无人平台SLAM技术研究进展
2019-07-11王常虹窦赫暄陈晓东赵新洋
王常虹,窦赫暄,陈晓东,赵新洋,刘 博
(1.哈尔滨工业大学,哈尔滨 150001; 2.上海机电工程研究所,上海 201109)
0 引言
同时定位与建图(Simultaneous Localization and Mapping, SLAM)指搭载环境感知传感器等的运动主体,利用环境观测信息估计自身的位姿变化与运动轨迹,同时建立环境地图。
SLAM的相关概念最早由Cheeseman等于1986年的IEEE机器人与自动化会议提出[1],旨在将基于估计理论的方法引入机器人的建图问题与定位问题中。经过30余年的发展,尤其是近年来兴起的基于视觉传感器以及基于优化方法的SLAM算法,使得SLAM及相关技术日渐成为机器人、图像处理、深度学习、运动恢复结构(Structure From Motion, SFM)、增强现实等领域的研究热点。
SLAM由运动主体通过对环境的观测获取相关信息,再通过多传感器融合和全局信息融合的方式进行位姿推算、轨迹估计与环境建图。与传统的卫星导航、惯性导航、路标导航等定位方式相比,SLAM的特点是其所有的算法都围绕传感器收集的环境信息展开。因此在无人移动平台中,SLAM的应用场景为以下三类:
第一类为轻量化、低造价的无人移动平台,例如微型飞行器(Micro Aerial Vehicle,MAV)与移动机器人等。这类平台尺寸与载荷较小,加之成本限制,难以使用高精度的姿态传感器,通常只能使用一些低成本、轻量化的传感器,例如相机、激光雷达、全球导航卫星系统(Global Navigation Satellite System,GNSS)模块、基于微机电系统( Micro-Electro-Mechanical System,MEMS)的惯性测量单元(Inertial Measurement Unit,IMU)等;同时,对于运动轨迹推算的精度又有较高要求。
第二类为复杂环境中长距离巡航的中大型无人移动平台,例如无人驾驶汽车[2]以及无人水下航行器(Unmanned Underwater Vehicle,UUV)[3]等。这类平台在巡航过程中需要对复杂的周围环境进行感知,并且需要解决长距离巡航中的航迹漂移与场景识别问题。
第三类为特种移动平台,例如救援机器人、火星车[4]、各类军用无人移动平台等。这类平台往往在陌生、严苛的室内或室外环境工作,尤其是由于建筑物倒塌或电磁干扰等造成的无卫星定位(GNSS-denied)环境[5-6],使得无人平台在执行任务的过程中既无先验的环境信息,又无法利用外部定位系统。
以激光雷达和轮式里程计等为传感器的2D激光SLAM较为成熟,已经应用于工业现场,例如KUKA Navigation Solution[7];以摄像头等为传感器的视觉SLAM也已应用于低速的商业产品,例如清洁机器人[8-9]。虽然现阶段SLAM算法的实时性、精确性与鲁棒性与实际需求仍有一定差距,但随着计算机视觉、深度学习、概率理论与优化理论的发展,以及多线激光雷达、全局快门相机等高性能传感器的量产化、廉价化与普及化,特别是嵌入式处理器功耗的不断降低、计算能力尤其是并行计算能力的不断提高,SLAM在移动平台上的应用前景越来越明晰,越来越多的国内外高校和机构的研究人员投入到SLAM算法与技术的研究当中。
