NUMA架构下数据热度的内存数据库日志恢复技术*
2019-06-19阿卜杜热西提热合曼乔百友韩东红
吴 刚,阿卜杜热西提·热合曼,李 梁,乔百友,韩东红
1.东北大学 计算机科学与工程学院,沈阳 110819
2.南京大学 计算机软件新技术国家重点实验室,南京 210093
1 引言
近年来,随着互联网技术的快速发展,越来越多的网络应用需要能够支持大量用户的并发访问以及高吞吐量和低延时等特性。传统的磁盘数据库由于将所有数据放在磁盘上进行管理,慢速的磁盘I/O限制了数据库的性能。而内存数据库的数据存储与管理都在内存中进行,因此综合性能有了很大的提升,特别适合此类对性能要求极高的场合[1-4]。
为了保证数据库的完整性,内存数据库通常使用日志结合检查点的故障恢复机制[5-6]。日志记录方面,ARIES类日志[7]和命令日志[8]为两大日志记录方式。其中,命令日志是专门为内存数据库而设计的粗粒度、轻量级的日志记录方式。它的优点是产生的日志小,I/O开销低。因此这种日志记录方式非常适合内存数据库。
但是,由于命令日志记录的事务之间存在复杂的依赖关系,故障发生后无法直接进行并行恢复[9],很难发挥好多核处理器的并行处理性能,恢复速度较慢。针对该情况,现有的解决办法是,在开始恢复之前,先分析日志记录中事务之间的依赖关系,并求出最优的并行执行计划,再开始并行恢复[10]。显然这样可以加快命令日志的恢复速度。但是,这需要在恢复之前遍历一遍日志内容。由于内存数据库的吞吐量很高,短时间内都能产生很大的日志数据。因此,遍历一遍日志的时间是不可忽视的。
相对于传统对称多处理器架构的多个CPU通过单一内存控制器访问内存的体系架构,在非统一内存访问(non-uniform memory access,NUMA)体系架构中,内存和多核CPU分布在多个节点上,CPU通过节点间的高速链路可以访问系统内所有节点的内存[11]。因此这种架构具有很好的可扩展性。在这种架构中,相比访问远端内存,CPU访问本地内存的延迟低,带宽高[12]。在本文的实验部分所用NUMA体系架构的服务器中,经实验测得,CPU访问远端内存的延时为251.1 ns,是访问本地内存延时138.2 ns的1.82倍。
最近研究显示,在NUMA体系架构上优化的内存数据库系统和内存存储引擎中,面向数据而非面向事务的设计架构是一种主流思想[13]。面向事务的设计架构中,事务处理所需要的数据往往会分布在不同的节点[14]。在NUMA架构中使用面向数据的设计架构可以避免这种跨节点访问数据带来的延时。在面向数据的设计架构中,通常的做法是将内存数据库中的每一条数据按键的范围平均划分到不同节点的内存区域中,每个节点的CPU上创建一个线程负责执行本区域内数据的添加、删除、修改、查找等操作[15]。这种策略有效地保证了各个节点所处理数据的均衡性,但忽略了数据访问的不均衡性,即忽略了数据的热度。
