一种改进的相邻块视差矢量快速获取方法
2019-06-27谢晓燕周金娜刘新闯王安琪
谢晓燕, 周金娜, 朱 筠, 刘新闯, 王安琪
(1. 西安邮电大学 计算机学院,陕西 西安 710121;2.西安邮电大学 电子工程学院,陕西 西安 710121)
三维高效视频编码(3D-high efficiency video coding,3D-HEVC)[1]利用不同视点编码的图像信息,借助类似于2D帧间预测的运动估计和Merge模式获得运动矢量的思想获取视差矢量。视差矢量 (disparity vector,DV)在视图间运动矢量预测、视差补偿预测和其他视图间编码技术中起着关键性作用[2]。3D-HEVC中基于相邻块的视差矢量获取方法(disparity vector from neighbouring blocks,NBDV)[3]按预定顺序搜索空间和时间候选块位置,把第一个搜索到的视差矢量当作最终视差矢量,并终止视差矢量的搜索。这种方法降低了视差矢量的精度,同时按照一定顺序搜索也降低了视差矢量的获取速度。
通过重新组合或者删减候选块,可缩短视差矢量编码时间。如对视差矢量候选块重新建立候选块视差矢量候选列表,根据列表中DV的数量,结合率失真优化算法推导出最终的NBDV[4],该方法虽然通过率失真有效筛选,降低了一定的编码时间,但是却增加了一定的码率。运动和视差矢量的早期确定方案[5-6],虽然跳过了一些模式,降低了算法的复杂度,但是可能会删减掉更有效的视差矢量信息。在3D-HEVC标准测试模型HTM 8.0测试平台对所有相邻候选块进行DV采用率的统计,为保持高效性在搜索过程中删除了B类的候选块,但视差矢量的精度有所降低[7]。基于候选块的组合搜索方法[8]和利用局部信息得到局部视差矢量的方法[9]虽然提高了视差矢量的精度,但是对候选块需要不断地进行组合再搜索,增加了编码时间。
为了能同时确保视差矢量精度和编码效率,本文提出一种改进的相邻块视差矢量快速获取方法。分别按照时域和空域方向获取相应块的视差矢量,对其进行均值计算获得最终的视差矢量;然后在视频阵列处理器[10]上对该方法进行并行化实现,以期减少视差矢量获取过程的编码时间。
1 基于相邻块的视差矢量获取方法
NBDV通过编码单元 (coding unit,CU)的时域和空域候选块获得视差矢量。根据相关性程度,NBDV获取视差矢量优先检测时域候选块,其次是空域候选块。时域候选块的搜索顺序为先中间块后右下角块,如图1(a)所示;5个空间候选块的搜索顺序为左边(A1),上边(B1),右上(B0),左下(A0),左上(B2),如图1(b)所示。

图1 相邻块视差矢量的候选块
选择第一个搜索到的视差矢量作为最终的视差矢量,一旦检测到可用的视差矢量,即当前CU的NBDV完成。但是采用这样的搜索匹配方式,第一个可用的视差矢量可能被当作最终的视差矢量,后面的候选块中可能存在更优的视差矢量信息,在没被搜索前就已被中止,降低了视差矢量的精度,且按照一定顺序搜索时域和空域候选块,编码时间过长,效率偏低。
2 改进的相邻块视差矢量获取方法
空间参考块的搜索顺序可以进行多种排列组合,改进方法在不舍弃B类候选块的前提下,将空域候选块进行重新排序,固定A1和A0的搜索顺序不变,重新组合B类。在原标准搜索顺序左边(A1),上边(B1),右上(B0),左下(A0),左上(B2)的基础上增加6组搜索顺序,即第1组左边(A1),左下(A0),右上(B0),上边(B1),左上(B2);第2组左边(A1),左下(A0),右上(B0),左上(B2),上边(B1);第3组左边(A1),左下(A0),上边(B1),右上(B0),左上(B2);第4组左边(A1),左下(A0),上边(B1),左上(B2),右上(B0);第5组左边(A1),左下(A0),左上(B2),右上(B0),上边(B1);第6组左边(A1),左下(A0),左上(B2),上边(B1),右上(B0)。
选取3D-HEVC标准测试模型HTM 16.1中Balloons 、Poznan_Street 、Poznan_Hall2、Newspaper 、Undo_Dancer和 kendo等 6个通用测试序列,利用7种空间候选块搜索顺序对视差矢量进行搜索,分别对比7种搜索顺序结果的比特率和信噪比,从而选取编码质量最好的搜索顺序作为既定的搜索顺序。对比结果如表1所示。

