基于深度置信网络的卡尔曼滤波算法改进
2019-06-17郭继峰李忠志张国强房德智李艳娟
郭继峰 李忠志 张国强 房德智 李艳娟
(东北林业大学信息与计算机工程学院 黑龙江 哈尔滨 150040)
0 引 言
卡尔曼滤波是一种基于最小方差下的最优估计方法。在系统模型、过程噪声和测量噪声的统计特性都已知的条件下,输入观测量、输出估计值,并且观测更新与时间变化具有一定联系,通过这一联系卡尔曼滤波可以不断地进行递推和对估计进行修正,主要解决的是随机线性问题[1]。卡尔曼滤波解决的是对线性系统的估计,主要算法设计如下,其中X(k+1)为k+1时刻目标状态变量,f(k)为状态转移矩阵,G(k)为噪声驱动矩阵,Z(k+1)为k+1时刻观测向量,H(k)为观测矩阵,R(k)为k时刻噪声协方差矩阵。
(1) 状态估计的一步预测方程:
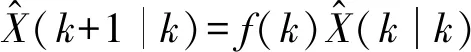
(1)
(2) 一步预测状态的协方差为:
P(k+1|k)=f(k)P(k|k)f′(k)+G(k)Q(k)G′(k)
(2)
(3) 一步观测矩阵的协方差为:
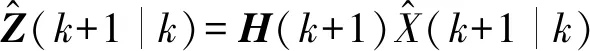
(3)
(4) 观测向量的预测误差协方差为:
S(k+1)=H(k+1)P(k+1|k)H′(k+1)+R(k+1)
(4)
(5) 新息或测量残差为:

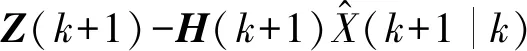
(5)
(6) 滤波器增益为:
K(k+1)=P(k+1|k)H′(k+1)S-1(k+1)
(6)
(7) 卡尔曼滤波算法的状态更新方程为:
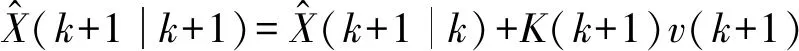
(7)
(8) 滤波误差协方差的更新方程为:
P(k+1|k+1)=P(k+1|k)-K(k+1)S(k+1)K′(k+1)=
[I-K(k+1)H(k+1)]P(k+1|k)
(8)
通过不断重复以上步骤来不断更新滤波的误差协方差矩阵,获得更精确的滤波效果,卡尔曼滤波算法的结构如图1所示。

图1 卡尔曼滤波结构框图
1 标准卡尔曼算法在滤波存在的问题分析改进
传统的卡尔曼滤波算法主要有自适应卡尔曼算法[15]、模糊卡尔曼算法[16]和新息卡尔曼算法等。其中韩亚坤等[17]提出的新息自适应卡尔曼滤波算法没有考虑对新息测量噪声协方差矩阵进行在线优化,李忠良[18]提出基于BP神经网络的自适应卡尔曼滤波算法没有考虑对人工神经网络进行优化,只使用简单的三角函数来对比试验,忽略了其他影响卡尔曼滤波的因素,对预测精度有一定的影响。针对以上卡尔曼算法在滤波中出现的,当系统模型不精确时滤波精度不高的问题,提出一种基于深度置信网络模型的新息卡尔曼滤波算法。首先通过对新息卡尔曼滤波算法在滤波过程中利用实时观测量和估计量信息在线修正参数和噪声的统计特性,然后使用深度置信网络模型在线调整噪声协方差矩阵Q,使其接近实际噪声量,从而提高滤波估计精度[2]。
1.1 新息自适应卡尔曼滤波原理
自适应卡尔曼滤波算法是为了解决理想状态下的噪声无法在现实环境中实现这个问题而提出的一种改进卡尔曼算法,而新息自适应卡尔曼算法是其中的一种。通过式(3)和式(8)推导出k时刻的新息,其中I(k)为k时刻的新息,C为新息协方差,Q(k+1)为k+1时刻噪声矩阵,R(k)为k时刻观测噪声协方差矩阵:
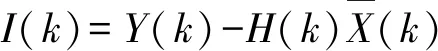
(9)
k时刻的新息协方差:
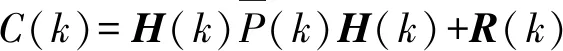
(10)
由式(4)和式(7)得到Q(k+1)的表达式:
Q(k+1)=K(k)H(k)P(k)
(11)
最后将式(11)代入式(6)得出:
Q(k+1)=K(k)C(k)H(k)K′(k)
(12)
由式(10)变换可得到新息测量噪声协方差矩阵R:

