数据分析服务流程模型推荐
2019-07-09曾兆伟
曾兆伟,曹 健
(上海交通大学 计算机科学与工程系,上海 200240)
1 引 言
当前数据分析服务在许多领域已经变得至关重要.但同时,由于数据和方法的多样性,执行数据分析可能是一项非常复杂的任务.例如数据分析中经典的案例——尝试预测数据内存在异常情况时的信用风险,其模型便十分复杂.一般这些数据分析服务工作流模型都是由专业的数据分析人员进行建立的,对于经验不足的人员来说,建立此数据分析服务工作流模型是一件具有挑战性的任务.而对于经验丰富的专业人员来说,这项任务同时也是十分费时费力的.
与此同时由于数据分析模型的多样性,用户想找到相似的模型进行借鉴或者复用时,也往往十分困难.如在流行的数据分析服务平台OpenML上,用户在上面上传数据集,对数据集创建相应的数据分析任务,构建模型,并挑选模型在数据集上运行、分析.但在OpenML上其存在着20,000左右用户上传的数据集,针对这些数据集用户创建了68,000左右的数据分析任务,并且构建约6,000个左右模型,在这些数据集上共运行了9,000,000次模型.用户如果想要通过数据集的相似性或者模型的运行记录来人工挑出一个符合当前数据集的模型,过程将十分困难并浪费精力.
因此对于数据分析人员进行专业和符合需求的数据分析工作流模型推荐是十分必要的.其一方面可以节省分析人员的时间,另一方面可以复用过去已建立的模型,无需用户自己从头构建模型,对建好的模型重复使用,节省成本.当前研究和市场上,也已经存在有相关的产品,如Microsoft的Azure机器学习平台,和德国的RapidMiner数据挖掘平台.但它们都或多或少存在一些不足之处或者可改进的地方,如RapidMiner通过用户在设计数据分析工作流模型的过程中,针对用户当前所设计完成的步骤,通过算法和库中存在的模型进行比较,然后为用户推荐模型下一步的设计方案.但是,其没将数据的上下文信息考虑在内,即数据的特征和用户的对分析结果的偏好(如非误率等),而这些信息对于模型推荐的准确率的影响是十分之大的.比如,两个数据集如果具有相似的特征,那么他们的数据分析工作流模型就有可能是相似的,可以复用的.同时,对于模型而言,其一般存在着文本语义标签,用以对于模型进行描述.因此在设计模型时,同样可以通过文本语义进行推荐,提高准确率和效率.
对于数据分析服务模型推荐,本文拟从每个用户最基本的上传信息入手,即数据集数据和文本描述信息.相比起传统的在用户建模过程中推荐下一步应该如何构建,本文通过数据集数据和文本描述信息在一开始为用户进行推荐,其一方面节省用户的时间,不需要从头开始构建自己的数据分析服务流程模型,另一方面也可和传统的建模过程中模型推荐相互补充.
本文基于OpenML数据分析服务平台,通过针对数据集的数据特征和文本描述为用户提供数据分析服务模型推荐.第二部分为背景与相关工作的介绍;第三部分直观地介绍了进行模型推荐的总体流程;第四部分介绍了文中所用算法的一些基本概念;第五部分详细介绍了所使用的算法;第六部分为实验的结果;最后对本文进行总结与展望.
2 相关工作
工作流(服务流程)模型推荐,现有主要分为传统的业务工作流模型推荐和随着数据挖掘、大数据兴起的数据分析工作流模型推荐.
对于传统的业务工作流模型推荐[1],各种研究已较为完善[2-5],算法已较为成熟.目前主流的算法主要分为:分类(Classification)、概率图模型(Probabilistic Graphical Models)[6].其中分类又主要分为:聚类(Clustering methods)、决策树(Decision trees).概率图模型又分为贝叶斯网络(Bayesian networks)、马尔科夫链(Markov Chains).它们都能较好的进行业务工作流模型的推荐.
而对于数据分析工作流模型推荐,一开始研究者们纷纷借鉴了业务工作流模型推荐的方法.在用户设计模型时,对模型进行解析,与数据库中模型进行比较,为用户推荐模型下一步构建步骤[7,8].常见的方法有:上下文感知的KNN方法(A Context-Aware kNN Method)[9]、上下文感知共现方法(A Context-Aware Co-Occurrence Method)[10]、基于链接的方法(A Linked-Based Method)、基于链的方法(A Chain-Based Method)等等.
