数控机床热误差的温度测点优化方法*
2019-07-01殷国富
谢 飞,王 玲,殷 鸣,谭 峰,殷国富
(1.四川大学 制造科学与工程学院,成都 610065;2.重庆邮电大学 先进制造工程学院,重庆 400065)
0 引言
热误差是影响机床加工精度的主要因素之一,其误差占比最高达到机床加工总误差的70%。在精密机床加工过程中,热误差已经成为最主要的误差来源[1-2]。减小热误差一般可采用硬件消除和软件补偿。硬件消除主要针对机床结构进行优化设计;软件补偿则是通过实时修改机床原点的方法进行补偿[3]。
国内外研究人员针对热误差测点优化与建模进行了深入的研究。林伟青等[4]利用最小二乘支持向量机结合遗传算法,提出了一种筛选及优化温度传感器的方法,使得轴向、径向建模平均绝对百分比误差低于2.04%。苗恩铭等[5]研究发现温度敏感点存在变动性特征并采用主成分回归算法建模,降低了温度敏感点变动对模型预测精度的影响。李艳等[6]提出了一种基于互信息法及改进模糊聚类的机床温度测点优化方法。马跃等[7]采用改进的模糊C-均值聚类算法及灰色综合关联度对热误差的温度测点进行了优化选择。崔岗卫等[8]基于线性回归对机床的几何误差及热误差进行了分离与建模,结合主因素与互不相关等优化策略优化测点,将机床热误差减小了64%以上。赵昌龙[9]通过数控机床的测温实验,利用灰色关联度分析对温度测点进行了优化,将实验测点由初始的8个减小为3个。Lee等[10]采用相关系数结合多元线性回归对温度测点进行了优化。此外还有基于逐步回归[11]、模糊C-均值聚类[12]、Fisher最优分割法[13]及粗糙集[14]等理论所得测点优化方法。以上方法虽然都采用了不同的聚类算法,但是在聚类数目的确定方面却仍然需要依靠人为经验,对于系统地选择聚类数目及测点的实际选择也缺乏完整清晰的思路,所建立的预测模型的泛化性能往往缺乏验证,很难确定预测模型的实用性。
本文以THM6380卧式加工中心为对象,进行了温度场及热误差的测量实验,分析了机床的温度场分布及其成因,采用系统聚类、灰色关联度及本文提出的测点筛选原则,整合了聚类数的确定及测点选择方法,最终对测点进行了系统优化。对比不同测点选择方法、不同预测模型的结果,结果表明采用此方法能够获得很好的模型预测精度及泛化性能。
1 温度测点优化选取算法
机床上的温度测点大多依靠工程经验人为选择,温度测点之间的距离相对靠近,以至于各测点的温度变化规律存在着相似性。若直接采用这些测点进行预测建模,不但经济成本高,而且各测点之间的多重共线性也会使得模型的预测精度下降。因此,对测点进行优化选择是很有必要的。
本文测点优化算法综合利用了系统聚类、灰色关联度及测点筛选原则,测点优化流程如图1所示。

