基于SSD和TensorFlow的图像识别与定位算法
2019-07-08姜华孙勇
姜华 孙勇

摘 要: 随着机器视觉技术发展,对识别速度、准确率和项目开发周期等方面都提出了更高的要求。人工智能无疑是较好的解决方式,而以往从底层编程搭建深度学习框架在技术和项目进度上都很难满足要求。为了满足图像识别要求,选择专用的图像处理服务器进行训练与识别,并对其主要部件进行选型。对SSD模型结构进行了分析,根据各层次结构计算了一次训练与前向运算过程中所需计算的参数及内存要求。通过开源的深度学习框架TensorFLow、SSD识别模型,在Python环境下设计图像格式转换、图像识别和定位程序。并在VOT2016标准数据集中进行测试。测试结果显示,在速度和识别成功率上都符合预期要求。
关键词: 机器视觉; 深度学习; TensorFLow; SSD; 定位
中图分类号:TP391.4 文献标志码:A 文章编号:1006-8228(2019)06-71-05
Abstract: With the development of machine vision technology, higher requirements are put forward for recognition speed, accuracy and project development cycle. Artificial intelligence is undoubtedly a better solution, but in the past, building a deep learning framework from the bottom programming is difficult to meet the technical and project progress requirements. In order to meet the requirements of image recognition, a special image processing server is selected for training and recognition, and its main components are selected. The structure of SSD model is analyzed, and the parameters and memory requirements for training and forward operation are calculated according to the hierarchical structure. Using SSD recognition model of machine learning framework TensorFLow, the program of image format conversion, image recognition and localization is designed with Python. It is tested on VOT 2016 standard data set; the test results show that the expected requirements in terms of speed and recognition success rate are achieved.