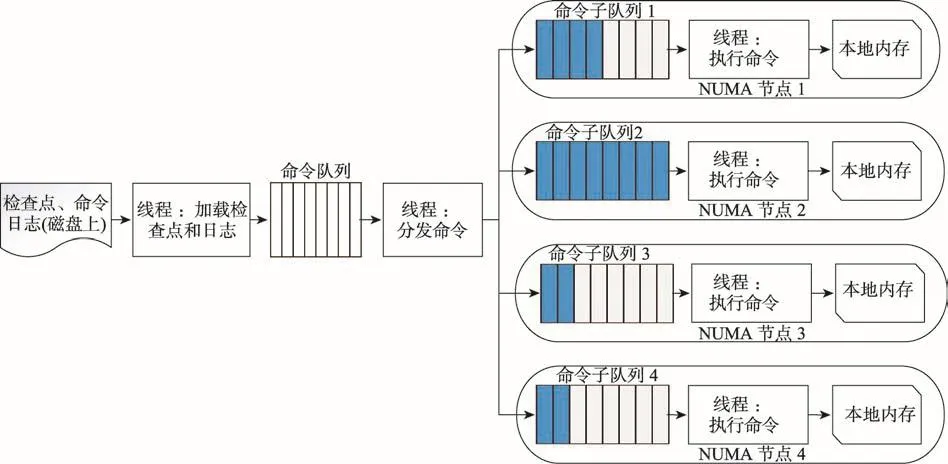
Fig.1 Framework of command log recovery algorithm based on data popularity图1 基于数据热度的命令日志恢复算法框架
通常情况下,数据库中的数据的访问符合正态分布规律。因此,一定会出现某些数据被频繁访问的情形。在故障恢复时这种数据划分策略显露出其弊端。即如果某些数据的访问次数远高于其他数据,在故障恢复阶段负责这些数据的线程的工作负载将会加重。划分到那些被频繁访问的数据的命令子队列中的命令明显多于其他命令子队列。如图1所示,命令子队列中命令数目(蓝色示意)呈现不均衡状态。由于总的恢复时间由最后执行完成的线程来决定,因此这种负载不均衡性显然增加了恢复时间。
因此,从这个角度出发,为了更好地利用硬件性能,认为在NUMA体系架构上针对命令日志恢复进行优化是很有必要的。
在本文中,针对NUMA体系架构的特性设计了NUMA体系架构下的基于热度记录的命令日志快速恢复算法。该算法的框架如图1所示。
在本文算法中,加载线程首先从磁盘加载检查点和日志数据,并将它们送入命令队列。然后,分发命令的线程使用一定策略将命令队列中的数据分发到各个命令子队列中。命令子队列的数量取决于本服务器上NUMA节点的数量。最后,执行线程不断地从所属的命令子队列中取出命令并执行,将数据添加到所在节点的内存中。本文提出的NUMA架构上基于数据热度的故障恢复策略在故障恢复时通过使各个执行线程的负载比较均衡,以此来加快恢复速度。本文的主要贡献如下:
(1)提出了基于数据操作热度的日志和检查点记录方案;
(2)设计并实现了NUMA架构上基于热度记录的故障恢复算法。实验表明,本文算法的恢复速度比常规划分策略快,恢复速度最高提升了19%。
本文工作安排如下:第2章介绍具有热度记录的日志和检查点记录方案;第3章介绍故障恢复算法;第4章为实验部分;第5章为结束语。
2 具有热度记录的日志和检查点
首先提出数据热度的定义。
定义1设D={d1,d2,…,dn}为数据记录的集合,C={c1,c2,…,cn}为与D中一一对应的数据记录的被访问次数的集合,τ为阈值。如果存在cn>τ,cn∈C,则与之对应的数据记录dn∈D为热数据;反之,则为冷数据。cn越大,数据dn的热度越高。
