改进最小二乘变点识别法在负荷分解的应用
2019-06-27
(华南理工大学 电力学院,广州 510000)
0 引言
非侵入式负荷监测分解[1-2](Non-Intrusive Load Monitoring,NILM)以最小的安装维护成本,将总功率曲线分解为单独电气设备的功率曲线,实现了对用户用电行为的捕捉,有利于制定电网运行计划,也能为消费者找到最优的用能方式。在基于暂态过程的NILM方法中,变点识别的准确性和鲁棒性[3],对于正确捕获设备启/停时刻,截取设备暂态信息起到关键作用,从而为特征提取与负荷识别的准确性提供充分的保证[4]。以往NILM的研究多关注于负荷印记的种类,以及识别负荷的方法,却忽略了变点检测的重要性。但随着用电设备日益多样化,特别是多状态型、连续变化型负荷的增多,变点检测方法的抗干扰能力和精确性,对NILM显得更为重要。
变点,即一段数据中的异常点,在负荷分解中则定义为负荷的开关事件。变点识别最早由陈希孺教授提出[5],经过几十年的发展,目前在信号处理的领域已经有较为成熟的应用。然而,在非侵入式负荷分解方面,变点识别的应用尚不广泛。文献[6-7]对于变点的检测仅仅依靠对于负荷总有功功率的变化量,然而这对于大功率电器与小功率电器混合运行时的检测效果比较差。文献[7]提出了利用最优化算法来实现对不同负荷组合的运行状态的识别,但只针对于负荷稳定运行时的工作状态。文献[8-9]提出了基于最大似然估计的思想来检测变点,即认为变点的前后服从两个不同的分布,它们的统计量会有显著的差异,从而达到识别变点的目的。然而最大似然估计的方法需要估计变点前后的分布参数,而目前对于变点前后的稳态功率所服从的分布尚不能有一个准确的定论。
最小二乘(Least Square, LS)法最早是由勒让德(A.M.Legendre)于1805年提出[10]。它不须对模型中的随机误差的分布有特定的假设, 且计算尚不很复杂,准确度高。而非侵入式负荷分解中的变点识别的前后分布参数未知,但可视作负荷的稳态运行,可以构建均值模型;另一方面,其计算量小,计算速度快,可以实现在线提取负荷暂态特征和负荷数据的传输。
然而随着用电负荷多样化,单纯地利用最小二乘法计算统计量无法应对大小功率负荷混合,连续变化型负荷等复杂的情况。而且在较高采样频率下,直接计算最小二乘法计算量非常大,这大大影响了负荷暂态特征提取的实时性。因此本文提出了基于模拟退火寻优方式的改进最小二乘法,通过最优化算法,能快速寻优,从而节省大量的计算成本。而且考虑到上述多电器同时运行时的复杂情况,提出了自适应阈值,从而确保较高的识别率。
1 改进最小二乘法
1.1 均值变点模型
在用电设备进行启/停或发生状态切换时刻前后,总用电负荷的电气量会发生剧烈的变化(例如功率,电流)。这个过程定义为一个事件,且视为暂态过程。在这个过程前后一小段时间内,可看做两个稳态阶段,其电气量不会发生剧烈变化,可认为前后两个稳态分别服从两个分布,且两个分布的均值有较大变化,但方差变化较小,这定义为均值变点模型[11]。
设有一段时间总负荷数据X1,X2, …,Xn,n为样本总量。假设其有q个变点,q< Xi=mi+ei,i=1,2,...,n (1) μ1=…=μq(1)-1=M1,…,μq(q)=…=μn=Mq+1 其中:μ为每个X所服从分布的数学期望,而q个变点将样本分为q+1个区间。M为每段区间内的平均值。理想情况下,如果Mi≠Mi+1,则认为是一个真正的变点。 ei为随机误差 , 假定为相互独立,数学期望为0,方差σ2<∞。 最小二乘法的目标函数为:确定q个变点的具体位置,使得总目标函数T最小。 (2) (定义Xq0=X1,Xq(q-1)=Xn) 接下来需要确定每个q的位置,从而确定T的最小值。由于样本数据庞大,且有多个变点,无法直接通过求微分等符号数学手段求出,直接计算其数值解又需要花费太多时间。因此采用启发式搜索的模拟退火算法(Simulated Annealing, SA)。 模拟退火算法对初值不敏感,而且不容易陷入局部最优的陷阱,收敛速度较快。它的核心是Metropolis准则和退火过程两部分。Metropolis采用概率来接受新状态,而不是使用完全确定的规则。