Key words: machine vision; deep learning; TensorFLow; location
0 引言
主流圖像识别和定位的方法大概可以两类,其一是基于滤波的图像特征提取,常用的滤波算法有小波变换[1],傅里叶变换[2],加博变换[3]等;其二是基于人工智能类的学习算法,通过对已有的图像特征学习来完成图像识别,常用算法有SVM(支持向量机)[4]和深度学习[5-6]。
从实现效果上来看,针对不同的识别领域,两大方法会呈现不同的识别准确率。一般而言,基于滤波的图像识别算法更适合于识别物体特征单一和识别背景相对简单的环境,如指定环境的某一工件识别等。而人工智能类的识别算法,更适用于识别物品可能发生一定变化,识别背景相对复杂的情况,如人脸识别,人的姿势、表情识别等。
TensorFlow是众多人工智能框架中最具代表性的一个,本文以此为图像识别深度学习框架,进行指定图像的识别与定位研究。
1 深度学习基础
1.1 卷积神经网络的组成
卷积神经网络属于神经网络的一种,是深度学习最常用的网络之一,已广泛地应用于机器视觉、文字处理和数值分析等领域。而深度学习是机器学习的最重要的一个分支,在很多领域已经达到了原有机器学习未能实现的高度。因此,卷积神经网络可以看作当前主流人工智能实现方式的一个代表[7]。
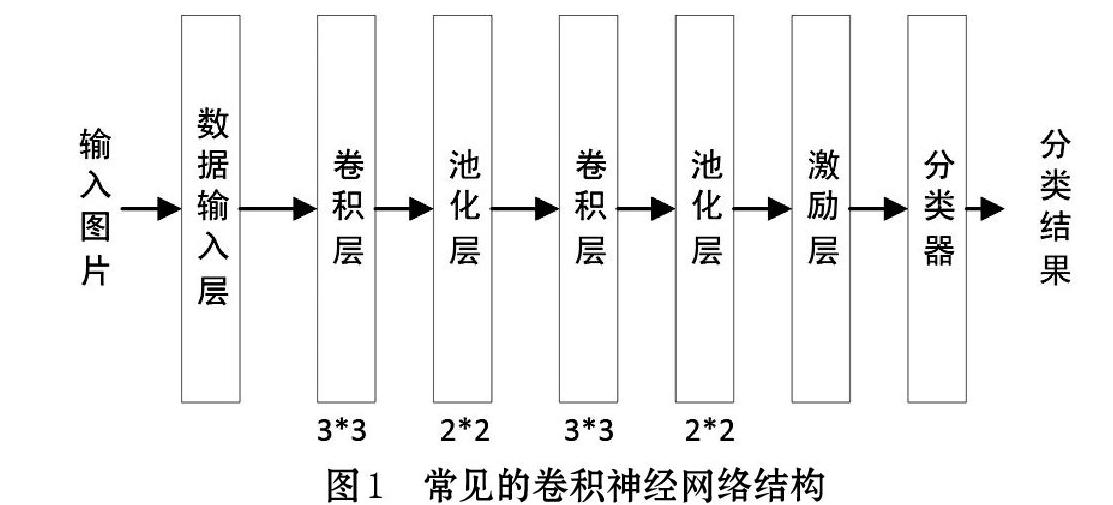
应用于机器视觉方面的卷积神经网络一般包括:数据输入、卷积层、池化层、激励层、全连接层等,具体如图1所示。
其中,数据输入层除了接收和向下一层级传输图片外,但需要进行去均值、归一化以及降维等工作。卷积层是把输入图片在一定步长和一定尺寸的卷积核进行卷积运算,而后得出的图片作为输出,步长就是卷积核在原图片上滑动间隔的步距,卷积核的尺寸一般可以选3*3或者5*5,卷积层中卷积核的数量与卷积后输出的图片数量相等。池化层往往在卷积层的后面,有时和卷积层一并被当作同一个层级。它通过最大池化运算或者平均池化运算压缩图片数据。
一般采用2*2的最大池化压缩方法,每次池化后数据量仅为原有的1/4。激励层是把之前各层运算结构转换成标准化的非线性映射,常见的激励函数如Sigmoid、ReLU和Tanh等。卷积神经网络有时也会包含全连接层,经常出现在网络的末端。而目前的卷积神经网络往往没有全连接层,很可能是以一个1*1的卷积层代替。分类层一般采用SoftMax分类器,识别出图片中所包含物体的类别。
1.2 卷积神经网络的特点
相对于传统的神经网络,卷积神经网络具有如下几个特点。
⑴ 随机激活与关断部分神经元
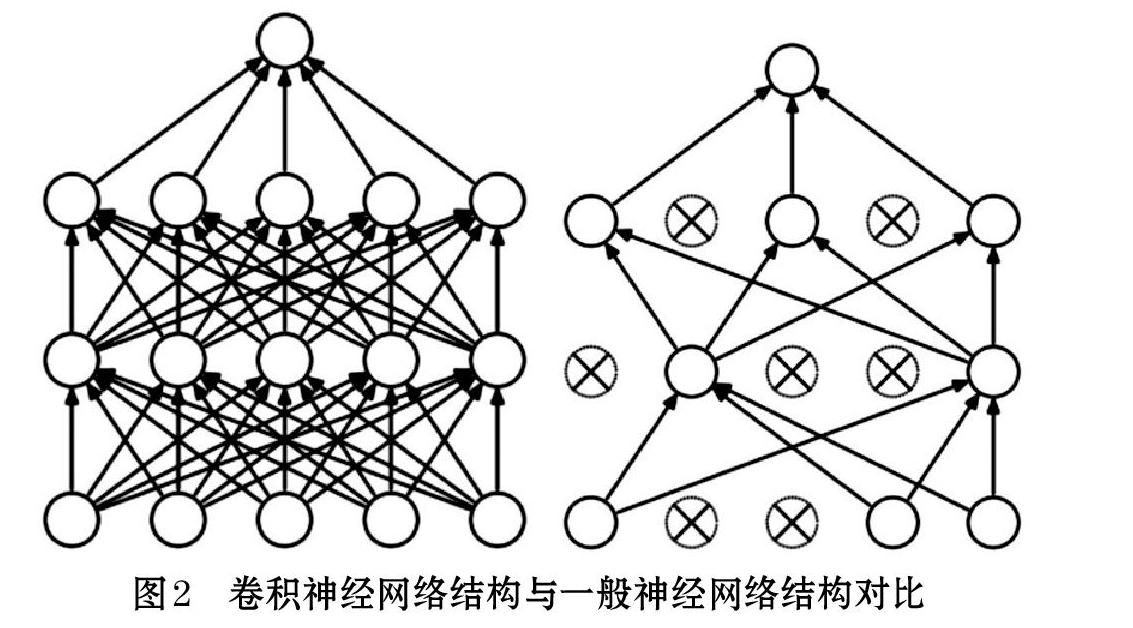
传统的神经网络在学习和训练的过程中,经常会出现过拟合现象,也就是由于过于详细的关注每个样本的细节而忽略了物体原有的变化过滤,过多学习了噪声等干扰。而卷积神经网络采用随机激活和关断部分神经元的方法,使得神经网络在训练的过程中无需详细的保存图片的每条细节,泛化部分特点,反而能够更容易抓住物品的特征进行识别。具体地结构变化如图2所示,左图为一般神经网络,右图为卷积神经网络。