图1 测点优化流程
优化算法步骤如下:
(1)首先进行系统聚类,将温度测点分为N类,N≥2;
(2)其次对新类进行灰色关联度分析,获得所有测点关于热误差的灰色关联度,并在每一类测点中按关联度从大到小进行排序;
(3)对每一新类测点,保留前M个排序后的测点,M≥1;
(4)当N≤2时,对N类中N×M个测点进行组合,并建立多元线性回归模型,选择具有最小预测残差的测点组合为第N-1步的最佳测点组合。当N>2时,将单步最佳测点组合与新类测点进行交叉组合,建立回归模型,取残差最小组合为第N-1步的最佳测点组合;
(5)N=N+1;重复步骤(3)、(4),直到N=测点数;
(6)将所有前N-1步最佳测点组合进行对比,选择具有最大残差下降比的组合为最终的优化测点。
1.1 系统聚类
系统聚类分析法[15]是一种可以对温度测点进行高效分类的一种方法。其基本思想是:先将各样本看成一类,然后计算各类与类之间的距离,选择距离最小的一对合并为一类,并计算新的类与类之间的距离,再将距离最近的两类合并为一类,如此每次缩小一类,直到所有的类合并为一类。最终得到的聚类树就是这一过程的完整体现。本文采用基于欧氏距离的类平均法进行距离定义。
通过欧式范数定义Rn上的距离函数为:
(1)
这个距离称为欧几里得度量,也称欧式距离。类平均法:定义类与类之间的距离为两类样本对之间的平均距离或两类样本对之间平均距离的平均值。
1.2 灰色关联度
灰色关联分析[16]的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线越接近,相应序列之间关联度越高,反之越小。
设X0=(x0(1),x0(2),…,x0(n))为系统特征行为序列,且
X1=(x1(1),x1(2),…,x1(n))
……
Xi=(xi(1),xi(2),…,xi(n))
……
Xm=(xm(1),xm(2),…,xm(n))
(2)
为相关因素序列。对于ξ∈(0,1),令:
r(x0(k),xi(k))=
(3)
(4)
则r(X0,Xi)称为X0与Xi的灰色关联度,其中ξ为分辨系数,一般取0.5。
灰色关联度的计算步骤如下:
第1步求各序列的初值像(或均值像)。令:

(5)
第2步求差序列。记:
Δi=(Δi(1),Δi(2),…,Δi(n)),i=1,2,…,m
(6)
第3步求两极最大差与最小差。记:
(7)
第4步求关联系数。
ξ∈(0,1),k=1,2,…,n,i=1,2,…m
(8)
第5步计算关联度。
(9)
1.3 多元线性回归
多元线性回归模型是热误差建模中常见的一种,其方法简单易行、计算量小且准确度高,基于最小二乘法的多元线性回归模型一般形式为:
i=1,2,…,n
(10)
模型中各系数及常数项利用最小二乘法求得。
2 温度测点优化选取实验
2.1 温度场及热误差数据采集
以某机床厂生产的THM6380高精度卧式加工中心为研究对象,采用Fluke公司的PT100温度传感器及Fluke2638A 20通道温度采集器测量机床主要部位的温度场。采用API主轴测试系统测量机床主轴的三向定位误差。测量时机床空载运行,每1min记录一次温度场及热误差数据,分别测量主轴转速为2000rpm,4000rpm,6000rpm及混合转速的温度场,热误差温度传感器的布置如表1所示。

表1 温度传感器的布置
温度测点的具体位置如图2所示,图3为热误差实验现场图。

图2 温度测点位置 图3 实验现场图
由此测得的机床热误差曲线如图4所示,温升曲线(6000rpm)如图5所示。由图可知该机床工作时热误差以Z轴(轴向)热误差为主,其余两轴热误差小于10μm,因此本文仅以Z轴热误差为主要研究对象。

图4 机床热误差曲线 图5 测点温升曲线
由以上数据可知,大部分温度数据具有相似性。其中位于主轴后轴承端盖处的T8~T10是温升最大的部分,因为后轴承高速旋转,为机床最大热源,故而温升最大与理论相符。T2~T7具有极大的相似性则主要是因为测点均与主轴相关,T11~T13由于依次靠近热源呈现依次增大的趋势,T14~T19由于远离热源的缘故,使得温升很小且几乎重合,T20为环境温度变化无规律,T1处于主轴最远端,由于端部散热情况的不同而呈现出不同的上升趋势。
2.2 系统聚类

