大数据技术在加氢高压换热器腐蚀预警系统中的应用
2019-06-17
(北京邮电大学国际学院,北京 100876)
近年来,石油化工工业向大型化、自动化、智能化和低能耗等方向发展。然而,一旦生产系统出现故障,轻则导致整个设备或系统运行瘫痪,影响企业的正常生产和经济效益;重则会发生人员伤亡事件,给企业带来负面影响。因此,如何实现石化工业生产过程和运行设备的实时监测与状态评估,排除潜在的故障,预防重大事故发生,已成为当前石油化工领域亟需解决的问题之一[1]。
在传统石化生产过程中,普遍使用一些监控设备来监控生产流程和保障生产安全,但其中大多数是传统的工业控制系统,只对已经发生的生产故障进行阈值报警,而不能在故障发生的苗头阶段或者故障发生的早期阶段,发现生产流程中的异常,进行预测报警。
随着科学技术的进步,尤其是计算机和信息管理技术的飞速发展,石油化工工业生产设备中越来越多的变量能够得到测量、处理和监控。在此背景下,设计并实现一套基于大数据的加氢高压换热器运行状态评估系统,通过采集历史数据建立监控模型,充分挖掘隐藏在过程数据中的信息,分析生产过程的运行情况,通过运行状态评估实现辅助故障预警的目标。
1 大数据分析技术基础
石化工业设备运行状态评估的理论研究来源于1971年Beard博士所提出的用解析冗余代替硬件冗余的理论[2]。随着检测滤波器、广义似然比等运行状态评估理论算法被提出,运行状态评估理论和应用得到了快速发展。
工业运行状态评估方法主要分成三类:基于数学模型的方法、基于过程知识的方法和基于数据驱动的方法[3]。近年来,现代工业不断向大型化、复杂化方向发展。在当今的大型系统中, 一方面, 基于数学模型的方法不可能获得复杂机理模型的每个细节;另一方面, 基于过程知识的监控方法需要很多复杂高深的专业知识以及长期积累的经验, 大大超出一般工程师所掌握的知识范围, 因此不易操作。数据驱动方法不依赖精确的数学模型,仅依赖工业生产中所获得的历史数据,来建立监控模型,进而得到了广泛关注。目前, 多数企业每天都产生和存储较多运行、设备和过程监测数据, 这些数据分为正常条件下和在特定故障条件下收集的数据, 包含着过程中各方面的信息,这为基于数据驱动的运行状态评估方法提供了基础。
