基于竞争神经网络的全局K-Medoids聚类算法研究*
2019-07-01王兆辉甄丽红
曹 勇,王兆辉,高 琦, 甄丽红
(1.山东大学 机械工程学院CAD/CAM研究所,济南 250061;2.山东省科技发展服务推进中心,济南 250101)
0 引言
聚类是十大常见数据挖掘技术之一,属于无监督分类技术,它通过将数据分成不同的组,使组内数据间相似度大,而组间数据差异大。常见的聚类算法分为基于划分、层次、密度、网格和模型的方法[1]。其中由Kaufman[2]提出的K-Medoids算法是基于划分的方法的典型代表,它以样本中的原始数据作为聚类中心,可以避免离群点对聚类结果的影响,但是该算法对初始点比较敏感,容易陷入局部最优。Park[3]提出的简单快速的K-Medoids算法,可以有效的提升聚类精度,但该算法在对大规模数据进行聚类分析时耗时比较长。Aristidis L[4]提出的全局K-Means算法,可以有效的避免聚类结果依赖于初始中心点的选择和算法过早收敛,防止陷入局部最优。但由于全局算法串行迭代搜索的本质,使得算法在对大规模数据进行聚类分析时同样耗时比较长。而神经网络并行计算的特性使得它在面对大规模和高维数据聚类问题具有很大的计算优势。竞争型神经网络是一类非常典型的无监督学习聚类算法,Kohonen等[5-7]提出的基于竞争神经网络和基于SOM的聚类算法是其中的典型代表。算法通过训练网络的结构参数,根据数据之间的相似性对数据进行自动分类,但这类聚类算法只能提供粗糙的聚类方案,并不能提供最终的精确聚类信息。
本文拟将竞争神经网络和全局K-Medoids算法结合起来用于样本聚类分析。将Aristidis L提出的全局思想应用于K-Medoids算法,避免算法陷入局部最优的情况。此外,利用神经网络快速并行计算的优点来解决全局K-Medoids算法串行迭代的缺点,加快算法的全局搜索速度。基于上述原因,本文提出基于竞争神经网络的全局K-Medoids聚类算法。
1 算法介绍
1.1 竞争神经网络算法
竞争神经网络是一种无监督学习方法的神经网络,其主要思想是基于竞争学习,通过网络输出层中各个神经元之间相互竞争来获得对输入模式的响应机会,且只有一个神经元成为胜利者[8]。整个网络由m个神经元构成的输入层和n个神经元构成的输出层组成,其网络的连接权重为:
W={wij|i=1,2,...,m;j=1,2,...,n}>
(1)
其中,wij为第i个输入神经元与第j个输出神经元之间的权重。
对于N个样本,其输入模式为:
X={Xi|i=1,2,...,N}>,Xi=(xi1,xi2,...,xim)
其中,xij为样本Xi的第j维属性值。
(2)
其中,bj为第j个输出神经元的阈值。
根据竞争机制,输出层中状态最好的神经元取得胜利,其状态值为1,其余竞争均失败,对应状态值为0,则对应的输出模式Yk为二值向量:

(3)
对于获胜的神经元而言,根据Kohonen学习规则更新与其相关的连接权重,假设学习速率为η,则根据下式调整权重Δwij:
(4)
竞争神经网络算法流程如图1所示。

图1 竞争神经网络算法流程图
1.2 全局K-Medoids聚类算法
全局K-Medoids聚类算法是以数据样本中的原始样本作为聚类中心,然后利用某种距离度量函数来度量样本之间的相似性,将相似性大的样本聚成一类。对于样本{Xi,Xj}>的相似性度量函数为欧拉距离,如式(5)所示,其相似度为距离的倒数,如式(6)所示。
(5)
Sim
(6)
对于N个样本{X1,X2,...,XN}>的聚类问题,其相异度矩阵如下:
特别地,dXi,Xi=0,dXi,Xj=dXj,Xi。
聚类数为K的聚类问题,其目标函数为最小距离平方和Fc,如下:
s.t.
