异构云环境下的密码服务调度方法
2019-06-17孙德洋娄嘉鹏李建鹏张寒冰成文文
孙德洋 娄嘉鹏 李建鹏 张寒冰 成文文
1(西安电子科技大学通信工程学院 陕西 西安 710071)2(北京电子科技学院网络空间安全系 北京 100070)
0 引 言
云计算作为新兴的计算模式,具有高可扩展性、高可靠性和按需服务等特点[1],云基础设施由共享的硬件和软件商品资源池组成,这些资源按地理位置分布并提供按需服务[2-3],可以为用户提供可变的按需资源。从服务消费者角度来看,用户希望获得满足其个性化需求的云服务,这些云服务将利用“云”中的领域知识和用户端的状态信息来提供服务,以极大提高用户体验。在云计算中,调度是重要的组成部分之一,其效率决定整个云计算环境的工作性能。面对云计算环境下的用户业务类型多样、需求个性化的问题,如何实现业务的高效调度,保证不同的业务请求得到快速、有效的解决起着至关重要的作用。
异构云环境下的任务调度问题,已被证明为NP-hard问题[4],而多算法的密码服务器属于典型的异构系统,各密码算法处理节点的处理能力存在差异,如果没有有效的密码服务调度机制,会导致作业包与处理节点之间的映射不合理,从而影响整个服务系统的工作性能。现有的很多文献大多采用的是理想化的节点性能,通过采用一定的调度方法,从负载均衡、资源利用率和减少能耗等方面进行研究[5],而调度系统性能的最优解往往与具体应用有关,需要针对具体实际问题建立模型[6]。本文从以上问题的角度出发,在充分考虑节点异构性的基础上,提出一种基于任务截止时间的调度方法,通过两级调度模型,完成作业包和密码计算单元之间的映射,从而实现对不同密码任务的调度。
1 相关研究
围绕云环境下的任务调度问题,国内外学者展开一系列的研究工作,先后提出多种调度模型和算法[7]。文献[8]提出了基于遗传算法的两阶段任务调度方法,结合任务截止时间和资源利用率以确定优先级队列,从而提升任务调度性能,但文中没有考虑任务优先级等因素对调度的影响,无法满足调度过程中的实时性需求。Zhou等综合考虑了任务的截止时间和优先级等因素,提出一种基于仿真的动态调度方法,但该方法需反复查询信息表并由模拟器模拟生成调度策略,实现较为复杂且系统开销较大[9]。文献[10]以总任务完成时间和任务平均完成时间作为参考量,提出一种双适应度遗传算法(DFGA)的任务调度算法,但该方案的节点处理能力较为理想化,无法适应不同节点处理能力不均衡的实际应用问题。文献[11]提出一种基于滚动优化的实时任务调度系统,通过新增加虚拟机的方式来保证在任务的截止期内完成任务请求,此方案能在一定程度上保证任务执行的成功率,但是无法适应异构环境下不同节点处理能力不同的问题,并且无法处理虚拟云中的并行任务。文献[12]提出通过用户优先级感知负载平衡改进的Min-Min调度算法(PA-LBIMM),但是该算法仅关注任务的运行时间、负载均衡和用户优先级等因素,没有考虑任务的完成时间约束,可能会导致计算资源中现有负载过多而产生的任务失效问题。
