基于EEMD数据预处理和DNN的语音增强算法研究
2019-07-05陈建明梁志成
陈建明,梁志成
(陆军装甲兵学院 信息通信系, 北京 100072)
语音增强是语音信号处理领域的一个重要分支,主要目标是从带噪声的语音信号中提取尽可能纯净的原始语音信号,提高语音信号的质量、清晰度和可懂度。语音增强算法主要分为两大类:有监督算法和无监督算法。比较典型的无监督算法有:谱减法、自适应滤波法、小波变换法、EEMD(Ensemble Empirical Mode Decomposition)法等[1],基本原理是通过先估计噪声的谱信息,然后从带噪语谱中将估计的噪声谱减去以获得干净的语音谱。其优点是运算量比较小,可实现实时语音增强,便于实际应用。缺点是各个无监督算法都会不同程度的产生“音乐噪声”[2]。其中谱减法中的“音乐噪声”最明显;自适应滤波法主要是利用滤波器估计发音器官的声道参数和激励源的参数,但在信噪比较低的情况下,难以估计出正确的参数,会产生严重的语音失真;小波法可以灵活选择小波基,由于语音信号的时变性,如何有效地选择小波基是一大难点[3]。EEMD法是由于剔除不同频率分量造成高频语音损失,语音失真的问题在低信噪比下更加严重。再者,传统无监督算法都基于平稳噪声的假设,对于非平稳噪声,尤其是极端非平稳噪声(比如机关枪射击声)难以起到有效的增强作用。最后,传统的无监督算法中,存在一些为了计算而采取的假设,例如噪声是加性的、噪声和语音互相独立,这些假设和近似,对传统语音增强算法性能的进一步提高形成制约[4]。就目前有关语音增强算法的研究来说,无监督算法的研究已趋于成熟,由于算法原理本身的局限性,无法满足非线性、非平稳语音信号的去噪要求,也不可能有通用的去噪算法。有监督算法主要分为:浅层模型和深层模型。浅层模型有浅层神经网络、隐马尔科夫模型 HMM(Hidden Markov Model)和非负矩阵分解NMF(Nonnegative Matrix Factorization)等。