1 SLAM算法简析
SLAM可建模为机器人系统的状态估计问题[10-11]
xk=f(xk-1,uk,wk),k=1,…,K
(1)
zk,j=h(mj,xk,vk,j),k=0,…,K
(2)
式中,xk为k时刻机器人位姿,uk为驱动器输入,wk为测量噪声,zk,j为k时刻对环境路标mj的观测,vk,j为观测噪声。利用驱动器的传感器读数uk与环境观测数据zk,j,排除wk、vk,j等噪声影响,对机器人系统的状态,即位姿xk与环境mj进行空间状态不确定性的估计,从而获得xk序列的估计值即“定位”,以及环境mj序列的估计值即“建图”,如图1所示[1]。
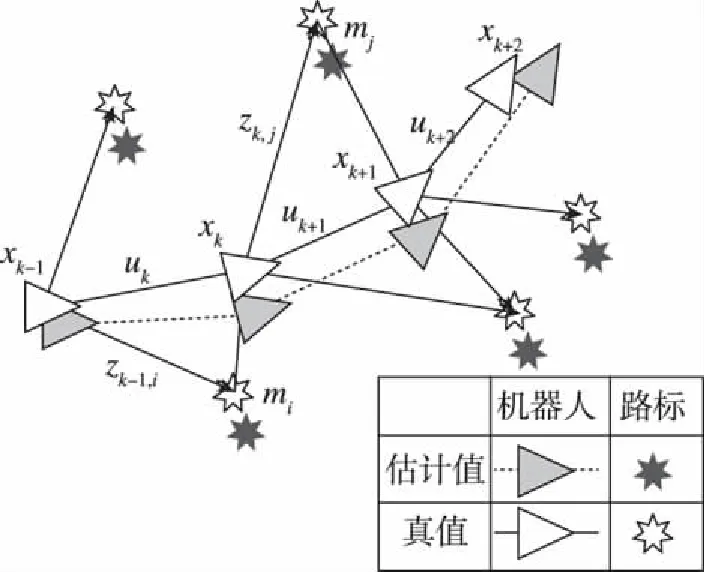
图1 SLAM问题示意Fig.1 The essential SLAM problem
典型SLAM系统通常由环境感知器辅以位姿传感器作为系统输入,前端部分利用传感器信息进行帧间运动估计与局部路标描绘,后端部分利用前端结果进行最大后验(Maximum a Posterior, MAP)估计,从而估计系统的状态及不确定性,输出位姿轨迹以及全局地图。回环检测(Loop Closure)通过检测当前场景与历史场景的相似性,判断当前位置是否在之前访问过,从而纠正位姿轨迹的偏移。SLAM典型结构如图2所示。
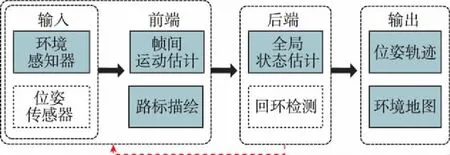
图2 SLAM典型结构Fig.2 Typical SLAM system
后端算法能够实现全局状态估计,是SLAM算法的核心。以扩展卡尔曼滤波(Extended Kalman Filter,EKF)等为代表的滤波法后端基于马尔可夫模型,利用临近帧数据对系统状态进行预测-更新,从而实现全局状态估计。粒子滤波法后端基于蒙特卡罗方法,将系统状态的概率密度函数表示为采样点(粒子)的集合,并在状态后验分布中进行随机采样与均值统计,根据统计结果对概率密度函数进行近似。优化法后端构造了以误差为目标函数,以系统状态为函数变量的优化函数,求得使误差取得极小值时的最优解,即为系统状态的最优估计。
早期SLAM后端多以滤波法为主,但滤波法往往使用临近帧数据,难以利用历史帧数据,这将更容易产生累积误差;系统的马尔可夫假设也使得在回环发生时,当前帧难以与历史帧进行数据关联;此外,典型的滤波方法存在线性化误差,且随着时间的推移难以维护庞大的协方差矩阵。粒子滤波法在一些特定的SLAM算法中有着较好的效果,但其需要用大量的样本数量才能很好地近似状态的概率密度,而大量的样本数量会造成算法的复杂度急剧增加;此外,对样本进行重采样的过程可能导致粒子退化从而影响估计结果。
典型的优化法后端将位姿与路标构成图的节点,并利用光束平差法(Bundle Adjustment, BA)等进行局部优化;同时,将局部优化得到的位姿关键帧作为位姿图的节点进行全局优化。优化法后端能够利用所有时刻的数据进行全状态估计,便于将回环检测加入优化框架,并且将局部估计与全局估计分离。优化法在保证精确性的同时兼顾了效率性,因此在长时间、大地图情景下优化法的效果明显优于其他方法,故优化法尤其是图优化法逐渐成为SLAM的主流后端方法[12]。
2 SLAM算法实现