以上方法将传统的模型推荐算法结合上下文信息,应用于数据服务流程模型推荐上,确实提高了推荐的准确率,但其同时也存在一些问题:
1)只考虑了模型的信息,但是数据分析工作流与传统的业务工作流不同,还需要考虑数据的特征.相比起传统的业务工作流模型,数据分析服务流程模型其拥有丰富的数据集信息,通过数据集信息的特征比较挖掘,往往能使得模型推荐拥有更好的效果.
2)可以利用模型描述的文本描述语义标签,将其加入预测因子中,提高推荐的准确率.对于数据分析服务流程,其文本描述信息常常包含着其设计者所需达到的目标或是偏好,如其可能更加偏向非误率等,这些信息对于模型推荐的结果有很大的影响,需将其考虑在内,用以提高模型推荐的准确率.
3 模型推荐
对于数据分析服务流程模型推荐,通过从OpenML下载数据集、模型、模型运行信息,其中可以直观的观察到在数据集中可以用于模型推荐的信息有数据集的数据信息和数据集的文本描述信息.然而,直接用数据集数据信息和文本信息进行模型推荐是较为难以做到的.
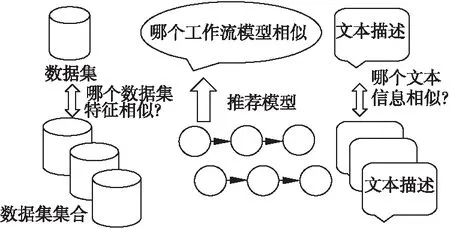
图1 全局模型推荐步骤Fig.1 Global model recommendation steps
故对于数据集数据,如图1所示,其可以在之上进行特征的提取,将数据信息转化为数字的模型特征.之后便可以利用协同过滤计算相似性.
同时,对于文本描述信息,其可以转换为计算文本相似性.同时,可以通过转换为文本多分类问题计算模型的类型,提高准确率.
4 基本概念
文本相似性:由于文本相似性在不同领域其内涵有所不同,因此没有统一公认的定义.从信息论的角度而言,文本相似度与文本之间的共性和差异有关,当文本之间的共性越大、差异越小时,则相似度越高;当文本之间的共性越小、差异越大,则相似度越低.文本完全相同便是相似度最大的情况.基于假设可以推论出相似度定理,如公式(1)所示.
(1)
其中,common(A,B)是描述文本A和B的共性信息,description(A,B)是描述A和B的全部信息,从公式(1)可以看出相似度与文本共性成正相关.同时在实际应用中其计算文本相似性主要的方法有如图2所示.
协同过滤[11]:协同过滤是利用集体智慧的一个典型方法,其主要目的便是预测和推荐.协同过滤算法的核心思想便是:人以类聚,物以群分.其通过对用户历史行为数据进行挖掘,发现用户的偏好,基于用户不同的偏好为用户进行群组划分,并且为各个群组推荐符合用户偏好的商品.
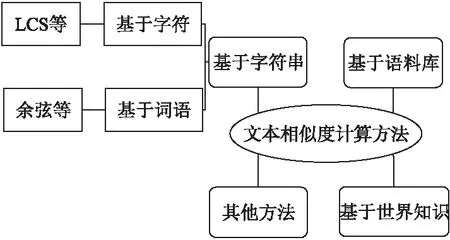
图2 文本相似度计算方法分类Fig.2 Text similarity calculation method category
协同过滤算法主要可以分为两类:基于用户的协同过滤算法(user-based collaborative filtering)和基于用户的协同过滤算法(item-based collaborative filtering).
其中,协同过滤算法最重要的便是相似度的度量.相似性的度量的方法有很多种,不同的度量方法适用于不同的应用.相似性度量方法的设计也是机器学习算法设计中很重要的一部分,尤其是对于聚类算法,推荐系统这类算法.
相似性的度量方法必须满足拓扑学中的度量空间的基本条件:
假设d是度量空间M上的度量:d:M×M→R,其中度量d满足:
非负性:d(x,y)≥0,当且仅当x=y时取等号;
对称性:d(x,y)=d(y,x);
三角不等性:d(x,z)≤d(x,y)+d(y,z)
这里主要介绍三种相似性的度量方法:欧式距离、皮尔逊相关系数和余弦相似度.
欧式距离,即欧几里德距离(Euclidean Distance)最初用于计算欧几里德空间中两个点的直线距离.假设点x和y是n维空间的两个点,它们之间的欧几里德距离计算公式为:
(2)
可以看出,当n=2时,欧几里德距离即为平面上两个点的直线距离.用欧几里德距离表示相似度时,一般采用公式(3)进行转换:
(3)
由公式可以看出,当x,y间距离越小,它们的相似度便越大.