基于HMM和NMF的语音增强算法,都是基于噪声和语音之间是独立的假设,限制了语音增强性能的上限;对于浅层神经网络来说,网络层数少,隐含层节点数少,无法精确地学习到带噪语音和纯净语音间复杂的非线性关系,而且浅层神经网络缺乏有效的初始化方法,随机初始化造成每次训练结果不稳定,容易陷入局部最优解[5]。深层模型起于2006年Hinton等人提出深度信念网络[6](DBN),使用受限玻尔兹曼机(RBM)逐层训练神经网络的初始化权值[7],使得深度神经网络(DNN)开始受到国内外研究者的广泛关注,并在图像、语音、视频和自然语言处理等领域取得巨大进步。DNN应用于语音增强是近几年研究的热点,通过网络学习带噪语音和纯净语音之间复杂的非线性映射关系,并不断调整网络参数以找到最优的函数关系,从而去除噪声。文献[7]提出了一种基于理想二元时频掩蔽估计的语音增强方法,该方法把语音增强问题转化成用DNN估计理想二元时频掩蔽估计的分类问题,该方法对于低信噪比非平稳语音增强可得到高可懂度的增强语音,语音音质损失严重。文献[8]提出了一种基于DNN的最小均方误差回归拟合语音增强方案,该方法基于对数功率谱最小均方误差准则,通过DNN对带噪语音和干净语音间的复杂关系进行回归拟合建模。文献[9]提出了采用一种堆叠式去噪自编码器来进行语音增强的方法。目前,监督性语音分离的框架基本成熟,即利用深度模型学习一个从带噪特征到分离目标的映射函数,很难在框架层面进行重大的改进。DNN用于语音增强处理研究主要集中在如何进一步提升对不包含在训练集噪声环境下的语音增强性能,即提升系统的泛化能力;研究语音增强 DNN模型在噪声环境的自适应问题和进一步将深度学习方法应用到多通道语音增强中等[5]。本文针对典型装甲车辆运动噪声背景下语音传输质量差问题,采用基于EEMD预处理和DNN结合的方法,研究DNN模型在该噪声环境下的自适应性,达到提高语音质量和可懂度的目的。
1 算法整体框图
本算法分三部分:数据预处理阶段、模型训练阶段和增强处理阶段。算法整体框图如图1。
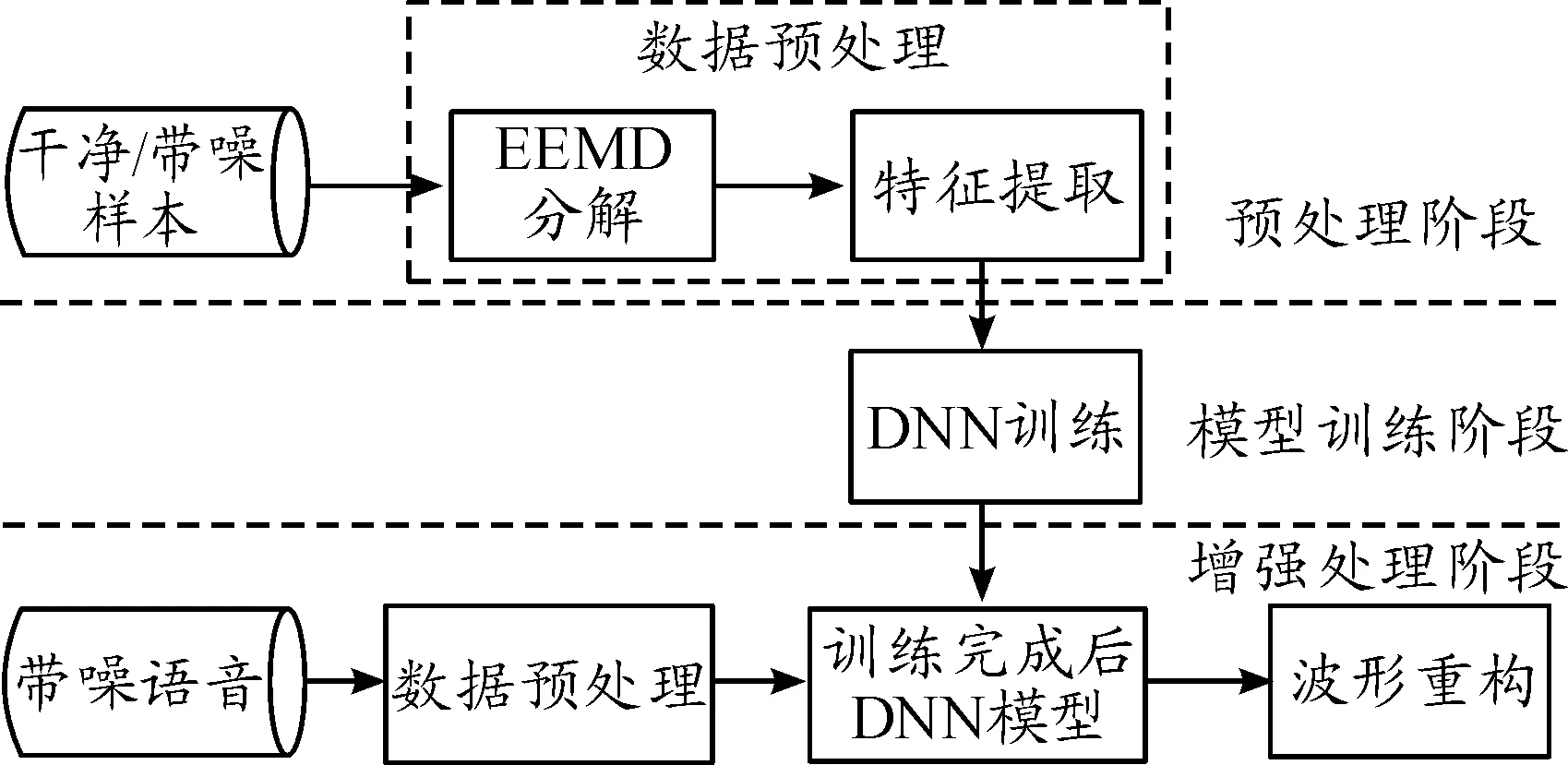
图1 算法整体框图