表1 空域候选块按照不同搜索顺序的性能结果对比
由表1可以看出,第5组的搜索顺序比其他组搜索顺序编码质量略好,故选择第5组搜索顺序作为最终空间候选块的搜索顺序。
按照左边(A1),左下(A0),左上(B2),右上(B0),上边(B1)最终空间候选块搜索顺序,搜索空域候选块的所有视差矢量;时域候选块按照先中间后右下的顺序搜索视差矢量。分别对空域和时域候选块得到的视差矢量进行均值计算,得到最终视差矢量,计算表达式为
(1)
其中:VDi为所有视差矢量的集合;m为候选块个数,每个候选块通过均值计算得到视差矢量。
3 改进的相邻块视差矢量获取方法并行化实现
候选块视差矢量按照一定顺序在空域和时域候选块中搜索视差矢量,其中空域的5个候选块和时域的2个候选块数据之间虽然存在一定的相关性,但是其像素计算部分却相互独立,存在着较大的并行性。因此,可将改进方法中的空域和时域候选块划分,整合并行部分,在阵列处理器上进行并行化实现。
3.1 动态视频阵列处理器架构
动态视频阵列处理器支持H.264/AVC、MVC、H.265/HEVC和3D-HEVC等视频编解码标准。该视频阵列处理器以4×4结构为例,结构如图2所示。
阵列处理器在逻辑上把结构划分成处理元簇 (processing element group,PEG)阵列,每个簇由4×4的处理单元(processing element,PE)以阵列的形式组成。全局控制器实现对计算资源的控制与管理,输入存储 (data input memory,DIM)用于存储原始视频数据。视频算法中数据的处理大多以N×N矩形块进行,这种阵列体系结构能更有效地实现视频算法并行化。

图2 阵列处理器的部分结构
3.2 基于阵列处理器的获取DV并行化实现
将空间候选块A1、B1、B0、A0、B2和两个时域候选列表的中间块及右下角块,分别配置到PE00、PE10、PE20、PE30、PE21、PE01、PE11、PE02和PE12中,给所属PE下发原始像素数据和参考像素数据。在进行块匹配之前已将数据存储到对应PE的地址中,和其他PE计算不会产生冲突,因此,在同一时刻不同PE可以同时工作,最大程度实现算法的并行化。
每个PE接收到数据后同时开始进行处理,计算得到各自候选块的DV和绝对差值和(sum of absolute difference,SAD),然后将各个块得到的DV传送到PE03中,在PE03中对DV进行均值计算。改进的视差矢量方法计算流程如图3所示。

图3 获取视差矢量流程
并行化实现具体步骤如下。
步骤1从基本视点中读入原始像素,同时从两个时域参考帧中读入参考像素,像素值分别存储在外部存储中。
步骤2调度PE00、PE10、PE20、PE30、PE21、PE01、PE11、PE02和PE12。对时域的中间块、右下角块和空域块A1,B1,B0,A0,B2分配原始像素和参考像素,分别计算各自的DV和SAD。
步骤3将PE01、PE02、PE11、PE12中两个时域参考块中得到的DV和SAD信息存储到PE12中,通过SAD得到最优的时域DV信息,发送到PE03中。
步骤4将步骤2得到的空域候选块的所有DV也发送到PE03中。
步骤5将步骤3和步骤4分别得到的时域和空域候选块的DV进行均值计算,即可获取得到最终的DV。
4 仿真结果及实验分析
以3D-HEVC标准测试模型HTM 16.1为测试平台[11],将改进方法在平台上加以实现。视频测试序列为Undo_Dancer、Poznan_Hall2和Poznan_Street等 3个1 920×1 088序列,及Kendo、Balloons和Newspaper 等3个1 024×768序列。通用测试条件规定的纹理及深度量化参数(quantization parameter,QP)为(25,34)、(30,39)、(35,42)和(40,45)。采用3个视点编码,编码顺序分别是中间视点到左视点再到右视点,其中中间视点为基本视点。编码测试参数如表2所示。