2.1 激光雷达SLAM
以激光雷达(Light Detection And Ranging, LiDAR)作为环境感知器的SLAM算法称为激光雷达SLAM。激光雷达测量本机与环境边界的距离从而形成一系列空间点,通过帧间点集的扫描匹配进行位姿推算,并建立环境的点云地图。激光雷达的距离测量较为准确、误差模型较为简单,加之测量所得的点集能够直观地反映环境信息,所以激光SLAM是一种发展时间长且较为成熟的SLAM解决方案。
早期激光雷达SLAM的关注点集中于前端的扫描匹配。例如Grisetti等[13]提出的Gmapping算法利用梯度下降法进行前端扫描匹配,并利用RB粒子滤波(Rao-Blackwellized Particle Filter)对匹配进行优化;再如Kohlbrecher等[14]提出的Hector SLAM利用高斯牛顿法进行扫描匹配,无需里程计信息即可得到精度较高的结果。为了提高大范围、长距离场景下的准确性,近年来的激光SLAM研究逐渐关注基于优化的后端算法,例如Hess等[15]发表的Cartographer在局部范围内利用Ceres Solver求解非线性最小二乘实现扫描匹配,并通过子图的构建以及帧与子图的匹配实现了回环检测及全局优化。
基于多线激光雷达的三维激光雷达SLAM可以构造三维点云地图,不仅在帧间匹配上拥有更多的匹配手段以及更好的鲁棒性,而且可以与物理模型、图像等信息进行融合,故拥有较高的定位精度以及较大的发展潜力。例如Zhang等提出的LOAM[16]基于特征点进行扫描匹配并利用非线性优化的方法进行运动估计,以及结合了视觉里程计进行改进的VLOAM[17];Deschaud等[18]提出的IMLS-SLAM利用隐式滑动最小二乘(Implicit Moving Least Square,IMLS)将环境中的点集聚类为表面,并实现了扫描到模型(Scan-to-model)的扫描匹配。有关激光SLAM可参考危双丰等[19]的综述。
2.2 视觉SLAM
以各类视觉传感器作为环境感知器的SLAM算法称为视觉SLAM。视觉传感器结构轻便、成本低廉,并且可以获得丰富的形状、颜色、纹理、语义等辅助信息,因此视觉SLAM具有很大的发展潜力,也是当前的研究热点。根据图像帧间运动推算原理的不同,视觉SLAM主要分为特征法与直接法。
特征法前端对图像中的点、边缘、区域等特征进行提取并将其作为路标,由特征构成的路标在相机运动过程中保持可追踪且全局位置不变。利用计算机视觉方法对帧间图像进行特征提取与匹配后,根据对极几何约束,通过最小化重投影误差(Reprojection Error)来推算帧间运动。特征法SLAM往往采用具有可复验性、可区别性、鲁棒性与效率性的特征点[20],例如SURF[21]、FAST[22]、ORB[23]等。Klein等[24]构造了帧间特征跟踪与全局优化建图的并行结构,并提出了基于FAST特征的PTAM。Mur-Artal等[25]提出了基于ORB特征的前端与基于图优化的后端、适用于单双目与RGB-D相机的ORB-SLAM2。