(13)
通过以上的推导和变换就可将标准的卡尔曼滤波算法改写成基于新息的自适应滤波表达式,新息的自适应卡尔曼滤波和标准的卡尔曼滤波的不同在于,新息自适应卡尔曼滤波表达式中的噪声协方差不再是固定的,而是对噪声进行实时估计,从而使R和Q更加精确,提高了滤波的精度。
1.2 深度置信网络模型构建与原理
深度置信网络(Deep Belief Network)[14]由许多层用于接受输入的显层神经元(以下简称显元)和用于提取特征的隐层神经元(以下简称隐元)构成,因此隐元也可以被称为特征检测器[3]。顶部两层之间是无方向连接的,并构成联合记忆。 下层的其他上层和下层之间存在有方向连接。 最底层表示的是数据向量,每个神经元表示为一维数据向量。受限玻尔兹曼机RBM(Restricted Boltzmann Machine)是DBN的主要组成元件。 因此,DBN的训练过程是渐进的。 在每一层中,数据向量用于推断隐藏层神经元,并且该隐藏层被视为下一层的数据向量。其结构如图2所示。
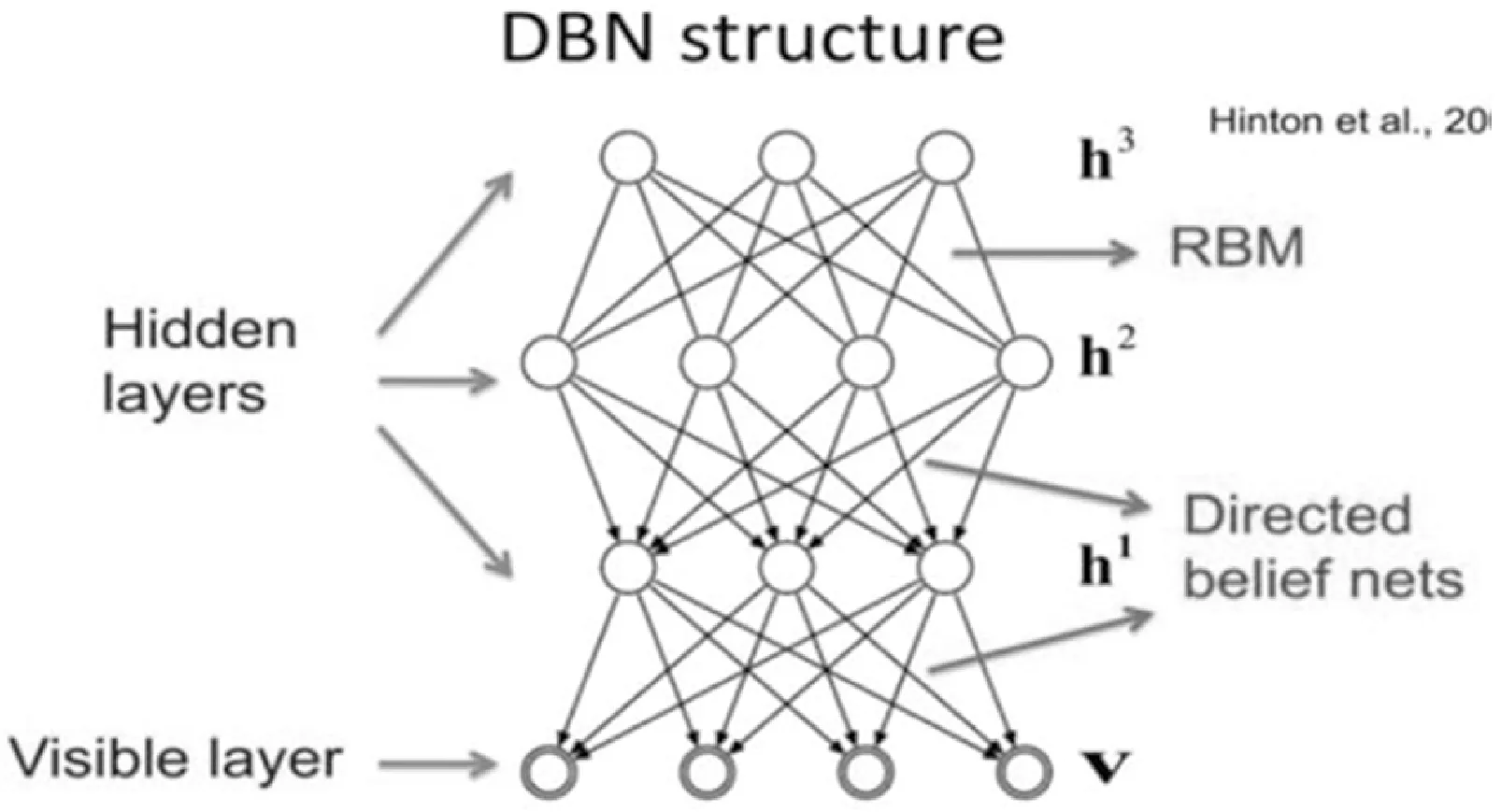
图2 模型结构图
1.2.1受限玻尔兹曼机结构及工作原理
受限玻尔兹曼机是由一层显性神经元和一层隐性神经元组成的,并且两层神经元之间为双向全连接,所以又被成为神经感知器,结构如图3所示。
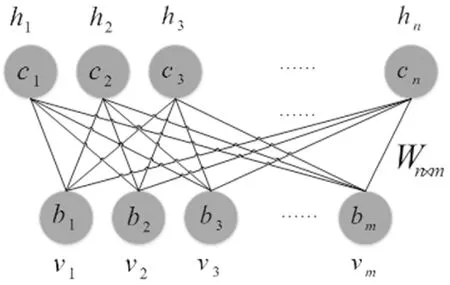
图3 受限玻尔兹曼机网络结构图
在受限玻尔兹曼机中,任意两个连接的隐层神经元和显层神经元都有权重w来表示它们的连接强度,且每个显层神经元都有表示自身权重的偏置系数c,每个隐层神经元都有表示自身权重的偏置系数b。因为RBM是基于能量的模型EBM(Energy Based Model),所以可以用下面函数表示一个受限玻尔兹曼机的能量,并通过该能量函数引入一系列相关的概率分布函数:
(14)
在一个受限玻尔兹曼机中,激活隐层神经元hj的概率密度函数为:
(15)
由于是双向连接,所以显层神经元可以被隐层神经元激活,其概率密度函数为:
(16)
式中:σ为Sigmoid函数[4],也可以设定为其他函数。由于同一层显性或隐性神经元之间无连接权重,故具有独立性,所以概率密度亦满足独立性,易得到下式:
(17)
(18)
通过以上的推导和分析得出了RBM的基本构造。
当用一条数据向量来训练完RBM的显性神经元层后,受限玻尔兹曼机会根据式(15)计算出相应的隐层神经元被激活的概率:P(hi|x)j=1,2,…,Nh,并且取0-1随机数μ作为阈值,若概率大于该阈值则神经元将被激活,否则会被抑制,即:
hj=1P(hj|x)<μ
(19)
hj=0P(hj|x)≥μ
(20)
由以上不等式得出隐层的每个神经元是否被激活。