相比于传统任务的调度系统而言,密码服务的专业性、安全性、实时性要求更高,在实际的应用环境中,调度方案要均衡和优化影响系统性能的多种因素[13]。基于上述问题,本文针对异构云环境中不同密码服务处理节点实现功能和性能不同的问题,综合考虑用户优先级、作业包等待时间、节点运算速率等级以及各节点当前任务队列等影响因素,提出一种新的任务调度模型和算法,实现异构云环境下多种密码任务的调度[14]。主要工作如下:
(1) 构建一种密码任务调度模型,主要包括任务分析模块、任务调度单元和异构环境下的算法计算模块。
(2) 提出一种基于该调度模型的任务调度方案。通过对任务截止时间进行等级划分,建立节点性能和任务截止时间之间的映射关系。
(3) 提出一种对应等级节点的任务调度算法。利用用户优先级和任务等待时间定义任务优先级,实现请求任务与执行节点的最佳匹配。
2 系统模型
2.1 任务模型
假设现有n个相互独立的作业包,则作业包的集合表示为T={T1,T2,…,Tn},对于每个作业包Ti,具体可表示如下:
Ti={T_IDi,cmd,key_idi,Proi,d_timei,w_timei,e_timei,longi,datai,tar_vmi}
式中:T_IDi(i≥1)表示作业包的唯一标识,故不同作业包的标号不同,该字段主要用来将处理后的作业包按照T_IDi返回;cmd是命令字段,表示具体密码任务的请求操作指令,可以为加密、解密、签名、验签和Hash等请求,并规定对应的字段依次为1、2、3、…;key_idi为该密码服务所需的密钥标识;Proi表示用户的等级;d_timei表示作业包截止时间,决定作业包与等级队列之间的映射关系。所谓的截止时间,是指某项任务必须要在规定的时间内完成的时间[15],即超过该时间任务失效;w_timei表示作业包等待时间,其值为从作业包加入到任务队列至任务被执行这一时间段的总时间;e_timei为作业包的完成时间;longi为作业包的长度;datai为运算数据;tar_vmi表示经系统调度后作业包对应的目标执行节点,该参数由调度系统赋值。从而,作业包Ti可以由包含上述字段的的结构体定义,m个作业包可以由m维结构体数组task[m]定义。
作业包处理系统如图1所示,该系统中的实时任务具有以下特性:
(1) 每一个作业包Ti都是非周期性的,其等待时间为w_timei,完成时间为e_timei,截止时间为d_timei,按上述可得到d_timei≥(w_timei+e_timei)。
(2) 作业包是不可抢占的,且相互独立。
2.2 队列模型
