GPU无锁跳步哈希表
2019-06-19孙建伶
张 娟,孙建伶
1.浙江大学 计算机科学与技术学院,杭州 310027
2.阿里巴巴-浙江大学前沿技术联合研究中心,杭州 311121
1 引言
图形处理单元(graphics processing unit,GPU)具有卓越的并行加速能力。将通用内存索引结构应用到GPU之上成为了一个新的研究方向。目前针对GPU优化的内存索引结构还较少,只有很少的完全并发且可动态更新的结构能够适应GPU。
完全并发的GPU数据结构的应用场景更加广泛,无锁特性又可以解决传统基于锁的方法由于大量驻留线程对资源的争用而造成的低效率。本文设计并实现GPU完全并发且可动态更新的无锁跳步哈希表——GPU无锁跳步哈希表(GPU lock-free hopscotch Hash table,GLHT)。
目前尚未有GPU完全并发且可动态更新的跳步哈希表,但是有少许GPU其他哈希表设计。GPU其他哈希表设计主要分为两个方向:静态哈希表、完全并发且可动态更新的哈希表。据本文所知,虽然已有多种有效的GPU静态哈希表(例如Alcantara等人设计的杜鹃哈希表[1]),但完全并发且可动态更新的GPU哈希表目前只有Misra和Chaudhuri实现的无锁链式哈希表[2]和Ashkiani等人设计的Slab Hash[3],并且文献[2]中的哈希表还不是完全动态的。
GLHT的基础数据结构是跳步哈希表[4]。跳步哈希表的插入操作保持数据的紧凑。当发生数据冲突时,新数据插入到哈希槽(哈希槽即指键原始应该被哈希到的槽)随后的H个槽,这H个槽称为当前槽的邻域,H是用户设置的常数。每个槽关联一个由H+1个bit组成的bitmap,指示当前槽和后续H个槽中的项是否是最初哈希到当前槽的项。若某个槽的项本来应该哈希到前面的槽,则称这个槽“从属”于前面的那个槽。图1是键v插入跳步哈希表的过程,白色表示空槽,灰色表示槽中有项,该哈希表的H为3。键v本应哈希到槽6,但是发生了数据冲突。于是,首先通过线性探测找到距槽6最近的空槽13。如果两个槽的距离小于等于H,则可以将键直接插入到该空槽中,但是槽13到槽6超过了H的范围,因此需要按照邻域从属关系,置换它们之间的键,将空槽移近槽6。观察槽10(13-H=10)的bitmap,发现只有槽11从属于槽10,于是置换槽11的键w到槽13并更新槽10的bitmap。现在空槽为槽11,但它仍然不在槽6的邻域内,于是观察槽8(11-H=8)的bitmap,发现槽9从属于槽8,于是置换键z到槽11并更新槽8的bitmap。现在,槽9在槽6的邻域范围内了,可以直接将键v安排在槽9。通过这一系列的移位操作,跳步哈希表保证了数据与原始哈希槽的距离不会大于H,因此查找时只需检查哈希槽及其邻域中是否有目标键,若无则可确定目标键不存在,由此保证任何情况下的查找时间都是O(1)。
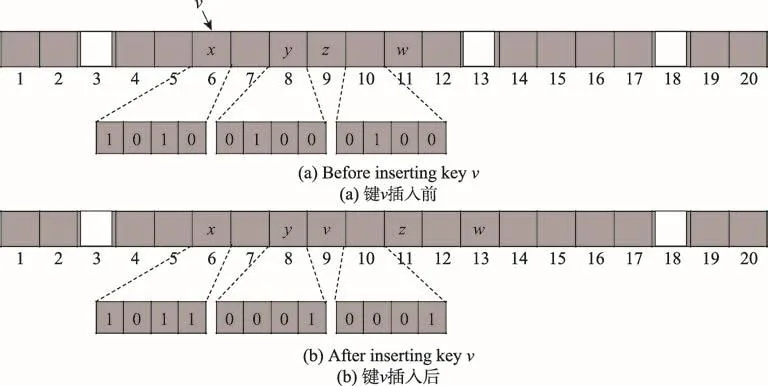
Fig.1 Insert key vinto hopscotch Hash table图1 键v插入跳步哈希表
在GPU中,若一个warp内的线程请求访问连续对齐的内存块,则会进行合并访问(coalesced access)以便最大化内存带宽。跳步哈希表的所有操作恰好都只需要并行读取连续内存范围内的哈希槽和邻域,因此可以使用高效的GPU合并访问完成读取请求。而其他哈希表,例如杜鹃哈希表[5],在插入过程中反而追求项的随机分布,自然不利于合并访问的使用。
设计实现GPU哈希表并不是直接将原有的CPU哈希表简单地放置到GPU上,不仅需要考虑GPU环境下的并发安全问题,还要结合GPU的硬件特性,实现哈希表在GPU上的并行性能最大化。GLHT的设计主要围绕两方面:
(1)warp内并行:采用warp协同工作共享策略(warp-cooperative work sharing strategy),减少程序控制流中的分支与发散,以实现对哈希表单个操作的并行加速。
(2)warp间完全并发:全局内存配合CUDA(compute unified device architecture)原子操作atomic-CAS以及特殊的并发控制策略设计,在实现完全并发和无锁特性的同时,保证了读操作的无等待特性,以实现哈希表多个操作的并发执行。