RBM共有五个参数:v、h、b、c、W,其中v是输入向量,h是输出向量,b、c、W,是通过学习相应数据得到的偏置值和权重。训练RBM采用的是K步对比散度算法DC-k(Contrastive Divergence)[5]。先将数据输入给显层V1,并使用式(15)计算出每个隐层神经元的激活概率值。然后从计算的概率分布中通过Gibbs抽样[6]选取一个样本:
h1~P(h1|V1)
(21)
并用h1重新构造显层,因为显层和隐层之间为双向全连接所以可通过隐层反推出显层,最后使用式(16)计算出显层中的每个神经元的激活概率P(V2|h1)。再次在h1的基础上计算得出新的概率分布并通过Gibbs抽样选取一个新的样本:
V2~P(V2|h1)
(22)
利用V2再次计算每个隐层神经元的激活概率,最后得到更新的概率分布P(h2|V2)的权重:
W←W+λ(P(h1|V1)V1-P(h2|V2)V2)
(23)
b←b+λ(V1-V2)
(24)
c←c+λ(h1-h2)
(25)
按照以上步骤经过若干次训练后,隐层神经元不但能较为精准地表达出显层神经元的特征,而且还能够在一定程度还原显层。
1.2.2网络的训练与调优
DBN 在训练模型的过程中主要分为两步:
(1) 预训练:首先对第一个RBM进行完全训练,并将第一个RBM的偏移量和权值固定;然后将第一个RBM的隐层神经元的学习状态作为输入向量输入到第二个RBM中进行充分训练,在训练完第二RBM之后,将第二RBM设置在第一RBM的顶部;最后重复上述训练步骤任意次数,并需要分别对每一层的RBM网络进行无监督训练以确保将特征向量尽可能地映射到多个不同的特征空间,同时保留多个特征信息,若训练集为被标记的数据,那么在顶层训练RBM时,除了RBM显层中的神经元之外,需要加入表示分类标签的神经元,与Softmax分类器等一起进行训练。根据学习到的相应标签数据,分类器中相应的标签神经元被激活为1,其他神经元被抑制为0。
(2) 微调:在对组成DBN的RBM进行训练后,每层RBM只能保证自身的权值对该层得到最优的特征向量映射,并不能对整个DBN模型达到最优的特征向量映射,所以还需要计算出预测值和真实值之间的误差。这就要将DBN的输出层替换为反向传播层(BPNN)[7],反向传播层会将误差值从上向下传播至每一层的RBM,从而达到微调整个DBN网络的效果。将RBM学习到的特征向量作为其输入向量,并且对关系分类器进行有监督训练。上述训练RBM网络模型的过程也可以看作是对深层的BP神经网络[13]权值参数的初始化,避免了DBN像BP神经网络一样因随机初始化权值参数而容易陷入局部最优和训练时间过长的缺陷[13]。训练好的模型如图4所示,其中深色部分为参与训练最顶层RBM的标签。