为了更好地满足异构云环境下的用户需求,保证用户密码服务任务的最佳处理节点匹配,根据节点的处理速率将其划分为四个不同等级的队列,分别为1级队列、2级队列、3级队列和4级队列。在用户的任务调度过程中,各级队列之间不设置固定的优先级差异,由系统第一级调度子系统综合考虑不同任务的截止时间属性、队列长度属性和时间属性为任务寻找和匹配与其最佳的节点等级队列。对于不同等级的队列Qi,具体可表示为:
Qi={q_leni,q_timei,da_ratei,q_numi,l_numi,task[u]}
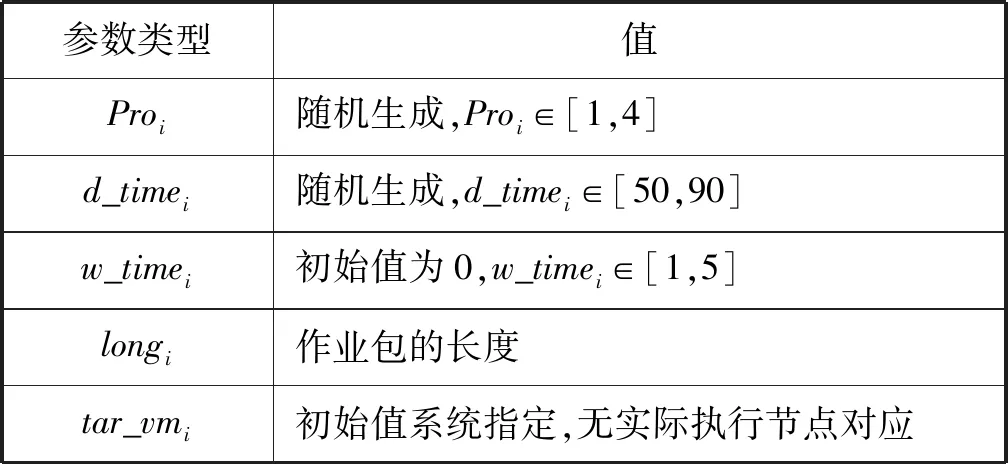
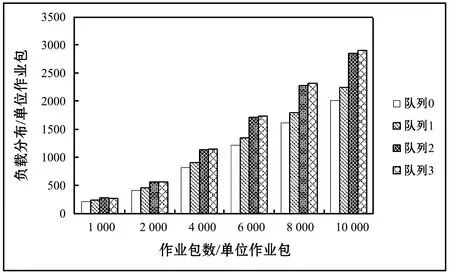
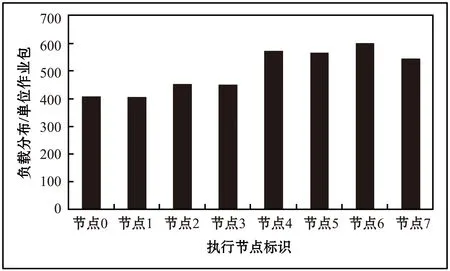
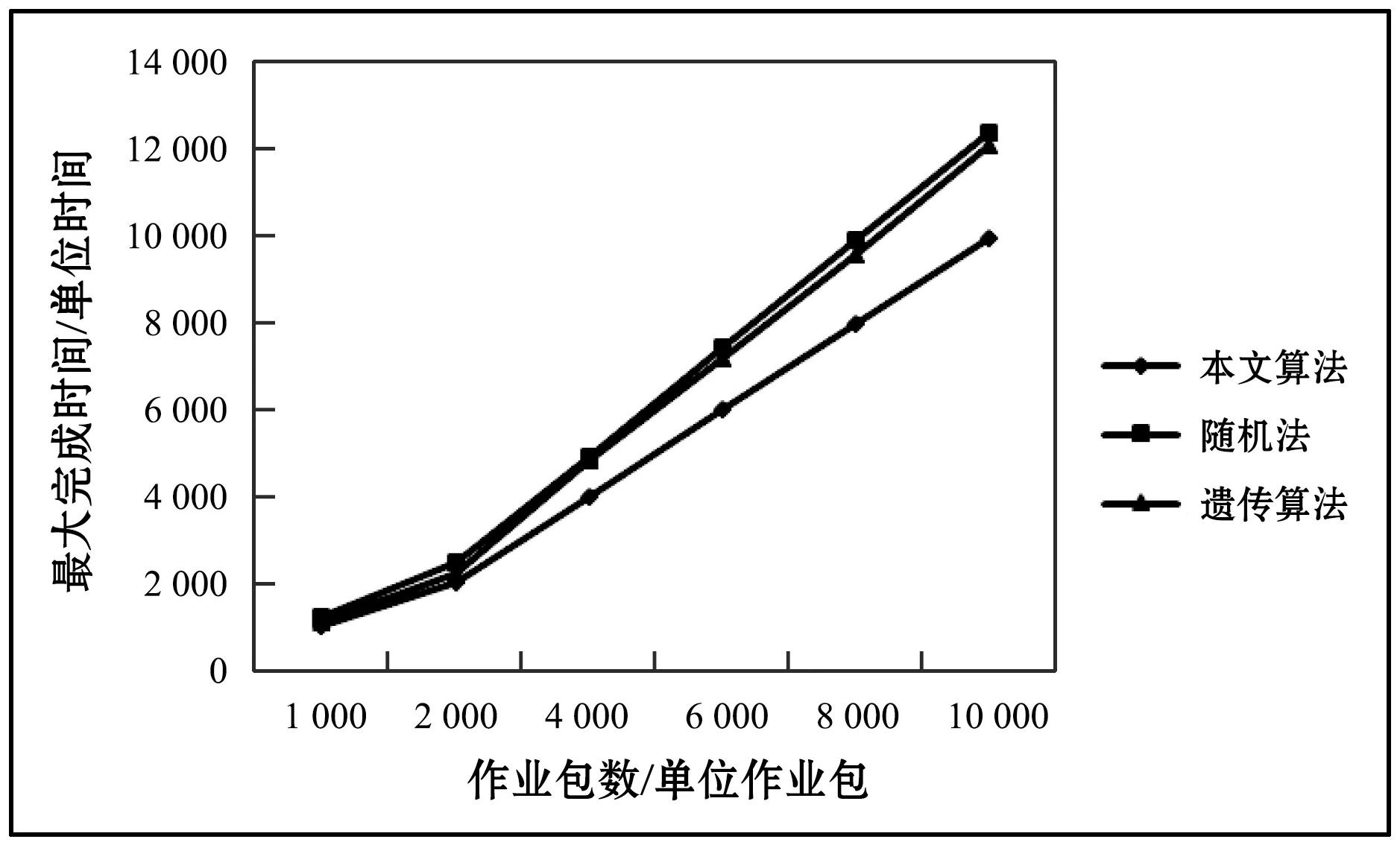
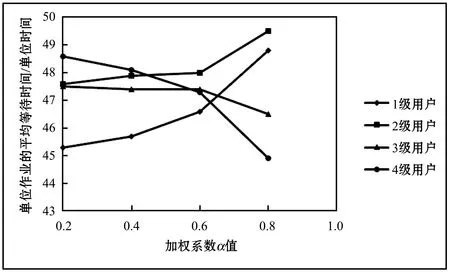
式中:q_leni表示队列可容纳的最多负载数,即队列长度;q_timei字段为队列的时间属性,表示该队列下节点所能处理任务的最小截止时间;da_ratei表示队列下节点的平均数据处理速率;q_numi表示当前队列下的节点个数;l_numi表示该队列当前的负载量;task[u]表示已分配到该队列中任务的标识集合,u满足0≤u 在任意队列中,假设所有节点单位任务的平均用时为t_Ti,则: (1) 因此,在设置队列长度与时间属性时遵循以下约束关系: (2) 正常情况下,对于作业包数量为l_numi的等级队列,当满足d_timei>q_timei且l_numi≤q_leni时,将当前作业包分配至该队列,负载量l_numi+1,对应的密码计算节点每执行一个作业包,负载量l_numi-1。当l_numi>q_leni时,即表示该等级队列负载量已满,当前作业包无法进入该队列,将其调度到等级较高且满足截止时间属性q_timei的队列中。 在第二级调度中,通过任务优先级调度算法计算各任务的优先级,空闲节点根据所属队列中各任务的优先级大小选择任务执行。其中,任务优先级调度算法综合考虑任务对应的用户优先级和等待时间属性。 每个等级队列对应的计算节点可用一个集合表示,即:VM={VM11,VM12,…,VM1n,…,VMn1,…,VMnn}。 对于任意VMi,有: VMi={VM_IDi,VM_ratei,funci} 式中:VM_IDi表示对应节点的唯一标识,与任务模型的tar_vmi对应;VM_ratei表示节点下数据的处理速率,该值由节点本身确定;funci表示该节点下的功能,与任务模型的cmd对应。 对于具有n个节点的队列Qi,队列模型参数da_ratei和所属节点的VM_ratei有以下对应的关系: (3) 调度模型包括以下四部分:作业分析模块、任务请求队列、任务映射模块和等级队列。如图2所示。 