本文进行了实验评估,结果表明GLHT具有在灵活性和性能上的优势。GLHT与其他GPU静态哈希表相比,具有可以接受的构建和检索速度;与现有的CPU跳步哈希表相比,具有4~9倍的性能优势;比采取预先分配内存的GPU无锁链式哈希表[2]更加灵活,并且在写操作较多的工作负载中获得了更好的性能。
本文工作安排如下:第2章介绍GPU数据结构相关工作;第3章描述GLHT的总体设计;第4章介绍GLHT的实现细节;第5章为实验评估;第6章对全文进行总结。
2 相关工作
目前有多种GPU静态哈希表。Alcantara等人的杜鹃哈希表[1]在批量构建阶段和检索阶段都有很好的性能,但随着负载因子要求的增加,批量构建过程越来越有可能失败。该哈希表已用于CUDA数据并行原语库(CUDA data parallel primitives library,CUDPP)[6]。García等人[7]提出了一种基于Robin hood的哈希方法,他们专注于更高的负载因子并利用了图形应用程序的空间局部性,但代价是该哈希方法与杜鹃哈希相比性能有所下降。Khorasani等人[8]提出了Stadium Hashing(Stash)技术,它也是一种杜鹃哈希表设计,可以扩展为大型哈希表。它解决的重点问题是out-of-core哈希表不能完整地放进单个GPU内存中。通过将表容器存储在CPU内存中,Stash消除了将哈希表整个维护在有限的GPU内存上的限制。Stash使用了名为ticket-board的紧凑数据结构,这个数据结构引导了哈希表上的所有操作。在最好的情况下(即空表),Stash的插入操作只需要一个原子操作和一个常规的内存写操作,查找操作则至少需要两个内存读取操作。虽然各种静态哈希表的侧重有所不同,但文献[1]似乎是这些设计中具有最佳性能指标的通用in-core哈希表。
在GPU完全并发且可动态更新的哈希表研究方面,Misra和Chaudhuri[2]测试了几种已知的CPU无锁数据结构移植到GPU后的加速情况。他们实现了一个GPU上的无锁链表,并由此实现了无锁链式哈希表,这个哈希表能够支持并发的插入、删除和查找操作。但该实现实际上仍然不是完全动态的,因为在它的实验中,为将来所有的插入操作都预先分配了一个结点资源数组(必须在编译时知道),并且不能在运行时动态分配新项和释放已删除项,这就是所谓的“预先分配内存”,而本文实现的GLHT则完全不需要这样的过程,因此更具灵活性。Cederman等人[9]对各种已知的基于锁和无锁的Queue实现进行了类似文献[2]的实验,他们得出的结论是:Queue面向GPU的并行优化将有利于性能的提升。现在,人们也开发出了一些更简单的、专为GPU设计的数据结构,例如队列[10]和链表[11]。此外,graph-based算法也使用优化的GPU实现了速度的加快[12-14]。受文献[2]的启发,Moscovici等人[15]提出了基于细粒度锁的GPU友好的跳表(GPU-friendly skip list,GFSL),该工作主要考虑的是GPU的优选合并内存访问(preferred coalesced memory accesses)。
最近,Ashkiani等人[3]设计了一种完全并发的GPU动态无锁链式哈希表——Slab Hash。他们认为,GFSL无论在插入、删除还是查找操作中,都无法击败Slab Hash的性能峰值。
3 设计
GLHT通过warp内并行实现对单个操作的并行加速,通过warp间并发实现多个操作的并发执行。
3.1 warp内并行:warp协同工作共享策略
GPU运行时,各个线程块被分配给不同的流式多处理器(streaming multiprocessors,SM)执行。SM会以32个线程为一组执行线程块操作,这称为warp调度。一个warp中的线程从相同的程序计数器开始执行,但是也可以独立地进行分支与发散(branch and diverge)。如果一个warp内的线程由于判断条件的不同而进行了分支,则warp将依次执行每个线程所采用的分支路径。当所有的分支路径被执行完时,warp中的线程才会重新聚到共同路径中。
在GPU上执行一组独立操作的传统方法是让每个线程都独立处理一个操作,例如,GPU上经典的链表操作[2]。图2描绘了传统方法的执行过程,图中空白的时间块表明当线程在处理分支时,其他线程将处于等待状态。频繁的控制流发散将会严重影响执行性能,由此可知,这种传统方法并没有充分发挥出GPU线程的并行能力。