假设前一状态为x(n),系统受到一定扰动,状态变为x(n+1),系统能量由E(n)变为E(n+1),定义接受概率为P: (3) 当状态转移之后,如果能量减小,那么转移被接受(P=1)。如果能量增大,就说明函数偏离全局或局部最优更远,此时进行概率操作,在[0,1]区间内产生一个随机数ξ,如果ξ Metropolis保证了算法能搜索到全局最优解,但直接使用Metropolis会导致寻优的速度太慢,以致于失去了最优化算法的意义,其关键在于退火参数的选择。本文选择指数式下降温度的退火控制策略。使得算法不至于退火太快,导致算法在局部最优即结束迭代。另外,为了减小不必要的搜索时间,提高算法效率,设定当寻优的结果趋于稳定时终止迭代。 检验原假设H0: 不存在变点;H1:存在变点。针对这个问题,引入样本未除以自由度的方差: (4) 随后将样本随机分成两部分,前一段有j-1个数据,后者有n-j+1个数据。然后计算这两段数据的方差并求其和: (5) 阈值C由概率论中的中心极限定理[12]得到: C=σ2(2loglogn+logloglogn-logπ+xa) (6) 一般情况下分布σ2未知,因此未知,所以采用一个相合且渐进无偏的估计来代替[13]: (7) 由此计算得到自适应的阈值C进行检测,可以使假设检验有α的检验水平。 本文提出的变点识别方法以负荷有功功率为识别对象。在变点识别中负荷的有功功率是最为明显的特征,不像无功等其他特征,电阻性的负荷开/关则不会产生变化,从而干扰了算法的识别。具体算法流程如图1所示。 图1 变点识别算法流程 算法的核心在于两个循环,第一个循环检测每个窗口变点数目,并给出粗略的变点时刻。第2个循环针对于假设:“只有一个变点”的区间进行检验,以得到精确的变点时刻。 为了利用最小二乘法来估计窗口内的变点数目,首先先确定窗口长度winlen和窗口内至多有q个变点。q应取得相当小(减少算法计算量),相对于窗口长度而言,但q又需满足大于变点个数。在本文中,选取q=5。 接下来,对于q从1到5的情形,分别由公式(2)计算T1min-T5min,考虑到窗口内没有变点的情况,定义没有变点的目标函数T0min为窗口数据中未除以自由度的方差。 为了求解对应于T1min-T5min的变点位置M1-M5,本文采用最小二乘-模拟退火算法(LS-SA),即采用模拟退火方式来快速寻找LS的最优解,其流程如表1所示。 表1 LS-SA算法 例如在电动机型负荷启动曲线中,会产生较大的过电流,随后又缓慢下降到正常电流水平,导致误识别出负变点。 在搜索到各个q值对应的Mq和Tqmin之后,接下来寻找正确变点数目。 以在SA算法得到的T1min-T5min以及T0min,显然T0min≥T1min≥…≥T5min。由公式(2)可以看出,在变点数q 这样问题转化为寻找Tqmin序列变化的拐点。这里采用一个比值K=Tqmin/Tq-1min,目标是寻找到刚好不满足K>K0的最小的变点数目q。即小于q时满足该不等式,否则不满足。K0=1.1,为比较阈值。 在根据上一个循环算法A能得到变点粗略的位置,对于复杂负荷开关事件往往会误识别出“变点”。在连续变化型负荷运行中,由于其功率连续变化,在算法A求解最优变点数目时,也往往会将其误识别。因此本文采用最小二乘-假设检验法(Least Square-Hypothetical Test, LS-HT)对识别的变点进行检查。 对其划分时间段,使得每段窗口数据中至多含有一个变点,且有足够多的样本数目。接下来进行假设检验,流程如表2所示。 表2 LS-ST 进行假设检验不仅可以对上一个循环的最优化算法的结果进行检验,以防止多识别变点的情况;而且最优化算法往往只能给出个在精确解附近的相似解,但后续的假设检验针对于只有一个变点的区间,再次运用最小二乘法可以准确的确定变点的时刻。 本文采用的监测设备为广州贯行电能技术有限公司的高级全信息采集单元CEIU-S-01,如图2所示。CEIU为一款具备双向通信的集成多功能电能计量仪、电能质量监测仪、周波表、故障录波等装置全部功能的智能化终端装置。将其通过网线连接至局域网的电脑,即可实时获得测量的数据。 图2 CEIU量测单元电气图 CEIU拥有7个通道接入测量数据,包括3相电压,零序电压,三相电流,输入电源为市电220 V,本文采用其中一相电压、电流作为实验测试。