直接法前端基于强度不变假设(Intensity Coherence Assumption),即同一个空间点投射到连续临近图像中的像素点,图像强度近似不变。利用计算机视觉方法对帧间的局部或全部像素点的光度误差(Photometric Error)进行计算,并将光度误差进行最小化估计,从而推算帧间运动。Engel等提出了基于单目相机、生成半稠密地图的LSD-SLAM[26],和基于RGB-D相机、生成稠密地图的RGB-D SLAM[27]。Forster等[28]提出的SVO结合了特征法与直接法,通过提取角点并对角点局部的光度误差进行最小化估计从而实现位姿跟踪,同时生成稀疏的环境地图。
2.3 视觉-惯性SLAM
由于传感器数据采集频率的限制,基于激光雷达与传统视觉传感器的前端位姿推算频率很难进一步提高,这严重制约了其在无人驾驶汽车、无人机等高速运动平台上的应用;相应地,基于加速度计与陀螺的惯性位姿传感器的数据采集频率很高,但具有明显的累计误差与漂移。基于这两类传感器的互补性,将IMU等惯性位姿传感器与视觉传感器、激光雷达等环境感知器进行组合,利用冗余信息进行带宽互补与误差补偿,具有很大的应用潜力并已被越来越多地用于SLAM算法[29]。其中最有代表性的就是视觉-惯性SLAM。
早期的视觉-惯性SLAM以滤波方法为主,其中多数基于Mourikis等[30]提出的多状态约束卡尔曼滤波(Multi-State Constraint Kalman Filter, MSCKF),例如Hesch等[31]提出的单目视觉惯性里程计,以及Google的Project Tango[32]。Leuteneg-ger等[33]将基于特征法的关键帧与IMU信息进行紧耦合,构造了包括重投影误差和IMU误差的能量函数,以优化法实现了视觉-惯性里程计,并发布了OKVIS。Tong等[34]利用光流法和IMU构造视觉-惯性前端,并利用关键帧进行全局优化和回环检测,提出了VINS-Mono。有关视觉-惯性SLAM可参考Gui等的综述[29]。
应用不同传感器的SLAM方案简要对比见表1。
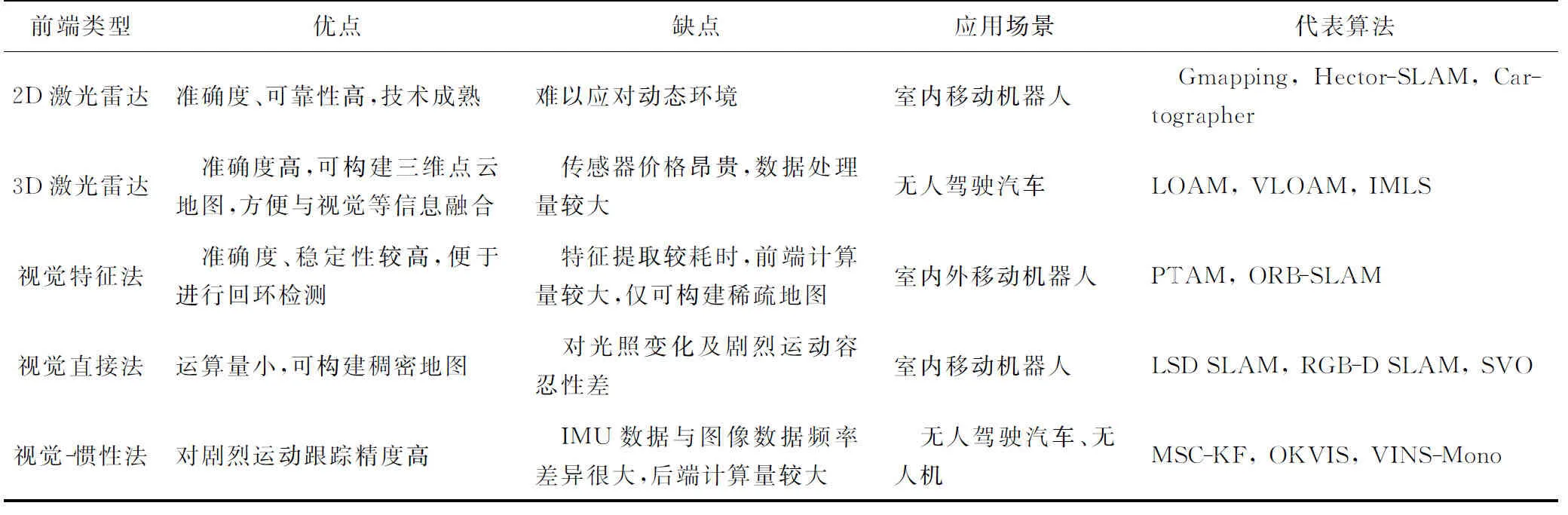
表1 SLAM方案简要对比
2.4 SLAM地图表示
根据无人平台不同的运行环境与任务类型,SLAM可以构建不同种类的二维或三维地图。依据IEEE标准1873-2015[35],二维地图分为几何地图(Geometric Map)、网格地图(Grid Map)与拓扑地图(Topological Map)。几何地图将环境描述为稀疏的点、线等路标;网格地图将环境均等地划分为网格,并标记每个网格被占用的概率,从而区分可通过区域与障碍物区域。几何地图与网格地图统称为度量地图(Metric Map),度量地图定量地描述了环境中物体间的位置关系。拓扑地图将环境表示为包含节点和边的图(Graph),其中节点表示环境中的地点,节点间的边表示地点间的联系。拓扑地图舍去了环境的度量信息,只保留了与任务相关的地点以及地点间的连通性。二维地图的三种表示如图3所示[35]。
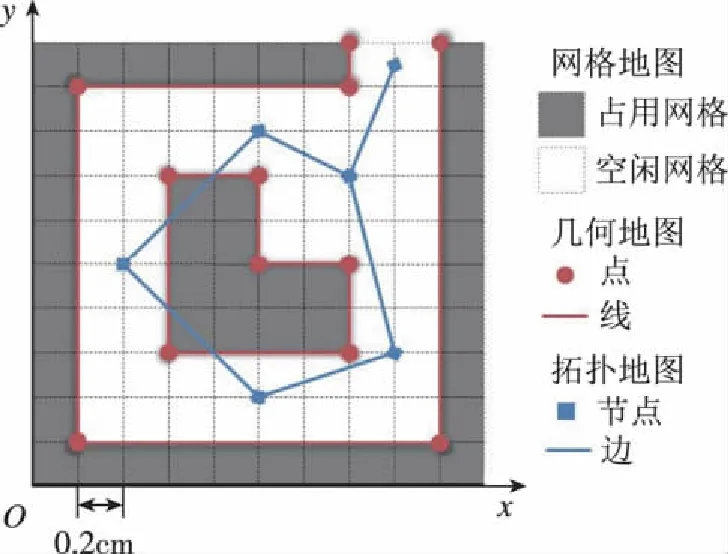
图3 二维地图示例Fig.3 Legend of 2D Map
三维度量地图分为稀疏与稠密两种。稀疏地图一般对应特征法前端,以特征点等作为环境路标。稠密地图一般对应直接法前端与三维激光雷达前端,以点云描述环境,或者将点云聚类为边界、表面或三维物体。Salas-Moreno等提出的SLAM++[36]以及Dame等[37]将稠密地图与图像信息结合,构建了包含实物建模的度量地图。