Slab Hash[3]和 warp-wide直方图计算[16],让 warp内的线程协同地并行工作,可以指定warp内线程,使用一些warp-wide指令,协同处理同一个操作,也就是将原本分配给不同线程的操作统一分配给整个warp来处理,如图3这种方法就称为warp协同工作共享策略。warp-wide指令指的是NVIDIA GPU支持的一组内建函数,可以协同warp内线程的通信过程以减少分支与发散。与传统的单线程独立处理相比,warp协同工作共享策略显著减少GPU程序中的分支与发散。
3.2 warp间完全并发:全局内存配合CUDA原子操作
如图4,虽然GLHT让warp大小的整个线程块内的线程协同地处理同一个操作任务,但不同线程块之间仍然是操作独立且完全并发。
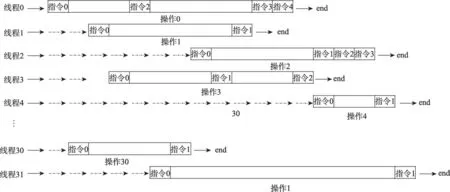
Fig.2 Traditional method图2 传统方法
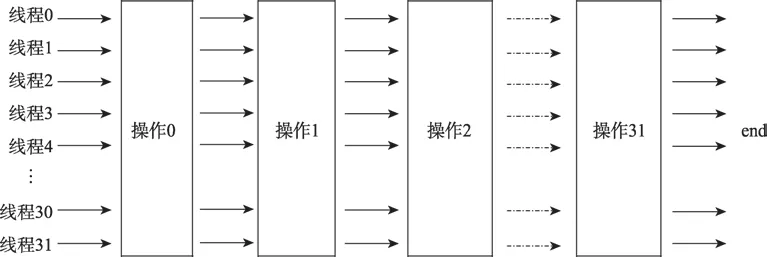
Fig.3 warp-cooperative work sharing strategy图3 warp协同工作共享策略
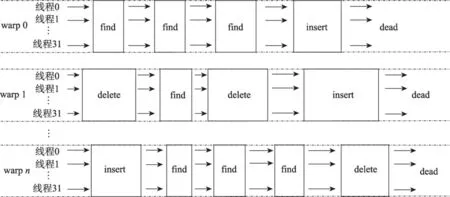
Fig.4 Fully concurrent operations between warp图4 warp间完全并发的操作
如何做到warp间完全并发,首先需要考虑操作执行在GPU内存的哪个层次。GPU的内存结构分为三个层次:可以被设备内所有线程访问的大的全局内存;每个线程块有着的更小但更快的共享内存;线程块中每个线程的本地寄存器。共享内存很小(通常为16 KB),并且它进行了分区,因此来自不同块的线程无法访问另一个块的共享内存。GPU的全局内存容量大,可供所有线程访问。由于数以百万计的线程可以执行GPU内核函数,但只有有限数量的SM存在,因此线程块需要排队等待SM。因此,除了内核函数结束的时候,并没有办法可以全局地同步所有线程。为了实现warp间操作的完全并发,GLHT通过全局内存实现各线程对所有数据状态的共享。
GLHT选择无锁乐观并发控制。这种控制方法会在访问内存资源时“乐观地”假设没有并发冲突,对数据不加锁就直接拿来用,在最后真正更新数据时再判断冲突是否发生。选择这种并发控制方法的好处:一是在GPU编程环境中,锁的设计代价非常昂贵;二是它可以减少成千上万的驻留线程对锁资源的争用,从而提高执行效率。而这种并发控制方法的缺点是,当数据冲突发生时,解决冲突的代价较大,除非冲突发生的几率很小。
常见的无锁编程一般基于原子操作。常用的原子操作是比较和设置(compare-and-set,CAS)操作。CAS操作将内存数据与给定值进行比较,只有当它们相同时,才会将该内存数据修改为新值。GLHT就用到了CUDA的CAS原子操作atomicCAS。
4 实现
GLHT的实际数据结构是一个在GPU内存中的unsigned long long int数组,而对GLHT查找操作、删除操作和插入操作的具体实现细节感兴趣的读者可自行阅读代码及注释(https://github.com/fanny2011/GLHT),本章仅作简要介绍。
4.1 拆分操作阶段
首先将插入操作拆分为不同的阶段并区分不同阶段的槽角色。拆分阶段是为了细分并发操作的粒度,而区分槽角色只是为了描述的方便。
插入操作可以拆分成find、find_empty、update和find_closer_empty四个阶段,其中find_closer_empty阶段又可以循环多个swap_value_into_empty阶段,如图5。而GLHT的删除操作则只用分为find和update两个阶段。
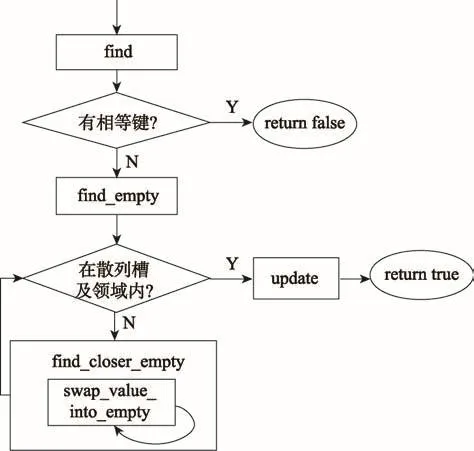
Fig.5 Phase decomposition of insert operation图5 插入操作的阶段分解
下面描述插入操作不同阶段的槽角色,先将哈希槽以角色hash_pos表示。find阶段找出哈希表中是否已有相等的键,没有则执行find_empty阶段。插入操作和删除操作的find阶段与查找操作做的是相同的事情。