在实验中模拟了Key-Value型数据库的操作过程。在本文的策略中,数据库执行过程中会记录每一条数据记录的访问次数,并保存在一个Map结构中。在本文的算法中,日志记录的格式如图2(a)中所示。在日志内容中除了记录该数据的键和值外,还记录该数据的热度。数据记录的热度为该数据记录在最近一次检查点中所记录的操作次数。如图3所示为数据库执行过程的简易示意图。t0为完成一次一致性检查点的时刻。在t0至t1时间内数据库执行过程中,数据记录每被访问一次,就将该数据的操作次数自增1。在t1至t2时间内检查点制作过程中,将该数据的被访问次数作为该数据的热度跟数据记录一并传输到磁盘中。从t2开始到下一次检查点之前,日志中数据热度即为前一次检查点时该数据的操作次数。如果某一数据是在此时间段内新增数据,则其热度置为零,并记录其操作次数。在t3时刻发生故障后,数据库进入恢复阶段。恢复阶段根据热度来划分检查点数据和日志数据。
在传统的一致性检查点中,只会记录包括版本号在内的头部信息以及该时刻数据库中数据的内容。由于其没有对热数据进行特殊划分,因此无法保证故障恢复时的工作负载均衡。在本文方案中,在检查点中还设置两个全局参数D和C。其中,D记录该时刻数据库中的数据记录的总数,C记录从前一次检查点到该时刻数据库的总的操作次数。在制作检查点时,这些信息将被放在检查点头部传输到磁盘中。检查点格式如图2(b)所示。
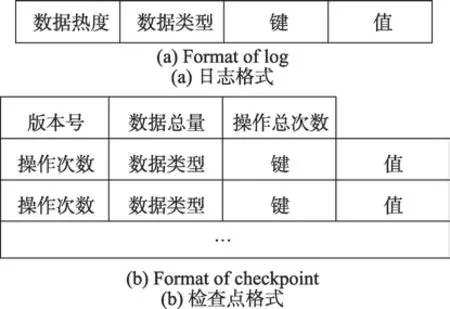
Fig.2 Log and checkpoint with popularity record图2 带有热度记录的日志和检查点
在本文的方案中,总的数据量D,总的操作次数C以及每一个数据条目的操作次数均使用64位无符号整数来代替。
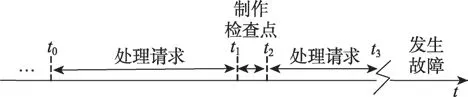
Fig.3 Database execution process图3 数据库执行过程
3 故障恢复算法
3.1 整体介绍
首先介绍命令日志恢复实验的算法框架,如图1所示。首先加载线程会从磁盘中加载检查点数据到命令队列。检查点数据加载完毕后,向命令队列发送一条结束指令,以表示检查点数据加载完毕。随后,加载线程加载命令日志数据,并将其数据追加到命令队列。日志数据加载完毕后,加载线程同样会发送一条结束指令到命令队列,表示加载日志数据结束。就此,加载过程结束。
然后,分发命令的线程用热度记录分发策略将数据从命令队列中取出并送入相应的命令子队列。命令分发算法为本程序的核心算法,而且检查点数据的分发算法与日志数据的分发算法有些不同,两种命令分发算法以加载时的结束指令为分界。命令分发过程的流程图如图4所示。命令分发算法单独做介绍。
在分发命令结束后,各个NUMA节点上的执行命令的线程不断地从相应命令子队列中取出指令并执行,将数据恢复到本地内存中,每一个执行命令的线程为Redis进程。如此一来,数据库恢复过程结束,数据库恢复到了故障发生前的一致性状态。