3 SLAM领域研究热点
3.1 基于新传感器的SLAM
相较于已广泛应用于SLAM的激光雷达、视觉相机与惯性传感器,一些新传感器展现出很大的应用潜力,例如全光相机(Plenoptic Camera)与动态视觉相机(Event-based Camera)等。
区别于仅记录像素点光线强度的传统相机,全光相机可以记录光场,即光线的方向与强度,所以全光相机也被称为光场相机(Light-field Camera)。Dong等[38]利用3×3~40×30的小分辨率全光相机实现了视觉里程计,并证实了其相较于普通单目视觉里程计拥有更高的准确性。Zeller等[39]利用基于微型透镜阵列的全光相机,提出了半稠密视觉里程计DPO,能够输出运动轨迹之外更广范围、更加精细的点云地图。
动态视觉相机受仿生学的启发,不记录场景而是记录场景的变化。区别于传统相机按固定帧率输出整幅图像,动态视觉相机在视场内的像素点光照强度发生变化时,输出对应像素点局部的光强变化情况。因此动态视觉相机的特点是低延时(低至1ms)、高帧率(更新率可达1MHz)、大动态范围(可达140dB,区别于普通相机60~70dB)等[7],在应用于SLAM方面具有很大的潜力。Kim等[40]以及Rebecq等[41]已经初步实现了基于动态视觉相机的SLAM。由于现阶段动态视觉相机的成本较高、普及率很低,为了推动动态视觉相机SLAM算法的研究,Mueggler等[42]发布了基于动态视觉相机的数据集与模拟器。
3.2 基于深度学习的SLAM
深度学习在图像识别与跟踪方面具有非常好的表现,因此其在视觉SLAM领域具有很大的潜力,主要体现在前端的帧间估计以及后端的回环检测两方面。
在前端方面,基于深度学习的方法无需提取特征或计算光度,仅通过神经网络的学习与训练得出模型,以图像序列作为模型的输入,直接输出帧间运动。Constante等[43]利用卷积神经网络(Co-nvolutional Neural Networks, CNN)进行图像帧间估计,从而实现了基于深度学习方法的视觉里程计,展现了在模糊、光照变化等场景下的鲁棒性并具有较好的实时性。
在回环检测方面,与传统的基于稀疏、像素级特征的匹配方法相比,深度学习通过神经网络对图像中的深层次特征进行训练与学习,能够对场景局部信息进行识别与匹配,实现更高的识别率且对光照、季节等环境变化具有更好的鲁棒性,从而更好地实现场景识别。例如Sünderhauf等[44]利用CNN模型提取场景中的图像区域作为特征描述子,由此实现的场景识别在图像视角改变或局部遮挡等情况下仍保持稳定的性能。
虽然越来越多的深度学习技术与成果应用于SLAM领域,但现阶段纯粹的深度学习SLAM有着明显的局限性。例如,深度学习视觉里程计的性能严重依赖于训练集;当场景的运动速度、帧间频率与训练数据差异较大时,对帧间运用尤其是旋转的估计误差会加大。再如,深度学习方法能够实现当前帧与历史帧的场景识别,但难以从场景识别中计算出当前帧相对于历史帧的位姿,往往仅从定性而非定量的角度实现回环检测。所以,如何利用深度学习得到直观、物理意义明确的模型与定量的结果,如何将深度学习方法与传统SLAM方法进行有机结合,是基于深度学习SLAM未来的发展方向;而将深度学习方法与传统SLAM结合的一个典型例子是语义SLAM。有关深度学习SLAM可参考赵洋等的综述[45]。
