大数据随机样本划分模型及相关分析计算技术
2019-06-15黄哲学何玉林魏丞昊张晓亮
黄哲学 何玉林 魏丞昊 张晓亮
(1.深圳大学计算机与软件学院大数据技术与应用研究所,深圳,518060;2.深圳大学大数据系统计算技术国家工程实验室,深圳,518060)
引 言
数据分析是挖掘大数据价值的重要手段和途径。数据文件通常被表示成个对象(或记录)的集合D={x1,x2,…,xN},其中每个对象被表示成M个属性(或特征)的向量xn=(xn1,xn2,…,xnM),n=1,2,…(当M很大时,D为超高维数据;当N很大时,D为大数据;当M和N都很大时,D为超高维大数据)。正如陈国良院士[1]描述的那样:“到目前为止尚没有这样一个被普遍认可的大数据定义出现”,仅能够从大数据的特征对其展开描述,其中比较有代表性的是大数据的“4V”特征。给定数据文件或数据集D,数据分析的任务主要包括:数据预处理、数据探索分析、奇异值检测、关联分析、聚类分析、分类和预测等。
目前可用于数据分析的方法和算法很多,计算复杂度高是许多数据分析和机器学习算法的共有特点,因此,这些算法很难用于大数据分析。分而治之是当前大数据分布式并行处理普遍采用的策略,其步骤是将大数据文件D切分成个小的数据块文件,分布式地存储在集群节点上。对大数据分析时,先在每个节点上对小数据块进行计算,然后把小数据块的计算结果传送到主节点进行综合分析,得到大数据的分析结果,对于复杂的分析算法,上述两个步骤需要迭代进行,算法需要按分而治之的计算模式并行实现。当前主流的大数据处理平台Hadoop MapReduce和Apache Spark采用的都是分而治之策略。
大数据的划分和数据块文件的管理采用分布式文件系统,如HDFS[2-3];而大数据的分析算法则采用MapReduce[4-5]或Spark[6]计算模型实现。近年来,国内对于MapReduce和Spark的研究主要集中在提高它们解决大数据分析问题的效率上。2017年,张滨[7]对MapReduce大数据并行处理过程中的查询优化控制、数据分布优化和调度优化控制等若干关键技术进行了研究。2018年,李志斌[8]通过引入基于内存的PageRank算法设计了一个针对大规模图数据集的MapReduce大数据并行处理系统。2018年,王晨曦等人[9]提出了面向大数据处理的基于Spark的异质内存编程框架,解决了如何将数据合理地布局到异质内存的问题。2019年,宋泊东等人[10]通过使用Apache Kafka作为消息中间件设计了一种基于Spark的分布式大数据分析算法。更多关于MapReduce和Spark框架性能分析的介绍可参见吴信东等人的研究工作[11]。
基于MapReduce的分布式计算框架通过磁盘文件进行Map节点与Reduce节点之间的数据交换,在运行循环迭代算法时需要大量的磁盘读写操作,极大地降低了算法的执行效率。Spark采用RDD内存数据结构将大数据分布式存储在节点的内存中,在运行迭代式分而治之的算法时不需要反复地读写磁盘,在一定程度上提升了算法的运行速度。但是,当数据量超出内存容量时,Spark的算法执行效率将被大大降低,甚至无法运行。因此,内存资源成为TB级以上大数据的深度分析、挖掘和建模技术的瓶颈。