图6 测点聚类树
2.3 灰色关联度分析
对所有测点温升与热误差进行灰色关联度分析,并按照灰色关联度从大到小的顺序排列,如表2所示。

表2 测点灰色关联度排序
2.4 测点选择
当聚类数N=2时,选择每一类测点中灰色关联度最高的前M个测点进行组合(M=2),建立多元线性回归模型,选取最大预测残差最小的组合为第1步最佳组合,最佳组合为ΔT2,ΔT18,预测模型最大残差为4.1873μm;当聚类数N=3时,选取新类测点中灰色关联度最高的前2个测点,并与第1步最佳组合进行组合,建立多元线性回归模型,选取最大预测残差最小的组合为第2步最佳组合,最佳组合为ΔT2,ΔT8,ΔT18,预测模型最大残差为3.6542μm。依此类推,所有测点组合预测性能曲线如图7所示。
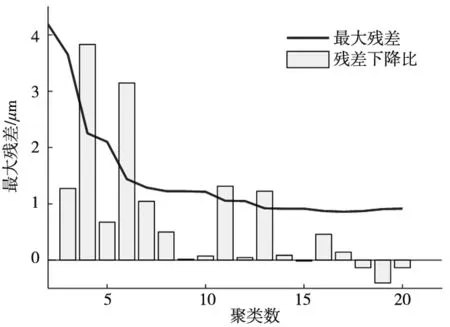
图7 测点组合性能图
通过此优化方法获得的测点组合模型的预测性能曲线,可以看出当聚类数最小为2时最大残差已经从127.1μm降低为4.1873μm,即热误差降低了96.7%,预测性能优异。但是测点数目过少容易丢失机床整体温度场信息及预测模型的稳健性,文献[5]亦表明对于不同转速的热误差预测,温度敏感点存在变动性特点,而过多的测点又会导致实验成本的增加,测点之间出现多重共线性。因此针对以上结果提出测点筛选原则:在测点优化模型的预测性能足够的前提下,选取残差下降比最大的测点组合为最终测点组合。残差下降比最大表明此测点组合模型在增加测点时获得了最大的性能提升,也即是实现了测点的最大“性价比”。
由图7可知,随着测点数的增加,预测模型最大残差逐渐减小,但是下降斜率却在不断变化。当聚类数为4时,预测性能曲线残差下降比最大,之后残差下降明显减慢,说明此时的测点组合实现了预测性能最大化。因此,选择此4测点(ΔT2,ΔT7,ΔT8,ΔT18)为最终优化测点组合,分别位于主轴前端、主轴后轴承端盖以及床身处,其温升随时间变化如图8所示。
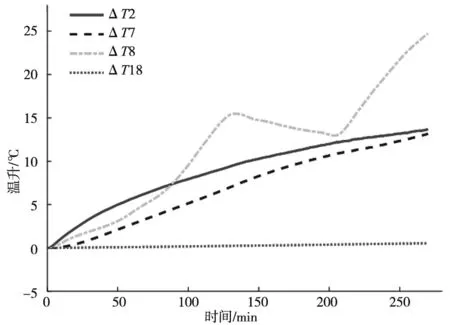
图8 优化测点组合
并进行基于最小二乘的多元线性回归建模。优化预测模型为:
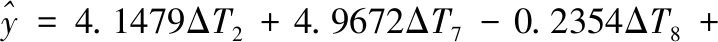
(14)
3 热误差建模及对比
3.1 预测性能对比
为了验证优化模型是否能较好预测机床的热误差,使用该优化模型对转速为6000rpm下的机床进行热误差预测。为研究不同测点优化算法及误差建模算法的预测性能,设置如下对比预测模型:
(1)预测模型1:MLR——20测点。使用所有20测点的温升作为模型输入,进行最小二乘多元线性回归;
(2)预测模型2:GC-MLR——4测点。以所有测点中灰色关联度最高的前4个测点的温升(ΔT2,ΔT7,ΔT18,ΔT19)作为模型输入,进行最小二乘多元线性回归;
(3)预测模型3:FCM-MLR——4测点。以模糊C-均值聚类法,将测点温升聚为4类,取每一类具有最大灰色关联度的测点温升(ΔT6,ΔT8,ΔT13,ΔT14)作为输入,再进行最小二乘多元线性回归;
(4)预测模型4:FCM-GM——4测点。以预测模型3的测点温升作为输入,利用全信息灰色模型GM(1,5)进行建模;
(5)预测模型5:SC-GM——4测点。以优化算法选取的4个测点温升(ΔT2,ΔT7,ΔT8,ΔT18)作为输入,利用全信息灰色模型GM(1,5)进行建模。
将以上对比实验结果及优化模型的热误差预测残差值进行对比,如图9所示。