图2 调度模型 当有新的任务到达时,调度可以分为以下5个步骤: step1不同地域的用户终端提交任务请求,将作业包依次放入调度系统的任务接收队列中; step2调度器中的任务分析模块根据不同的任务请求参数cmd,将任务接收队列中的作业包依次放入对应的任务请求队列中,例:加密队列中的作业包均为加密算法任务请求,其他队列同理; step3任务映射模块依据任务映射策略中队列时间属性、队列长度属性和任务截止时间之间的映射关系确定队列等级,将作业包依次分配到对应的队列中; step4在每个等级队列中,根据任务优先级算法计算任务优先级值,空闲节点根据该值的大小选择相应的执行任务; step5将处理后的数据反馈输出。 为方便描述,本文流程图和仿真等仅以加密请求为例,其他任务请求模式同加密请求。 3.2.1第一级调度 当用户提交的作业包进入任务接收队列后,任务分析模块根据作业包中的cmd字段将任务队列中的作业包放入任务请求队列中。以加密队列为例,在此队列中,对于任意作业包Ti,通过其字段中定义的d_timei值,根据映射策略关系将该作业包调度到对应的等级队列中。 任务映射策略:当任务j截止时间、队列k时间属性以及长度满足如下约束关系时,将任务分配至该等级队列;否则,按照等级队列属性da_ratei递增的顺序依次查询,若存在等级队列符合上述约束关系,则将任务包调度至该队列: (sizeof(queue[k].task[ui])≤queue[k].q_len) && (task[j].d_time≥queue[k].q_time) (4) 算法1任务与等级队列的映射算法。 输入:任务截止时间,等级队列时间属性和长度属性; 输出:依次遍历各等级队列,将任务分配到符合约束条件的等级队列,更新该等级队列属性;否则丢弃该任务。 对于m个待调度任务和等级队列k(0 1. for(j=0;j 2. { 3. for(k=0;k<4;k++) 4. { 5. if((4)式成立) 6. Queue[k].task[ui]=j; 7. ui++; 8. end if 9. } 10. } 3.2.2第二级调度 不同用户优先级不同,且每个作业包经算法1调度后在等级队列中的等待时间也不相同。为了使较高等级用户的作业包具有较高的执行优先级,同时避免其他用户的任务在队列中等待时间过长,本文提出一种基于用户优先级和等待时间的加权任务优先级调度算法。通过该算法确定任务优先级T_Pro的大小,处理节点根据该值从其所述的等级队列中选择相应的任务执行。 完整的任务优先级调度算法如下: T_Proi=α×priorityi+β×waitTimei (5) 式中:α、β分别为加权系数,α,β∈[0,1]且α+β=1。 算法2任务调度优先级算法。 输入:各等级队列的任务集合,以及对应执行节点属性; 输出:若等级队列中的任务已被执行节点成功调度,则返回调度成功标识,且更新该任务所在等级队列属性。 对于共有n个执行节点、m个待分配任务的等级队列k: 1. 