采用随机样本数据对大数据做统计估计和建模是大数据分析的有效途径。但是,对分布式大数据做随机抽样是计算成本很高的操作,因为要对大数据的分布式数据块文件进行遍历才能获得随机样本数据,这一过程需要大量的磁盘读写操作和节点间的数据通信。如果大数据的分布式数据块可以直接当作样本数据来用,大数据的随机抽样操作就不需要了,有了可用的样本数据,大数据的分析与建模问题就可以通过对样本数据的分析与建模解决,这样就减少了大数据分析对内存的约束。但是,当前的大数据分布式数据块,即HDFS数据块文件不能当作大数据的随机样本使用,因为不同数据块的数据分布不同,数据块的数据分布与大数据本身的数据分布也不同,简单地将数据块当作大数据的随机样本数据使用,会产生统计意义上不正确的结果。
针对当前大数据分析的技术瓶颈,本文介绍一个新的将统计方法与集群计算融合的大数据分析解决方案。针对分布式大数据抽样的问题,本文提出大数据随机样本划分(Random sample partition,RSP)模型来表达分布式大数据。RSP模型同样将大数据划分成小的数据块分布式存储在集群的节点上,但每个数据块的样本数据分布与整个大数据的样本数据分布保持一致,这样就可以将存储在节点上的数据块文件直接拿来当作随机样本数据使用,采用统计中普遍使用的样本估计方法估计大数据的统计量,采用机器学习中的集成学习方法建立大数据集成学习模型。基于RSP数据块的大数据分析不需要对整个大数据进行计算,极大地降低对内存的需求,具有更大的数据扩展性,突破了TB级大数据的计算技术瓶颈。
本文首先介绍大数据随机样本划分模型的定义、存在性定理和大数据随机样本划分的生成算法。然后介绍了基于RSP数据表达模型的大数据渐近式集成学习框架——Alpha框架以及基于此框架和RSP数据块的大数据分析方法,包括大数据探索与清洗、大数据概率密度函数估计、大数据子空间学习、大数据半监督集成学习、大数据聚类集成和大数据异常点检测等。最后总结采用RSP数据模型和Alpha框架进行大数据分析的优越性和创新性。
1 随机样本划分模型
随机样本划分模型的核心思想是将大数据文件划分成许多小的随机样本划分数据块文件,即每个数据块文件是大数据文件的一个随机样本数据。这样的划分给大数据分析带来两个好处:(1)随机样本数据可以直接通过选择数据块文件获得,不需要对大数据的单个记录进行抽样,避免了分布式大数据随机抽样的操作;(2)通过对少量数据块文件的分析和建模即可得到大数据的统计估计结果和模型。采用随机样本划分模型,大数据分析的工作转变成对随机样本数据块文件的分析与建模,极大地减少了大数据分析的计算量,提高了大数据分析的能力。本节对大数据随机样本划分的理论基础和大数据随机样本数据块的生成方法进行详细阐述。
1.1 RSP模型的理论基础
在定义随机样本划分之前,本文首先定义大数据划分。
定义1(大数据划分)设T是由操作T生成的大数据的一组子集D1,D2,…,Dk构成的集合,即T={D1,D2,…,Dk},如果T满足以下两个条件,则称T是D的一个划分:(1)对于任意的i,j∈ {1,2,…,k}且i≠j,Di∩Dj= ∅;(2),同时称T是大数据D的一个划分操作。
由定义1可知,在HDFS分布式文件系统中,大数据表达成数据块文件的划分,HDFS数据块文件被分布式存储在集群节点上。在一般情况下,HDFS数据块文件不能作为大数据的随机样本数据使用,因为数据块文件的数据分布与大数据的数据分布不一致。为解决分布不一致的问题,本文给出大数据随机样本划分定义[12]。