⑵ 参数共享机制
卷积神经网络中,每层之间或者说每个神经元之间的权重是不变的。也就是说连接同一个图片中的神经元,假定其为3*3矩阵,那么卷积神经网络中这个9个数在前向运算中是不变的。
从神经或者生物学角度来讲,这使得每个神经元所关注的特征是唯一的。这也使得卷积神经网络的学习训练所需的计算量变得可以实现,例如,以AlexNet框架的网络深度为例,传统神经网络和卷积神经网络在学习训练的过程中需要计算的权重参数由1亿降至3.5万。
⑶ 交叉熵损失函数计算
卷积神经网络的训练和运行整体上来说采用反向传播和链式法则。而找出之前构建模型参数中的错误就需要交叉熵计算了。交叉熵是通过概率论的方法,把模型得出属于某一被识别出的物品的概率进行归一化,以便了解与真实结果的差异。
交叉熵计算如公式⑴,其中xi为图片样本中的第i张图片矩阵,fyi表示在W激励作用下的运算结果,Li为交叉熵结构。
而计算机程序计算时,往往会采用公式⑵
1.3 SSD计算模型
常规的卷积神经网络的确可以对目标图像是否包含指定物体,但无法实现物品对图像中的位置定位。若图像中物体位置定位只能通过在图片中进行一定规律的矩形分割识别搜索,例如把原有图像分成2000个,这样即便是目前最先进的服务器也较难完成,因为工作量增加了近2000倍。
SSD的结构如图3所示,它的矩形识别框都算出一个各自的检测值,与以往运算模型不同的有两点。其一是常规的得出每个矩形识别框和图片背景的归类评分,其二以矩形识别框的中心X、Y坐标,高度和宽度,相当于建立起这个四个参数与检测值的函数。
矩形识别框的匹配原则分为两个步骤,其一是在被识别图片中的真实目标,都找到一个对应物体准确度最高的矩形识别框,其二是首轮未匹配到的对大于一定阈值的矩形识别框进行第二次选择匹配。
2 图像识别平台的搭建
本文操作系统为Windows 10,Windows系列是TensorFlow在支持linux和MAC之后的第三个操作系统。软件开发语言选择更适合于数值计算,而且与TensorFlow平台使用资料较为丰富的Python。为了安装TensorFlow方便,选择Python插件工具包Anaconda4.3,在此基础上安装TensorFlow1.12,并把Python版本降至3.5,以便支持TensorFlow1.12。Anaconda安装后,Python的编译环境为Spyder3.2.3。
为了缩短训练时间,图像处理选择支持GPU运算的服务器。服务器的主要配置如表1所示。为了追求深度学习的运算速度,显卡为四个英伟达的Titan XP并联。
单张图片进行前向运算所需要内存约为28*4=112M,单张图片需要确认参数约为21M个。如果与VGG相比的话,相对比VGG的224*224像素图像的93M和138M比,无疑是节约了很多内存空间和运算时间。而且在识别的功能性上,也由识别图像内是否包含物體变成物体定位。计算内存占用量和参数计算有助于了解训练和前向运算时所需要的服务器显卡资源。训练是需要一次获取若干张图片的,例如32张,那么需要的内存就至少是一张的32倍。
计算的层次顺序不完全按照SSD进行排序的,由于它前面与VGG一致,所以层次的计算顺序是先是VGG部分,而后是SSD增加部分。
4 基于SSD模型的程序设计
4.1 卷积层参数训练