find_empty阶段返回正好为空的hash_pos或后方最靠近hash_pos的空槽,若空槽为hash_pos或在hash_pos邻域内,则将此空槽以角色target表示,并执行update阶段,否则执行find_closer_empty阶段。
插入操作的update阶段将目标键通过atomic-CAS放进hash_pos,而删除操作的update阶段将target通过atomicCAS置为空,update阶段的槽角色如图6,注意target可能与hash_pos重合。

Fig.6 Slot role in update phase图6 update阶段的槽角色
find_closer_empty阶段的目标是将找到的空槽向前移动一次,find_closer_empty阶段循环多个swap_value_into_empty阶段,直到移动成功。swap_value_into_empty阶段每次对一块置换区域操作,置换区域的第一个槽以角色swap_head表示,置换区域的最后一个槽即前面找到的那个空槽。从前到后在置换区域中寻找一个“从属”于swap_head的槽,将这个槽以角色swap表示,并置换target和swap的项,置换完成则find_closer_empty阶段也完成了;但若没有找到swap,则find_closer_empty阶段将角色swap_head向后推动一个位置,并循环swap_value_into_empty阶段。find_closer_empty阶段最初将swap_head定在target前的第H个位置。swap_value_into_empty阶段的槽角色如图7所示,注意swap_head与swap可能重合。

Fig.7 Slot role in swap_value_into_empty phase图7 swap_value_into_empty阶段的槽角色
4.2 锁标记
GLHT采用乐观并发控制,在数据项上设置锁标记,操作时使用原子操作来更改这些锁标记,以达到使用原子操作锁定数据项的目的。对应于上一节所述的四个角色(hash_pos、target、swap_head和swap),GLHT设计了两种锁标记:multiple_lock和swap_lock。规定锁标记间的互斥关系及它们对并发读写操作的互斥性质,就能保证warp间操作的完全并发安全性。
multiple_lock的含义如下:
(1)当其标记在非空槽时,表示该槽正处于插入或删除操作的update阶段的hash_pos角色。
(2)当其标记在空槽时,有两种可能:①该槽正处于swap_value_into_empty阶段的target角色;②该槽正处于插入操作的update阶段的target角色。
swap_lock的含义如下:
表示该槽正处于swap_head角色,或表示该槽正处于swap角色。
两种锁标记均为排他锁标记,即当槽带上上述标记后,不能再带上另外的锁标记,也不能重复带上相同的标记。
GLHT查找操作不涉及对锁标记的操作,只读取锁标记的状态,根据hash_pos中的项是否带有multiple_lock锁标记(项带有的swap_lock可以忽略),决定重读或继续下一个步骤。
删除操作在update阶段,若发现hash_pos带有任何锁标记,就需要从头重试整个操作;否则,为hash_pos带上multiple_lock,以表明本操作对该hash_pos及其领域拥有了操作权,其他操作发现锁标记的状态改变后只能重试。然后,删除操作将target改变为空槽。最后,操作收尾,取消hash_pos上的multiple_lock。期间,任何一个原子操作失败后,都需要清理锁标记并从头重试整个操作。
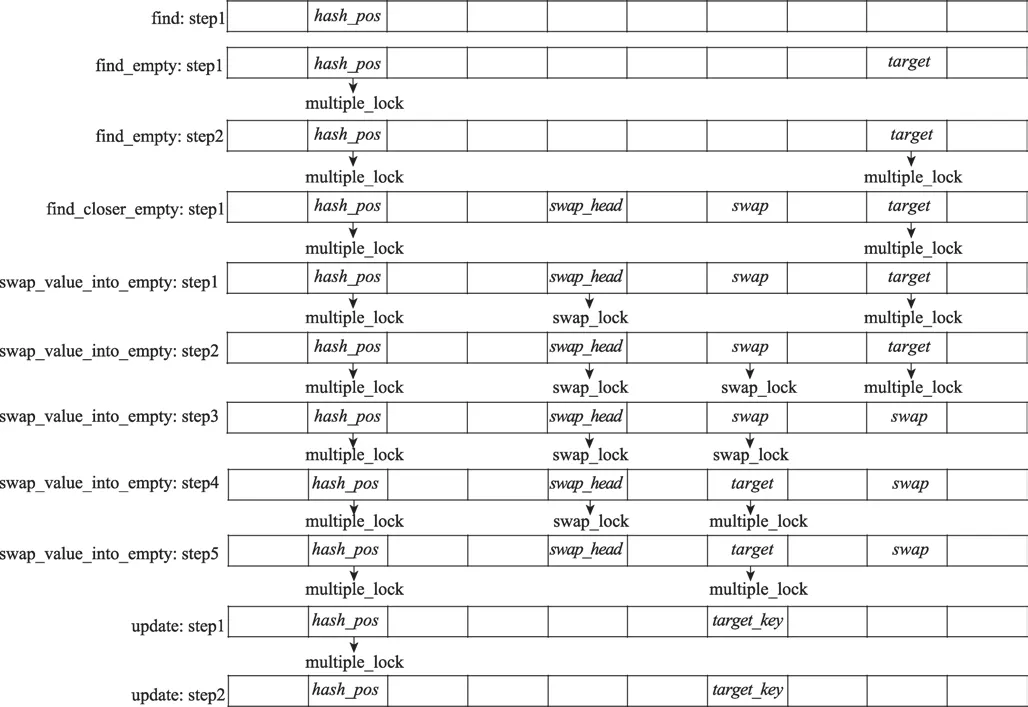
Fig.8 Operations on lockflag during insert operation图8 插入操作过程中对锁标记的操作