定义2(随机样本划分数据块)设T是大数据D的一个划分操作,T={D1,D2,…,Dk}是由T生成的D的含有k个子集的一个划分,记和F(D)分别表示数据子集Dk和大数据D的概率分布函数。对于任意k∈{1,2,…,k},如果成立,表示分布的期望,则称T是D的一个随机样本划分,D1,D2,…,Dk是D的随机样本划分数据块,简称RSP数据块。
下面给出定理1,确保对于任何大数据都可以将其表达成一组RSP数据块,本文将RSP数据块称之为大数据随机样本划分数据模型,或RSP模型。
定理1(RRSSPP存在性定理)设大数据D有N个记录,N1,N2,…,Nk,是满足的k(k>1)个正整数,则存在一个划分操作T,使得由T生成的大数据划分T={D1,D2,…,Dk}是D的随机样本划分,其中Dk含有Nk个记录,k∈{1,2,…,K}。
证明:对于任意给定的含有N个对象的大数据D={x1,x2,…,xN},随机选取一个N元排列τ={τ1,τ2,…,τN}。 将D的全部N个对象按τn(n=1,2,…,N)值的大小重新排序,得到D′={x′1,x′2,…,x′N},其中x′n=xτn。将D′按顺序切分成k个子集D1,D2,…,Dk,其中每个子集分别含有N1,N2,…,Nk个记录。则对任意Dk,k∈ {1,2,…,K}以及D中任意一个元素xn,n∈ {1,2,…,N},有成立。记F(x)和F(x)分别表示数据子集D和大数据D的概率分布函数。对任意kk实数x,由样本分布函数的定义知,D中取值不大于x的对象数为N×F(x),所以Dk中取值不大于x的对象数的期望为,所以Fk(x)的期望为。由k的任意性知T={D1,D2,…,DK}为大数据D的一个RSP。
简便起见,这里只考虑对象取值为一维时的情况。当对象取值为向量时,证明方法类似。定理1保证了对于任意大数据,本文都能通过随机样本划分操作将它转换成RSP表达。由定义2可知,每个RSP数据块的概率分布函数与大数据D的概率分布函数保持一致性。但是,这种一致性是在期望意义下的,所以每个具体的RSP数据块的概率分布函数与大数据D的概率分布函数不完全相同。当然,RSP数据块之间的概率分布函数相似度也有所不同。相似度越高,两个数据块之间相互表达的准确度越高。
给定一个大数据D的随机样本划分T,本文采用如下公式计算两个RSP数据块的概率密度相似性和RSP数据块与D的概率密度相似性。首先,如果,i,j∈{1,2,…,K}且i≠j,满足
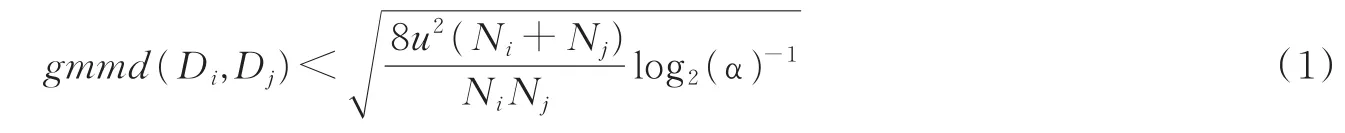
则称Di和Dj具有α显著性水平下的概率分布一致性,其中gmmd(·,·)为基于再生核希尔伯特空间核函数kernel(·,·)构造的推广最大平均差异(Generalized maximum mean discrepancy,GMMD)[13-14],表达式为
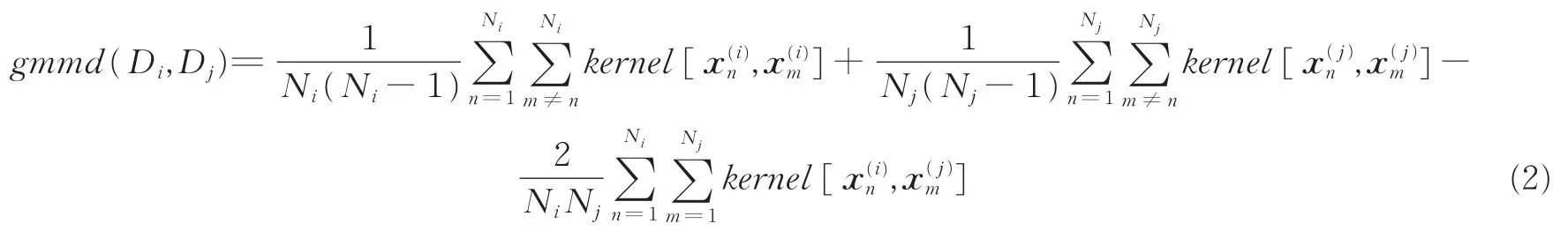
式中:Ni和Nj为数据块Di和Dj包含记录的个数,u为核函数kernel(·,·)的上界,kernel(·,·)可以选择径向基函数核。之后,构造个数据块对(D,D),i=1,2,…,K-1,j=i+1,i+2,…,K,如果式ij(1)成立的次数大于等于,其中为正态分布的分位数,则将D1,D2,…,DK判定为α显著性水平下的概率同分布数据块。在实践中,本文可以用式(1)来检验RSP的大数据表达,也可以在RSP抽样过程中通过式(1)来选择RSP数据块。