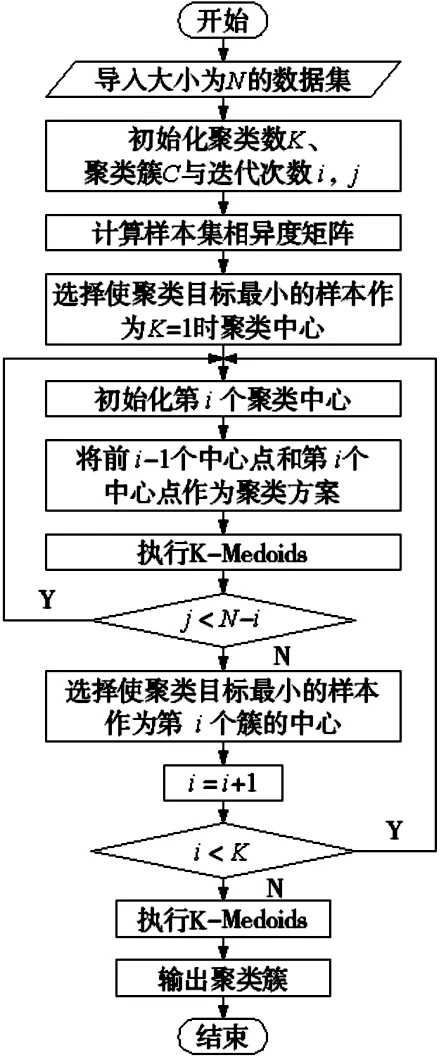
C={Ci|i=1,2,…,K} 全局K-Medoids算法流程如图2所示。 图2 全局K-Medoids算法流程图 由于神经网络数值向量输入模式的要求,需要提出一种数值属性的表达方式来描述文本序列,使该算法适合于文本序列数据的聚类分析。对文本序列数据的聚类问题,如刘书暖等[9-12]提出的工艺路线的聚类问题,基于神经网络的聚类方法研究尚显不足。针对神经网络不能处理文本序列数据的缺点,提出一种将文本序列数据转换成数值数据的方法,从而使该方法适用于文本序列数据的聚类分析问题。本文提出将文本序列间的相似性作为描述文本序列的方式,利用最长公共子文本序列(Longest Common Sequence,LCS)算法[13]进行文本序列间相似度计算。算法具体内容如下: 对于两个文本序列Xm=(x1,x2,...,xm)与Xn=(x1,x2,...,xn),它们之间最长公共子文本序列为:LCS(Xm,Xn)={l1,l2...,li,...,lr}>,其中li=xk,m=xg,n,xk,m∈Xm且xg,n∈Xn,xk,m为文本序列Xm中的第k个元素,则文本序列Xm与Xn之间的相似度为: (7) dX1,Xi=1/Sim (8) 其中,|Xm|为文本序列Xm中元素的个数。 根据上述计算,则文本序列数据的数值属性描述方式如下: Xi=(dX1,Xi,dX2,Xi,...,dXi,Xi,...,dXN,Xi) 其中,dXj,Xi为文本序列Xi的第j维属性值。 则对于一组文本序列数据X={X1,X2,...,XN}>,按照上述方法,可将其转换成用数值性属性描述的数据,样本总体可表示为: 根据上述步骤,整个算法的流程如图3所示。 图3 本文算法流程图 为验证本文算法和所提文本序列的属性描述方式的有效性,选择K-Medoids算法和全局K-Medoids算法,根据聚类质量指标和算法运行的时间,利用UCI数据库中的实验数据和某机加工企业的工艺数据库中的工艺路线数据与本文所提算法进行对比验证。实验环境为:Intel i5 CPU 3.20 GHz,RAM 4GB,Windows7操作系统, MATLAB 2014Ra。 数据来源于UCI machine learning repository数据库,共8组,均为数值数据。为了消除由于数据属性量纲的差异对结果造成的影响,在进行聚类分析前,先将原始数据各个维度的属性值进行归一化处理,在这里采用最大最小归一法,其公式为: (9) 其中,xij为第i个样本第j维的原始值,xij*为第i个样本第j维的归一值,xmin为所有样本第j维度上的最小值,xmax为所有样本第j维度上的最大值。 对实验数据,运行三种算法,其结果如表1所示。表中,N为样本总数,d为样本属性维数,K为聚类数目,E为聚类质量指标,即聚类距离平方和,T为算法的运行时间。