插入操作过程中对锁标记执行的操作与删除操作类似,但更为复杂,如图8。首先,在find_empty阶段开始前,需要在hash_pos上带上multiple_lock。发现target后,也要为它带上multiple_lock,这是因为后续可能伴随着find_closer_empty阶段,这个阶段持续时间较长,所以需要提前抢占这个槽,保持它只能被本操作读写。在swap_value_into_empty阶段,首先,为swap_head带上swap_lock;然后,为swap带上swap_lock;接着,在target中填入swap的项,同时取消target的multiple_lock;将swap变为空槽,同时取消swap_lock并带上multiple_lock,在下一阶段,这个槽就成为了新的target;最后,取消swap_head的swap_lock。在插入操作期间,任何一个原子操作失败后,都需要按带上时的倒序清理锁标记并从特定阶段的开头重试操作。
之所以设计了两种互斥锁,原因在于multiple_lock与swap_lock在读-写互斥关系的表达上是不同的:multiple_lock用作写-写互斥和读-写互斥,即当发现槽带有multiple_lock时,这对该槽及其“从属”槽的操作,无论读操作还是写操作,都需要不断重试直到multiple_lock消失。swap_lock只用作写-写互斥,即对带有这个标记的槽,任何针对该槽及其“从属”槽的写操作都需要重试,但读操作可以忽略它。
4.3 warp内并行:warp-wide指令的使用
应用warp协同工作共享策略的GLHT使用了warp-wide指令shuffle、ballot和ffs。shuffle指令允许线程直接读取同一个warp内的其他线程的寄存器值,这种通信方式比通过访问共享内存进行线程间通信的效果更好、延迟更低,同时也不用消耗额外的内存资源来执行数据交换。ballot指令的作用是在warp内线程间进行投票,也常用于让线程根据同名变量了解其他线程所处的状态。每个线程将同名变量作为输入,ballot指令将判断这些变量是否等于零,比较结果将统一广播给每一个线程,若比较结果的第N位被置为1,则表示该warp内的第N个线程处于活动状态且它的变量非零。ffs指令返回输入的最低有效位(即最低为1的bit)的下标,下标从1开始,减去1即得到真正的最低有效位下标,这个指令通常会搭配ballot指令。
warp-wide指令以32个线程为一组执行操作,因此,GLHT设置线程块大小为32,运用warp协同工作共享策略对槽数组进行操作。相应的,设置常数H=31,使得GLHT可以以线程块为单位对整个邻域进行操作。
4.3.1 查找操作
1.__device__void Find(LLkey,LL*result,Slot*position){
2.hash=Hash(key);
3.do{
4.*position=table[hash+threadIdx.x];
5.*hash_pos=__shfl(*position,0);
6.}while((*hash_pos& MULTIPLE_LOCK_MASK)!=0);
7.bitmap=getBitmap(*hash_pos);
8.if(isValid(*position,bitmap)
9.&&(((*position)&EMP_FLAG_MASK)==0)
10.&&isEqual(*position,key)
11.&&(getHash(*position)==hash)){
12.predict=1;
13.}
14.ans=__ffs(__ballot(predict));
15.if(ans==0){
16.*result=WRONG_POS;
17.}else{
18.*result=hash+(ans-1);
19.}
20.}
以上是查找操作Find的伪代码,其中MULTIPLE_LOCK_MASK用来判断槽是否带有multiple_lock锁标记,EMP_FLAG_MASK用来判断是否为空槽。
warp内的每个线程根据其带有的threadIdx确定其应该读取的槽,threadIdx指示线程在warp内的下标,线程应该读取的槽position与下标为hash的槽hash_pos的偏移正好与threadIdx.x相对应(line 4)。虽然读取的槽不同,但每个线程都需要对hash_pos中数据进行条件判断,因此此时会使用shuffle指令将第一个线程读取到的hash_pos中数据分发给其他线程(line 5)。
GLHT执行查找操作时,会反复读取hash_pos和领近槽的数据,并检查hash_pos中的项是否带有multiple_lock锁标记(line 3~6)。