① 数据预处理阶段。包括两个部分:EEMD分解和特征提取。首先将带噪语音信号和纯净语音信号进行EEMD分解,获得一组频率从高到低的本征模态函数IMF(Intrinsic Mode Function)分量,原一维时域信号分解成多维时域信号,更便于DNN学习带噪语音与纯净语音间的关系。提取时域的信号特征,组成特征向量,输入神经网络中进行训练,网络的训练目标为纯净语音信号的特征。
② 模型训练阶段。经过预处理后,带噪语音和纯净语音分别被分为相对应的特征样本,在训练阶段,将特征样本和对应的训练目标按批次输入到DNN中进行训练,经过信号的正向传播和误差的反向传播,得到最优的网络模型并进行保存。DNN训练模型如图2所示。
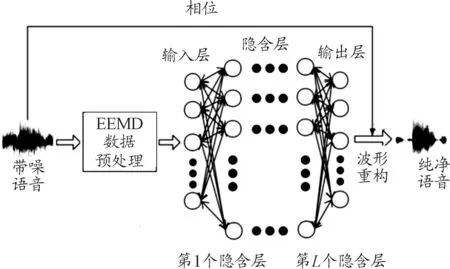
图2 DNN训练模型
③ 增强阶段。增强阶段是对真实带噪语音进行处理。首先将待测语音按照①中步骤完成预处理,得到特征向量。然后输入到②中获得的最优网络模型中进行增强处理,最后将输出的特征向量结合带噪语音的相位一起合成可主观测听的语音波形文件。
2 数据预处理
2.1 EEMD分解
EEMD分解[10]的实质是对信号进行平稳化处理,不借助任何基函数,只需根据信号自身的时间尺度特征进行分解,使整个“筛分”过程具有直接性和自适应性,突出了信号的局部特征,能更直观地观察分析信号,对于非线性、非平稳信号的处理有很大帮助[11]。
选取含有-5 dB装甲车运动噪声的带噪语音“四百米障碍”y(t)进行EEMD分解,波形图如图3所示,分解后各IMF分量如图4所示。从图4可以直观的看到每个IMF分量的时域波形,不同级数的IMF,其包含的信号频率、能量等均不相同。各IMF占原信号的能量比如表1所示,由表1可知信号的能量主要集中在级数较低的IMF中,前7个IMF大约占总能量的85%,其余的只占总能量的15%。能量较低的低频虚假分量对语音分析没有意义,因此在EEMD分解后,本文只保留信号的前7个分量进行分析。
图3 带噪语音“四百米障碍”波形
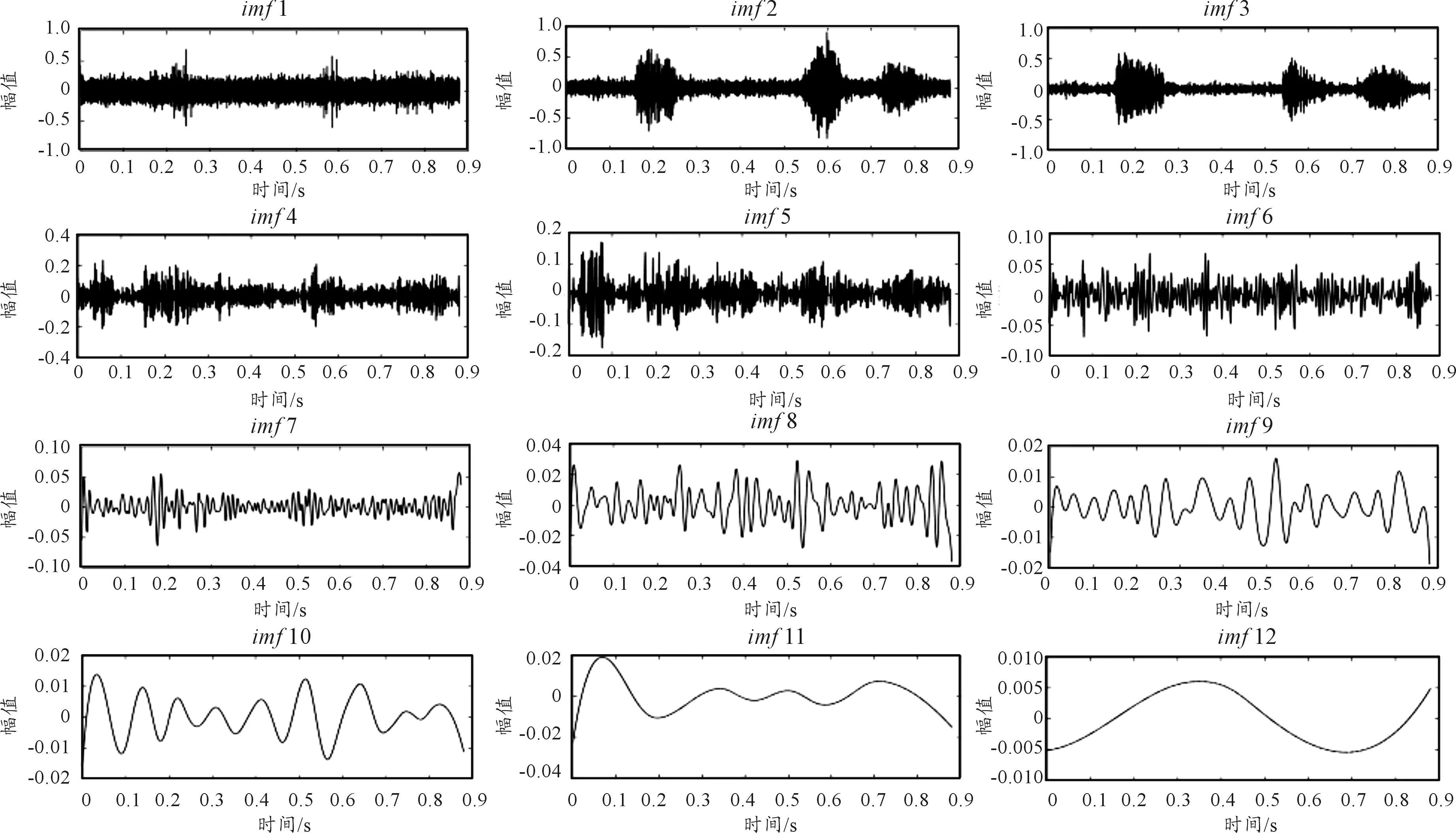
图4 EEMD分解后IMF(1-12)的波形

IMF1IMF2IMF3IMF4IMF5IMF6IMF7IMF8IMF9IMF10IMF11IMF120.090.220.240.100.090.070.050.030.020.020.010.06