基于数据驱动的运行状态评估方法主要有3种:基于统计分析的方法、基于信号分析的方法以及基于定量知识的数据分析方法。其中,基于统计分析的方法有:基于控制图法的运行状态评估技术,基于PCA(主元分析法)的运行状态评估技术和基于PLS(全潜结构投影法)的运行状态评估技术等[4-6]。基于信号分析的方法主要有:基于小波变换的运行状态评估方法、基于S变换的运行状态评估方法等[7]。基于定量知识的方法不需要定量数学模型,利用人工智能技术实现运行状态评估,典型代表有基于人工神经网络的方法[8],基于支持向量机的方法和基于模糊逻辑的方法[9-10]。虽然基于人工神经网络的方法在很多领域取得了较好的应用成果,但是在石化领域,面对数据维度多、种类单一及用于训练的故障数据少等问题,基于统计分析的方法要优于神经网络的方法。
2 高压换热器运行状态评估
基于大数据技术的加氢高压换热器运行状态评估方法,主要从模型开发与系统建设两方面入手。(1)模型开发:主要基于统计分析找出稳定状态下的系统参数分布,并对需要评估的时间点逐一与健康模型对比,最终基于运行状态评估算法估算出系统健康分值;(2)系统建设:主要搭建出满足数据采集存储、分析及展示的数据分析链路,解决工业数据量大、周期性作业的问题。
2.1 大数据模型开发
大数据模型主要基于统计方法进行运行状态评估。在运行状态评估之前,需要解决工业数据中因人为操作而造成的噪声数据以及工业场景下大量传感器产生不相关维度数据等问题。在运行状态评估中,需要解决现有的数学模型输出指标不直观,没有考虑到数据时间相关性等问题。
2.1.1 自动化噪声区间检测算法
针对人为操作、其他点位故障造成的传感器数据波动,使用基于滑动窗口检测的自动化噪声区间检测算法自动诊断出故障区间,并通过与日志文件对照的方法,区分出噪声区间和真正关注的故障区间。
故障区间检测首先通过一个滑动窗口算法进行判断,如图1所示。对于每一个检测长度L1的区间,取前后一段时间L2和L3作为参考区间,对L1,L2和L3区间进行统计指标计算,最后对比L1和L2,L3的统计指标之比,如果大于阈值,则认为该验证区间异常,记录该异常区间后,整个窗口向后滑动L1步长。在使用滑动区间检测出异常区间后,通过与操作日志及运行日志联合分析,确定由泄漏导致的异常和人为操作造成的异常。清除噪声数据,从而避免噪声数据对后续建模造成影响。
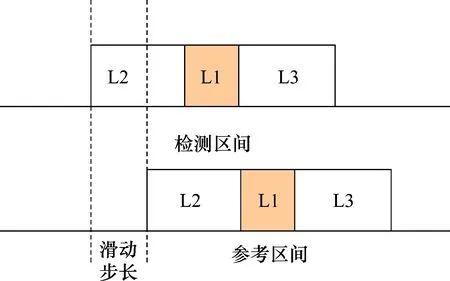
图1 噪声检测滑动区间示意
2.1.2 皮尔森系数的参数选择算法
针对采集的传感器数据维度高、大量参数与故障无关的问题,采用皮尔森系数的相关参数选择算法挑选与故障相关的维度作为模型输入。皮尔森系数描述两个随机变量的相关程度,取值在-1至1之间,两个随机变量的相关系数越接近-1或1即表明相关性越大,接近0即表示相关性小,公式描述如下:
该系统针对采集的122维参数算法,首先确定与泄漏故障直接相关的换热器管口压力、温度以及瞬时流量三维关键参数,并计算剩余119维数据与关键参数的皮尔森相关系数绝对值,将相关系数绝对值按照大小排列,并取总体相关系数绝对值贡献的前90%作为相关参数,最终得到22维与故障紧密相关的参数。
2.1.3 主成分分析的运行状态评估算法
该算法首先基于主成分分析对模型输入进行分解,并通过HotellingT2和Q统计检验方法进行健康诊断。但仅使用统计检验方法存在两个缺点:(1)HotellingT2和Q是两个独立的指标,当两个指标出现“一高一低”时,无法直接断定系统健康状况;(2)HotellingT2和Q仅仅检验了特定某一个时刻的系统指标分布,没有从时间上考虑系统变化的情况,因此,需对统计检验结果进一步分析。综合当天健康指标波动值和历史健康值水平,提出健康诊断算法,整体算法流程见图2。
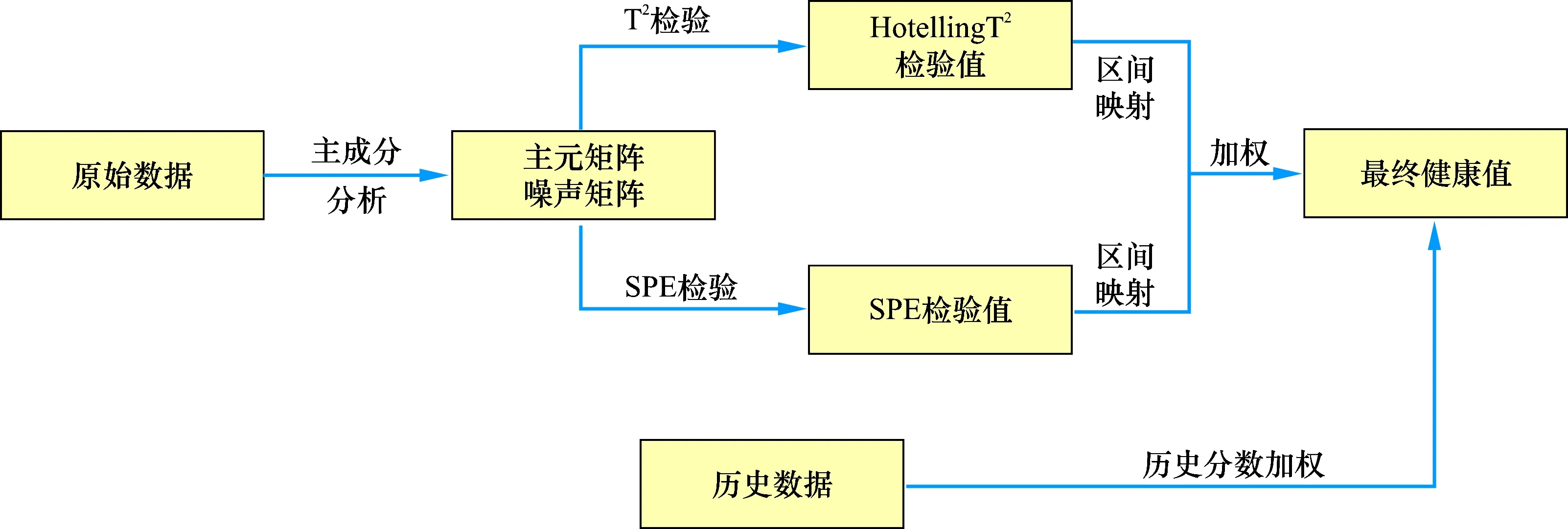
图2 运行状态评估算法流程
主元分析法(PCA)又称为主成分分析法,是目前主要的过程工业控制故障检测与诊断方法。PCA的主要思想是将高维度空间转化为低维度空间,并尽可能保留高维度的信息。假设当前数据集X包含了m个维度,n个时间点的观测值,用矩阵表示如下。
通过变换矩阵P,可将矩阵X线性变换为得分矩阵T,表示如下:
在得分矩阵T中,T的列向量为得分向量,也称作主成分;P称为负载矩阵,P的列向量称为负载向量。负载矩阵可以通过X的协方差矩阵特征分解得到。假设样本矩阵X的协方差矩阵为:
由于样本矩阵的协方差矩阵是一个方阵,对协方差矩阵进行特征分解即可得到特征向量p1p2…pm以及对应特征值λ1λ2…λm,特征分解如下:
式中:P=[p1p2…pm]即为所求负载矩阵P,且P为单位正交矩阵,即有下式成立:
PPT=I
从而不难得出得分矩阵T:
T=XP
最终可将矩阵X分解为如下两个部分:
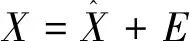
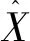
在对数据集X进行了主成分分析后,即得到了数据模型的数据分布。统计学上,可以通过建立统计量指标的假设检验来判断当前过程是否符合模型数据分布。在PCA的假设检验中,通常通过HotellingT2和Q两个统计量进行假设检验。其中,HotellingT2统计量表明每个待检验数据在变化趋势和幅度上实际偏离模型的程度,可以通过计算检验数据在主元子空间的投影偏离程度得出;Q表明该时刻待检验数据到模型空间的距离,可以通过计算待检验数据在残差空间的投影符合程度得出,其值越大,表示当前检验数据越不符合主元模型。