图9 转速为6000rpm时,各预测模型热误差预测残差
对于预测模型的性能验证,本文采用最大残差、残差范围及均方根误差等进行衡量,其中最大残差取残差绝对值最大者,值越小则预测性能越好;均方根误差RMSE即预测值与期望值之差的平方和的根,其值越小则预测精度越高。

表3 转速为6000rpm时,各预测模型的预测性能对比
由图9及表3可知:
(1)当温度测点数由20优化为4时,优化模型的最大残差e、残差范围R及均方根误差RMSE均最小,优化模型对热误差能够进行较好的预测,可将热误差从127.1μm降低到2.254μm。说明优化选点算法优于模糊C-均值聚类及灰色关联度选点;
(2)对比FCM-MLR和FCM-GM及SC-GM和SC-GC-MLR的预测结果可知,以相同温度测点作为输入时,多元线性回归模型MLR的各项预测性能均高于灰色模型GM(1,5),其均方根误差RMSE仅为灰色预测模型的1/3。说明多元线性回归比灰色模型预测性能更好,更适合本文测点优化算法后的热误差建模。
3.2 泛化性能的对比
将转速为6000rpm的所有实验数据作为训练集,而转速为2000rpm的实验数据作为验证集。对比实验同3.1节。对比结果见图10及表4。

图10 转速为2000rpm时,各预测模型热误差预测残差

预测模型最大残差e/μm残差范围R/μm均方根误差RMSE/μmMLR4.7365[-4.7365,2.2993]3.1237GC-MLR5.7708[-5.7708,4.5762]9.6185FCM-MLR4.4139[-4.1343,4.4139]3.8359FCM-GM7.8426[-7.8426,0.2323]11.5086SC-GM4.1802[-4.1802,3.4288]5.0597优化模型(SC-GC-MLR)3.0650[-2.1351,3.0650]1.6465
由图10及表4可知:
(1)以相同测点作为输入时,灰色模型GM的预测性能比多元线性回归MLR更差。以MLR建立热误差预测模型时,优化模型选点的泛化性能比仅通过GC、FCM-GC或GC-CA进行选点效果更好,能够将最大热误差降低95.78%。
(2)各预测模型预测性能均有所降低,但优化模型SC-GC-MLR的最大残差e、残差范围R及均方根误差RMSE均最小,泛化性能最好,均方根误差仅为1.6465μm。优化选点比全测点模型预测精度更好,说明测点优化算法可行,不仅能减少温度测点数更能提高预测模型的泛化性能。
4 结论
本文针对THM6380卧式数控加工中心进行了温度场及热误差的测量实验,分析了机床温度场特点,基于系统聚类法、灰色关联度分析及测点筛选原则优化了温度测点的选择,并通过预测建模降低了机床的热误差。结论如下:
(1)优化模型测点优化性能显著,使得温度测点从20个减少为4个。通过MLR建模,虽然优化模型的预测性能稍低于全点预测模型,但是泛化性能提升效果显著,综合预测性能最好。
(2)全信息GM(1,5)模型预测性能及泛化性能均不如MLR模型,由于对初始聚类中心敏感的特性,FCM聚类容易陷入局部最优,测点优化效果不如本文所提优化方法。
(3)采用系统聚类、灰色关联度分析及本文提出的测点筛选原则,可以获得机床热误差预测模型的最优测点组合,且能够避免自变量之间的多重共线性,实现预测性能及泛化性能的均衡。有望应用于类似机床热误差的预测,进行系统的温度测点选择及误差建模。