2.2 特征提取
步骤如下:
① 经EEMD分解后获得IMF分量。语音信号经EEMD分解后,能初步区分噪声分量和语音分量,这对于DNN来说是非常重要的信息,可以排除许多干扰因素。
② 选择有效的IMF分量,并对各IMF分量分帧。
③ 短时傅立叶变换。对各IMF每一帧信号进行FFT变换,从时域数据变为频域数据。
④ 计算各IMF的谱线能量。
⑤ 计算对数功率谱。对各频点能量取对数。
⑥ 组成子带特征向量。每一帧N个频点的短时能量组成一个子带的特征向量:Pi=[Ei(1),Ei(2),…,Ei(N)]
对所有特征数据进行高斯归一化处理,即所有训练数据的均值归一化为0,方差规整为1。
3 DNN训练
深度神经网络的训练过程由信号的正向传播与误差的反向传播两个部分组成,模型框架如图2所示。信号正向传播与误差反向传播的过程,是循环往复且权值不断修改的过程,也就是网络的训练过程,这个过程一直进行到输出层的输出误差逐步减小到可以接受的范围或者达到预先设定的学习次数为止。
3.1 信号正向传播
正向传播时,样本特征作用于输入层,经隐含层逐层处理之后,传到输出层,具体过程分以下。
DNN训练之前首先要进行初始化。据早期研究[6]可知,DNN的网络初始化对于找到全局最优的结果非常重要,DNN大部分利用受限玻尔兹曼机RBM组成的DBN,通过对比散度算法进行无监督的预训练来对网络进行初始化。最近的研究显示,数据量的增加和Dropout技术[12]的使用,同样能使网络获得较好的性能,因此本文采用随机初始化并利用Dropout来获得全局最优解。
第l个隐含层输出为:
(1)
输出层输出为:
(2)
O=[O1,O2,…,On]
(3)
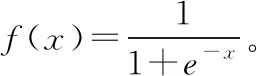
如果输出层未能够得到期望的输出,则转入到误差的反向传播阶段,将输出误差按照某种方式,通过隐含层向输入层返回,并把它“分摊”给各层的所有单元,从而获得各层单元的参考误差,用来修改各单元权值的依据。采用纯净语音和增强后语音对应特征之间的最小均方误差作为损失函数,反向传播算法允许来自损失函数的信息通过网络向后流动,被用于计算梯度,利用小批量随机梯度下降法(Mini-batch gradient descent algorithm)进行学习,从而更新整个DNN的参数。