第i时刻观测数据的HotellingT2统计量计算公式为:
第i时刻观测数据Xi的Q统计量计算公式为:
对于每个观测点数据,通过计算HotelingT2和Q值,可以定量表示观测点与主模型的偏离程度以及与主模型的变化趋势,也可以表示主模型变化幅度与主模型的偏离程度。
基于PCA,HotellingT2和Q检验得到每个时刻点的指标,并未考虑历史数据和多指标存在潜在不一致性的问题。针对上述问题,该算法对HotellingT2和Q计算得到的统计量进行进一步处理。首先,该算法将HotellingT2值以及Q值从[0,+∞)映射至[0,100],对于任意时刻,对健康值进行映射的计算公式如下:
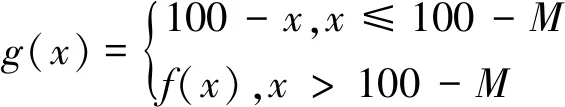
式中:M是健康阈值,对于大于该阈值的HotellingT2和Q值,通过类sigmoid函数进行平滑,分别计算出映射值,通过加权得到综合映射值。综合映射值计算公式如下:
g(x)=λggT2(x)+(1-λg)gQ(x)
对于健康的计算,该算法还考虑了一天内健康状况值的方差带来的影响,计算公式如下:
his(x)=g(x)-α·std
式中:x是当前时刻的输入值,std是近一天内健康状况的标准差,α是权重系数。
为了使系统对健康状况的评估更加谨慎,增加了健康值平滑策略,计算公式如下:
health(x)=λ·his(xt)+(1-λ)·his(xt-1),his(xt)>his(xt-1)
his(xt),otherwise
式中:health(x)是最终分数,his(xt)是当前观测时刻健康值,his(xt-1)是前一个观测时刻的健康值,λ是权重系数。
在经过了平滑策略后,系统对健康的评估分数趋于“出现异常快速衰减,异常减轻缓慢恢复”的状态,有助于现场人员谨慎关注系统状况。
2.2 大数据系统建设
大数据系统架构如图3所示。该架构主要分为数据存储采集子系统、数据调度分析子系统和数据查询展示子系统。其中,数据采集存储子系统主要负责数据源获取及持久化;数据调度分析子系统是大数据模块的实现核心,主要负责基于原始数据的系统运行状态评估分析;数据展示子系统主要负责读取分析结果,为现场人员提供可视化的系统评估呈现。
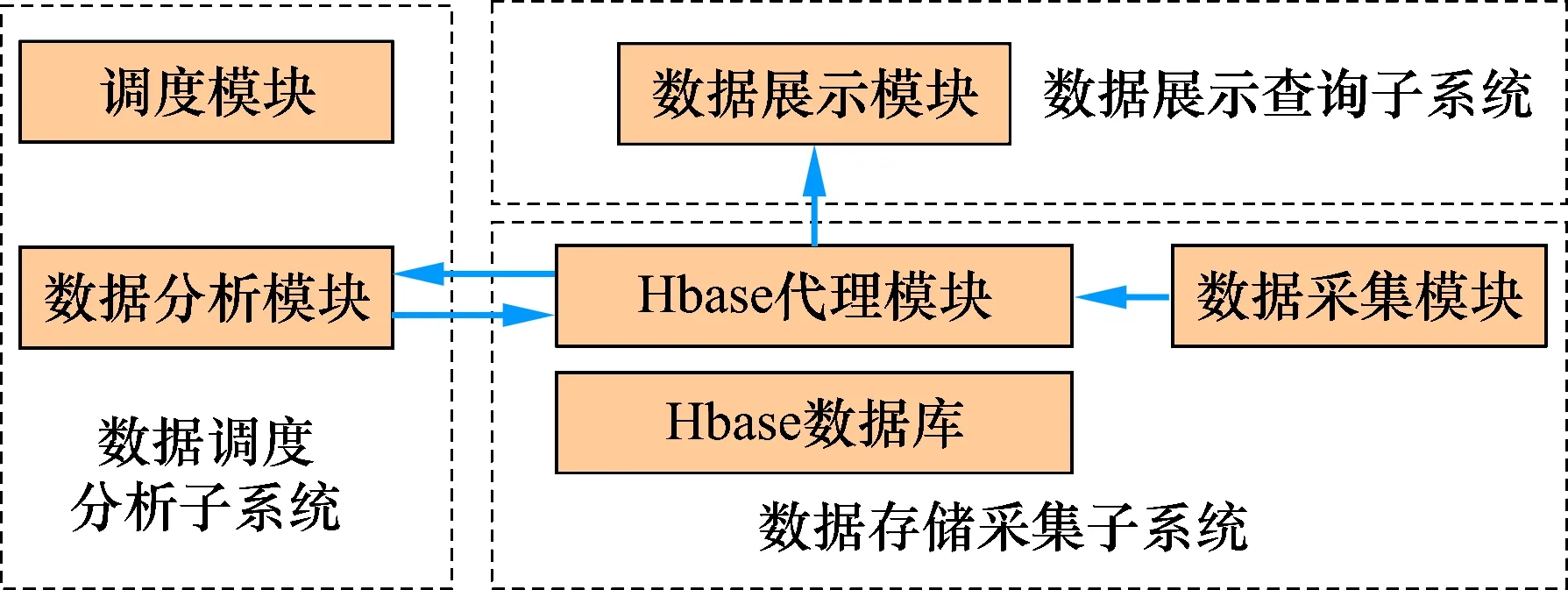
图3 大数据系统架构
2.2.1 数据采集存储子系统
(1)数据采集模块:该模块的主要功能是周期性地从各种异构的数据库读数据。该模块以时间为关键字,合并多行数据,并通过HTTP请求将传感器采集数据发送给Hbase代理服务器。