表2 实验测试参数
4.1 改进方法的编码结果分析
分别对比改进方法与HTM 16.1的编码比特率差值(bjøntegaard delta bit rate,BDBR)、编码峰值信噪比差值(bjøntegaard delta peak signal-to-noise rate,BD-PSNR)[12]和编码时间差ΔTime[13],结果如表3所示。BDBR表示在同样的客观质量下,较优的编码方法可以节省的码率百分比,BDBR越小,当前编码器的压缩性能越佳;BD-PSNR表示在同等码率下,两种编码条件下压缩后视频PSNR-Y值的差异,BD-PSNR值越大,当前编码器质量损失越小;ΔTime指改进方法3D-HEVC编码时间之差的百分比。
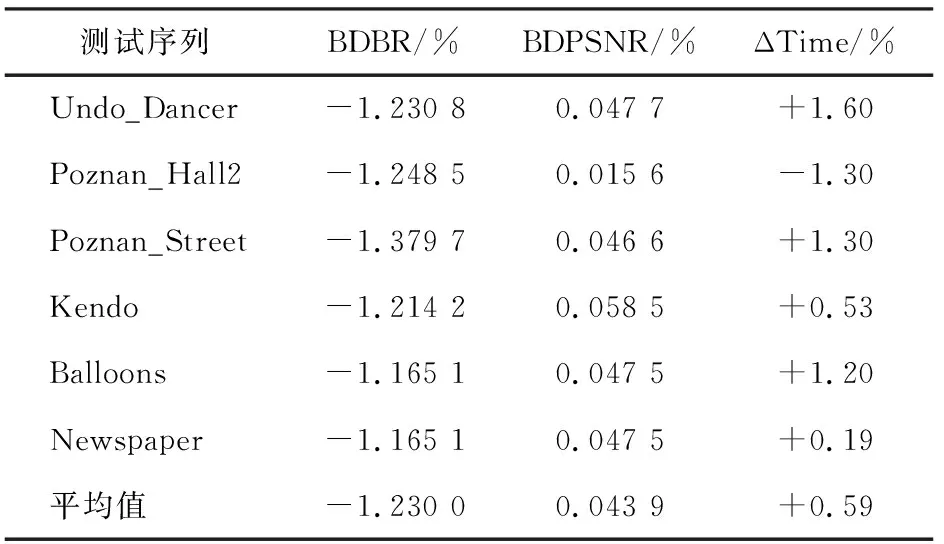
表3 改进方法与HTM16.1的编码性能对比
由表3可以看出,BDBR的平均值为-1.23%,表示改进方法比HTM 16.1增加了约1.23%的编码增益。BD-PSNR的平均值为0.043 9 dB, 表示改进方法比HTM 16.1平均提高了0.043 9%。因此,改进方法的性能指标更好。获取视差矢量采用了均值计算,ΔTime只增加了平均0.59%的计算量,故可忽略不计。
改进方法和HTM16.1的编码率失真曲线如图4所示。可以看出,改进方法能获得更好地率失真曲线。

