基于CNN的工业钉类识别研究及优化策略*
2019-07-01高兴宇陈凯生
高兴宇,陈凯生,黄 寅,张 朋
(桂林电子科技大学 广西制造系统与先进制造技术重点实验室,广西 桂林 541004)
0 引言
在工业中生产中,多类产品均涉及到钉类安装问题,钉类包括螺钉,拉钉,铆钉等等,钉的漏装问题将对产品的安全性、用户体验及企业形象有重大影响。钉类安装质量常通过机器视觉进行检测,因产品外观条件的复杂性,检测过程中主要存在两方面问题,一方面,焦距不变情况下,不同尺寸的产品所成像像素(清晰度)不同;另一方面,钉周围底纹及钉自带形状、颜色多种多样,并且他们都有可能出现在某款产品中。
目前,深度学习在面向交通标志识别、机器人视觉识别、智能驾驶等领域都有一定的应用,但鲜少有用于工业检测中,主要因为一方面传统视觉算法稳定[1],另一方面深度学习开发成本高,本文提出一种改进卷积神经网络(CNN)的检测算法与优化策略是采用基于CPU训练,在解决检测适用性问题的同时,笔记本便可完成工作,极大降低企业的成本与工作人员学习操作难度。
1 定位提取样本
图1为部分需检测的产品图,本文以交换机外壳上的螺钉与螺孔为研究对象来展开研究。

图1 部分产品图
在深度学习应用于智能驾驶的交通标志识别中,其中一个方向是自动寻找检测对象[2],技术相对尚未成熟,若将该技术应用工业检测中,不仅样本收集难度大,成本昂贵,鲁棒性与正确率也不能达到工业要求,因此本研究先采用传统图像处理算法,根据产品实际尺寸建立模板实现钉的定位。
1.1 建立模板与透视变换
图2a为产品的其中一个经过高斯滤波去噪后的检测面,中间有两个螺钉,以产品左上角(红圈)为基点,输入产品的长与宽,钉相对于基点X方向(横向)与Y方向(纵向)的距离,其它钉同理,便可建立相应检测面的模板,如图2b所示。检测面通过Canny算子[3]提取交换机外壳检测面边缘,如图3所示。提取边缘为产品外壳在图像中的尺寸,要将输入模板的尺寸定位至图像的尺寸,因此,需通过透视变换将提取边缘尺寸缩放映射至模板尺寸,实现尺寸统一。

(a) 检测面 (b) 模版 图2 交换机外壳及检测模板

图3 交换机外壳图像边缘提取
透视变换本质是投影映射,即一种将图片投影至一个新的平面[4],其中图片位移、角度、大小尺度的改变都属于透视变换中的一种特殊形式。要将提取边缘后的矩形投影模板中矩形,根据透视变换公式只需找到变换前矩形4个角的坐标点(u1,v1),(u2,v2),(u3,v3),(u4,v4)与映射后图像4个点对应坐标点(x1′,y1′),(x2′,y2′),(x3′,y3′),(x4′,y4′),联立方程组可求解透视变换矩阵。
变换公式为:
变换后得:
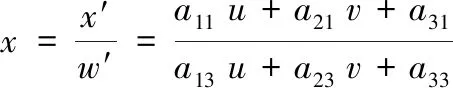
利用透视变换后,在产品检测面图像中,只要涉及检测的钉,通过模板输入钉的坐标位置,即可定位。在定位过程中,会出现与输入模板尺寸与理想定位偏差,本文采用50×50尺寸的图片基本适应钉的大小并且采集训练样本数据时已经覆盖所有钉偏移情况,故这个偏差不影响检测准确度并且可降低对定位精度算法开发难度。
1.2 提取样本
在CNN网络输入图片数据中,小尺寸的图有利于卷积提取特征并且减少网络训练时间,在经过建立模板后,可以定位截取同一种钉的不同光照下各种姿态及偏移的训练样本。在样本采集中,建立“标准”样本库作为补充,所谓标准为钉的位置始终位于50×50图像中心,在原图上利用截图软件截取标准样本。图4所示为列举6种螺钉(第0类)与对应螺孔(第1类)的部分样本,每种螺钉与螺孔的样本中存在位置,光照,背景与像素的变化干扰。
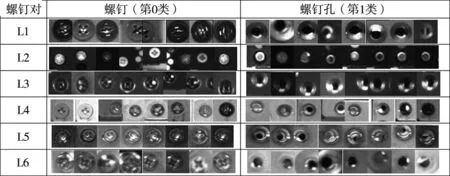
图4 螺钉对样本图
以L1螺钉对为例,需采集7种不同光照下,3种旋转90°的样本,以钉圆中心上下左右8个方位偏移采集16×16种样本,螺钉2种(×与+)位姿,共10752个样本,另外补充非偏移标准样本以达到1.25万个样本。L1螺孔与螺钉是对应的同样数目,最终L1螺钉与螺钉孔总数为2.5万个样本,L2~L6也同理采集样本。
2 螺钉与螺孔识别
2.1 CNN基本结构
不同于ResNet、SSD等复杂深度卷积神经网络,分析螺钉与螺钉孔的图像特点,两者差异较明显,本文提出基于数字识别网络LENet进行超参数优化的CNN网络结构算法,本质上属于有监督学习算法。一个卷积神经网络构建基础由卷积层,池化(Pooling)层,全连接层组成[5],本网络有三个卷积层和三个池化层结合超参数(在开始深度学习过程之前设置值的参数)的选择构建而成的网络结构,通过对输入50×50的样本图像特征进行提取形成特征子图,再把特征子图全部展开,形成一维特征子集,最后运用全连接层平铺连接特征子集,对输入的图像进行分类识别,并输出结果。网络的结构与参数如图5、表1所示,超参数的设置如表2所示。
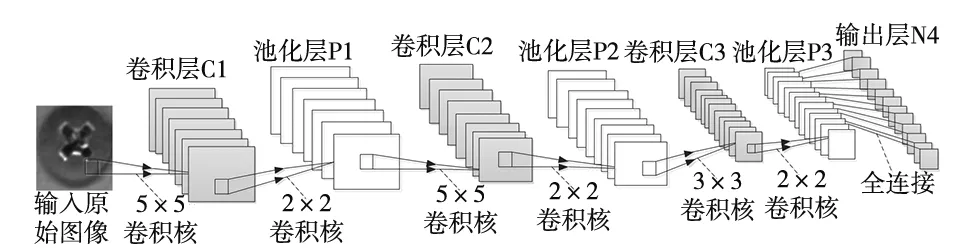
图5 用于螺钉对识别的CNN模型网络图