(2)Hbase代理模块:该模块为其他模块提供操作Hbase的RESTful的HTTP接口,并进行身份验证。在写入Hbase时,Hbase模块会对写入数据进行预处理,以符合平台数据格式规范。在读Hbase数据时,Hbase代理模块直接向Hbase请求数据结果。
(3)Hbase数据库:HBase是一个分布式的、面向列的数据库。使用Hbase对数据进行按列存储,并按时间戳存储,能有效应对加氢大数据按时间存储、参数指标多的特点。
2.2.2 数据调度分析子系统
(1)分析模块:基于大数据模型,将数据处理流程抽象为数据预处理与清洗、健康模型生成和健康数据分数计算等3个计算任务。每个计算任务基于Hbase作为数据源,对相应的大数据模型进行实现。
(2)调度模块:对于周期性采集的原始数据,先后执行预处理与清洗、健康分数计算等任务,并按照生产需要,执行健康模型生成计算任务,更新系统健康模型。
2.2.3 数据展示查询子系统
数据展示查询子系统主要负责获取下层模块数据,进行健康状况展示。数据展示子系统包含数据展示模块,主要基于Hbase读入特定时刻系统健康状况,实现可视化展示。
3 工业应用和经济效益分析
3.1 工业应用
加氢高压换热器腐蚀预警系统开发完成后,在2017年3月开始在中国石化某公司2号柴油加氢装置上运行。该系统在2017年5月17日对2号柴油加氢装置发出腐蚀告警。通过对该系统腐蚀评估模型分析,定位了故障时间和位置,提醒企业提前进行处理。2017年5月23日,该装置出现泄漏,与预估时间非常接近。泄漏设备拆解后发现,泄漏位置、腐蚀类型与评估结果相符合。
3.2 经济效益分析
该预警系统的直接经济效益主要来自于减少非计划停工和减缓换热器腐蚀等方面。
在减少非计划停工方面,按照每年减少一次非计划停工计算,可产生经济效益约500万元RMB;在减轻换热器腐蚀进而节约设备更新费用方面,预计换热器使用寿命可由1.2年提高至4年,一个检修周期可节约更新费用约800万元RMB。
4 结 论
(1)针对高压换热器的故障预警,探讨了自动化异常区间检测的滑动窗口算法;针对石油化工系统传感器多,待分析参数维度高的特点,提出了基于关键参数的皮尔森相关系数选择方法进行特征选择。
(2)使用基于PCA的统计检验方法对系统健康状况进行评估,并针对传统统计检验方法评价指标不一致、未考虑健康数据事件相关性的问题,设计了一套运行状态评估算法,能更直观、全面地评估系统健康状况。
(3)基于大数据技术对高压换热器的运行状态进行评估,比传统方法有较大优势,能更准确地掌握该系统运行状况,对故障预警有积极意义,从而降低事故发生率,提升系统的经济效益和社会效益。