下面介绍检查点数据和日志数据的命令分发算法。
3.2 检查点数据的分发算法
由于检查点数据具有热度记录,因此可以根据数据的热度记录采用与NUMA常规方案不同的方式分发数据。
首先,计算数据热度的阈值τ。此处可以根据检查点数据的头部记录中检查点数据记录的总量D和操作总次数C,以及设定的影响因子α,得到τ=(C/D)×α。则根据数据热度的定义,操作次数大于τ的数据记录属于热数据。
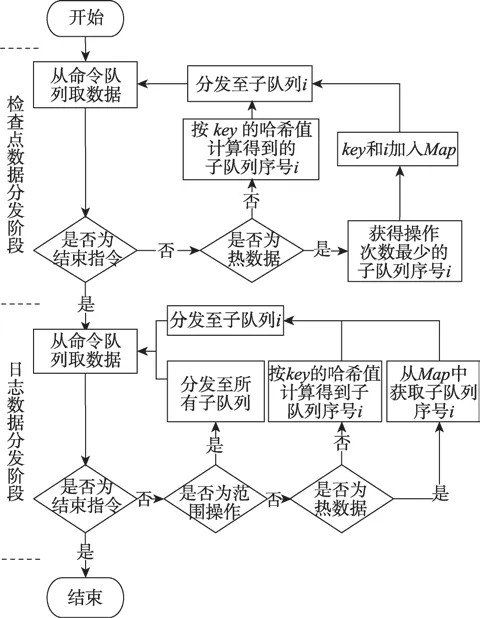
Fig.4 Command distribution thread flow chart图4 命令分发线程流程图
同时,每一个命令子队列也会记录该子队列中的数据的操作总次数。如果从命令队列中取出的数据记录是热数据,则动态地将其分发到当前操作总次数最少的命令子队列,并将该热数据的key和分发到的命令子队列的序号i保存在为热数据创建的哈希表Map中。否则,根据其key值计算出哈希值,并分发到该哈希值相应的命令子队列中。当从命令队列中取到结束指令时,检查点数据分发结束。该算法如算法1所示。
算法1检查点数据的命令分发算法
输入:Ci,第i个线程所持有的数据在检查点中记录的操作次数之和;C,检查点中存放的所有操作次数之和;D,检查点中所存放的数据条目数量;α,影响因子;Q,命令队列;Qi,命令子队列;Hi,命令子队列Qi在堆H中的位;Map,哈希表,键为热数据的键,值为其分配的命令子队列的序号。
输出:命令子队列Qi。
1.Distribute_data_in_checkpoint():
2.τ=(C/D)×α
3.whileDATA=Q.top_and_pop:
4.ifDATA.N>τ:
5.i=min(H)
6.Map[DATA.key]=i
7.else:
8.i=hash(DATA.key)%H.size()
9.H[Hi]+=N
10.Qi.push(DATA)
3.3 日志数据的命令分发算法
加载完检查点数据后,数据库恢复到了故障发生前最近一次一致性检查点完成时的状态。检查点数据也就是数据库在该检查点完成时刻的数据库中的数据。随后的日志为对这些数据的各种操作。日志恢复期间将所获取到的命令日志按序执行。此过程中,有可能会重复更新某条数据,且有可能增加新数据或删除已有数据。
日志恢复期间的命令分发算法如算法2所示。
首先从命令队列Q中获取命令。命令有可能是范围操作,如果是范围操作,则向每一个命令子队列发送此命令;如果不是,再判断其是否为热数据的访问操作。如果是,则从哈希表Map中取其分配的命令子队列序号i;如果不是热数据的操作,则计算其哈希值,得到其分发的子队列的序号i。最后将其分发到命令子队列i中。
