最佳源偏倚方法的计算结果。由表1可得出如下结论。
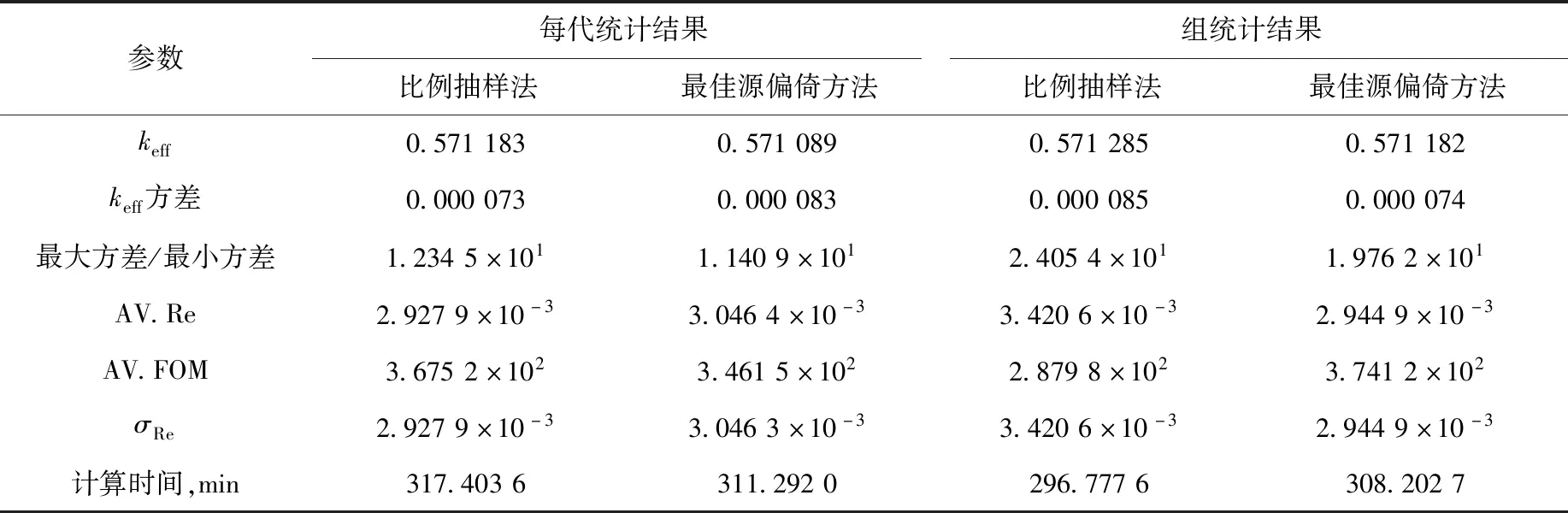
表1 压水堆组件能量偏倚的最佳源偏倚方法的计算结果
1) 不论是每代统计还是组统计,能量偏倚的最佳源偏倚方法均能保证计算结果的精度,即能量偏倚的最佳源偏倚方法的计算结果与未进行能量偏倚的最佳源偏倚的计算结果相同。
2) 不论是每代统计还是组统计,能量偏倚的最佳源偏倚方法均能展平方差的分布。因为能量偏倚的最佳源偏倚因子使得方差大的裂变源区多抽样,方差小的裂变源区少抽样。
3) 基于每代统计的能量偏倚的最佳源偏倚方法与比例抽样法的平均相对偏差、平均品质因子和相对偏差标准差各有大小,未见明显区别。因为每代统计的计算结果存在方差低估计现象,代与代之间具有较大相关性。
4) 基于组统计的能量偏倚的最佳源偏倚方法,平均相对偏差、平均品质因子和相对偏差标准差明显优于比例抽样法,可见消除了代与代之间的相关性后,能量偏倚的最佳源偏倚方法可有效实现全局减方差的效果。
4 结论
使用MC程序进行反应堆临界计算时,裂变源迭代法会带来方差低估计的现象。通过分析源中子的抽样过程,以及对分层抽样法进行数学推导,本文建立起了能量偏倚的最佳源偏倚方法。该方法基于香农熵诊断和组统计方法,对源中子的空间位置和能量进行偏倚,展平了全堆方差分布,并实现了全局减方差的计算效果。对一标准压水堆组件进行了测试,计算结果证明了能量偏倚的最佳源偏倚方法的正确性和有效性。