1.2 RSP模型的生成方法
定理1的证明给出了一个RSP数据模型的生成方法,但此方法需要对整个大数据进行排序,当大数据的对象数很大时,在分布式计算环境下对大数据的排序是计算量很大的操作,费时或者难于完成。
为了解决分布式环境下大数据RSP的生成问题,本文提出了分为两步的计算方法[15]:第一步先将大数据切成P(P> 1)个较大的数据块D1,D2,…,DP,再将每个数据块按定理1证明中的方法分别随机打乱,切分成Q(Q> 1)个更小的RSP数据块Dp1,Dp2,…,Dp,p=1,2,…,P,生成P个RSP集合;第二步将每个RSP中的对应RSP数据块D1q,D2q,…,Dq,q=1,2,…,Q,合并生成新的数据块D′q,新生成的大数据划分D′1,D′2,…,D′Q是大数据的一个RSP。这一方法的正确性可以通过定理2证明。
定理2设D1和D2是分别含有N1和N2个对象的两个数据块,D1·和D2·分别是D1和D2的含有N1·和N个对象的RSP数据块,当2·时,D1·∪D2·是D1∪D2的 RSP 数据块。
证明:设D1和D2的概率分布函数分别为F1(x)和F2(x),D1·和D2·的概率分布函数分别为F1·(x)和F2·(x),则有E[F1·(x)]=F1(x)和E[F2·(x)]=F2(x)。对于任意实数x,D1·和D2·中取值不大于x的对象数分别为N1·×F1·(x)和N2·×F2·(x),所 以D1·∪D2·的概率分布函数为。同理可得D1∪D2的概率分布函数为。从而可计算F1·∪2·(x)的期望为
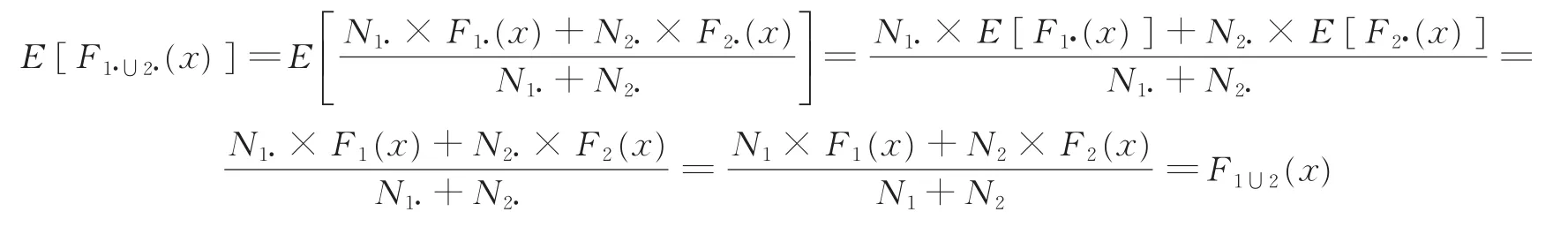
所以,D1·∪D2·是D1∪D2的 RSP数据块。
简便起见,这里只考虑对象取值为一维时的情况。当对象取值为向量时,证明方法类似。根据定理2进行推理,可以证明合并后的每个数据块都是大数据的一个随机样本,因此,Q个数据块是大数据的一个RSP。图1展示了上述大数据RSP的两步生成算法实现过程。
图2展示一个真实数据HDFS数据块的一个属性分布和RSP数据块的同一属性分布。可以看到,RSP数据块的属性数据分布同大数据的属性数据分布相似,因此RSP数据块可以作为随机样本来分析大数据(图2(b))。HDFS数据块之间的属性数据分布不同,同时与大数据的属性数据分布也不同,因此HDFS数据块不能当作随机样本数据块来用(图2(a)),要想得到大数据的正确结果,必须对整个大数据进行分析。
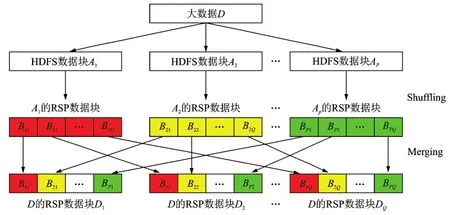
图1 大数据RSP的生成过程Fig.1 RSP model of big data
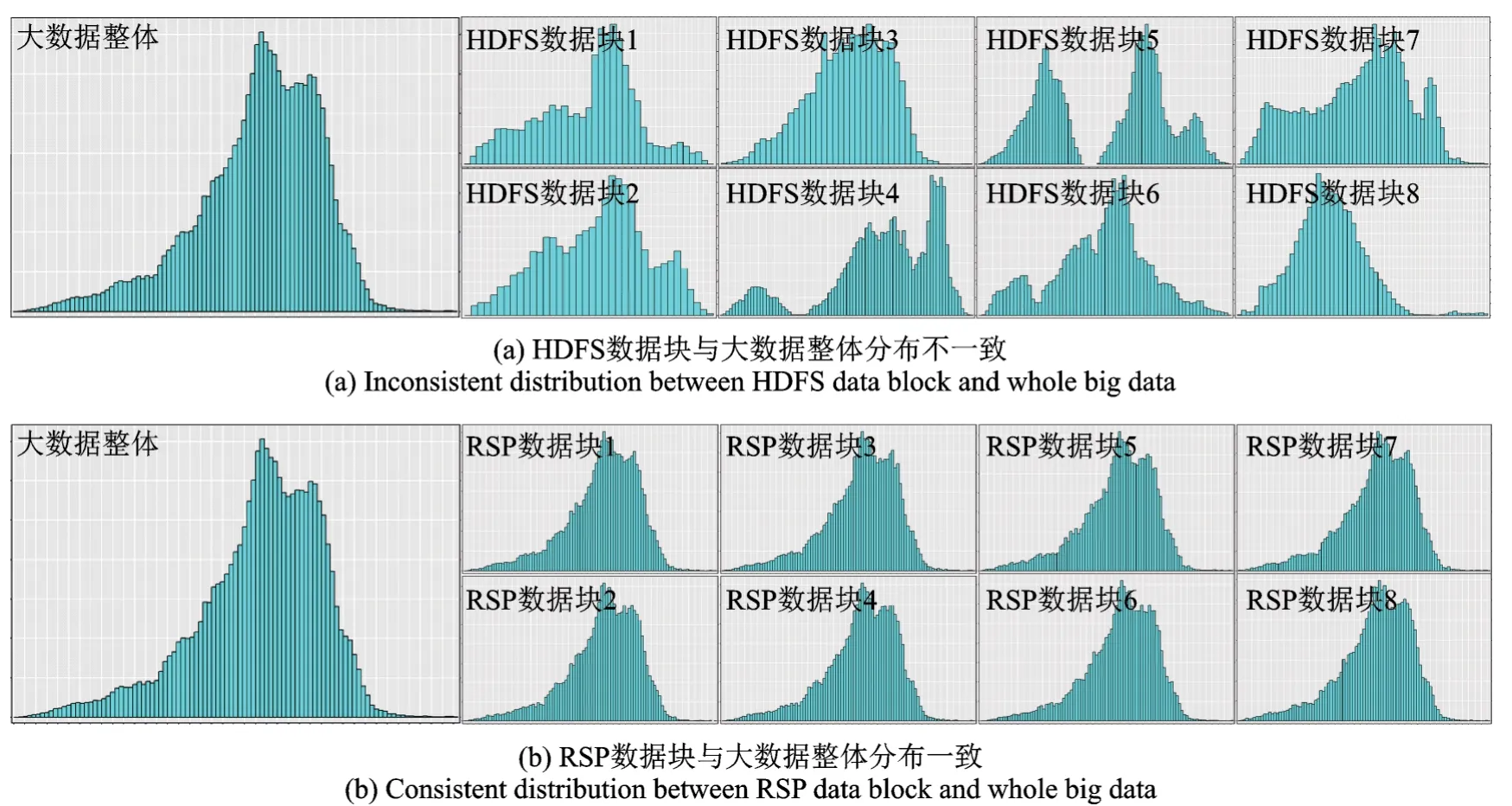
图2 不同数据模型中数据块与大数据整体分布一致性的对比Fig.2 Distribution comparison between data block and whole big data in different data management models
笔者已经在Spark上实现了上述大数据RSP的两步生成算法,初步的实验结果显示,在27个计算节点的集群上,生成1 TB大数据(含100亿个对象,10属性)的RSP(30 000个RSP数据块)大概需要56 min。在实际应用中,对每个大数据的RSP生成只需要一次。