算法2命令日志数据的命令分发算法
输入:Q,命令队列;Qi,命令子队列;Map,哈希表,键为热数据的键,值为被分配的命令子队列的序号。
输出:命令子队列Qi。
1.Distribute_data_in_log():
2.whileCMD=Q.top_and_pop():
3.ifCMDis a range command:
4.Q[every].push(CMD)
5.ifCMD.N>τ:
6.QMap[CMD.KEY].push(CMD)
7.else:
8.Qhash(CMD.KEY).push(CMD)
4 实验及结果分析
4.1 实验环境
实验在内核版本为4.13.0的Ubuntu 16.04系统中实现NUMA架构下基于热度的内存数据库日志恢复算法。所用主机是配有4个NUMA节点的服务器(结构见图5)。该服务器的详细配置如表1所示。
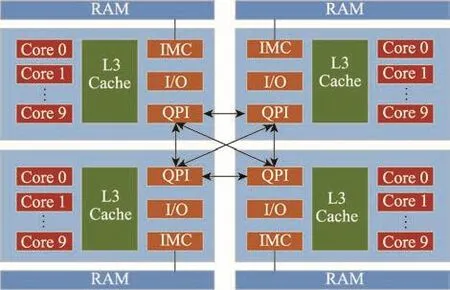
Fig.5 Server structure图5 服务器结构
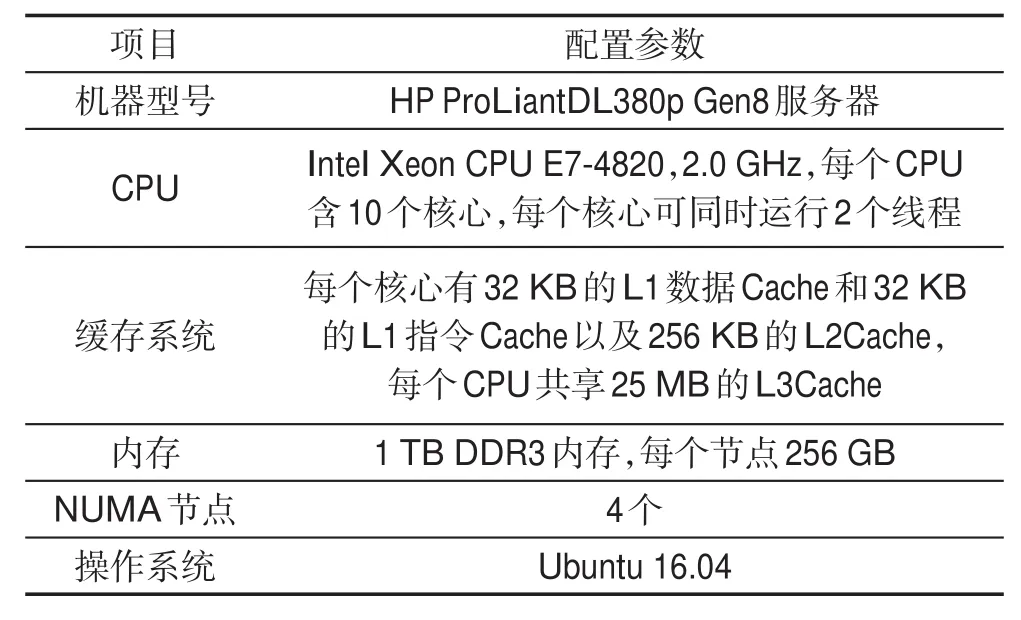
Table1 Detailed server configuration information表1 服务器详细配置信息
4.2 实验负载参数
实验中所用命令日志和检查点数据另由一个程序产生,并保存在磁盘中。其中,数据记录的键为64位无符号整型数组成的字符串,值为大小为512 Byte至1 024 Byte的随机字符组成的字符串。命令日志中数据的键由检查点数据中数据记录的键按正态分布规律访问而得,符合数据库的日常访问规律。如图6所示,横坐标的整数值表示数据记录的键的值,数据记录的键互不重复,而且相邻两个键相差为1,纵坐标表示该数据的访问次数,访问次数超过τ的数据为热数据。这样,检查点中数据记录的数量可理解为图6中左右边界A和B中整数点的数量,日志数量为这些离散点的纵坐标值之和。实验中通过调整检查点数据记录的数量、命令日志数量、影响因子α以及正态分布函数的参数σ2来产生不同的实验数据。
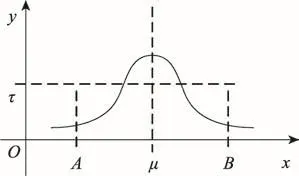
Fig.6 Key access rules in checkpoint data图6 检查点数据中键的访问规律
4.3 命令日志恢复实验
4.3.1 控制检查点数据记录数量不变
实验1中恢复所用数据是通过控制检查点数据记录的数量不变,针对不同的σ2产生的。该实验中的实验负载参数如表2所示。σ2会影响正态分布曲线的陡峭程度。
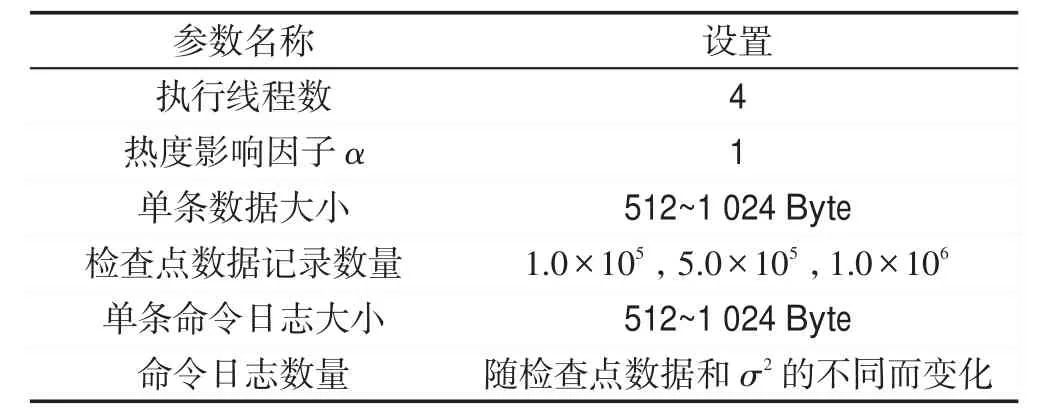
Table2 Experiment 1 load parameters表2 实验1负载参数