图4 训练好的深度置信模型
训练生成DBN模型后,除了顶层RBM以外,其他层RBM的权重都被分成了向下的生成权重和向上的认知权重,接下来使用醒睡算法CWS(Contrastive Wake-Sleep)[9]对模型调优。该算法主要分为两个阶段,醒阶段为学习和认知过程,通过学习外界的特征和向上的认知权重产生每一层的抽象表示的结点状态,并且使用随机梯度下降算法[10]修改层间向下的生成权重。睡眠阶段为联想和生成过程,通过醒阶段学习和认知到的概念和向下的生成权重来生成底层状态的同时再修改层与层之间向上的认知权重。
2 实验效果与对比
以电磁继电器寿命实验数据的滤波来测试本算法效果。电磁继电器是指专门应用于电器控制的继电器,该类继电器切换负载功率大,抗冲、抗振性高。电磁继电器在航空航天等用电系统中担负着控制、调节和保护等极其重要的任务,其质量的好坏与工作的可靠性直接影响着各种用电设备整体运行的可靠性和安全性。由文献[18]可知接触电阻、超程时间和弹跳时间是影响继电器寿命和可靠性的关键参数。执行大众集团VW80932标准工作模式:通电2 s,断电3 s。采用寿命试验台对德国海拉公司HELLA/JD191型常开式触点电磁继电器进行寿命实验,该样件动作104 088次失效[11]。图5-图7为该样件三个参数进行断点和野值[12]的处理后的生命周期中退化趋势数据。