3.3 语义SLAM
传统的SLAM算法利用点、点云、线、面等低级特征(Low-level Feature)作为环境路标,这将导致运动跟踪与回环检测在动态环境中误差变大甚至失效。语义SLAM将环境中物体的图像、几何特征等聚类为语义标签(Semantic Label),利用深度学习等方法对包含语义信息的环境物体进行识别、跟踪与建图。例如Bowman等[46]将IMU信息、几何特征以及语义信息进行紧耦合并进行统一优化实现语义SLAM;Vineet等[47]利用双目相机在户外环境构造了包含语义分割的稠密地图,并且具有较好的实时性。
语义建图的特点是将传统建图中对环境物体的静态-动态二元分类转变为墙壁、门窗、走廊、人、车等带有不同语义标签的多元分类,隶属于不同语义标签的环境物体具有不同的通过性、移动性等属性。这将有利于增强机器人探索动态环境的自主性与鲁棒性,有助于机器人执行查找特定地点、搜寻特定物体等与语义相关的复杂任务。
3.4 多机SLAM
与传统的单机SLAM相比,以多机器人协作的方式对环境进行探索和建图可以提高速度与精度;并且在分布式系统中,单个或小部分机器人的异常不会导致整个系统的终止,这将大大增加SLAM算法的稳定性[48]。
现阶段,多机SLAM往往将大场景分割为小区域,并将各区域分发给各个子机器人。为了解决数据在多机间的通信、共享、分发与处理问题,多机SLAM的拓扑结构分为两类:一类为中心化结构,数个机器人分别对小区域建图,并将地图传输给主机进行拼接、优化等处理,例如Dong等[49]利用激光雷达以及FLIRT特征实现了分布式机器人建图拼接;另一类为去中心化结构,数个机器人共同建图,通过机间的局部数据交换,建立一致的全局地图,例如Knuth等[50]、Lazaro等[51]、Cunningham等[52]以及Opdenbosch等[53]的研究。有关多机SLAM可参考Saeedi等的综述[48]。
3.5 主动SLAM
传统的SLAM算法被动地利用接收到的数据进行机器人状态估计,而主动SLAM将定位问题与路径规划问题结合,目的是通过控制机器人的运动从而降低状态估计中的不确定性[7]。
主动SLAM问题尚无明确的算法架构与流程。作为一个动态决策问题,主动SLAM方法包括最优试验设计理论(Theory of Optimal Experimental Design,TOED)[54]、信息论[55]、模型预测控制[56]等。
4 结论
经过30余年的发展,SLAM相关技术日渐成熟,基于激光与视觉的SLAM也已初步应用于自动驾驶汽车与MAV等无人平台。目前的SLAM算法在短时、短距、特定场景中已经达到了较高的精度,但为了在无人平台中进行更广泛的应用,当前的SLAM研究需要解决一系列问题。例如,如何构造一种通用、兼容的SLAM算法与实现框架,如何更有效地利用多传感器冗余数据实现SLAM,如何在嵌入式环境中高效可靠地运行SLAM算法,以及如何解决高动态环境下的SLAM算法稳定性等。当这些问题得以解决之后,将迎来SLAM技术得以广泛应用、机器人执行任务更加自主化的时代。