层数类型特征图个数及尺寸核大小步长1输入层X01&50×50——2卷积层C124&46×465×513池化层P124&23×232×224卷积层C260&19×195×515池化层P260&10×102×226卷积层C3120&8×83×317池化层P3120&4×42×228全连接F4560&1×11×1—9输出成N4100&1×1——

表2 超参数表
2.2 网络训练
深度学习与传统视觉算法不同之处在于利用已知框架对输入信息的卷积神经网络进行系统训练,可以提取特征子图的同时学习在输入与输出的一种多层数据模式的非线性关系[6]。卷积层每个神经元与部分神经元相连,每组连接可以共享同一个权值实现降低计算量,利用池化层减少每层的样本数,进一步减少参数数量提高鲁棒性同时增加迭代次数以提高网络训练的精度。
本网络结构在Caffe框架搭建,Caffe框架可将所有训练样本图片数据转换生成一种闪电般的内存映射型数据库管理(LMDB),有利于减少读取图片数据时间。


3 硬件配置
制造交换机外壳行业不同于智能机器人行业,并非都可以投入人工成本及高昂服务器进行开发,本网络结构采用Caffe框架并且用普通配置酷睿i5处理器或以上电脑即可进行CPU训练,除了可达到检测准确度要求外,可降低工业开发周期与成本,有利于推进工业检测发展。
本实验采用联想笔记本小新系列V4000型号,CPU配置为i7-5500U,结合在虚拟机Mware Workstation Pro下安装ubuntu16.04版本Linux系统中安装Caffe并训练。
4 实验结果与分析
将6组螺钉与螺钉孔对即L1~L6依次添加样本数量,发现生成LMDB时间随着样本总数量增加,而训练在最大迭代次数5000次完成的消耗时间相对稳定在80min左右。若继续放入螺钉对数量,会造成生成LMDB时间不断延长,这不利于解决验证模型问题。
将螺钉与螺钉孔以随机方式输入模型进行测试500次,记录是否准确判断结果。
在本网络结构与超参数的选定中,发现Caffe显示准确率稳定在99%以上,但实际测试时,在样本数10万以外则无法达到与训练准确率一致,下降极其明显,结果见表3。

表3 训练结果表
分析数据发现原因之一是在所有参数,特别训练深度(卷积核数量)保持不变而不断增加样本数量时,该网络难对10万以后的训练样本更深入的读取与训练。增加卷积核会延长训练时间,考虑螺钉对远不止列举的6种,不利解决工程问题。将L1~L6的螺钉对中随机抽取出一部分螺钉与螺钉孔,每对螺钉与螺钉孔的样本数压缩至2万,结果见表4,样本数量保证在10万内的准确率与实际测试准确率一致,更重要是比表3中(L1~L4)检测多一种螺钉对(L5)。

表4 减少样本训练结果表
5 优化策略及结果
在交换机外壳行业中,一款产品的钉一般由螺钉,拉钉等多种钉装配,而螺钉种类一般不会超过4种不同类型,比如L1~L6中,只出现其中4种或少于4种,其余钉为拉钉,铆钉等等钉类,因此采取一种“一产品一螺钉模型”优化策略,即对一个产品中出现的螺钉种类进行训练相应螺钉模型,当换产品检测时,调用相应螺钉模型检测。
首先这种优化策略有利于工业检测稳定性,工业上在每次批量检测某款产品时换上相应模型可提高检测准确率的方式更容易让企业接受。其次,本网络结构在采样后利用普通电脑可进行短时间模型训练,相对容易实现。第三,需提前细分螺钉中第1~n种的螺钉对,采样分类过程繁琐,但在不同产品的螺钉对中,只要出现与之前分类的n种钉一样的螺钉对即可调用样本,不用再重新采集,有利于维护与增加可检测产品。最后,采用优化策略后每款产品测试500次,结果表5所示,产品一至三分别包括2、3、4种螺钉对,综合准确率为实际测试准确率取均值,保持99%以上,可达到工业检测标准。

表5 优化策略结果表
6 结束语
针对交换机的同一检测面上存在多种类型的钉并且每种钉有位置变化,光照变化,背景干扰,像素模糊等因素影响的问题,采取了现实场景采集样本输入改进的CNN中进行一系列训练与测试,并通过在换产品检测时,自动调用相应钉模型的优化策略,实现工业钉类是否漏装的精确检测。实验结果表明利用本文方法,稳定性高,平均识别准确率达到99%以上。为了使其更具有智能性,研制能够实现与装钉机器人配合进行实时补装钉的系统是下一步的工作重点。