图4 率失真参数实验结果比较曲线
4.2 改进方法的合成结果分析
根据图像质量的评价指标峰值信噪比(peak signal-to-noise ratio,PSNR)和图像间的相似度评价指标结构相似性(structural similarity index,SSIM)[14],对比改进方法与HTM 16.1对合成图像的影响。改进方法与HTM 16.1合成后图像的PSNR和SSIM对比结果分别如图5和图6所示。
从图5 (a)、图5 (b)和图5 (c)可以看出,图像合成后改进方法和HTM 16.1的PSNR相近,图5 (d)、图5 (e)和图5 (f)可以看出图像合成后改进方法比HTM 16.1的PSNR略高。从图6 中可以看出,图像合成后改进方法和HTM 16.1的 SSIM相近,改进方法损失的失真度较小,因此,改进方法合成后视频质量更好。
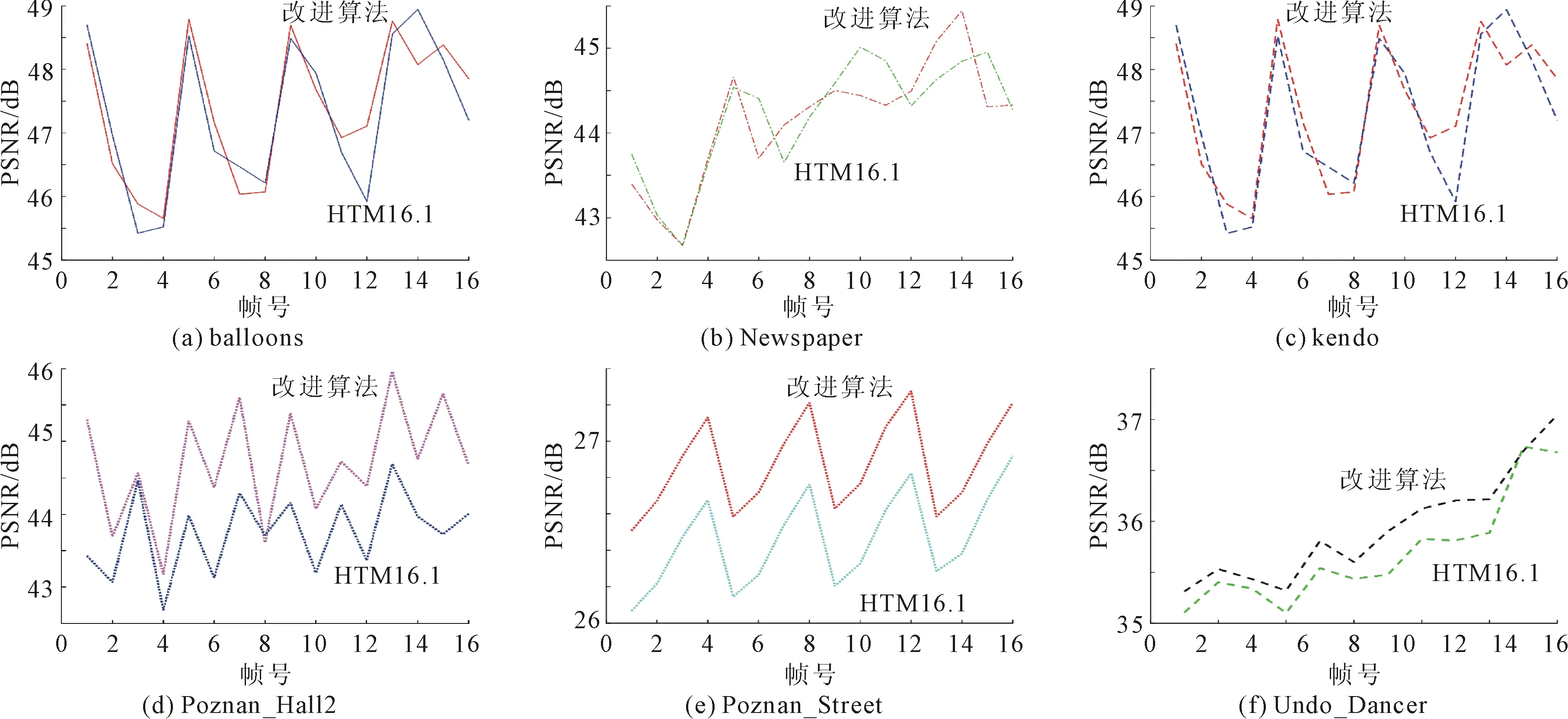
图5 合成后图像PSNR对比

图6 合成后图像SSIM对比
4.3 与文献[7]方法的对比
改进方法与文献[7]方法性能对比结果如表4所示,Video1和Video2表示非独立视点的编码性能。

表4 改进方法与文献[7]的BDBR对比
由表4可以看出,改进方法比文献[7]方法在Video1中平均提升0.25% 的BDBR增益,在Video2中平均提升0.9%的编码增益,编码性能更好。
4.4 并行化实现计算时间及性能分析
改进方法在阵列处理器上的并行编码时间和串行编码时间之比如表5所示,可以看出,并行化后平均编码时间减少了约8倍,提高了算法的编码速度,减少了编码时间。
采用Virtex-6的XC6VLX550T 现场可编程门阵列(field programmable gate array, FPGA)芯片在集成软件开发环境(integrated software environment,ISE)下进行综合测试,采用90 nm进行逻辑综合(Design Compiler,DC),分别对比改进方法与其他方法的计算时间、频率和功耗,结果如图6所示。
从表6中可以看出,文献[15]方法中的资源占用量高于改进方法,最高硬件频率低于改进方法;文献[16]方法的工作频率和改进方法基本相当,但是资源消耗是改进方法的2倍多;文献[17]方法的硬件工作频率为175 MHz,稍低于改进方法,但是其查找表(look up table,LUT)消耗却是改进方法的4.7倍。文献[18]方法的工作频率和改进方法相同,但整个设计规模却是改进方法的3.6倍,占用了更多的硬件资源。文献[19]方法的整个设计规模占用5.098 M门数,资源占用过高,改进方法的工作频率也是其3倍。因此,改进方法在硬件性能方面可以达到工作频率和占用资源的相对平衡,性能相对较高。

表5 改进后视差矢量方法的编码时间

表6 4种方法运算性能比较结果
5 结语
改进的候选块视差矢量快速获取方法,通过重新组合空域候选块,得到最优空域候选块与时域候选块的视差矢量,再均值计算得到最终视差矢量。整合该方法可并行部分,在视频阵列处理器上进行并行化实现,减少编码时间。实验结果表明,改进方法不但提高了视差矢量的精度,而且减少了编码时间,提高了整体的编码效率;在硬件性能方面可以达到工作频率和占用资源的相对平衡,性能相对较高。