2 基于RSP模型的计算框架
第1节介绍了RSP数据模型的理论基础和在分布式环境下生成大数据RSP的算法。在分布式集群上,针对某个大数据D生成的RSP数据块随机分布存储在计算节点的磁盘上,为了有效地利用分布的RSP数据块对大数据进行分析,本文设计开发了基于RSP数据块的渐近式集成学习框架——Alpha计算框架[16-17]。下面介绍Alpha计算框架和在此框架下的大数据分析流程。
Alpha计算框架是基于RSP数据块的分布式大数据处理与分析框架,其设计思想是基于RSP模型的相关理论。处理和分析一个给定的大数据D,当把D转换成RSP数据块D1,D2,…,DK,并将其分布存储在计算节点磁盘上后,针对任意一个RSP数据块Dk,k∈{1,2,…,K},进行处理和分析都能得到D的一个统计量θk的估计值,而θk估计值的期望值是D的统计量θ值[18]。因此,θk是θ的近似值,存在一定的误差。如果采用多个RSP数据块的来计算θ的估计值,其估计值的误差将随着RSP数据块的增加而下降。
根据上述统计估计原理和分布式环境下分而治之的大数据处理策略,本文设计了渐近式集成学习Alpha计算框架如图3所示,本文仅以分类问题来阐述Alpha框架的工作原理。给定大数据D的RSP数据块集合{D1,D2,…,DK},假设集群中计算节点的个数为Q(Q<K)。采用无放回块抽样随机抽取个RSP数据块,每个计算节点抽取一个,上标(1)表示是第一批抽样;在Q个节点上采用同一算法从Q个RSP数据块训练Q个基分类器,每个基分类器在各节点上独立计算完成;在主节点上构建集成分类器H1;采用独立样本测试集测试H1,如果精度达到了设定的阈值条件,输出H1,训练结束;否则,进行第二批RSP数据块无放回抽样,按相同方式训练第二批基分类器,在主节点上构建集成分类器H2,采用统一样本测试集测试H1∪H2,如果精度达到了设定的阈值条件,输出H1∪H2,否则,进行新的一次RSP抽样和建模过程。不断重复上述过程,直到满足设定的阈值条件,其中J为逼近阈值条件的迭代次数。理论推导可以得出上述渐近式集成学习Alpha框架的收敛条件为
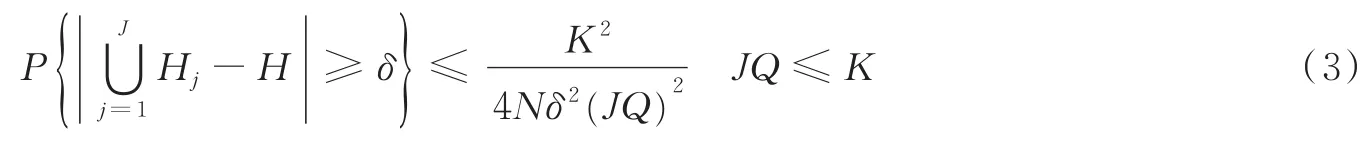
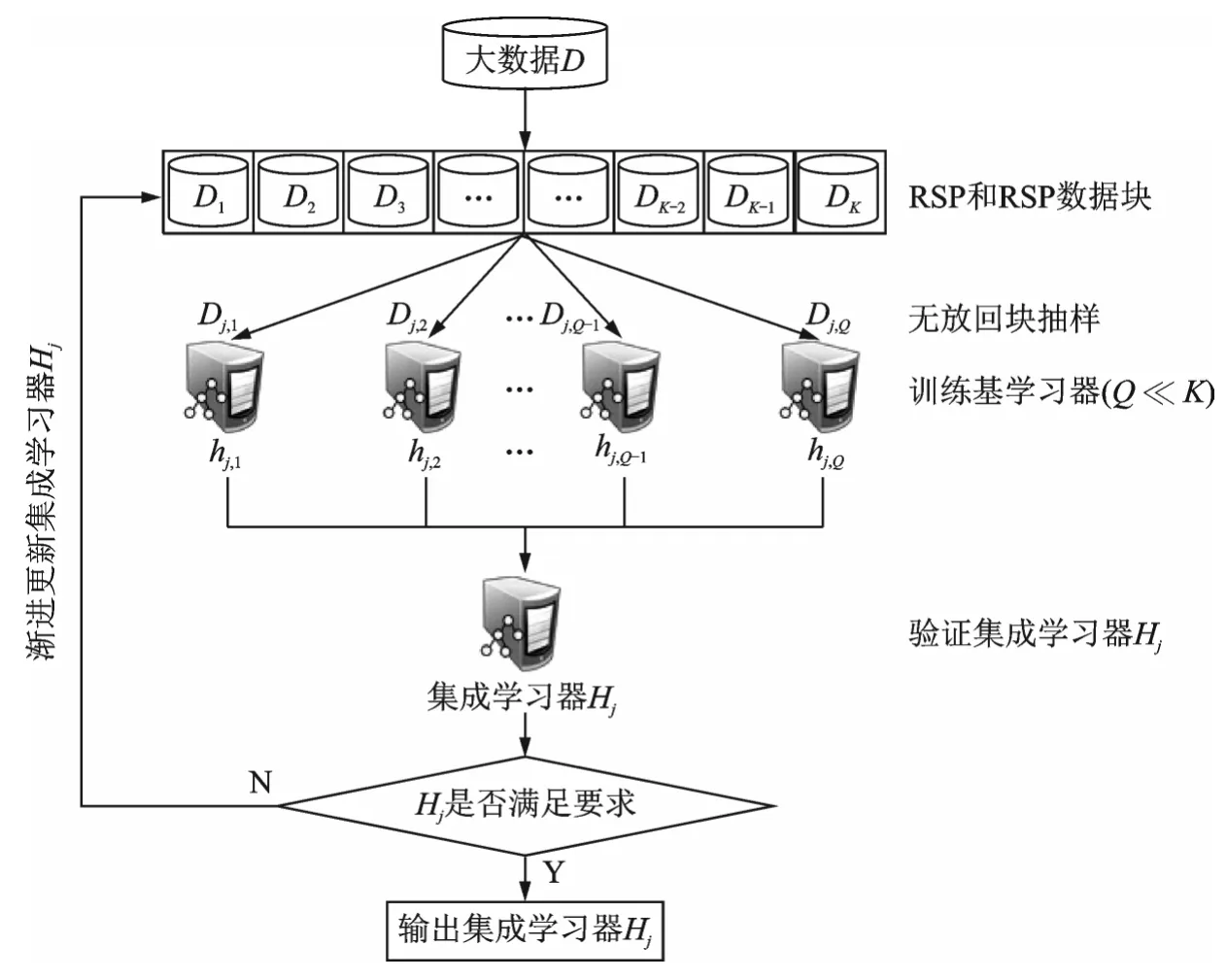
图3 大数据渐近式集成学习Alpha计算框架Fig.3 Alpha framework for big data analysis and computation
式中:H为在大数据D上的学习模型(这是一个期望模型,实际不存在),N为大数据D含有对象的个数,K为RSP数据块的个数,δ>0为正数阈值。由式(3)可见,当RSP数据块的个数K和集群计算节点个数Q确定之后,的取值仅与逼近阈值条件的迭代次数J相关,当J→+∞时,。这表明Alpha框架能够保证学习算法的收敛性。