皮尔逊相关系数(Pearson Correlation Coefficient)则一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间.在欧氏距离的计算中,不同特征之间的量级对欧氏距离的影响比较大,例如A=(0.05,1),B=(1,1)和C=(0.05,4),我们就不能很好的利用欧式距离判A和B,A和C之间的相似性的大小.而皮尔逊相似性的度量就对量级不敏感:
(4)
sx,sy是x和y的样品标准差.
余弦相似性[12](Cosine Similarity)则为计算两个向量的夹角,有着与皮尔逊相似度同样的性质,对量级不敏感,被广泛应用于计算文档数据的相似度:
(5)
5 算 法
利用数据文本描述信息和特征进行数据分析服务流程模型推荐,本文利用OpenML上的数据集及模型数据信息,其构建模型步骤如图3所示.
1)对数据集及模型信息进行预处理;
2)提取数据集数据特征;
3)提取数据集文本描述特征;
4)利用数据集数据和文本特征构建SVM模型类型分类器,得到模型类型;
5)利用协同过滤算法计算数据集间数据特征和文本描述信息特征的相似性,根据相似性和模型类型推荐模型.
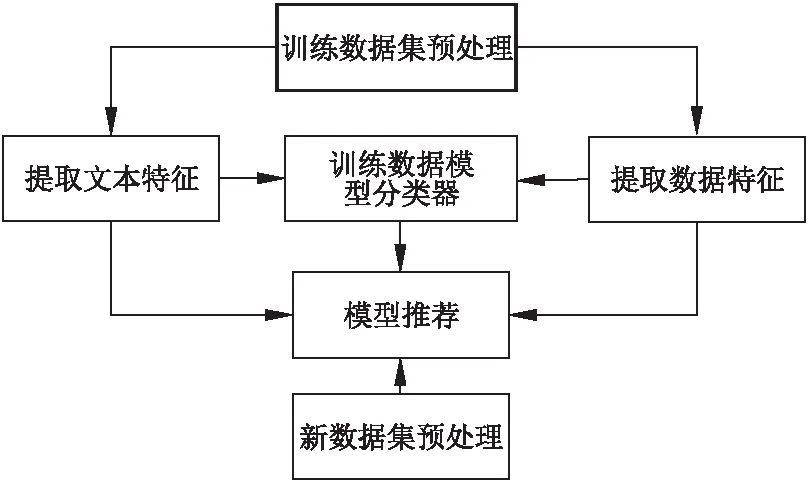
图3 模型推荐具体步骤Fig.3 Model recommended specific steps
5.1 数据预处理
实验基于数据集基于OpenML,主要包括数据集数据,数据集文本描述信息,各个数据集上模型运行信息等.
首先过滤数据集信息,对于在上面运行模型次数少于100次的数据集,因为其信息不足,进行排除.
然后标注各个数据集上的“最佳模型”,并得到此模型的模型类型.在此考虑最佳模型主要有两方面影响因子:模型在此数据集上运行得到的准确率accuracy,模型被用户运行次数runTime.可以根据如下公式进行归一化处理,并得到评分最高的模型.
(6)
其中,A为准确率,R为单个模型运行次数,R′为数据集上所有模型总运行次数,α和β为归一化因子.
当然定义模型运行好坏与否不一定只取决于运行得到的准确率,还有模型的ROC曲线等,其也可以类比带入公式,并将其扩展.
一般为取最佳运行效果或最多运行次数,故根据各个模型取出此两种评价因子,然后计算评分,即可得到各个数据集对应的最佳模型.
5.2 数据集特征信息挖掘
对于数据集特征,可以对数据集进行统计分析,参考OpenML可得到119个特征.利用这些特性可以得知数据集的一些特性,如数据集实例数目,数据集属性数目,数字属性数目,文本属性数目等.同时,这些特征本身也都属于数字特征,故可以很直接的用于后面的协同过滤推荐中.
5.3 文本描述信息挖掘
对于同类数据集的文本描述信息,其往往隐藏着相似的信息,如数据集来源、用户偏好等等.对于文本信息挖掘,其第一步便是进行分词.对于英文,其天然有空格隔开,可以按照空格分词.而对于中文则需要使用相应的算法来进行分词,可以使用现成的分词工具jieba等.由于本实验采用基于OpenML的数据集,其文本描述信息英文直接分词便可,但需要处理无用的介词,如on等,将其筛选掉,减少无用信息.
