基于子图模式的反恐情报关联图集分析
2019-07-09李勇男


摘 要:[目的/意义]利用子图模式对暴恐案件中的人员关联进行分析可以发现涉恐人员关联图中的规律,为反恐情报分析提供有效参考。[方法/过程]首先对涉恐基础数据进行预处理,保证图中各顶点的唯一性。通过计数统计出所有的频繁1-子图和频繁2-子图,然后不断迭代生成其他候选子图并筛选频繁子图,直到达到终止条件为止。[结果/结论]该方法根据反恐情报的特点进行了优化,避免了普通频繁子图挖掘中的大量图同构检测,挖掘出的频繁子图可以反映不同类别涉恐人员之间的联系规律和联系特点,发现暴恐案件线索,有效预测和打击恐怖活动。
关键词:子图模式;反恐情报;数据挖掘;候选子图;图同构
DOI:10.3969/j.issn.1008-0821.2019.07.005
〔中图分类号〕G359;D631 〔文献标识码〕A 〔文章编号〕1008-0821(2019)07-0037-07
Abstract:[Purpose/significance]Frequent subgraph mining could provide rules which are found from relational graphs of terrorists in the crime of terrorism for counter-terrorism intelligence analysis.[Method/process]Before subgraph mining,the paper preprocessed the data to make sure the uniqueness of every vertex,the it counted the number of subgraph to produce frequent 1-subgraph and 2-subgraph in order.After that,repeated the process of generating other candidate subgraph and mining frequent subgraph until the terminal condition was satisfied.[Result/Conclusion]The result subgraphs could provide terrorism related clues which reflect the features of relationships among terrorists and effectively fight against terrorism.
Key words:subgraph pattern;counter terrorism intelligence;data mining;candidate subgraph;graph isomorphism
美國9?11 恐怖袭击事件发生以后,世界各地的恐怖主义活动逐渐呈现越反越恐之势[1]。尤其近几年,以欧洲的一些大城市为代表发生了多起大规模暴力恐怖袭击事件。2014 年6 月,在第68 届联合国大会上决议通过了《联合国全球反恐战略》,自此严厉打击暴力恐怖主义成为维护世界和平的主要任务之一。我国近年来也发生了昆明3?01、北京10?28、新疆7?5等多起暴恐案件[2]。为打击我国境内的恐怖主义活动,2015年12 月27日第十二届全国人民代表大会常务委员会第十八次会议正式通过《中华人民共和国反恐怖主义法》,新疆维吾尔自治区、浙江省等地也陆续出台了相关的反恐法实施办法。面对如此严峻的反恐形势,国家反恐怖工作领导小组多次强调要加强反恐情报收集,实现反恐预警,将暴恐活动消灭在萌芽中。在大数据背景下,人们在工作、生活、学习、旅游、消费等活动中都会产生数据,形成多种来源的数据流,利用数据挖掘等技术可以对这些信息进行快速有效的分析,为实现提前预警提供有效的情报依据。