将网络的实际输出O与期望输出T带入损失函数,计算网络误差e。由于语音增强是一个回归问题,因此选用均方误差MSE(Mean-Square Error)作为损失函数[1]。为了避免模型出现过拟合问题,在损失函数中加入了L2正则化,限制模型的复杂程度。
(4)
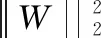
(5)
(6)
式(4)-(6)中,N为样本数;T为期望输出;R(W)为体现模型复杂度的函数;W为网络中所有权重参数;E(W)为网络优化目标函数;λ为模型复杂度损失在总损失中的比例。
3.2 权重更新
首先调整第l隐含层与输出层之间的权重,沿着梯度最快下降的方向调整。然后误差向前传播,对前面各层权重进行调整。
第l个隐含层权重调整为:
(7)
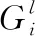
至此,一轮权重调整结束。调整规则归纳为:权重调整量=学习率×局部梯度×上一层输出信号。
4 实验及数据分析
为了检验本算法的有效性,通过DNN模型训练后与语音增强经典算法中的谱减法(算法1)、自适应滤波法(算法2)以及深度神经网络中的基于短时FFT变换的对数功率谱特征提取方法(算法3)进行比较。选择一段语音“四百米障碍”进行分析对比研究,纯净语音波形及语谱图如图5所示,噪声为装甲车运动噪声如图6所示。
4.1 实验参数设置
特征位数:896维(7×128),即IMF分量有效个数为7,每帧为128个点。因而输入输出节点数分别为896。
特殊函数:隐含层激活函数选择ReLU,输出层激活函数选择Sigmoid,损失函数选择MSE,采用随机初始化,训练算法采用小批量随机梯度下降法,采用Dropout对模型进行优化,损失比例设置为0.2,学习率设置为0.01,并按照0.004的差值逐渐减小。