参数训练部分主要代码如下:
4.2 在已有参数基础上进行微调
为了更快的训练卷积神经网络的参数,也可以下载一些已经训练好的数据,并在此基础上进行微调得到这类图片的训练结果。例如可以在GitHub中下载TensorFlow-SSD数据包,保存参数的文件名为:ssd_300_vgg.ckpt.data-00000-of-00001,以此作为参数基础。微调的主要部分程序如下所示:
5 实验结果与对比
5.1 实验结果
在VOT2016中选择蝴蝶作为实验对象,这类图片共计150张,取后130张作为训练样本,前20张作为测试样本。通过变换把原图像转换到300*300像素再转换到TF数据集格式,每次迭代训练16张图片,反复训练500次后测试出识别结果。其中,训练速度平均在8张图片/秒左右。实验结果如图4所示。
5.2 实验过程数据
分别采用在新建模型重新训练和在下载数据中进行微调做测试对比,对比结果如图5所示。可见微调的实际测试中收敛速度更快。
6 结束语
随着TensorFlow的开源发布,基于卷积神经网络的图像识别资源已经逐渐向此方向倾斜。例如SSD最初是在Caffe框架下设计的,目前不仅可以较为方便的下载TensorFlow的学习模型框架,而且也有越来越多的人在使用它进行研究和应用。
本文采用SSD和TensorFlow相结合,在图像处理服务器中对VOT2016的蝴蝶样本进行训练和测试,在训练速度和识别成功率在都取得了较好的结果。
参考文献(References):
[1] 石岩.基于二维不可分形态小波变换的多光谱图像全色锐化方法[J].北京交通大学学报,2018.42(5):116-122
[2] 朗俊,付香雪,郭盼.分数傅里叶变换域的彩色图像非对称光学压缩加密[J].光电工程,2018.45(6):124-133
[3] 姚琼,徐翔,邹昆.基于3D Gabor多视图主动学习的高光谱图像分类[J].计算机工程与应用,2018.54(22):197-204
[4] 李红丽,许春香,马耀锋.基于多核学习SVM的图像分类识别算法[J].计算机科学与应用,2018.41(6):50-52
[5] 李胜旺,韩倩.基于深度学习的图像处理技术[J].数字技术与应用,2018.36(9):65-66
[6] 李永刚,王朝晖,万晓依等.基于深度残差双单向DLSTM的时空一致视频事件识别[J].计算机学报,2018.41(12):2853-2864
[7] 刘忠利,陈光,单志勇等.基于深度学习的脊柱 CT 图像分割[J].计算机应用与软件,2018.35(10):200-204
[8] LIU W,ANGUELOV D, ERHAN D, et al.SSD: single shot multi-box detector,2016[C].Berlin: ECCV,2016:21-37
[9] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition,2015[C]. Montreal :NIPS.(2015)
收稿日期:2019-02-25
*基金项目:浙江省2018年度重点研发计划项目(2018C01111)
作者简介:姜华(1976-),男,浙江杭州人,硕士,高级工程师,主要研究方向:图像识别与大数据。