子图模式又称频繁子图,是指在图集中出现频率较高的子图,即“公共子结构”。子图模式挖掘是数据挖掘的主要方法之一,也是一种比较复杂的关联分析。在由“顶点”和“边”组成的数据结构“图”的集合上挖掘子图模式的任务称作频繁子图挖掘。频繁子图挖掘目前主要应用于生物分子分析、化学结构分析、网络拓扑以及文档拓扑结构等实体的分析。在中国知网、百度学术等知名中文文献数据库或者学术搜索引擎中利用中文关键词“频繁子图”或“子图模式”与“反恐”组合搜索,没有发现直接相关的文献。说明在以上中文数据库中,关于反恐情报中频繁子图挖掘的研究非常少。在谷歌学术搜索和必应学术搜索中,涉及这两个概念(“Subgraph Mining”和“Counter-terrorism”)的英文文献主要包括网页链接分析[3-4]、社交网络战略分析[5]、社交网络中的社区探测[6]、社交网络的风险评估[7-8]、重要人员检测[9]、新的频繁子图挖掘算法[10-11]、基于云计算的智能数据分析模型[12]等方向,也没有发现根据涉恐人员的特点专门利用频繁子图分析涉恐人员关联规律的研究。本文将研究频繁子图挖掘在涉恐人员关联分析中的应用。
1 子图模式挖掘
1.1 子图模式挖掘简介
子图模式又称频繁子图,子图模式挖掘是指给定图集和最小支持度阈值,找出使得所有支持度大于或等于最小支持度阈值的子图[13]。子图模式挖掘是关联分析方法中远比频繁项集挖掘[14]、频繁静态空间模式挖掘[15]、频繁序列模式挖掘[16]、频繁轨迹模式挖掘[17]更复杂的方法。一般情况下,在任何1个项集中每个单项只能出现0次或1次。但是,在图中1个顶点可能出现多次,而且即使是对相同的顶点标号对,其边的权值也可能不同[18]。
1.2 子图模式挖掘中的基本概念
本文的反恐情报关联图集分析中需要用到的基本概念如下:
1)顶点:表示涉恐人员;
2)边:表示两个涉恐人员之间的联系,边的权值表示联系的紧密程度,权值的大小根据涉恐人员之间的通话[19]、同住宿[20]、同上网[21]等联系设定;
3)图:由若干顶点和连接顶点的边构成的数据结构体,是涉恐人员关联的一种直观的表示方法;
4)子图:是指给定图G′=(V′,E′)和G=(V,E),如果顶点集V′是V的子集,并且它的边集E′是E的子集,则称G′是G的子图;
5)k-子图:包含k个顶点的子图,即表示k个涉恐人员的关联;
6)支持度:表示在图集中所有包含某子图的图的计数与总图计数的比值;
7)邻接矩阵:一种利用矩阵表示图中顶点和边的方法;
8)事务表:将图中的每条边表示成形如(顶点1,顶点2,边的权值)形式的表格,对应表示(涉恐人员1,涉恐人员2,两人的联系紧密程度数值)。
1.3 子图模式挖掘方法分析
主流的子图模式挖掘方法主要分为基于先验原理的方法(例如AGM和FSG等)和基于模式增长的方法(例如gSpan、CloseGraph和FFSM等)[22]。基于先验原理的方法运算简单,专业门槛低,更易于普及推广。基于先验原理的方法还可以采用直接将图结构映射为事务集的形式,然后利用普通频繁项集的挖掘方法进行频繁子图挖掘,但是这种方式会产生非连通图,即同一个图中包含孤立顶点或孤立子图。如果应用这种方法,则挖掘出的涉恐人员关联会有连接中断,分析结果并无实际意义。在反恐情报分析中主要考虑涉恐人员之间的联系,频繁子图挖掘时只需要考虑连通图。非连通图表示该图中存在至少两组涉恐人员之间没有联系,反恐情报分析中不考虑此类图。AGM(Apriori-based Graph Mining)算法使用每一步增加1个节点的扩展方式来产生候选子图,FSG算法使用每一步增加1条边的扩展方式来产生候选子图。这两种方法在生成频繁子图的过程中都需要比较大量的图同构,如果原始图集较大较复杂,则剪枝后的候选子图数量仍然很多,计算效率不高。
假设两个顶点互换后的图结构不变,则称交换前以及交换后的两个图等价,即两个图同构。一般情况下,在挖掘频繁子图的过程中,需要判断每个候选子图是否与其他频繁子图拓扑等价。由于每个图按照顶点次序不同,可以有多个邻接矩阵表示方法,所以处理图同构时要转换为唯一的邻接矩阵表示,将图映射为唯一的串表达式,一般采用字典最小或字典最大串,计算开销非常大。类似化学结构分析中的频繁子图挖掘,各种元素在元素周期表中的代号唯一,因此分析中一定会存在需要检测大量图同构的问题。
2 涉恐人员关联图集生成方法