Alpha计算框架的样机已经在Microsoft R Server、Apache Spark和HDFS集群上实现。图4展示真实数据HIGGS上4个特征的均值和标准差的渐近估计值,每一个子图的横轴代表使用数据的数据量占数据总量的百分比。图5展示HIGGS数据基于RSP数据块的渐近集成分类模型精度与所有数据建模的精度对比,每一个子图的横轴代表使用数据的数据量占数据总量的百分比,其中60个RSP数据块,每个数据块大约183 753条记录;100个RSP数据块,每个数据块110 000条记录;200个RSP数据块,每个数据块55 000条记录。本文从图5中可以发现只用少量的RSP数据块就可以达到从全部数据学习的单一模型的精度,该实验证实了式(3)的合理性。图6是集成学习模型的计算时间与单个模型计算时间的对比,其中图6(b)最右侧的灰色柱代表单个模型计算时间。本文从图6中可以发现基于RSP数据块的Alpha计算框架极大地提高了集群计算的效率。
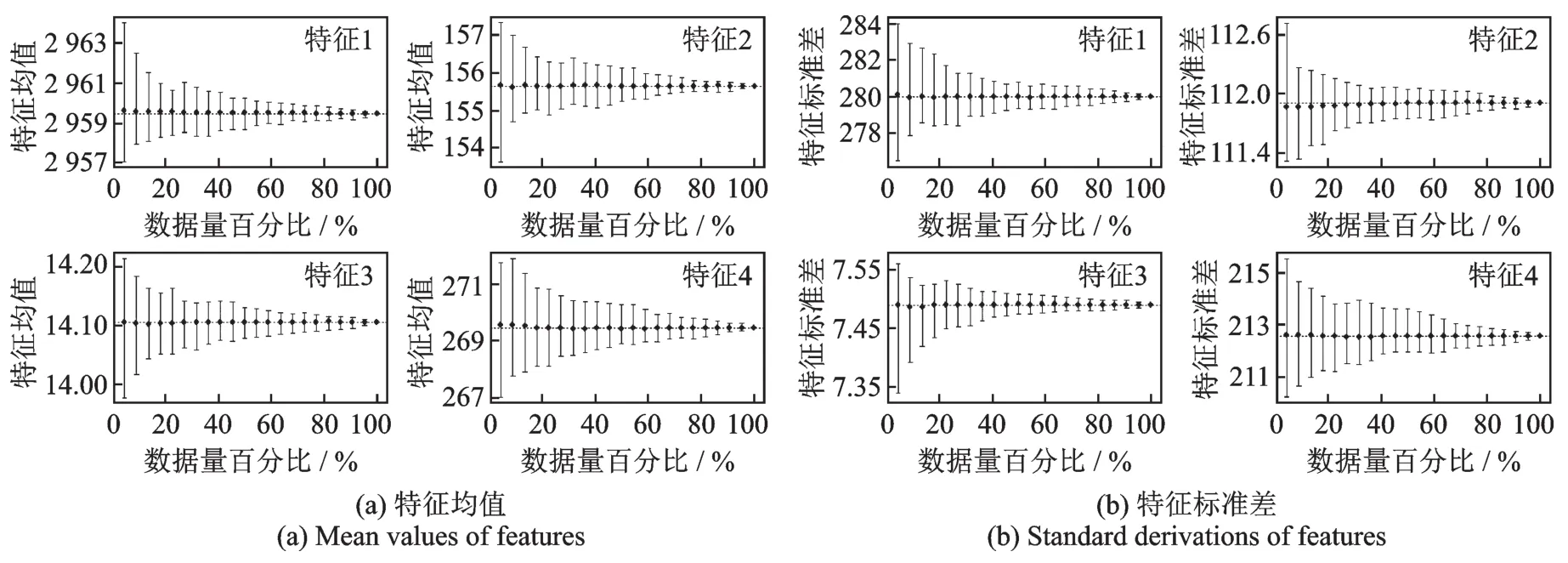
图4 HIGGS数据4个特征均值和标准差的渐近估计值Fig.4 Feature approximations of mean and standard derivation in HIGGS data set
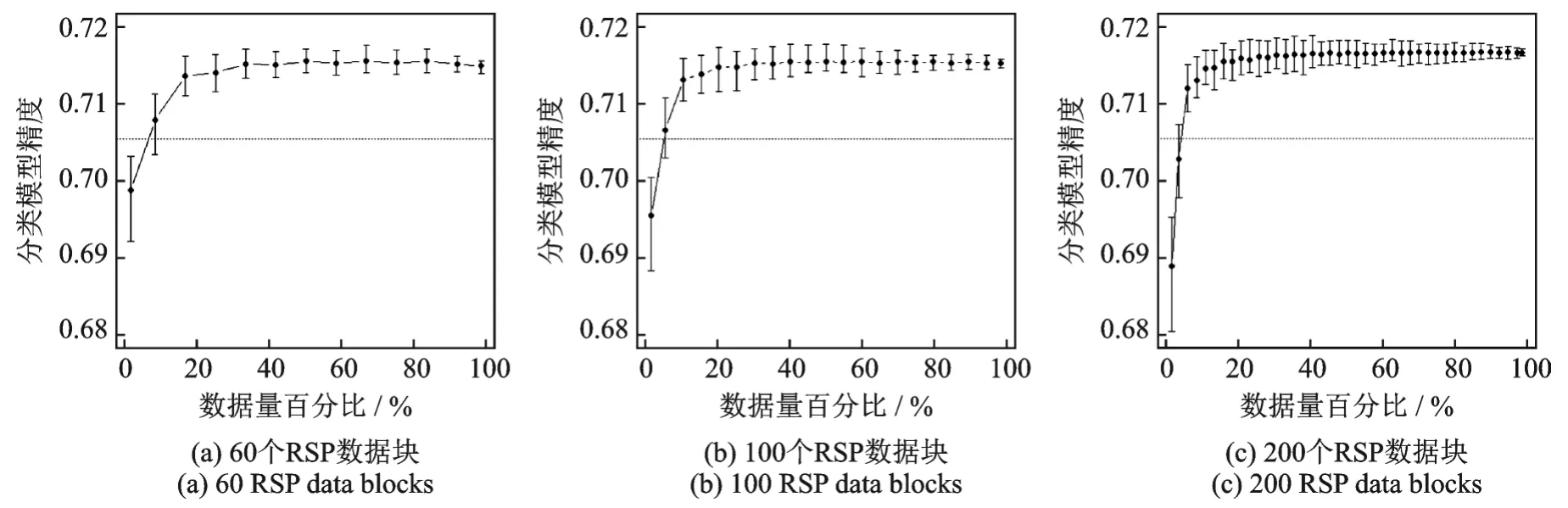
图5 基于RSP数据块的集成分类模型与基于所有数据建模的精度对比Fig.5 Accuracy comparison between asymptotic ensemble learning model and single learning model
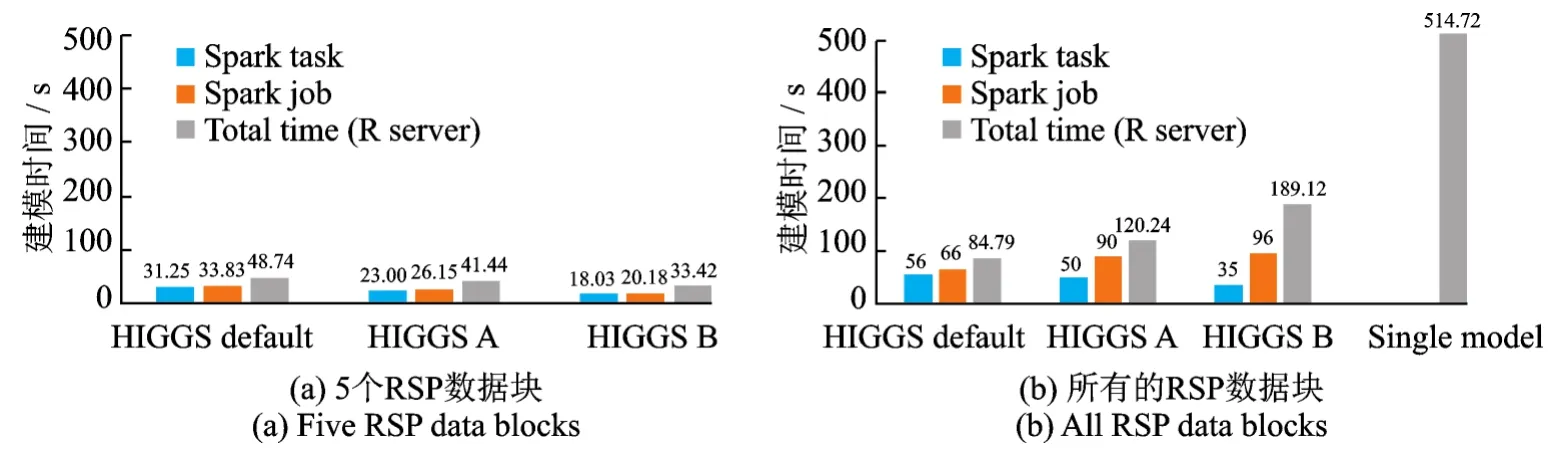
图6 渐近式集成学习模型与单个模型计算时间的对比Fig.6 Time comparison between asymptotic ensemble learning model and single learning model
3 基于RSP模型的大数据分析技术
基于RSP模型和Alpha计算框架可以设计开发一系列新的分布式大数据分析方法和技术,这些分析方法的核心思想是:根据分而治之的策略,在分布式集群系统上利用Alpha计算框架,随机抽取RSP数据块的子集计算大数据的统计量估计值,建立大数据的集成模型。本节介绍以下6种基于RSP数据模型和Alpha计算框架的大数据分析方法。
3.1 数据探索和清洗
数据探索是数据分析的重要步骤,分析一个未知的大数据D,首先需要做的工作是要理解D,要知道D的各属性的分布,了解D的各种数据错误,设计数据清洗流程对D进行清理,改正数据错误。有了D的RSP数据模型后,数据探索和清洗可以在RSP数据块上进行,可以极大地降低工作量,提高数据理解和清洗的效率。
因为RSP数据块具有同整个大数据D一致的分布,可以随机抽取一个或几个RSP数据块,用可视化工具展示数据块属性的分布,通过数据块属性的分布即可理解大数据的属性分布,其原理如图2(b)所示。同理,可以通过处理RSP数据块找出数据的错误,设计清洗错误的过程,再将清洗过程应用在其他RSP数据块。由于错误数据重复出现在RSP数据块中的概率大致相同,在少量随机抽取的RSP数据块中发现的错误数据反映了大数据中的主要错误数据,通过Alpha计算框架的多次迭代,即可发现大数据D中的大部分错误数据。由于错误数据的发现过程是在RSP数据块上进行的,要比从整个大数据上发现错误的效率高。
3.2 概率密度函数估计
概率密度函数(Probability density function,PDF)是随机变量统计特性的集中体现,估计概率密度分布是数据分析的重要任务,也是大数据分析的一大挑战。RSP数据模型提供了一种“局部推断整体”的间接式估计大数据PDF的途径。