在检查是否有等于查找键的槽数据时,首先根据判断条件设置同名变量predict(line 8~13),然后用ballot和ffs指令并行地对所有warp内线程持有的数据进行同步判断(line 14)。
4.3.2 插入操作
插入操作使用了shuffle指令,主要用在两方面:(1)在所有warp内线程间同步hash_pos数据;(2)在某一个线程执行atomicCAS操作后,将表达操作最终成功与否的变量广播给其他线程以同步地推进所有warp内线程的控制流判断。
除了shuffle指令,插入操作还会在以下情况使用ballot和ffs指令组合:(1)在find_empty阶段,找到最靠近hash_pos的不带multiple_lock锁标记的空槽;(2)在swap_value_into_empty阶段,找到不带任何锁标记的swap槽。插入操作的ballot和ffs指令组合的具体使用方式与查找操作的方式(见伪代码line 8~14)相似。
4.3.3 删除操作
GLHT的删除操作只使用到了与插入操作一样的shuffle指令使用方式。
4.4 warp间完全并发:特殊的并发控制策略
之前的相关工作也使用了全局内存配合CUDA原子操作,但全局内存访问速度要比共享内存慢几个数量级。为了提升性能,GLHT在此基础上设计了特殊的并发控制策略(包括4.2节描述的锁标记和暂时重复策略两方面),保证了读操作的无等待特性,在一定程度上弥补了全局内存访问慢的缺点。
在GLHT插入操作的swap_value_into_empty阶段,需要置换target和swap的项。但是这个置换过程并非原子过程,且GLHT没有结构锁,其他warp的读操作很容易发生在置换过程的各个操作之间,很可能出现其他warp在读取swap_head及其“从属”槽时,读取不到swap中有效键的情况。为此,GLHT设计了“暂时重复策略”,即先将swap中的项复制到target中,再将swap置为空。虽然造成了短暂的项重复,但保证了数据的正确性(即warp不会出现读取不到正确存储在表中的有效值)和读取操作不需要等待的设计要求。
GLHT的查找操作不涉及任何原子操作,因此可以保证在有限的步骤内完成,因此是无等待的,实际上所有的读操作都是无等待的。除了hash_pos的multiple_lock,任何其他的写操作标记都不会影响查找操作的进程,从而消除了读操作与写操作对于资源的互斥等待。这也正是GLHT将swap_lock和multiple_lock分开设计的原因,就是为了提高读操作效率。无论是键-值对映射还是键集合操作,从统计经验上来说,应用程序的读操作数量相对写操作会多一些,因此,提高读操作效率对提高整体操作效率是非常有意义的。
需要强调的是,GLHT的设计方案只能保证GPU上数据结构的无锁并发安全性,CPU上无法实现相同的安全效果。这是因为warp内的并行模式保证了多个位置的内存读操作是真正并行的,相当于在同一时间给多个位置的内存状态做了一个快照,后续所有对这些内存的联合判断都相当于是在同一时间内完成的,从而保证了操作的并发安全,而CPU无法做到这一点。
5 实验评估
本实验全部在Intel Xeon E5-2620服务器上执行,该服务器拥有1个Socket,每个Socket有6个核,每个核有2个超线程。内存为2×16 GB DDR3 SDRAM。高速缓存为32 KB L1数据缓存,32 KB L1指令缓存,256 KB L2缓存,15 360 KB L3缓存。操作系统为64位的Ubuntu 16.04.3。CPU代码采用打开O3优化的gcc-5.4.0编译器编译。GPU部分是在NVDIA GeForce GTX 1080上进行评估比较的,GDDR5X容量为8 GB。CUDA代码采用CUDA 8.0编译器(V8.0.61)编译。
实验评估分为两方面:首先是静态基准,以两个操作阶段(批量构建和检索)分步执行的方式与其他GPU静态哈希表(线性探测、平方探测和CUDPP的杜鹃哈希实现[6])进行比较;其次是动态并发基准,以并发执行随机混合操作(插入、删除和查找操作按比例混合)的方式与CPU跳步哈希表和Misra和Chaud-huri实现的完全并发且可动态更新的GPU无锁链式哈希表[2]进行比较。
5.1 静态基准