本文在构建原始图集时直接根据反恐情报的特点将图顶点按序排列,且保证每个顶点唯一,这就避免了大量图同构检测中的邻接矩阵转换,直接对比唯一的邻接矩阵即可,从而达到提高反恐情报分析效率的目的。
如图1所示为生成原始图集的方法,首先对不同来源的数据分组,然后在各分组中以人员为顶点、人员联系为边分别生成关联图,最后各分组中的数据组成图集。
在涉恐人员分析中,在人员分类用代号表示后,每个人员的涉恐风险以及部分特征还是有差别的。产生涉恐人员关联图集时首先利用分类方法[23]将涉恐人员分类,然后根据风险分析方法将图中同时出现的同一类人员进行排序,保证每个人在图中对应顶点的唯一性,同一类别人群中的人员排序以数字表示。不同图中的顶点标号例如A1和A2表示的是不同的人员,其标号中的字母A表示两人都属于A类别人员,数字1和2表示在其对应图中所有A类人员的相对风险排序。图中连接各“顶点”之间的“边”的权值根据已掌握的涉恐人员之间的联系确定。联系的种类主要包括通信关联、物流关联、交易关联、同乡关系、亲属关系等[24]。人员关联圖中如果以人员联系的直接权值为边的值,则为连续数值取值范围过大,不宜挖掘出频繁子图。所以还要利用区间划分的方法,将连续数值转换为几个离散的参数[25],例如11~20设为p,21~50设为q,51~100设为r。不满足最小权值要求的微弱关联例如权值为1~10则视为在图中不连通,即对应图顶点之间没有边。
这种处理方式的挖掘结果会漏掉一部分模糊频繁子图,但是挖掘出的频繁子图定义人员关联时会更精准,同时挖掘效率也会更高。这里的“模糊频繁子图”是指初步划分人员类别后,不再进行各分类内的排序,同类人员的代号完全相同。
3 涉恐人员关联图集子图模式挖掘方法
由于在涉恐人员关联分析中“人”即顶点是最核心的要素,因此本文采用顶点增长的方式。在实际的反恐情报关联图集分析中,如果频繁子图中顶点和边的数量过少则没有太大参考价值,在反恐情报关联图集分析中有必要专门设置最小顶点数阈值。如图2所示为参考顶点增长的经典方法AGM的流程[26],本文修改了数据生成和预处理的方法,具体分析流程描述如下:
1)数据生成和数据预处理。根据样本数据生成标准图结构的图集和对应事务表。将涉恐人员分类,每个类别用不同字母表示成一级编号,映射为图中的顶点。同类人员如果在图中多于1个,则根据涉恐风险特征排序进行二级编号用数字表示,保证其在图中的唯一性和顺序性,每个图对应的邻接矩阵唯一。图中边的权值根据不同人员之间的所有联系综合计算得出。
2)设定最小支持度计数、最小顶点计数的参数阈值。
3)利用统计计数依次发现频繁1-子图和频繁2-子图。
4)迭代产生频繁k-子图(k>2)。连接频繁(k-1)-子图产生候选k-子图,按序从该k-子图删除1条边,并检查删除该边后的(k-1)-子图是否连通且满足频繁条件。只要存在非频繁(k-1)-子图,则将该候选k-子图直接删除。对没有被删除的候选k-子图计算支持度,满足条件则保留,不满足条件则删除。继续本步骤,产生频繁(k+1)-子图。直到没有新的频繁子图或新的候选子图产生,终止挖掘过程。
在产生频繁k-子图的过程中还要考虑多种不同情况,将在下文中结合示例详细描述每一种情况。普通的频繁子图挖掘中,需要判定每个(k-1)-子图是否存在图同构问题。检查过程中要进行对应图邻接矩阵的大量转换,计算开销非常大。前文中提出了反恐情报中一种专用的原始样本图集生成和预处理方法,不再需要图同构检测,因此下文的分析中将不再讨论图同构问题。
4 反恐情报中的子图模式挖掘示例
4.1 涉恐人员关联图集样本
反恐情报子图模式挖掘前,除了常规的数据挖掘预处理外,还要将所有的人员关联统计出来并生成原始样本图集。首先按照基础人员的涉恐特征,将不同的人员分为几大类。基础涉恐人员分类时以职业、教育水平、年龄、身高、体重、性别、收入水平等属性特征划分。分类后将人员划定为A、B、C、D、E、F……等不同的人群,再利用风险分析为每个分类中的人员编号排序,保证唯一性。
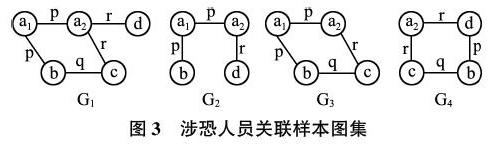