由于控制检查点数据记录的数量不变,数据记录的键的分布区域的边界已固定,σ2越小时,正态分布曲线越陡,产生的日志数量也越多,因此恢复所需时间也就越多。图7为检查点数据记录的数量为1.0×105,命令日志恢复实验。其中横坐标为与其访问规律相关的参数σ2,纵坐标为恢复时间,副纵坐标表示检查点数据记录中热数据记录所占比例。从图中可以看出,在本次实验中,虽然所产生日志数量各不相同,但针对每一数据,基于热度记录的内存数据库恢复策略比NUMA架构的常规恢复策略要快,而且随着σ2的增大,热数据所占比有增长的趋势。图8和图9分别为检查点数据记录数量为5.0×105和1.0×106时的内存数据库日志恢复实验。这两个实验中能发现同样的规律。
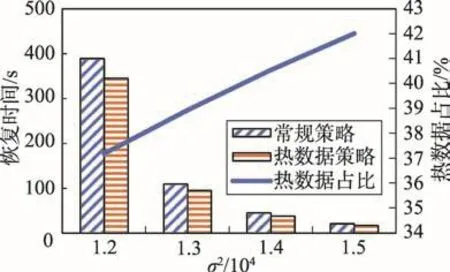
Fig.7 Recovery time when checkpoint data number is1.0×105图7 检查点数据记录数量为1.0×105时恢复时间
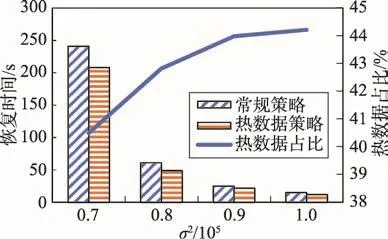
Fig.8 Recovery time when checkpoint data number is5.0×105图8 检查点数据记录数量为5.0×105时恢复时间
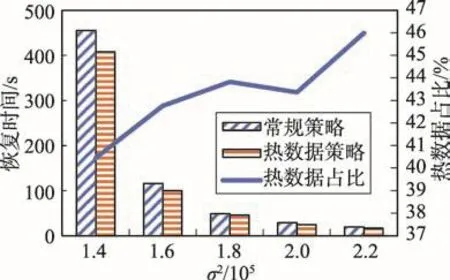
Fig.9 Recovery time when checkpoint data number is1.0×106图9 检查点数据记录数量为1.0×106时恢复时间
为了展示检查点数据记录数量不变时,不同的σ2产生的日志大小,实验中获取了检查点数据记录数量为1.0×106,日志大小随σ2而变化的情况,如表3所示。从表中可以看出,σ2越小,所产生的日志数据越多,恢复所需时间也将随之越多,符合图中所示实验结果。

Table3 σ2and log size when the number of checkpoint data is1.0×106表3 检查点数据数量为1.0×106时σ2与日志大小
4.3.2 控制日志大小不变
实验2中恢复所用数据是控制日志数量不变,调整σ2的大小而产生的。该实验中,实验负载参数如表4所示。由于日志数量不变,为了产生数量固定的日志数据,图6中检查点数据的键的左右边界会随着σ2的增大而增大。

Table4 Experiment 2 load parameters表4 实验2负载参数