由表1可知,3种算法中:①K-Medoids算法的聚类质量最差,这是由于受到初始聚类中心的影响,算法容易陷入局部最优;②全局K-Medoids算法相对于K-Medoids算法,能够有效提升聚类的质量,但是在面对样本数据量较大的时候,上述两种算法的搜索效率均不高;③本文所提算法的聚类效果最好,而且在面对样本数据量较大(样本量N≥4000)的时候,算法的效率相对于K-Medoids算法平均提升49.2%,相对于全局K-Medoids算法平均提升41.2%。 从实验中可知,本文所提算法能够有效的提升数值数据聚类分析时的质量,而且在面对大样本量的数值数据的聚类分析时,算法的效率能够得到大幅度提升。 为进一步验证本文算法对文本序列数据聚类分析的有效性,收集某机加工企业工艺路线数据中的5类107种零件的工艺路线,利用文献[14]所提到的编码方案对工艺路线进行编码,部分工艺路线如表2所示。 首先根据经验公式(10)确定聚类数的范围: (10) 然后从K=1,2,...,M,依次运行应用K-Medoids聚类算法、全局K-Medoids聚类算法和本文算法,记录对应的聚类误差,绘制聚类误差与聚类数目图,如图4所示。其中,K为聚类数目,E为聚类误差。 图4 聚类数和聚类误差图 由图4可知,K-Medoids算法的聚类误差最大,而相比于K-Medoids算法,全局K-Medoids算法和本文算法能够获得质量更好的聚类方案。此外,从图中可以看出,上述3种算法在K=1到K=5时聚类误差平均下降速度最快,因此,取合理的聚类数目为K=5,这与实例2中的实际零件类别数是一致的。针对于聚类数K=5,实验结果如下:对应K-Medoids算法的聚类距离平方和为365.81,算法运行时间为0.33s;全局K-Medoids算法的聚类距离平方和为356.11,算法运行时间为0.03s;本文算法的聚类距离平方和为349.48,算法运行时间为2.42s。由上述结果可知,本文算法的聚类质量最佳,能够获得更优的聚类方案。 因此,结合提出的文本序列数据的描述方式,本文所提算法能够有效的处理文本序列数据的聚类问题。 表1 3种算法聚类分析结果 表2 零件工艺路线和编码 (1)通过神经网络并行计算的特性加快大规模数据聚类的速度,在数据量大于4000时,相比于K-Medoids算法,效率平均提升49.2%,相比于全局K-Medoids算法,效率平均提升41.2%。 (2)通过全局K-Medoids算法的全局思想,实现数据的二次聚类,相比于K-Medoids算法,精度平均提升13.6%,相比于全局K-Medoids算法,精度平均提升2.8%,有效避免了算法陷入局部最优。 (3)通过定义文本序列数据的描述方式,使得神经网络算法能够处理该类数据的聚类问题。 实验证明,基于竞争神经网络的全局 K-Medoids算法融合了神经网络并行计算的优点和全局K-Medoids算法的全局思想,弥补了各自的缺点。此外,以某机加工企业工艺数据库中的工艺路线数据聚类分析为例,证明了本文提出的算法在面对文本序列数据的聚类问题时的有效性,同时为通过聚类技术提取典型工艺路线的问题,提供了一种新的解决思路。
C1∪C2∪…∪CK=X,Ci∩Cj=∅,1≤i≠j≤K
0<|Ci|
2 竞争神经网络全局K-Medoids聚类算法
2.1 文本序列数据的属性描述方式
2.2 算法总体流程

3 实例验证
3.1 实例1
3.2 实例2




4 结论