第二步便是特征工程.在这一步,将分词后的文本数据转换为特征向量.为了从文本数据中选出重要的特征,有以下几种方式:计数向量作为特征,TF-IDF向量作为特征,词嵌入作为特征,基于文本NLP的特征,主题模型作为特征等等.
本文推荐采用TF-IDF向量[13]或NLP[14].TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文件频率)是一种常用于资讯检索与资讯探勘的加权技术.TF-IDF采用统计方法,用以表示字词在文件集中的一份文件的重要程度,当该字词在本文件出现频率越高,同时在整个文件集中出现频率越低,该字词就越加重要,越能代表该文件.即TF-IDF与一个词语在一篇文章中出现次数成正相关,与在所有文章中出现次数成负相关.
其中,TF(term frequency,词频)指的是某一个给定的词语在给定的该文件中出现的频率.IDF(inverse document frequency,逆向文件频率)指的是如果包含词条t的文件总数越少,IDF越大,说明词条具有很好的类别区分能力.其公式可表示如下:
(7)
(8)
TF-IDF=TF*IDF
(9)
并且,由于一般分词后词语数量较多,如果取所有词语进行TF-IDF向量计算,则一是特征值过多,后面协同过滤计算也较慢;二是特征过于稀疏,故一般取TF-IDF值前M个词语进行代表该文本的TF-IDF值.
5.4 训练模型类型分类器
利用之前创建的数据集数据和文本特征可以训练一个分类器,用来判断数据集属于哪种类型的问题.常用的方法有SVM[15-18],KNN,LLSF,NNet等.其中,参考复旦大学自然语言处理实验室使用不同分类算法对基准语料进行测试的结果.这一基准预料共有9804篇训练文档,9833篇测试文档,并分为20类.在经过预处理之后,各个分类方法的性能指标如表1所示.
其中F1测度是综合了召回率与准确率的指标,当两个值都比较大的时候,对应的F1测度才会比较大,因此F1测度比单一的召回率或准确率更加具有代表性,更能体现性能的好坏.由比较结果不难看出,用SVM算法来进行分类器的训练能取得较好的结果.
表1 复旦大学分类算法性能
Table 1 Fudan University classification algorithm performance
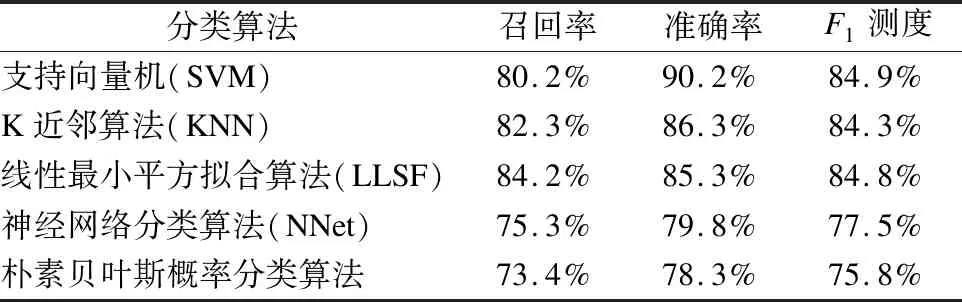
分类算法召回率准确率F1测度支持向量机(SVM)80.2%90.2%84.9%K近邻算法(KNN)82.3%86.3%84.3%线性最小平方拟合算法(LLSF)84.2%85.3%84.8%神经网络分类算法(NNet)75.3%79.8%77.5%朴素贝叶斯概率分类算法73.4%78.3%75.8%
SVM 算法有很坚实的理论基础,SVM 算法的本质是解决一个二次规划问题(Quadruple Programming),用其进行文本分类效果很好,是最好的分类器之一.同时SVM算法可以使用核函数将原始的样本空间向高维空间进行变换,进而能够解决原始样本线性不可分的问题.
通过SVM训练特征为TF-IDF向量的文本,预测数据集所属的模型类型,一般有分类、回归、聚类、子集划分等几种模型类型.
5.5 协同过滤模型推荐
通过利用以上的文本分析所得的数据集所属模型类型,TF-IDF文本特征向量,数据集特征值进行协同过滤得到推荐模型.即先利用TF-IDF向量和数据集特征值进行协同过滤[19-22],然后得到数据集集合中与该数据集的相似矩阵,然后判断其数据集的最佳模型是否属于由SVM所得的模型类型,然后得到相似性最高的Top k个数据集的最佳模型.