初始化局部变量temp=big=m,以及优先级数组F[m+1]={0}; 2. for(i=0; i 3. { 4. if(节点i空闲) 5. for(j=0; j 6. { 7. if(任务j未被节点调度) 8. 式(5)计算获得最大优先级任务的标识:big; 9. end if 10. } 11. if(F[big]!=0) 12. 将big标识的任务分配至节点i; 13. 更新队列k的属性; 14. end if 15. end if 16. } 通过在Windows环境下的C语言编程仿真,本节对调度系统任务的负载分布、完成时间以及加权系数对不同等级用户作业包等待时间的影响进行了仿真测试分析,并在完成时间的测试中,与随机法进行对比分析。由于其他密码服务任务请求的总体过程相同,在以下仿真中仅以加密算法为例进行。 在本次仿真中,作业包的参数设置如表1所示,其中,Proi表示用户的优先级,d_timei表示任务截止时间,w_timei表示任务等待时间,longi为作业包的长度。 表1 任务包的参数设置 共设置4个等级队列、8个处理节点,分别从0开始编号,每个等级队列分别对应两个处理节点:节点0和节点1所属队列编号为0,节点2和节点3所属队列编号为1,节点4和节点5所属队列编号为2,节点6和节点7所属队列编号为3。对于待处理数据量大小相同的单位作业包,各节点预计完成时间分别为(单位时间): Vm[i].(VM_ratei)={9.9,9.7,8.6,8.3,6.7,6.5, 5.6,5.5} (0≤i≤7) 等级队列的参数设置如表2所示,其中,q_timei表示队列的时间属性,q_leni表示队列长度,da_ratei表示队列下节点的平均数据处理速率。 表2 等级队列的参数设置 由于任务优先级算法中的加权系数α、β只影响等级队列中各作业包的执行顺序,不影响系统的负载分布和任务执行效率,故在仿真实验1和实验2中可任意设置该加权值,本文中取α=0.6、β=0.4。 仿真实验1:系统负载分布。分别测试等级队列和节点的负载分布情况。 等级队列的负载分布。按上述方式设置处理节点数量、处理节点性能参数以及队列参数,随机生成不同数量的作业包,各队列的负载分布随作业包数量变化情况如图3所示。 图3 队列的负载分布 由图3可知,在相同作业包数量的情况下,较高处理节点对应的等级队列(队列2和队列3)作业包负载量较大,体现了异构云环境下“能者多劳”的分配策略。随着作业包数量的增多,各等级队列中的负载分布逐渐增加,且均保持良好的负载分布。 由图4可知,在作业包数量固定的情况下,数据处理性能相似的节点作业包分布没有较大差异。总体而言,节点负载量随着节点处理性能的提高而增加。就节点7而言,在系统当前任务量下,负载量相对较少,为后续紧急作业包爆发的情况提供了保障,提高了系统在该情况下的调度成功率。 图4 节点的负载分布 仿真实验2:执行效率测试。