如图3所示为一组涉恐人员关联样本图集,图集中共有4个子图对应4组人员数据,分别包含5人、4人、4人、4人,即原始样本图集共由17名人员的数据生成,每个子图中的人员编号表示类别和在对应子图中的排序。图中的数据完全随机生成,表1所示为对应的事务表。例如图G1中的边(a1,b,p)前两个元素为两个顶点a1和b,表示两个涉恐人员,p表示两个人员之间的联系权值大小。本文将以这四个虚拟的关联图详细说明如何利用子图模式挖掘发现涉恐人员的联系规律。
图3中4个人员关联图对应的邻接矩阵分别为MG1、MG2、MG3、MG4。所有对角线数据表示每个人与自己的关联,对应值均为0,人员权值关联是双向的,所有邻接矩阵均为对称矩阵。矩阵中人员排序为a1、a2、b、c、d。G1矩阵中第一行第一个p即表示两名涉恐人员(a1,a2)的对应联系权值,第一行第二个p表示(a1,b)的对应权值,同理可得矩阵其他值的意义。因为图集中所有顶点即所有人员都是唯一的,且在邻接矩阵中的相对顺序是不变的,所以对应的邻接矩阵一定是唯一的,对比子图时只需要利用唯一的邻接矩阵对比。
4.2 量化分析过程
设最小支持度阈值为40%,则频繁子图支持度计数至少为2(大于等于4*40%,数值4表示图集中共有4个关联图),最小顶点数阈值为4。如图4所示为样本人员关联图的子图模式挖掘过程,图中圆括号内数字表示支持度计数。当子图中只有1个节点(k=1)时,只需对图集中每个顶点计数,如果候选1-子图(只有1个单独顶点)计数大于或等于2时,则满足支持度条件,样本图集中有5个顶点满足条件。接着在表1中利用频繁1-子图两两组合,通过计数挖掘出频繁2-子图(k=2),每个子图中包含2个顶点和1条边,共有5个频繁2-子图满足条件。
从挖掘频繁k-子图(k>2)开始,基于每两个频繁(k-1)-子图共享“核”(相同的频繁(k-2)-子图,对应邻接矩阵除了最后一行和最后一列完全相同)生成候選k-子图,然后利用先验原理和支持度计数统计选择满足条件的频繁k-子图。产生候选k-子图和频繁k-子图的过程有以下几种不同的情况。
查阅表1,对应事务表中(b,c,?)两个涉恐人员的边只有q一种值。当取值为q时,对应所有的3-子图均为频繁3-子图,且满足支持度计数条件,所以g41为频繁4-子图。假设b和c两个涉恐人员还有其他的联系权值也满足频繁条件,则只取权值更大的边。例如(b,c,Q)也满足条件且Q>q,则b和c之间的边取Q值。
情况3:存在新增顶点生成边且不满足频繁条件(图7中的“问号”可取非0值但对应子图不满足条件),这时考虑边的权值取0的情况。考虑合并频繁3-子图g31和g33的情况,候选4-子图如图7所示。查询表1发现(b,d)之间存在边,取值为p。当边的权值为p时,存在非频繁子图,不满足条件,这时只考虑二者之间没有边的情况,即权值取0。当取0时,所有3-子图频繁,且支持度计数满足条件,所以对应频繁4-子图为g42。
最后生成的频繁子图即为g41和g42,满足最小顶点数要求。本文中的虚拟涉恐人员关联样本图集较小,图中“顶点”和“边”数量也较少,所以频繁子图结构非常简单。实际反恐情报关联图集分析中挖掘出的人员关联会非常复杂。同时,在实际应用中,“边”的权值不一定用数值区间离散化简单表示,还可以根据不同的联系类型标记,挖掘出更精细化、更有参考价值的涉恐人员关联规律。
5 结 语
本文提出了如何利用子图模式挖掘发现暴恐案件中恐怖分子的联系规律。经典的子图模式挖掘方法中大多基于顶点增长或者边增长的方式迭代的扩展子图,通过生成候选子图然后筛选频繁子图的方式实现。也有一部分方法基于类似频繁模式树的方式采用模式增长的思路。这些方法中一般要利用一些专门设计的算法来进行大量的图同构检测,尽量减少这部分计算的开销。本文从反恐情报关联图集分析的目标出发,结合反恐情报的特点,在数据预处理时不但将涉恐人员按照涉恐特征分类,还在每个分类中对涉恐人员进行风险评估排序,保证图集中所有图顶点唯一且按序排列,进而保证每个图的邻接矩阵唯一,避免大量的图同构检测。文中涉恐人员之间的关联需要按照各种不同联系综合计算出数值权重,再利用区间划分将连续数值转换为权重类别。
参考文献
[1]王震.“9?11”以来全球反恐战略困境探析[J].社会科学,2017,(9):16-28.