数据源:本文实验纯净语音全部来自于清华大学语音与语言技术中心(CSLT)出版的开放式中文语音数据库,抽取500条纯净语音被用来与装甲车运动噪声相加在一起,相加的信噪比为15 dB、10 dB、5 dB、0 dB和-5 dB,来构建一个多种情况的平行训练数据。另外,从语音数据库里抽取另外100条语音与上述装甲车运动噪声相加构成测试数据集。
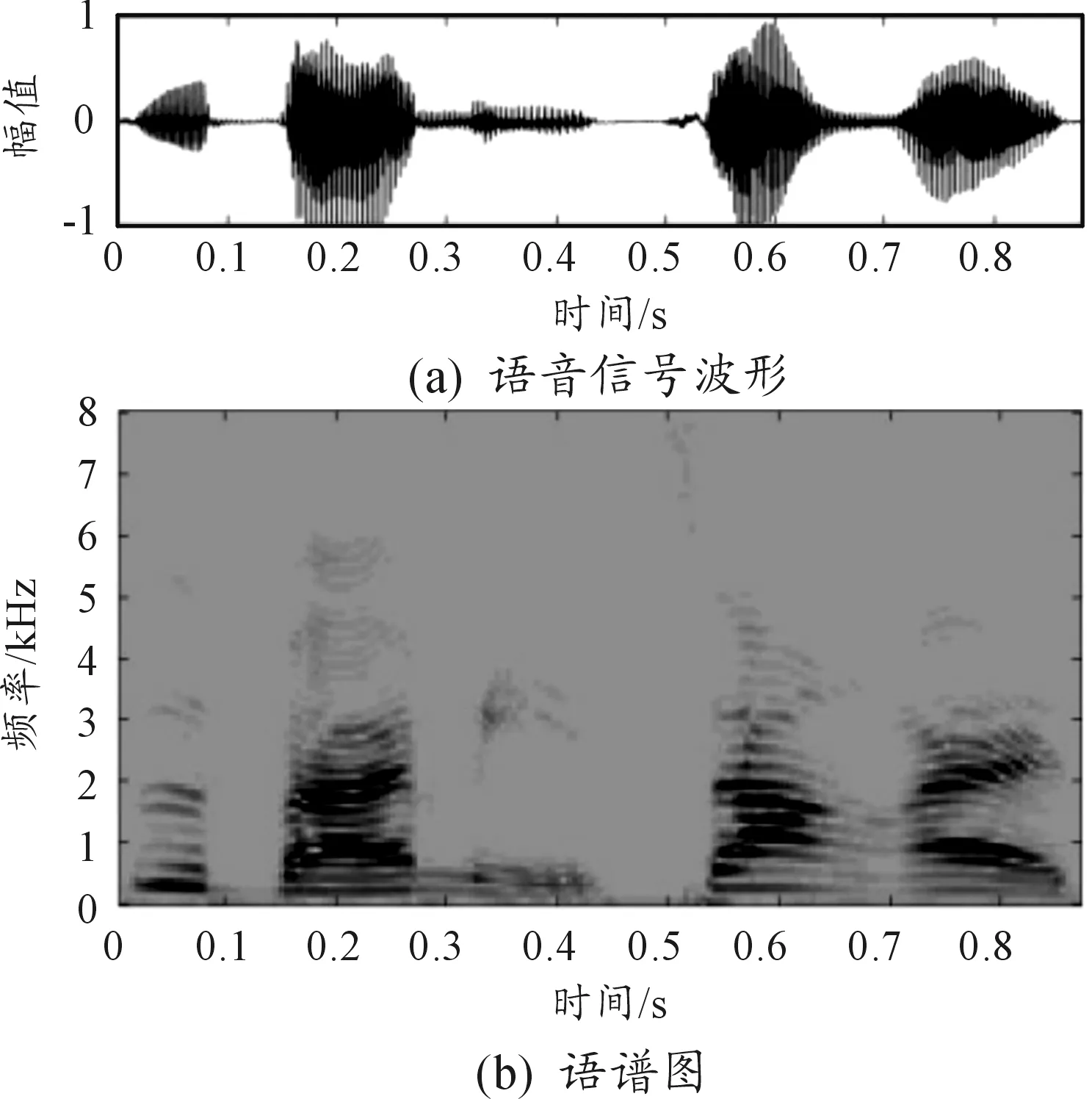
图5 纯净语音
图6 装甲车运动噪声
4.2 DNN隐含层及节点数的确定
一般来说,深度神经网络要求隐含层大于3层、每层节点数大于1 000。首先假定隐含层数为4,实验结果如表2所示,每个隐含层的节点数为1 024时效果较好,隐含层数为5时亦如此,确定隐含层节点数为1 024。然后节点数为1 024时实验数据如表3所示,确定隐含层为4层。
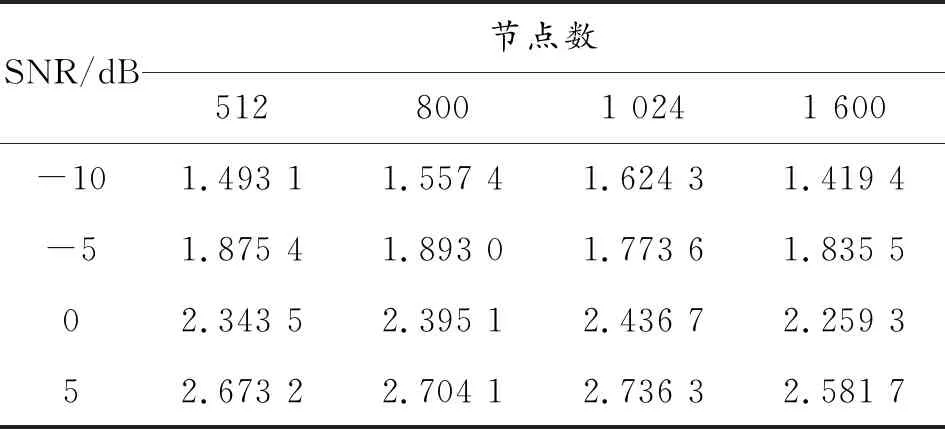
表2 隐含层不同节点数的DNN增强后PESQ
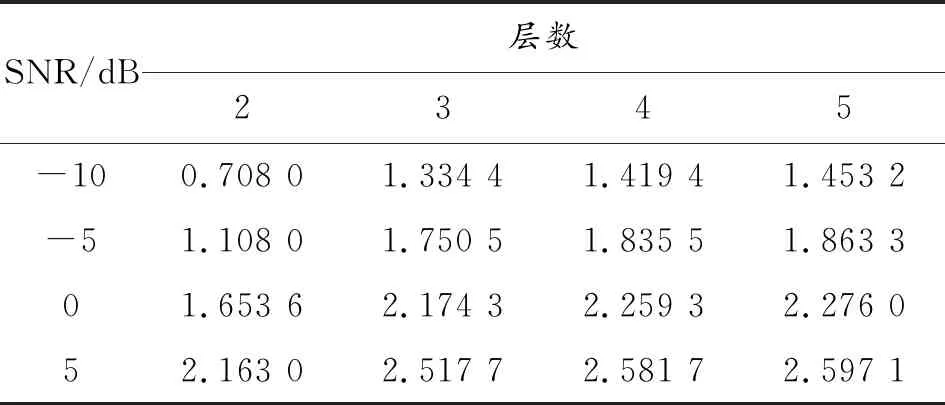
表3 不同隐含层数的DNN增强后PESQ
4.3 实验数据及比较
4.3.1模拟带噪语音下各算法比较结果及分析
选取纯净语音“四百米障碍”和装甲车运动噪声在-5 dB、0 dB和5 dB下混合构成带噪语音信号,检验指标为信噪比SNR、感知语音质量评估PESQ和短时客观可懂度STOI,数据如表4、表5、表6所示。-5 dB(限于篇幅只以-5 dB为例)带噪语音(如图7所示)经各算法增强后得到的波形与语谱图如图8、图9、图10和图11所示。
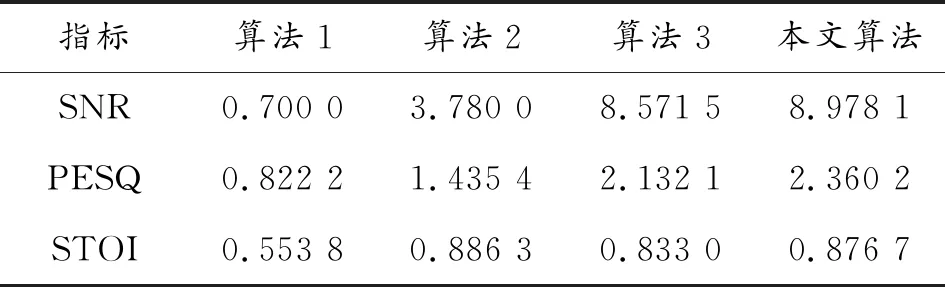
表4 不同算法在-5 dB装甲运动噪增强后的信噪比
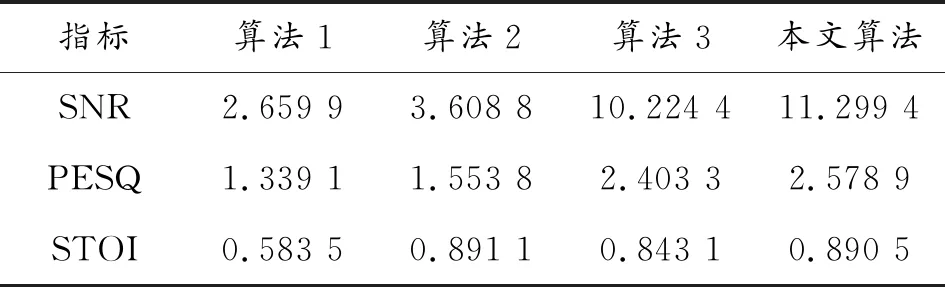
表5 不同算法在0 dB装甲运动噪增强后的信噪比
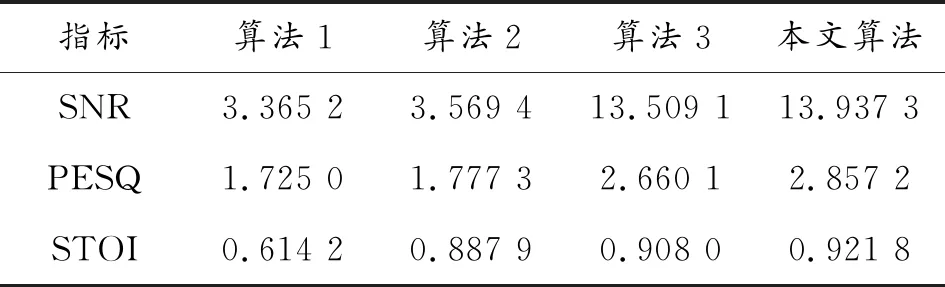
表6 不同算法在5 dB装甲运动噪增强后的信噪比
由表4、表5和表6可看出:算法3和本文算法在语音增强处理后信噪比均提高2倍以上,PESQ和STOI与经典算法比均显著提高,本文算法优势更明显。