为了测试本文算法的执行效率,设置相同的处理节点属性以及等级队列属性,随机生成不同数量的作业包,分别测试在使用本文算法、随机法和遗传算法时各节点最大完成时间随作业包数量的变化情况,如图5所示。 图5 任务执行效率测试 由图5可知,在相同的实验环境与参数设置下,本文算法的执行效率明显优于随机法和遗传算法。这是因为本文提出的算法考虑了作业包的自身属性、等级队列的负载情况以及处理节点的异构性,调度过程中以任务包的截止时间为参考进行节点的匹配,考虑作业包的优先级和等待时间因素选择执行任务,并且每次调度完成后及时反馈和更新各调度节点信息。同时,对满载的等级队列,通过将作业包动态调度到高等级队列,保证了任务的处理效率。而本文采用的随机法中节点是按照编号顺序从等级队列中随机选择任务来调度执行,会出现已空闲的高性能节点需等待低性能运算节点运行完成后才能进行后续任务调度的情况,无法充分发挥高性能节点的处理优势,从而导致整体任务运行时间较长。遗传算法在进行大量的个体计算时,计算时间较长,算法的收敛速度较慢,与随机法相似,在为任务搜索和匹配最佳执行节点时也未充分考虑节点运算速率异构等问题,故会影响整个调度系统的完成时间。因此,本文算法在最大完成时间上相较于随机法减少了约14.48%~19.52%,相较于遗传算法减少了约4.44%~17.54%,并且随着作业包数量的增多,执行效率的提升更明显。 仿真实验3:加权系数α对不同等级用户任务在等级队列中平均等待时间的影响。设置作业包总数为8 000,保持各处理节点、等级队列的性能属性固定不变,依次改变任务优先级算法中加权系数α值,分别测试不同等级用户对应作业包在等级队列中的平均等待时间,如图6所示。 图6 α对平均等待时间的影响 由于随着系数的增加,在任务优先级调度算法中用户优先级占据的比重逐渐加大,等待时间占据的比重减少,故优先级越高的用户作业包会优先得到处理。从而,在图6中,随着加权系数α的增大,3、4级用户对应的单位作业包平均等待时间逐渐降低,1、2级用户单位作业包的平均等待时间逐渐增加。由此可知,α和β的取值会对作业包在等级队列中的等待时间有一定的影响。 通过测试结果可知,当作业包数量逐渐增加,本文的框架和算法有更好的优势。 本文提出基于任务截止时间的二级任务调度模型,设计一个基于作业包属性的调度算法。首先根据作业包的命令标识cmd把任务调度到相应的任务请求队列。然后根据任务的截止时间d_timei选择合适的等级队列,在选择等级队列时可根据其参数q_leni对作业包进行动态调整,避免因某一个等级队列负载量过大导致其他作业包无法进行及时处理而失效的情况。在对应的等级队列中,通过任务调度优先级算法计算得到任务的优先级,空闲处理节点根据优先级值的大小选择相应的任务执行。仿真结果表明,该框架能有效保证节点的负载分布和良好的执行效率,与随机法和遗传算法相比,其执行效率分别提高了17%和11%左右。2.3 节点模型
3 调度模型及算法
3.1 调度模型

3.2 调度算法
4 仿真及分析

5 结 语