图5 接阻电阻随动作次数的变化规律
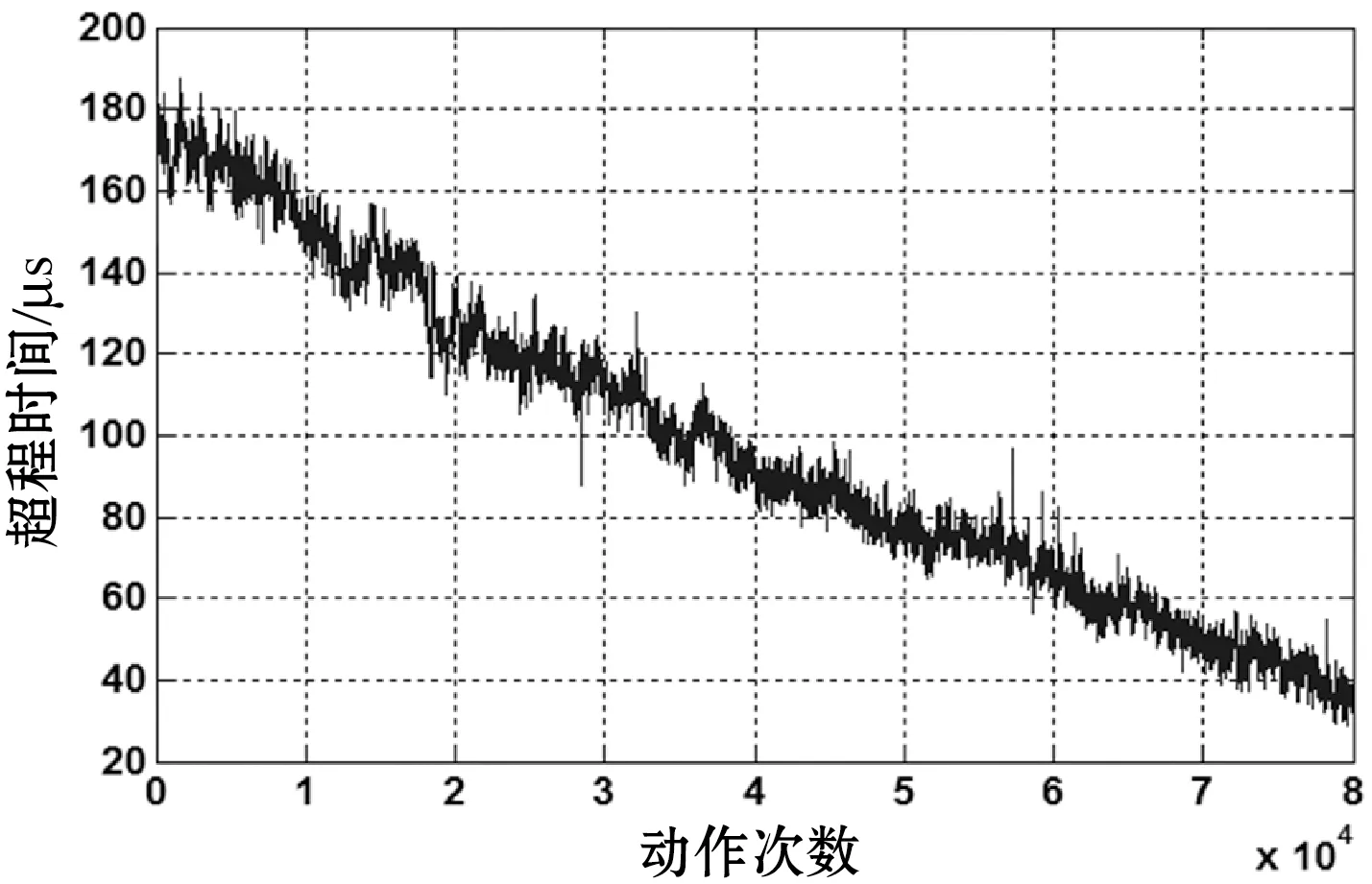
图6 超程时间随动作次数的变化规律
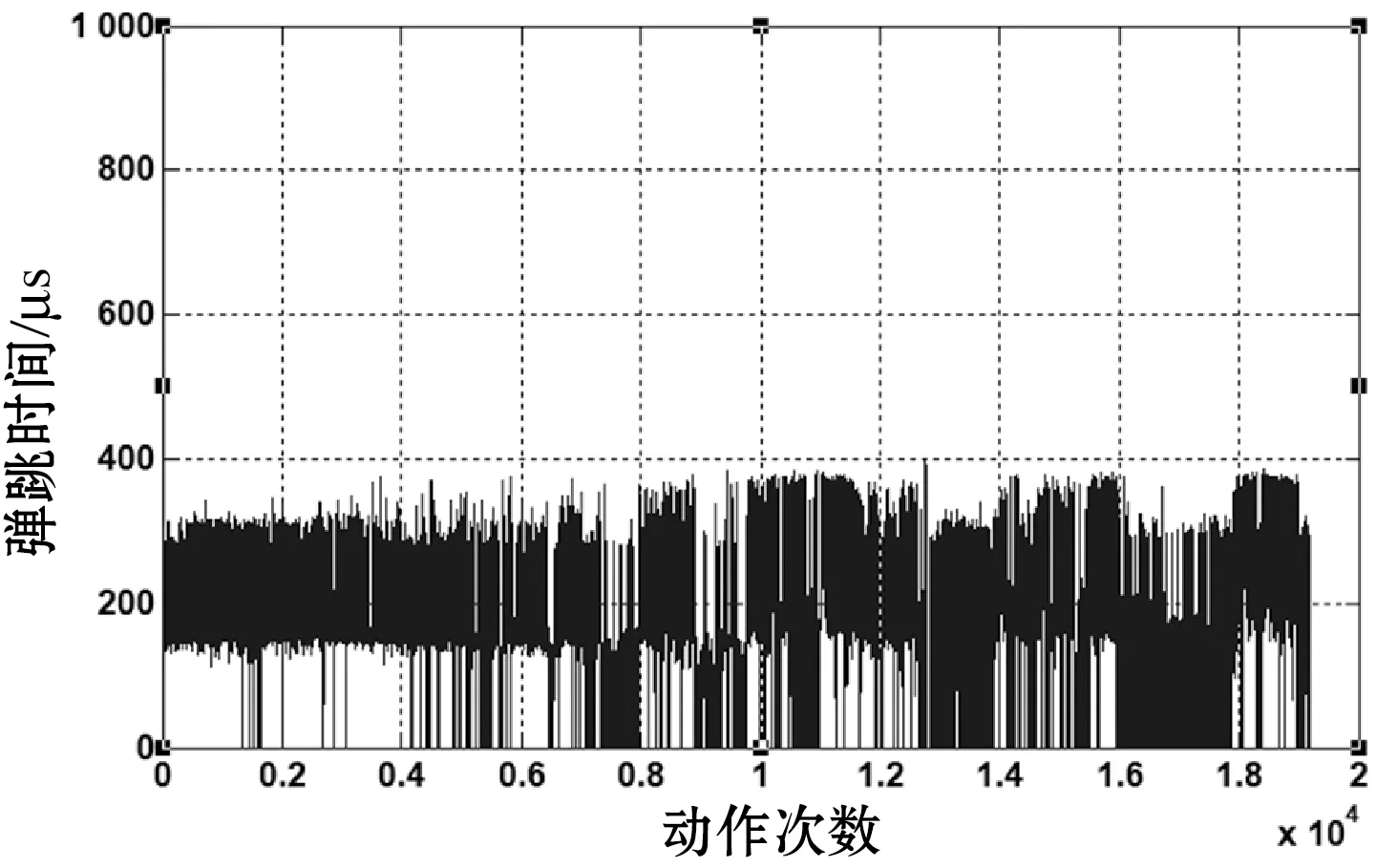
图7 弹跳时间随动作次数的变化规律
先后用新息自适应卡尔曼算法和基于DBN模型改进的卡尔曼算法对参数(接触电阻、超程时间和弹跳时间)进行滤波,前后效果对比如图8-图10所示。可见,采用DBN模型对卡尔曼滤波算法的噪声协方差矩阵进行调整,改变了滤波增益并在线调整系统模型从而明显提高对数据中目标状态的估计精度。