比较各算法增强后的语音与纯净语音的波形图可知,在-5 dB噪声环境下,谱减法去除的噪声最多,语音波形幅度较纯净语音有所减小,甚至有的语音波形已经消失不见,且在语音间隙期,新产生了几个小的波形凸起;自适应滤波法去除了大部分噪声,但还有小部分残留噪声,语音波形的幅度没有明显减小;算法3和本文算法很好地滤除了背景噪声,波形更接近于原始纯净语音,去噪效果都强于经典算法。本文算法较算法3的PESQ和STOI值分别提高0.228 1和0.013 8,说明本文算法在可懂度和语音质量方面均有所提高,这是因为信号经EEMD分解后,首先能初步区分噪声分量和语音分量,更能反映信号的时频特性。
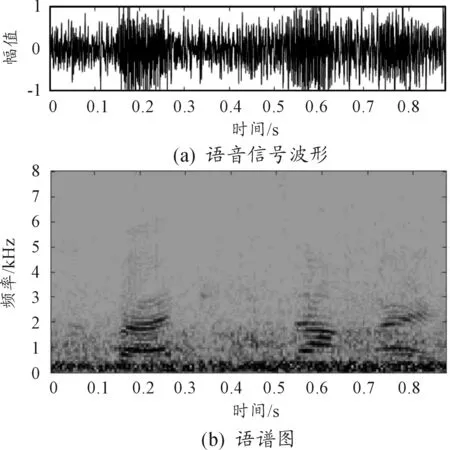
图7 -5 dB合成带噪语音
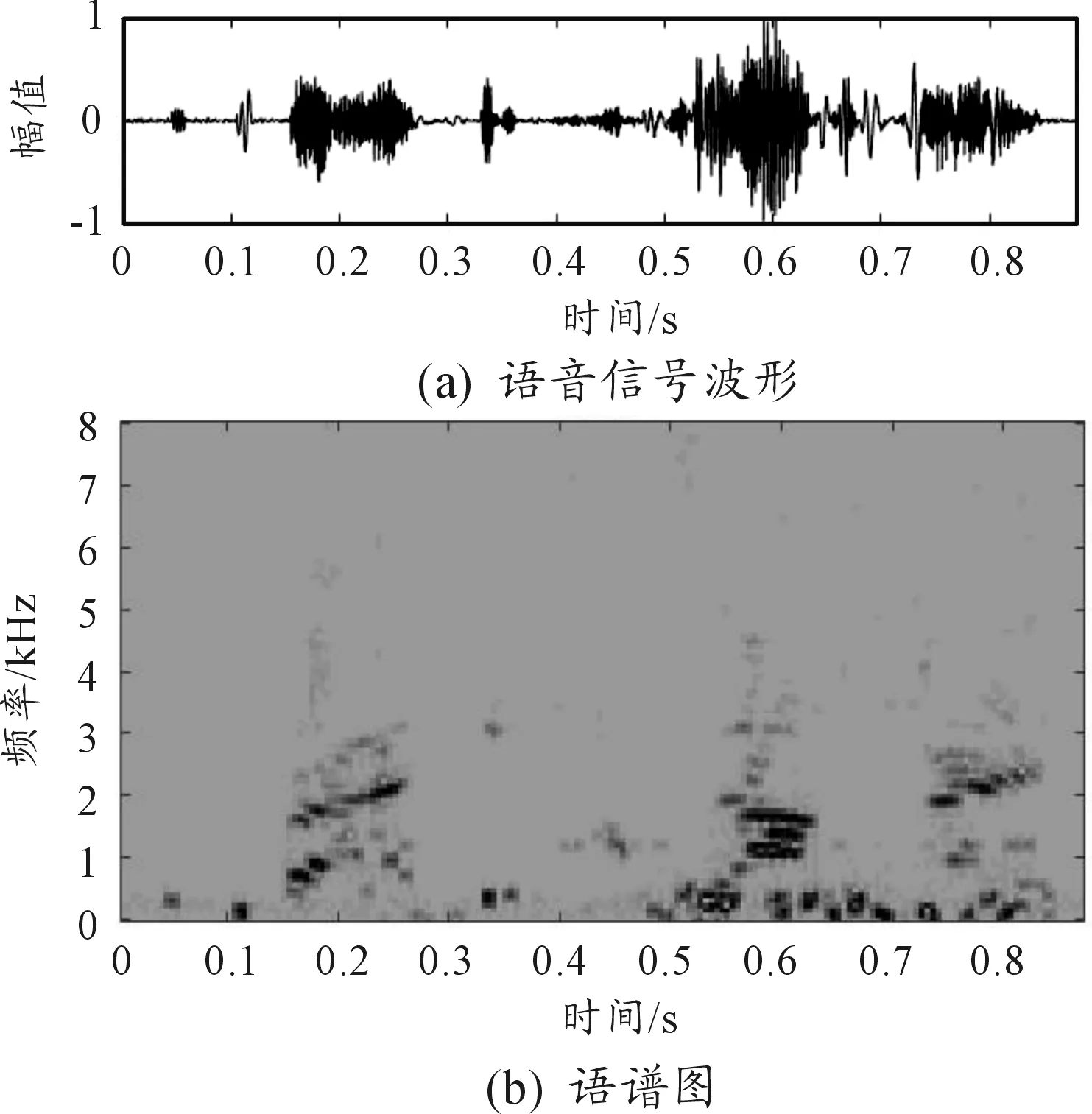
图8 算法1结果
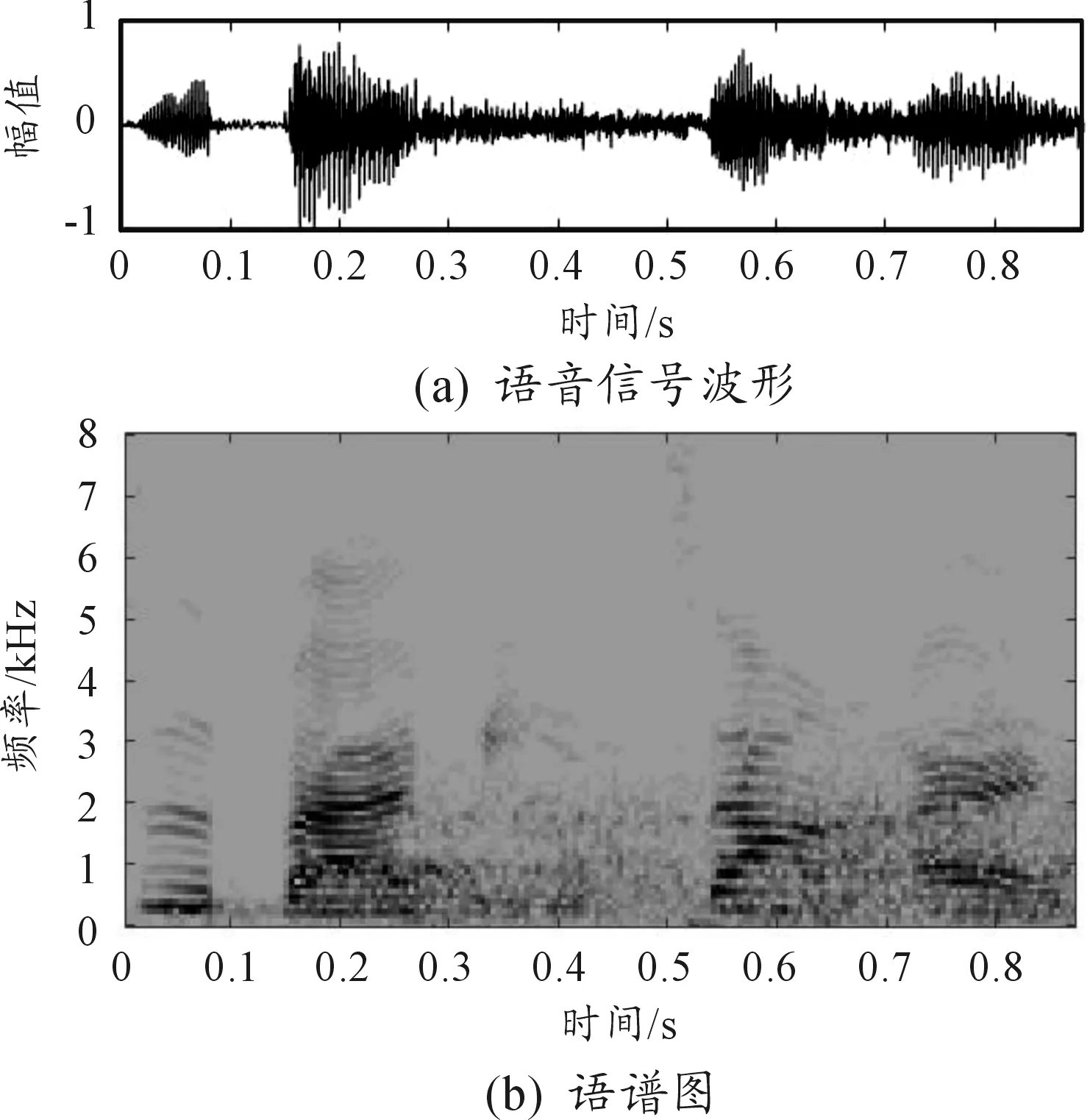
图9 算法2结果
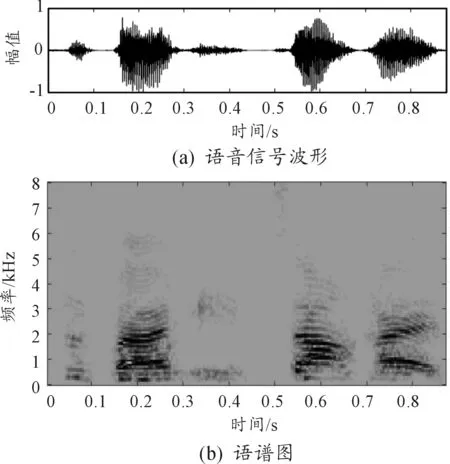
图10 算法3结果
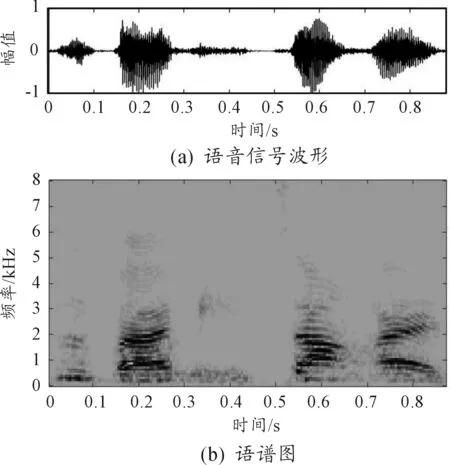
图11 本文算法结果
比较各算法增强后的语谱图,谱减法处理后不仅噪点消失不见,语音的谱线也几乎被消除,没有明显的语音变化趋势。自适应滤波法处理后的语谱图较清晰,高频噪声分量几乎完全去除,语音趋势清晰可见;算法3和本文算法处理后语谱图清晰,与原始纯净语音的语谱图一致,语音趋势清晰,本文算法较算法3比,能保留有效的低频信息。
4.3.2真实带噪语音下各算法比较结果及分析
对实际采集的带噪语音“刀光枪影”进行语音增强实验,原始带噪语音及语谱图如图12所示,图13、图14、图15和图16分别是算法1、算法2、算法3和本文算法增强后语音的波形图和语谱图。