假设大数据D的属性变量均为连续值,对应的PDF为,RSD数据块D1,D2,…,DK对应的PDF分别为,其中可以通过核密度估计方法求得。直观的想法,由于D1,D2,…,DK与D存在概率分布上的一致性,可以通过建立式(4)确定为

式中Q(Q<K)是随机抽取的RSP数据块个数。即在α显著性水平下大数据D的PDF可由RSP数据块PDF的均值表示。可以看出,可以采用Alpha计算框架获得,通过将在集群节点上独立地算出。
3.3 有监督子空间学习
采用RSP样本数据建立分类或回归集成模型,由于RSP数据块分布的一致性,降低了基分类器的多样性,影响集成模型的精度。为增加基分类器的多样性,可以采用子空间抽样的方法,对RSP数据块抽取不同的属性子集来学习基分类器。给定大数据D的属性变量集合{A1,A2,…,AM}和Q个RSP数据块集合{D1,D2,…,DQ},为每个RSP数据块随机抽取一个L维的子空间,得到Q个不同的子空间。
根据Alpha计算框架,子空间抽样可以在节点上的RSP数据块独立进行,对每个RSP数据块的子空间数据进行独立建模,生成基分类器{h′1,h′2,…,h′Q},最后获得集成模型

由于每个基模型h′q,q∈{1,2,…,Q}从不同子空间数据得来,因此增加了基模型的多样性,提高渐近集成学习模型的性能。
3.4 半监督集成学习
对于含有少量有标签数据和大量无标签数据的大数据,采用RSP数据模型在Alpha计算框架下最大限度地利用无标签数据提升基于有标签数据训练的集成模型的泛化能力。半监督集成学习[19]是一种融合了半监督学习和集成学习优势的学习方法,基于RSP数据模型,在Alpha计算框架下可以设计如下集成学习算法:
(1)随机抽取Q个RSP数据块{D1,D2,…,DQ},将这些数据块中的有标签数据抽取出来合并成一个训练数据集DT。
(2)对DT做Q次放回抽样生成Q个训练数据集,放回{D1,D2,…,DQ}的相应节点,根据Alpha框架训练个基模型,并构建集成模型。
(3)使用H(0)对{D1,D2,…,DQ}中的无标签数据进行打标。
(4)将打标的数据与同节点的相应训练数据合并,重新训练一组基模型,并构建集成模型。再用H(1)对中无标签数据进行打标。不断重复上述过程,直至集成模型表现稳定。
获得稳定的模型H后,用它对其他没有选择的RSP数据块中无类标的数据进行打标。如果有类标的数据极少,可以抽取大数据所有有类标的数据做有放回抽样。
3.5 聚类集成
基于大数据D的RSP数据块{D1,D2,…,DK}的聚类集成是一大挑战,因为已有的聚类集成方法都是集成同一数据集的不同聚类结果,而被聚类的对象是同一对象集合[20],在集成不同聚类结果时,有相同的对象标识可以参考。而不同的RSP数据块包含不同的对象集合,在集成不同RSP数据块聚类结果时没有相同的标识可以参考。因此,需要采用不同RSP数据块的簇的统计特征集成聚类结果。
基于RSP数据块的聚类集成过程可以采用不同的聚类算法[21-22]生成每个RSP数据块的聚类簇,可以采用不同的簇之间的相似性度量,可以采用不同的簇合并方法进行簇的合并,整个过程可以在Alpha计算框架上完成。
3.6 异常点检测
