适应性回归分析(Ⅰ)
——回归模型的构建与求解
2019-06-18罗艳虹胡良平
罗艳虹,胡良平
(1.山西医科大学公共卫生学院卫生统计学教研室,山西 太原 030001;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029;3.军事科学院研究生院,北京 100850
1 适应性回归模型
1.1 维数灾难
在回归分析中,当自变量的数目很多(往往问题本身带有很多自变量,再加上派生变量)时,模型空间就非常大,此时,建模者倾向于选择非参数模型取代参数模型。然而,当自变量数目大到一定程度时,由于自变量水平组合所形成的“试验点”在高维空间中会显得非常“稀疏”,从而导致回归模型的方差迅速增大,以至于回归建模过程无法收敛或回归分析的结果失去其应有的价值,这种现象被称为“维数灾难”。
1.2 何为适应性回归分析
解决“维数灾难”问题的常用方法有以下两种:其一,将所研究的问题限于“低维空间”;其二,假定建模过程具有“可加性”,采用“加性模型”[1]。这两种思维方法都存在一定的局限性,只是部分地或回避式地解决了“维数灾难”问题。Friedman[2]提出的“多元适应性回归样条建模技术”在一定程度上较好地解决了前述提及的难题。多元适应性回归样条建模技术被简称为“适应性回归分析方法”,此法由以下两步组成:第一步,采用“快速更新算法”创建一个“过拟合模型”,以下将被称为“向前选择”;第二步,采用“后向选择”修剪已经创建的回归模型。
1.3 适应性回归模型的形式[3]
由多元适应性回归样条算法产生的回归模型可用式(1)或式(2)表示:
(1)
(2)
式(1)或式(2)还可以用式(3)表示:
(3)
在式(3)中,第2、3、4项分别代表仅含单个自变量、含两个自变量及其交互作用项和含三个自变量及其交互作用项所形成的基函数之和。由此可知,多元适应性回归样条模型的结构非常复杂,以拟合复杂程度不同的数据结构并使之达到所期望的“拟合优度界值”。
1.4 适应性回归模型的解说
式(1)到式(3)在本质是一样的,但式(2)和式(3)的形式非常复杂,而式(1)相对简单。下面用通俗的语言解释式(1)。
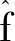
(4)
由此可知:构建适应性回归模型的关键在于如何构造各个“基函数”;模型求解的关键在于如何估计出式(1)或式(2)或式(3)中的回归系数。这个计算过程比较繁琐,通常需要借助统计软件(如SAS/STAT 12.1中的“ADAPTIVEREG”过程,此模块已嵌入SAS 9.3及以上版本)来完成。
2 变量变换方法
2.1 概述
在进行适应性回归建模过程中,需要对变量进行变换,而不是直接将原变量代入回归模型。对变量进行怎样的变换,取决于变量的类型。换言之,对连续型变量与分类变量将采取不同的变换方法。
2.2 连续型变量的变换
对于连续型变量,采用线性截断幂样条变换,分别见式(5)、式(6):
(5)
(6)
其中t为变量V的结点值(或称为分割值),而v为其观测值。为了不用测定变量V的每个值,通过假设底层函数的平滑度来使用一系列的最小跨度的结点值。Friedman[2]使用以下公式来确定结点之间的合理数目(跨度大小)。对于内部结点,跨度大小由以下公式决定,见式(7):
(7)
对于边界结点,跨度大小由以下公式决定,见式(8):
(8)
其中,α为决定结点密度的参数,p为变量数,nm为父基函数Bm>0的观察数目。
2.3 分类型变量的变换
对于分类变量,变量通过指示函数进行转换,分别见式(9)、式(10):
(9)
(10)
其中{c1,…,ct}为变量V类别的子集。这种平滑法适用于分类变量,它假设各个类别的子集具有相似的性质,类似于假设对连续变量进行局部区域的预测。
如果一个分类变量有k个不同的分类,那么共有(2k+1-1)种可能的子集。计算成本等于回归中所有子集的选择,对于大的k值来说代价较大。多元自适应回归样条算法采用逐步选择的方法选择分类,从而形成子集为{c1,…ct}。该方法仍然是贪婪的,但它减少了计算,并产生合理的最终模型。
3 回归模型中自变量的筛选
3.1 向前选择
多元自适应样条算法的向前选择过程如下:
(1)设定初值B0=1,M=1;
(2)重复以下步骤,直到基函数的值达到最大,最大值为Mmax;或者Bm、v和t三个参数的任意组合都不会使模型性能得到更好的提升。
1)设置“失拟(即模型不能表达资料变化的部分)”的界值LOF*=∞;
2)对于筛选出的基函数Bm,m∈{0,…,M-1}都对变量v做以下操作,对于v∉{v(k,m)|1≤k≤Km}者除外。
①对于满足v:t∈{v|Bm>0}的变量,每个结点值(或类别中子集)t建立一个由当前所有选定基函数组成的模型及两个新基函数:BmT1(v,t)和BmT2(v,t);