图10和图11分别为日志数量为1.0×107和5.0×107时的内存数据库日志恢复时间图。此实验中日志数量保持不变,检查点数据记录的数量随σ2的变化而不同。两张图的恢复时间的变化趋势基本类似,即σ2较小时,两种恢复策略的恢复时间差值较大,热数据策略相对常规策略的恢复速度的提升比例较大,最大提升为19%。随着σ2的增大,两种策略的恢复时间越来越接近。本实验中由于日志数量保持不变,在σ2较小时,数据访问规律的正态分布曲线比较陡,访问的数据比较集中。此时,各个执行恢复操作的线程的负载不均衡度越高。基于热度记录的恢复策略可以很好地做到负载均衡。此时,恢复性能的提升较高。随着σ2的增大,数据库对数据的访问越来越分散,正态分布曲线越来越平缓,导致NUMA架构下常规策略的执行恢复操作的线程的负载越来越趋向均衡。因此,常规策略的恢复时间会越来越少。热数据策略为负载均衡所做的开销逐渐成为劣势。因此,随着σ2的增大,热数据策略的恢复性能提升比例越来越小,两种策略的恢复时间越来越接近。图中,σ2的值为1.0×106时的两种恢复策略所用时间都明显高于前面几组的恢复时间。这是因为,在实验2中由于固定日志数量不变,当σ2较小时,所产生的检查点数据记录的数量很小,加载检查点数据的时间对整体恢复时间来说可忽略。但从σ2的值为1.0×105开始,检查点数据记录的数量为日志数量的5.2%,σ2的值为1.0×106时为37.3%。此时的检查点数据的加载时间会导致整体的数据库恢复时间增大。
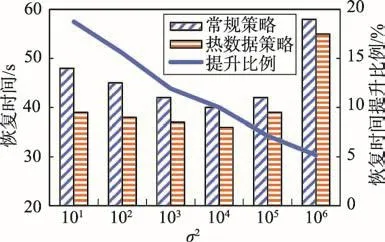
Fig.10 Recovery time when the number of logs is1.0×107图10 日志数量为1.0×107时的恢复时间
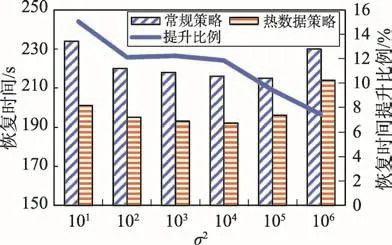
Fig.11 Recovery time when the number of logs is5.0×107图11 日志数量为5.0×107时的恢复时间
5 结束语
针对在面向数据设计的内存数据库系统中,NUMA体系架构环境下进行日志恢复时,因恢复线程负载不均衡而导致的恢复速度慢的问题,本文提出了基于数据热度的命令日志恢复算法。该算法利用数据的访问频次将数据分为热数据和非热数据,将热数据分配给相对空闲的恢复线程,有效解决了恢复线程负载不均衡的问题。实验表明,在数据访问相对集中时,基于数据热度的命令划分方案比NUMA架构的常规方案快,最高快19%。可以得出,在NUMA架构下面向数据设计的内存数据库系统中,对数据的访问频率相对集中的数据库系统中,适合使用本文提出的基于热度记录的命令日志恢复策略,相反则适合使用NUMA架构下的常规的平均划分策略。在未来的研究中主要解决的问题是在NUMA体系架构环境下,面向数据设计的内存数据库中,提高数据的本地性,减少CPU跨节点访问远端内存中的数据的问题。