5.6 算法实例
对OpenML上数据集anneal(id=2)进行验证并进行模型推荐.对其数据集数据特征提取,可得到如表2所示.
表2 数据集数据特征
Table 2 Feature of data set

数据集名称Credit-g实例数目 898属性数目 39数字属性数目6文本属性数目33… …
对其文本描述信息进行特征提取,转化为TF-IDF向量,如表3所示.
表3 文本TF-IDF向量
Table 3 Text TF-IDF vector
单词坐标TF-IDF值(0,2340)0.0804(0,869)0.1040(0,745)0.088(0,2326)0.2317……
然后通过代入SVM分类器,得到模型类型为有监督分类(Supervised Classification).
最后,利用欧氏距离处理TF-IDF向量,利用余弦相似度处理数据集数据特征,协同过滤得到推荐模型Top1为:weka.J48(1).Top5为:weka.J48(1),weka.SMO_RBFKernel,weka.ZeroR(1),weka.RandomForest(1),weka.weka.NaiveBayes(1).而通过分析任务运行信息得出的定义最佳模型为:weka.J48(1),故通过模型推荐结果符合实际情况.
6 实验结果
6.1 实验数据平台介绍
OpenML是一个开放,协作,自动化的数据分析、机器学习平台.其主要由数据集、任务、模型、运行情况构成.
数据集,即用户所需进行数据分析工作上传的数据集合,它们是由许多实例构成,通常以表格形式呈现.
任务由一个数据集和一个数据分析任务组成,如分类或聚类以及评估方法.对于监督任务,这也指数据中的目标所代表的列.
模型指从特定的库或框架(如Weka,mlr或scikit-learn)中识别特定的机器学习算法构成的工作流流程.
运行是特定的流程,即模型和具有特定的参数设置,适用于特定的任务.
用户在OpenML上面上传数据集,对数据集创建任务,构建模型,挑选模型在任务上运行.在OpenML上共有2万左右用户上传的数据集,对于这些数据集用户创建了6万8千左右的数据分析任务,构建了约6千个左右模型,在这些任务(数据集)上共运行了9百万次模型.实验通过API接口获取这些数据,对模型和运行信息分析,得到对应数据集的最佳模型,并将全部数据集分为训练数据集和测试数据集.接着对数据集数据信息和数据集文本描述信息进行特征提取,模型分类,模型推荐.
6.2 文本特征提取方法比较
首先,过滤运行次数不足100的数据集,然后对于公式(1)中α,β各取0.5,然后对于1814个数据集进行上述实验,对比实验各种不同的文本特征提取方法,得到结果为表4.
表4 文本特征提取方法比较
Table 4 Comparison of text feature extraction methods
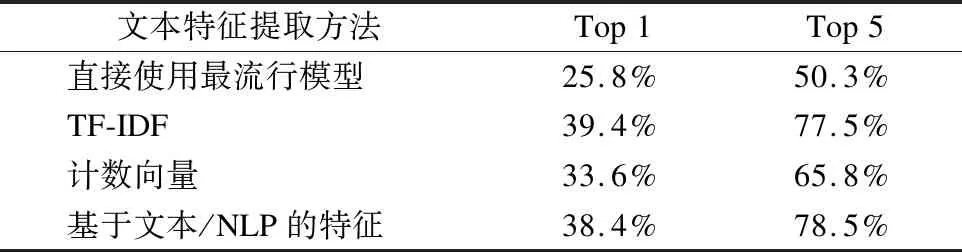
文本特征提取方法Top1Top5直接使用最流行模型25.8%50.3%TF-IDF39.4%77.5%计数向量33.6%65.8%基于文本/NLP的特征38.4%78.5%
由上述表格可以看到,在利用数据集特征和文本描述信息计算数据集相似性以推荐模型时,不同文本特征提取方法对结果的影响.
对比直接使用最流行模型,即使用人数最多的模型进行推荐,可以看到还是能取得不错的效果.对于使用最流行的一个模型进行推荐,其准确率可以达到25.8%,使用最流行的5个模型进行推荐,其准确率可以达到50%左右.当然,随着数据集和模型数量的增长,该准确率也会降低.
而当使用上述算法进行构建、推荐时,可以看到使用TF-IDF和NLP进行文本特征表示效果最好,同时也能较为明显的提升了模型推荐的准确率.对比计数向量,TF-IDF向量考虑到了逆文档频率,更加能够体现出不同文本信息之间的区别.而NLP也通过构建语言模型,提取特征更加丰富准确.而从效率方便性来看,TF-IDF特征向量要更加简便.