图8 接阻电阻随动作次数的变化规律滤波前后对比图

图9 超程时间随动作次数的变化规律滤波前后对比图

图10 弹跳时间随动作次数的变化规律滤波前后对比图
为了更直观地描述滤波的性能,使用均方根误差RMSE[20](root mean square error)进行定量分析,定义如下:
(26)

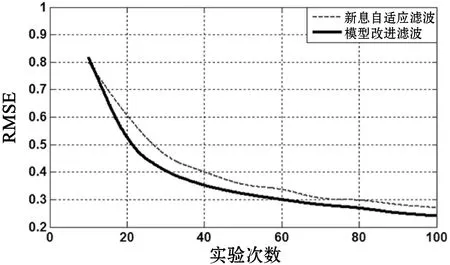
图11 超程时间均方根误差对比图

图12 弹跳时间均方根误差对比图

图13 接阻电阻均方根误差对比图
从图11-图13的三个参数 RMSE曲线可以看出,采用DBN模型改进的卡尔曼滤波算法可以较好地降低RMSE。通过使用RMSE曲线可以较好地分析和比较DBN模型对卡尔曼滤波算法的滤波增益,并且对基于不同神经网络模型改进的滤波算法提出一种较为理想的比较手段,同时也为后续进行滤波效果评估提供足够的依据。
3 结 语
实验使用DBN改进模型进行滤波后对结果进行分析和对比,提取了电磁继电器中的六个重要参数中具有代表性的三个参数为输入数据,建立基于DBN的新息卡尔曼滤波模型。滤波结果表明了该模型的精确性和有效性,根据仿真计算和实验的结果可以看出,基于深度置信网络改进的新息卡尔曼滤波模型是可行且有效的,可为继电器寿命预测、故障诊断以及其他相关设备器件的可靠性研究提供新的更高精度的数据处理方法。