图12是从59D装甲车运动现场采集的语音信号,语音“刀光枪影”淹没在噪声中。从图13可看出,经谱减法处理后,噪声波形几乎消失不见,但是语谱图中只有几个高能量的点随机分布,观察不到语音的趋势,说明谱减法对语音造成了严重失真。从图14看出,经自适应滤波法处理后的增强语音语谱图虽然有噪点,但是能基本看清语音分量的趋势。从图15看出,算法3处理后,噪声几乎被完全去除,语谱图比较干净且语音趋势清晰明显,但是低频信号去除太多,会造成部分语音失真。观察图16,本文算法处理后,波形十分清晰,从语谱图中可以发现,背景几乎没有噪点,语音趋势清晰明显,低频部分的噪声被去除,而有效的低频成分保留,由经验可知,这去除的恰是装甲车的运动噪声。

图12 实际采集带噪语音
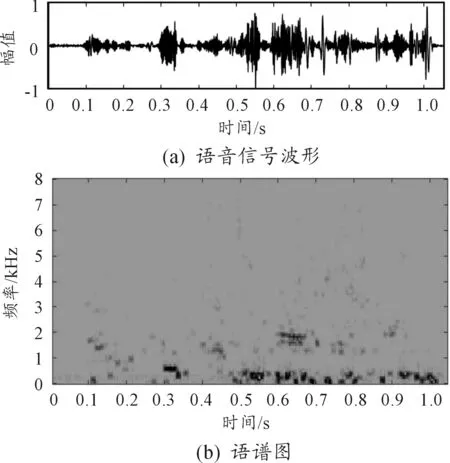
图13 算法1结果
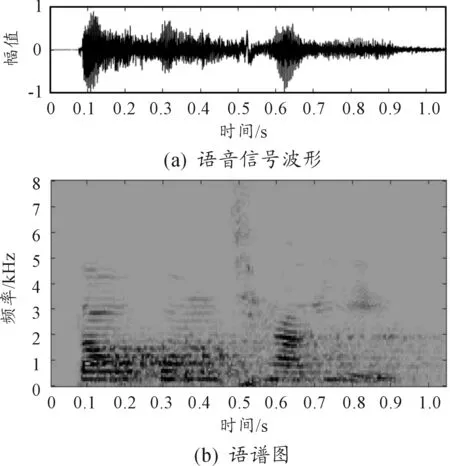
图14 算法2结果
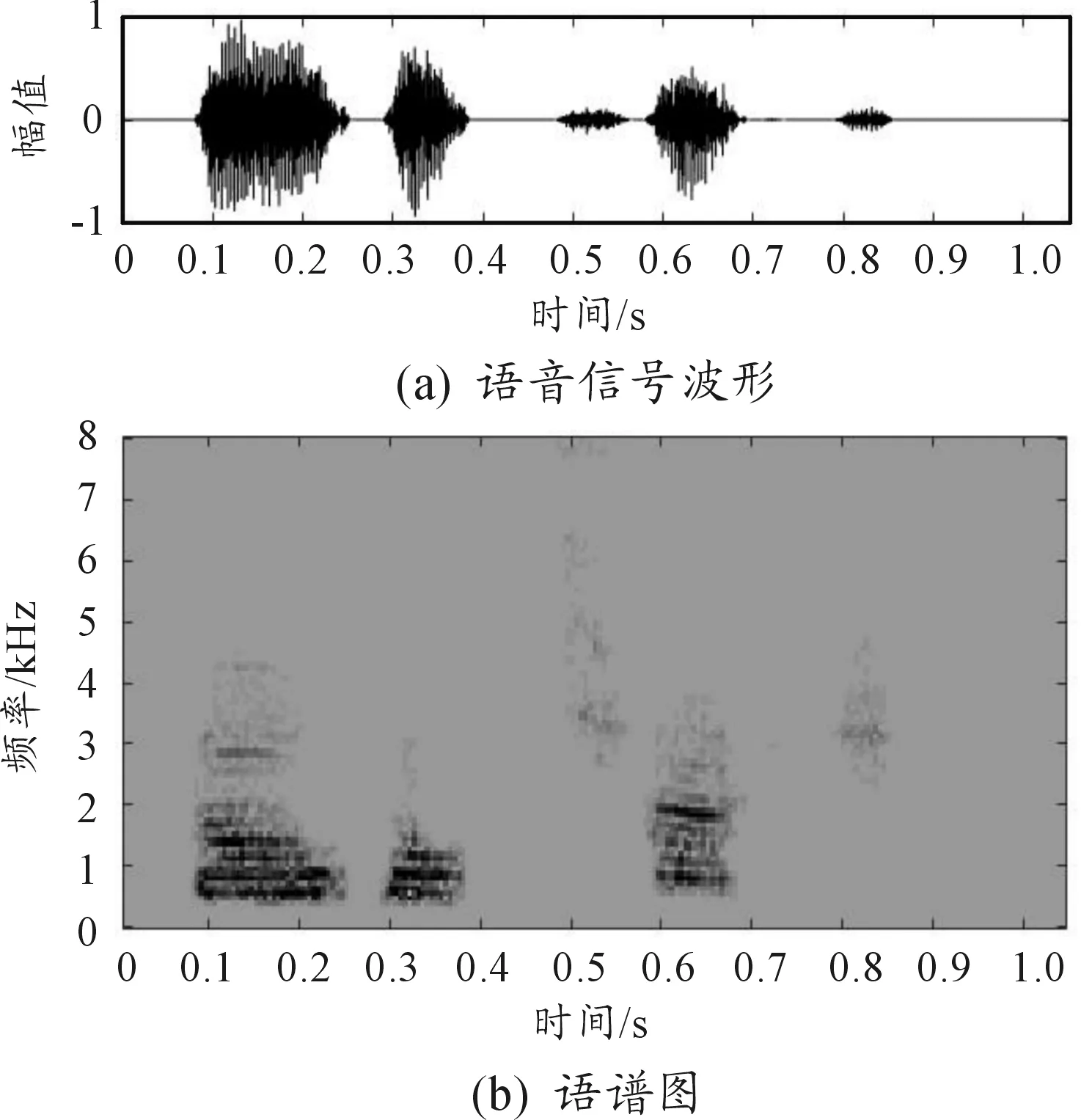
图15 算法3结果
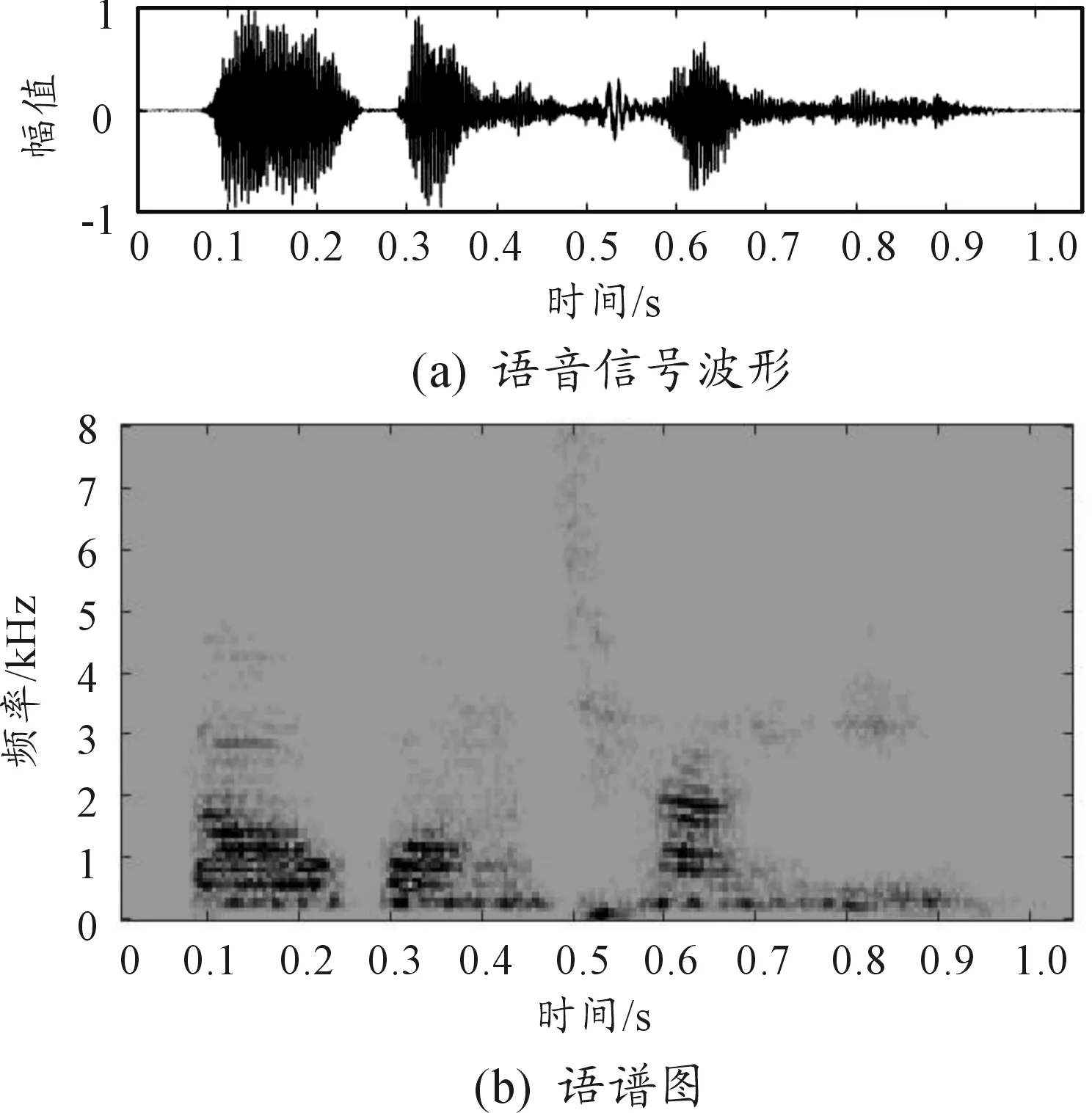
图16 本文算法结果
由于实验采集的是真实带噪语音,没有纯净语音做参考源,无法直接得到PESQ和STOI的分值,因此以各算法增强后的语音做参考源与原始带噪语音计算,获得相对分值进行分析,分值越低,表示效果越好,结果如表7所示。
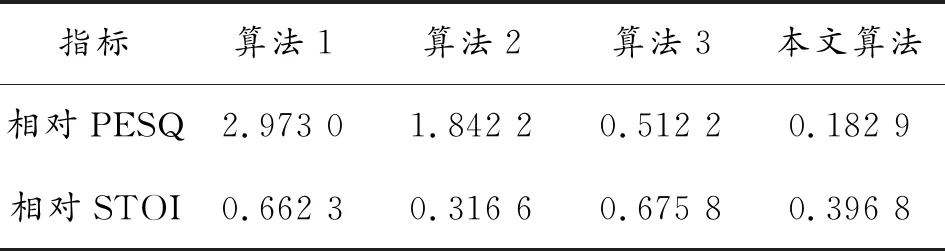
表7 不同算法增强后相对PESQ和STOI分值
从表7可看出:本文算法处理后的增强语音质量和可懂度都比较高,算法2处理后的音频能够听懂,但质量稍差,算法1音频更多的是“音乐噪声”。结合表中分值可知,基于深度神经网络的语音增强算法对装甲车运动时的声场环境有很好的增强作用,与算法3相比,本文算法的预处理对增强效果有更进一步的改善。
5 结论
本文算法提出在深度神经网络训练之前,先对数据进行预处理,包括EEMD分解和特征提取两步。本文预处理方法能有助于语音增强性能的提高,并在实际语音环境中进行检验。
本文算法主要针对装甲车运动噪声背景的语音增强,对其他噪声(如:餐厅噪声、极端噪声等)还需进一步研究,以充分发挥深度神经网络的独特作用。