②计算新模型LOF欠拟合的界值;
③如果LOF 3)通过在模型中增加Bm*T1(v*,t*)和Bm*T2(v*,t*),最大程度上更新模型。 4)设定M=M+2。 每个条目最重要的部分是发现Bm、v和t之间的关系,例如在模型中添加两个相关基函数。向前选择的目标是建立一种过拟合数据的模型。线性模型的残差准则通常是残差平方和(RSS)。 多元自适应回归样条算法的向后选择过程如下: (1)通过设置整体的欠拟合标准来初始化:LOF*=∞; (2)重复以下步骤,直到达到空模型为止。最后一个模型是在向后筛选过程中发现的最佳模型。 1)对于筛选的基函数Bm,m∈{0,…,M-1}: ①对于不包含Bm,计算欠拟合标准(LOF); ②如果LOF ③从当前模型中减去Bm*。 2)设定M=M-1。 向后选择的目的是“修剪”过拟合的模型,找出预测性能最好的模型。因此,使用过拟合界值来表示模型对原始数据表达的真实性是不合理的。相反,多元自适应回归样条算法使用一个类似于广义交叉验证界值的数量。更多信息参见“拟合优度界值”一节。 原始的多变量自适应回归样条算法计算代价较大。为了提高计算速度,Friedman提出了快速算法。快速算法的基本思想是减少在向前选择的每个步骤中,检验B、V和t的组合的数量。 假设有在第k次迭代之后形成的(2K+1)个基,其中选择父基Bm来构造两个新的基。考虑一个以基为元素的队列,在队列的顶部是B2k和B2k+1两个新构造的基。队列的其余部分根据每个基的最小无匹配条件进行排序,排序方法见式(11): (11) 式(11)中,求极小值函数“min”下部有两个条件,其一,“for all eligible V”的含义是“对于所有合格的变量V”;其二,“for all knott”的含义是“对于所有的结点t”。 当k不小时,模型中有相对较多的基,增加基的个数不太可能显著提高拟合优度。因此,在相邻迭代期间,优先队列中基的排名变化太大。候选的父基可以被限制为第一次迭代队列中的前K个基。第k次迭代之后,顶部基有新的J(Bi)值,而底基的值不变。队列根据J(Bi)值重新排序。这对应于MODEL语句中FAST选项的K=选项值。 为了避免排在最后的候选基被放弃使用,并允许它们重新上升到顶部,一个自然的“老化”因素被引入到每个基。通过定义每个基函数的优先级来实现,见式(12): P(Bi)=R(Bi)+β(kc-kr) (12) 其中R(Bi)为队列中第i个基的秩,kc为当前迭代次数,kr为上次计算J(Bi)值的迭代次数。然后根据这个优先级重新对前K个候选基进行排序。较大的β值会导致在以前的迭代中改进较小的基以更快的速度上升到列表顶部。这对应于MODEL语句中FAST选项的“BETA=”值。 对于优先级队列顶部的候选基,将重新计算(k+1)次迭代的所有合格变量V的最小失拟界值J(Bi)。得出的最优变量可能与前一次迭代中找到的变量相同。因此,快速多元自适应回归样条算法引入另一个因子H以节省计算成本。该因子指定J(Bi)应该为所有合格变量重新计算的频率。如果H=1,在考虑父基时,每次迭代中对所有变量都进行优化。如果H=5,经过5次迭代完成视为最优。如果小于指定H的迭代计数,则优化只在之前完全的优化中找到的最优变量进行。当然,有前三个候选项例外,B2k+1(这是用于构建两个新基的父基Bm)和两个新基:B2k和B2k+1。在每次迭代中执行它们的完整优化。这与MODEL语句中FAST选项的“H=”选项值有关。 与其他非参数回归过程一样,多元自适应回归样条算法可以产生复杂的模型,这些模型包含高阶交互作用项并考虑许多结点值或子集。除了基函数,向前选择和向后选择过程都是高度非线性的。考虑在偏倚与方差之间取其折中,包含多个参数的复杂模型倾向于较低偏倚而较高方差。为了选择具有良好预测性能的模型,Craven等[4]提出了被广泛使用的广义交叉验证(GCV)界值,见式(13): (13) (14) 其中d为每个非线性基函数所需要的自由度,M为模型中线性无关基函数的总数。因为在多变量自适应回归样条算法的每个步骤中评估的任何候选模型都是一个线性模型,所以M实际上是冒子矩阵的迹。GCV界值和LOF界值的唯一区别是额外项d(M-1)。相应的有效自由度被定义为M+d(M-1)/2。在形成新基函数时,需要考虑非线性,故引入了d这个数量,同时,它也作为一个平滑参数而存在。d值越大,函数估计越平滑。Friedman[2]认为d值一般为“2~4”。对于结构复杂的数据,d值可以更大。用户也可以使用交叉验证作为拟合优度界值,或使用各自的验证数据集来选择模型和单独的测试数据集来评估选定的模型。3.2 向后选择
4 快速算法
5 拟合优度界值
猜你喜欢
——人-时间资料率比分析与SAS实现