6.3 相似性距离计算方法对比
其次,当令α,β各取0.5,文本特征提取方法使用TF-IDF特征向量时,对比不同相似性距离计算方法如表5所示.
表5 相似性距离计算方法对比
Table 5 Comparison of similarity distance calculation methods

数据集特征 文本描述 准确率(Top5)欧式距离欧式距离66.1%欧式距离余弦相似度67.0%余弦相似度余弦相似度76.8%余弦相似度欧式距离77.5%
因为皮尔逊相关系数和余弦相似度效果类似,同时皮尔逊相关系数值区间为[-1,1]要将其转换,并和欧氏距离等进行合并比较麻烦,故此处不将皮尔逊相关系数进行比较.
结果如表5所示,分析可得,对于数据集特征,使用余弦相似性进行计算明显要比欧氏距离要好.分析其原因应该是因为数据集数字特征之间量级相差可能较大,用欧式距离进行计算较难以准确算出相似性,而余弦相似性在处理量级相差较大的特征时明显比欧式距离好.对于文本描述信息,其使用余弦相似度和欧式距离进行计算差别不大,因为在使用TF-IDF特征向量进行文本特征表示后,其值都为[0,1]之间,故两者并无太大区别.
6.4 模型分类影响
在处理文本描述信息中,我们先将其利用SVM多进行文本多分类,得到数据集所属的模型类型,然后利用此信息对协同过滤得到的模型进行过滤.对于模型分类,其准确率为89.7%.
而当令α,β各取0.5,文本特征提取方法使用TF-IDF特征向量,数据集特征距离计算方法使用余弦相似度,文本描述使用欧式距离计算时,其对比结果如表6所示.
表6 模型分类准确率影响
Table 6 Model classification accuracy rate impact

是否分类准确率(Top5)SVM分类得到模型类型77.5%无分类68.9%
由表6可以看出,利用SVM算法先对文本描述信息进行分类,得到数据集所属模型类型,对得到准确的模型有较为明显的提升.
6.5 最佳模型计算方法对比
最后,当文本特征提取方法使用TF-IDF特征向量,数据集特征距离计算方法使用余弦相似度,文本描述使用欧式距离计算,并使用SVM分类得到模型类型,α,β取不同值对模型推荐的准确率影响如表7所示.
由表7可以看出,当取最佳模型只考虑模型运行时准确率时,取得的最佳模型在算法模型推荐时效果最差.当取最佳模型只考虑流行度或者说模型运行次数时,取得的最佳模型在算法模型推荐时效果最好.
其原因是因为当只考虑模型运行准确率时,各个数据集的模型运行的准确率可能有偶然性,同时最佳模型的种类也会更多,各个数据集上最佳模型相似性也会更低.反之,当只考虑流行程度时,最佳模型的种类将会大大减少,模型推荐的准确率相对而言会更高,但这并不代表模型推荐的效果会更好.因为对于用户而言,不仅仅考虑模型的流行度,模型的准确率也是重要的考虑因素,故需对其取一个平衡,均衡考虑.
表7 最佳模型计算方法对比
Table 7 Comparison of the best model calculation methods

模型准确率运行次数准确率(Top5)α=1.0β=063.6%α=0β=1.081.7%α=0.5β=0.577.5%
7 结论与展望
本文针对当前流行的数据分析服务流程提出了基于数据集的模型推荐方法,通过对数据集数据和文本描述信息特征的提取,使用SVM分类对其进行模型类型的预测,再综合协同过滤算法对其进行模型推荐.
本文针对数据集数据特征和文本描述信息,实验了多种方法,在其之上定义了最佳模型的计算方法,实验了三种文本特征表示方法:计数向量,TF-IDF,NLP方法,并在其上验证了多种距离计算方法对模型推荐效果的影响.
实验结果可以发现,通过数据集数据特征和文本描述信息能较好进行模型推荐,可以大大节省用户建模时间,让模型可以充分被重复利用.
当然,实验也存在一些不足之处,和接下来进一步优化目标:
1)可将用户的偏好从文本描述信息中抽取出来,或者通过标注训练的方法从文本描述信息中得到用户偏好.
2)可以进一步分析数据集规模和模型推荐准确性的关系.
3)利用TF-IDF向量进行计算文本描述信息相似性,对于每个新的数据集每次都要重新开头计算.可以考虑使用其他文本特征表示方法在不失准确率的情况下提高效率.