[2]腾讯网.近年来新疆分裂势力制造的暴恐事件不完全汇总[EB/OL].http://news.qq.com/a/ 20140302/005359.htm,2018-10-15.
[3]Badia A,Kantardzic M.Link Analysis Tools for Intelligence and Counterterrorism[C]//International Conference on Intelligence and Security Informatics.Springer Berlin Heidelberg,2005:49-59.
[4]Akhtar Z,Singh M K,Begam N.Challenges and Usage of Link Mining to Semantic Web[J].Intemational Journal of Electronics and Computer Science Engineering,2012,(1):775-780.
[5]Michalak T P,Rahwan T,Wooldridge M.Strategic Social Network Analysis[C]//The Thirty-First AAAI Conference on Artificial Intelligence(AAAI),2017:4841-4845.
[6]Muslim N.A Combination Approach to Community Detection in Social Networks by Utilizing Structural and Attribute Data[J].Social Networking,2015,5(1):11-15.
[7]Camacho D,Gilpérez-López I,Gonzalez-Pardo A,et al.RiskTrack:A New Approach for Risk Assessment of Radicalisation Based on Social Media Data[C]//CEUR Workshop Proceedings,2016:1-10.
[8]Lara-Cabrera R,Pardo A G,Benouaret K,et al.Measuring the Radicalisation Risk in Social Networks[J].IEEE Access,2017,(5):10892-10900.
[9]Farooq E,Khan S A,Butt W H.Covert Network Analysis to Detect Key Players Using Correlation and Social Network Analysis[C]//International Conference Internet of Things and Cloud Computing.ACM,2017:1-6.
[10]Rao B,Mishra S.An Approach to Detect Patterns(Sub-graphs)with Edge Weight in Graph Using Graph Mining Techniques[M]//Computational Intelligence in Data Mining.Springer,Singapore,2019:807-817.
[11]Shelokar P,Quirin A,Cordon O.MOEP-SO:A Multiobjective Evolutionary Programming Algorithm for Graph Mining[C]//Intelligent Systems Design and Applications(ISDA),2011 11th International Conference on.IEEE,2011:219-224.
[12]Goteng G L,Tao X.Cloud Computing Intelligent Data-Driven Model:Connecting the Dots to Combat Global Terrorism[C]//Big Data(BigData Congress),2016 IEEE International Congress on.IEEE,2016:446-453.
[13]张仲妹,王桂玲,张赛,等.基于频繁子图挖掘的数据服务Mashup推荐[J].电子科技大学学报, 2016,45(2):263-269.
[14]李勇男,梅建明.基于频繁模式树的涉恐情报关联分析[J].情报科学,2017,35(9):141-145,152.
[15]李勇男.空间模式挖掘在反恐情报分析中的应用研究[J].情报杂志,2018,37(4):33-37.
[16]李勇男.基于频繁序列模式挖掘的反恐情报关联分析[J].情报理论与实践,2018,41(10):100-104,46.
[17]李勇男.时空轨迹频繁模式在反恐情报分析中的应用研究[J].情报杂志,2018,37(8):51-55.
[18]刘振.频繁子图挖掘算法的研究与应用[D].长沙:中南大学,2009:13-14.
[19]侯丽波,王冠.交互式话单数据的社会关系权值分析[J].中国刑警学院学报,2017,(5):106-112.
[20]付璇.旅店同住分析系统的设计与实现[D].北京:北京大学,2011.
[21]陳刚,李松岩.对以异常行为信息为基础科学构建积分预警系统的思考[J].北京警察学院学报,2013,(1):44-47.
[22]张焕生,崔炳德,王政峰,等.基于图的频繁子结构挖掘算法综述[J].微型机与应用,2009,28(10):5-9.
[23]李勇男.贝叶斯理论在反恐情报分类分析中的应用研究[J].数据分析与知识发现,2018,2(10):9-14.
[24]陈鹏,瞿珂,陈刚,等.反恐背景下的个人特征数据构成与涉恐个体的挖掘分析[J].情报杂志,2018,(4):38-41,68.
[25]李勇男,梅建明,秦广军.反恐情报分析中的数据预处理研究[J].情报科学,2017,35(11):103-107,113.
[26]张伟.频繁子图挖掘算法的研究[D].秦皇岛:燕山大学,2011:13-14.
(责任编辑:孙国雷)