其电压变比kU=5928256*515.0,电流变比kI=5928256*10.32。采样频率为8 kHz,即每个周波160个点。其采用基于UDP通信协议Modbus隧道的通信方式将电压、电流波形数据向外发送。 本文通过图3所示非侵入式负荷分解测量装置获得了实验所需的数据。测量装置右边通过插头接入电源,电源通过端子排分流,一路供给CEIU用电,另一路通过电流互感器,供给负荷用电。电流互感器二次侧出线和连接负荷的插座引出线,作为测量的电流和电压信息接入CEIU,CEIU最后通过网线将测量到的数据发送送入电脑,以供后续变点识别分析。 图3 非侵入式负荷测量系统 本文选取几种常用电器(空调,微波炉,笔记本电脑,灯管,热水壶等)进行30次测量,采样周期T=0.02 s,每次每种家电运行时间4 min得到各电器运行曲线如图4所示。 图4 实验家电运行曲线 由有功功率运行曲线可以看出,负变点较好识别,负荷关闭时,不像启动过程,总有功功率总是瞬间减小,可以视作无暂态过程。然而在负荷启动时,则情况较为复杂,根据其负荷启动时暂态功率的情况分为三类:Ⅰ,Ⅱ,Ⅲ型负载。各家电负荷特征如表3所示。 表3 实验家电特征库 1)Ⅰ型负载:这种负载以电阻性负载为主,其变点识别比较简单,跟一般的用电负荷关闭时类似,其功率变化很快,可视作无暂态过程。 2)Ⅱ型负载:这类大部分涵盖了电动机类型的负荷,其启动过程有明显的暂态过程,在启动瞬间会产生较大的过电流。以空调为例,空调压缩机在启动过程中有较大的过电流,随后立马下降,然后其功率P再缓慢上升直至稳定。 由空调启动曲线可以看出,在空调启动时会有很大的过电流(功率)产生,而且如果只是检测功率变化ΔP,则会误识别出很多个变点,从而将空调启动曲线误认为是多个负荷启动事件。然而通过寻找最小二乘法的最优解并进行检验,可以排除不正确的变点。 3)Ⅲ型负载:Ⅲ型负载启动和运行曲线比较复杂,其变化较为剧烈。本文以笔记本电脑作研究,其在运行时功率会随着运行模式变化其ΔP变化也不相同,简单的以一段时间的平均功率变化难以识别这种情况。而基于改进最小二乘法的变点识别方法,则关注于一段时间内的总误差和分段误差的差的大小,从而避免了只考虑均值所带来的偏差,就能正确识别其正确的变点时刻。 为了评价本文使用事件检测方法,采用F-score评估度量[13]。TP(True Positive)是实际发生事件也被正确识别的情况,FP(False Positive)是实际存在变点但未被识别,FN(False Negative)表示实际无负荷事件发生但被识别为变点。 接下来计算精度指标[12]:PR代表的是提取出的变点数中正确信息条数所占的比例,RE值是所有样本的信息条数中所占的比例。在评价中,P值和R值都是越高越好,但事实上这两者在某些情况下是矛盾的,因此,就需要综合考虑二者,FM值就是两者的综合指标。定义: PR=TP/(TP+FP) (10) RE=TP/(TP+FN) (11) FM=2×(PR×RE)/(PR+RE) (12) 本文对实验家电各进行30次开关测量,即TP+FP=60,选取采样周期T=0.02 s,窗口长度winlen=600,即12 s长度的时间,进行验证。并传入数据对算法进行验证,得到的结果如表4所示: 表4 某商业写字楼负荷识别结果 从表4来看,I型负荷最为简单,其变点基本上能识别出来;而II型负荷由于暂态过电流的存在,使得FN≠0,即误识别出一些“变点”;而在III型负荷中,虽然其负荷变化较为剧烈,但本文提出的算法识别率还是能达到70%以上。 本文提出了一种基于均值变点模型的识别方法,通过滑动窗口,利用最小二乘法计算相关目标函数,以确定变点的个数。此算法简单、抗干扰能力强。通过实际数据实验表明它能够自动检测、辨识负荷开关而产生电气量变点,从而为NILM算法提供准确的负荷事件识别,为之后负荷特征的提取和识别打下坚实的基础。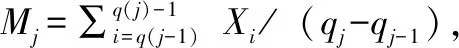
1.2 模拟退火算法

1.3 “变点有无”假设检验



2 变点识别算法
2.1 变点识别算法流程

2.2 LS-SA算法

2.3 LS-HT算法

3 算例仿真分析
3.1 非侵入式负荷测量系统




3.2 算例分析

4 结论