GPU静态哈希表有两个操作阶段:(1)批量构建阶段,给定一个固定的负载因子(可以简单地按照预先设计的内存使用率来表示)和一个键-值对输入数组,以批量的插入操作构建整个数据结构,若构建阶段发生插入失败则需要从头重建。(2)检索阶段,在批量构建阶段结束后,以键数组作为输入,在数据结构中执行批量的查找操作,并将返回找到的对应的值存储在输出数组中。
本实验基准以吞吐量(操作总数量/执行时间)作为衡量数据结构性能的指标。所有数据结构选取的槽数组都是大小一致的,并固定内存使用率为0.8。各数据结构的哈希函数也保持一致。操作总数作为横坐标。GPU数据结构的线程数量就等于操作总数量。在确定GPU数据结构的线程数量后,需要决定每个线程块的线程数量(线程块数量=线程总数/每个线程块的线程数量)。
图9是各数据结构的构建速度比较。GLHT虽然比线性探测和平方探测静态哈希表慢,但作为动态哈希表,它的速度基本上还是可以接受的。

Fig.9 Comparison on build speed图9 构建速度比较
预设所有检索键都已存在于数据结构。图10是各数据结构的检索速度比较。与其他静态哈希表相比,GLHT的速度仍然较为合理。
5.2 动态并发基准
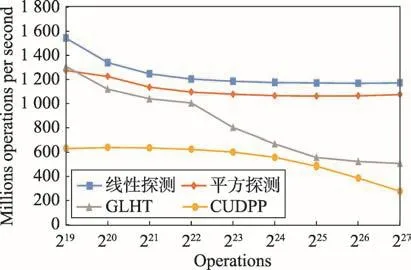
Fig.10 Comparison on retrieve speed图10 检索速度比较
文献[4]已提出了CPU跳步哈希表的并发版本,后续实验中以CPU lock-based hopscotch表示。此外,为了与之前他人提出的GPU哈希表进行比较,本实验基准选择了Misra和Chaudhuri提供的GPU上的无锁链式哈希表[2]作为参照。注意到文献[2]的槽数组实际是链表结点的指针数组,操作过程中需要动态地为链表结点进行内存分配。文献[2]称,为了确保性能评估可以集中在数据结构本身可实现的原始吞吐量上而不受内存分配开销的任何干扰,在GPU内核函数启动之前从CPU预先分配了足够数量的链表结点到GPU内存中,以便并发操作过程中不从GPU调用动态内存分配。本文把这个过程称为“预先分配内存”。这么做的原因是,在操作过程中从GPU调用动态内存分配是非常耗时的事情。但GLHT不需要这样的预分配过程和相关的耗时操作,因此更具有灵活性。若以文献[2]不计算“预先分配内存”的执行时间与GLHT直接相比,GLHT的优势将不能体现,因此为了公平,本实验将同时考虑文献[2]的不计算“预先分配内存”的情况(以GPU chained without allocation表示)和计算“预先分配内存”的情况(以GPU chained with allocation表示)下的吞吐量。
本实验基准以吞吐量(操作总数量/执行时间)作为衡量数据结构性能的指标。数据结构的性能可能取决于不同操作的混合比例、键的取值范围以及操作总数量。为评估不同的操作组合,将不同混合比例表示为三元组[x,y,z],表示具有x%的插入操作、y%的删除操作和z%的查找操作。本实验选取了两个操作组合,[20,20,60]和[40,40,20]。为评估键的取值范围,在每个操作组合上设计4个不同的整数键范围,[0,100],[0,1 000],[0,10 000]和[0,100 000]。操作总数固定为100 000。每个测试的操作序列都是根据混合比例和总数量预先生成的,操作键从被评估的键范围中随机生成。每个测试都需要在GPU上或CPU上评估3次,并且以中值作为其真实执行时间。所有数据结构选取的槽数组大小都是固定一致的,哈希函数也保持一致。线程数量对于CPU数据结构的执行性能来说,并不是越多越好。在本实验环境下,为CPU数据结构选择了达到最佳性能的线程数16。而GPU数据结构的线程数量是根据每次测试的操作总数量决定的,文献[2]称每个线程执行一个操作时效果是最好的,于是GPU数据结构的线程数量就等于操作总数量。文献[2]选择每个线程块512个线程,而GLHT根据设计方案选择每个线程块32个线程。
操作组合[20,20,60]偏向读操作。从图11可以看出,虽然GPU chained without allocation具有明显的性能优势,但是计算上预先分配内存时间后的GPU chained with allocation恰是执行时间最长的,实际上GLHT对GPU chained with allocation有200倍左右的性能提升。并且,随着键范围的增大,GPU chained without allocation对GLHT的性能优势也没有那么明显了,从2、3倍的优势降低到了1倍多。而GLHT对CPU lock-based hopscotch大概有4、5倍的性能优势。