异常点检测[23]是数据分析的一个重要任务,在许多领域有应用需求,大数据中的异常点检测也是当前的一大挑战,RSP数据模型提供了异常点检测的新途径。
基于RSP数据块的异常点检测通过两步进行:第一步是从随机选出的Q个RSP数据块{D1,D2,…,DQ}中发现异常点,已有的异常点检查算法都可以在这一步采用;第二步是判定从每个RSP数据块发现的异常点是否是大数据的异常点。假设数据,是RSP数据块Dq的异常点,可以用下面两种方法判断是否为大数据D的异常点。
(1)基于数据块的概率密度函数判定法:对于给定的阈值ε>0和显著性水平α,检验,p=1,2,…,Q且p≠q成立的次数,如果未达到某种假设检验的标准,则认为是大数据的异常点。
(2)基于数据信息量的判定法:即将RSP数据块Dq的异常点加到其他RSP数据块上会否引起信息量的激增。通常情况下,非异常数据的增加不会引起数据集信息量的激增。如果未能够引起大多数RSP数据块信息量的激增,那么则认为是大数据的异常点。
4 结束语
RSP数据模型将大数据划分成随机样本数据块文件分布式存储,由于任何一个RSP数据块的分布都与大数据的分布保持一致,因此大数据的统计特征可以用RSP数据块来估计,大数据的分类、聚类、回归等模型可以用随机抽取的少量RSP数据块来建立。Alpha计算框架提供了分布式环境下迭代渐近式的集成模型学习流程。任何大数据,一旦转换成RSP数据块后,大数据的分析就转换成RSP数据块的分析。因为单个RSP数据块就可以在集群的单个节点上独立计算,采用本文介绍的RSP数据模型和Alpha计算框架技术进行大数据分析极大地降低了集群计算资源的约束,提高了集群系统大数据处理与分析的扩展能力,在有限计算资源的集群上可以实现TB级大数据分析和建模能力。
对比现有的分布式大数据计算方法和分析技术,RSP数据模型在两个方面取得了突破:
(1)在分而治之的策略下,用随机抽取的少量RSP数据块计算取代了大数据所有数据块的计算,提高了计算效率和扩展能力;
(2)由于大数据的随机样本已经预先生成,不再需要分布式环境面向大数据所有记录的简单随机抽样操作。如果需要随机样本数据,随机抽取RSP数据块就可得到,计算量大大地降低。
第一个问题是目前大数据分析的主要技术瓶颈,Hadoop MapReduce和Spark采用的HDFS文件系统存储大数据,由于HDFS的数据块不是大数据的随机样本,因此要取得正确的结果,必须计算整个大数据,计算能力受到计算资源限制,特别是内存资源的约束。
除上述两个基本突破外,RSP数据模型和Alpha计算框架还带来了如下两个优势:
(1)由于每个数据块在单个计算节点独立计算,现有的串行算法都可以直接使用,不再需要并行算法,降低了算法并行化的成本。
(2)可以实现RSP数据块存储系统与大数据分析平台的分离。因为采用Alpha计算框架,在分批计算基模型时,可以从RSP数据块存储系统中随机抽取少量RSP数据块,下载到分析平台建模和集成,不需要在存储RSP大数据的平台上直接运算,可以很好地实现大数据的存储共享。
RSP数据模型和Alpha计算框架是为TB级以上大数据的分析设计开发的新技术,许多大数据分析任务[24-25]都可以采用此技术完成。目前笔者团队所完成的工作还只是实现一些基本功能,很多理论和技术问题需要深入研究解决。但是,初期的成果已经展示出这一新技术的发展前景,为大数据分析提供了一个新的可选择方案,可以促进大数据的分析与应用技术的发展。