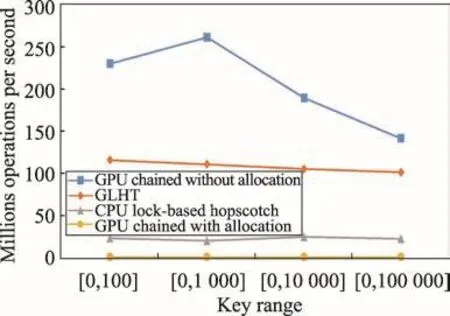
Fig.11 Comparison on throughput of combination[20,20,60]图11 组合[20,20,60]的吞吐量对比
操作组合[40,40,20]偏向写操作。依旧是GPU chained without allocation比较具优势,而GPU chained with allocation最差。但是从图12可以看到,与操作组合[20,20,60]相比,GLHT的优势越来越明显,GPU chained without allocation对GLHT仅有1倍多的性能优势,甚至在键范围较大的情况下,存在GLHT性能超越GPU chained without allocation的现象;GLHT对GPU chained with allocation有200~400倍的性能比;另一方面,GLHT依旧具有对基于锁的CPU跳步哈希表的优势,且优势扩大到了5~9倍。

Fig.12 Comparison on throughput of combination[40,40,20]图12 组合[40,40,20]的吞吐量对比
从以上实验数据可以明显看出,无论是读操作比重较大的情况还是写操作比重较大的情况,本章实现的GLHT对CPU上的跳步哈希表具有绝对的性能优势(4~9倍)。
至于文献[2]提供的GPU上的无锁链式哈希表,虽然它也支持并发的插入、删除和查找操作,但其实仍然不是完全动态的数据结构。GPU内核函数通常无法直接访问CPU内存,因此在处理CPU内存之前必须将数据复制到GPU上,然后再写回CPU。但是,将数据复制到GPU或从GPU复制数据需要付出非常昂贵的时间代价,文献[2]正是采用了这种昂贵的方式为实验中的所有插入操作都预先分配了结点资源(必须在编译时知道具体分配计划),并且不能在运行时动态分配新项和释放已删除项。这是GPU上链式哈希表的一个最大的限制。而GLHT就没有这样的限制,因此更具灵活性。
链式哈希表必须为每个插入结点分配相应的内存,但幸运的是开放寻址的哈希表可以避免大量的内存分配,GLHT中作为结构基础的跳步哈希表正是开放寻找哈希表的一个典型。虽然表面上看GLHT比GPU chained without allocation性能差,但在真实生产环境中更关心的是程序的总体运行时间,也就是GPU chained with allocation的运行性能,因此可以毫不犹豫地说,GLHT更具有竞争优势,毕竟它相对GPU chained with allocation有200~400倍的性能比。退一步说,即使不考虑GPU chained with allocation,GLHT也已经在写操作比重较大的工作负载中超越了GPU chained without allocation。
6 结束语
跳步哈希表可以使用高效的GPU合并访问完成读取请求,相对其他哈希表,更适合用于GPU设计,本文提出并实现了一种GPU跳步哈希表GLHT,它是首个GPU完全并发且可动态更新的跳步哈希表。GLHT与之前的工作相比,具有以下两个特点:(1)warp内单个操作并行,采用warp协同工作共享策略,减少程序控制流中的分支与发散;(2)warp间多个操作并发,使用全局内存配合CUDA原子操作以及特殊的并发控制策略设计,在实现完全并发和无锁特性的同时保证了读操作的无等待特性。GLHT与其他GPU静态哈希表相比,具有可以接受的构建和检索速度;与现有的CPU跳步哈希相比,具有4~9倍的性能优势;比采取预先分配内存的GPU无锁链式哈希表[1]更加灵活,并且在写操作较多的工作负载中获得了更好的性能。
本文实现的GLHT中,为了模型设计和说明的简便,直接以unsigned long long int作为数据结构的项,未来可以将键值存储部分改为指向键-值对的指针以提高使用性。另外,由于目前GPU原子操作的限制(例如atomicCAS操作只涉及整数数据类型),GLHT的设计模型仍显粗糙,未来可以等GPU原子操作可以涉及结构对象时,继续丰富本模型。
