基于重要性采样的优势估计器
2019-06-11刘全姜玉斌胡智慧
刘全,姜玉斌,胡智慧
(1. 苏州大学计算机科学与技术学院,江苏 苏州 215006;2. 苏州大学江苏省计算机信息处理技术重点实验室,江苏 苏州 215006;3. 吉林大学符号计算与知识工程教育部重点实验室,吉林 长春 130012;4. 软件新技术与产业化协同创新中心,江苏 南京 210093)
1 引言
强化学习(RL, reinforcement learning)[1]利用智能体(agent)与环境交互获得的反馈信息进行自学习以获得最优策略。根据状态特征的表示方式,可以将强化学习分为3种:1)表格形式,将所有状态特征存储在表格中,每个状态都可以被准确地表达出来,这种形式有利于理论分析,但是无法应用到大规模状态空间和连续状态空间任务中;2)线性函数近似,通过人工标注或构造编码函数[2]等人为的方式产生每个状态的特征,状态的特征值在学习中不会改变,使用线性函数近似将强化学习的应用范围扩大,但是无法处理非线性任务;3)非线性函数近似,利用多层神经网(MLP, multilayer perceptron)[3]、卷积神经网络(CNN, convolutional neural network)[4]等深度网络对状态进行特征提取,状态的特征值在学习中不固定。深度网络将强化学习从线性任务推广到非线性任务,但是深度网络生成特征的不确定性会导致算法的稳定性不足[5]。
深度强化学习(DRL, deep reinforcement learning)将强化学习与深度学习(DL, deep learning)[6]结合,在游戏、机器人控制、机器人运动等众多领域中取得了引人瞩目的成功。DeepMind公司的Mnih等[7]将强化学习中的Q学习算法与深度网络结合,提出了深度 Q网络(DQN, deep Q-network)模型。DQN将Atari 2600游戏的原始图像作为输入,通过卷积神经网提取状态特征并通过全连接构造 Q值网络。为了保证样本的独立同分布,DQN使用经验重放机制打破样本间的关联,提高了模型的稳定性。DQN在许多游戏中都达到了人类水平,但是经验重放机制会导致模型样本利用率低、收敛速度慢。Mnih等[8]提出了优先级经验重放机制,对样本优先级进行排序,高优先级的样本更容易被采用,提高了样本利用率。Van等[9]将双 Q学习算法扩展到 DQN,提出了双层深度 Q网络(DDQN, double deep Q-network)模型,解决了DQN最大化偏差问题。Wang等[10]将Q值拆分成状态值与动作优势值,提出了竞争深度 Q网络(dueling deep Q-network),能够大幅提升学习效果,加快算法的收敛。
但是上述深度强化学习算法并未解决信用分配的问题[11]。信用分配是强化学习中的众多挑战之一,用于解决动作与长期回报延迟的问题。在强化学习中,解决信用分配问题最常用的方法就是资格迹(eligibility trace)[12]。资格迹的向前观点λ回报最早由Watkins等[13]提出并给出性质,Sutton等[14]提出了向后观点TD(λ)算法,从实践角度简化了资格迹并使其可以进行在线学习,提高了计算效率。Van等[15]通过构造截断式λ回报,将资格迹的向前观点与向后观点统一,提出了真实在线 TD(λ)算法。在深度学习中,为了保证网络参数的稳定性,通常使用批量数据进行训练。使用批量数据意味着无法进行完全在线的训练,并且深度学习提取的特征会随着训练而改变,这使资格迹无法应用到深度强化学习中。为了解决深度强化学习的信用分配问题,Ho等[16]利用λ回报的思想,构造了通用优势估计器(GAE, generalized advantage estimator),提高了样本利用率。Mnih等[17]提出了异步优势行动者评论家(A3C, asynchronous advantage actor-critic)算法,将异步方法与 GAE结合,替代了经验重放机制。在大量减少内存使用与训练时间的情况下,A3C算法在Atari 2600游戏中的表现超越了DQN。Schulman等[18]提出了置信域策略优化(TRPO, trust region policy optimization)算法,使用GAE作为策略函数的估计器,将GAE应用到高维连续动作中,并证明了该算法在随机梯度更新下对策略的改进是单调递增的。TRPO为了保证单调性,每次更新都要计算新旧策略的交叉熵,计算量较大。为此,Schulman等[19]了改进TRPO,提出了近端策略优化(PPO, proximal policy optimization)算法,使用截断的更新步长保证策略改进的单调性。PPO算法在MuJoCo环境中表现优异,但是使用高斯策略进行动作选择会导致边界动作被选择的概率陡然升高,影响值函数的准确性,降低了训练的收敛速度。Fujita等[20]提出了截断动作策略梯度(CAPG,clipped action policy gradient)算法,通过改变边界动作的策略梯度减少了目标函数的方差,提高了算法的稳定性。
本文在 GAE的基础上提出了重要性采样优势估计器(ISAE, importance sampling advantage estimator)。针对高斯策略下截断动作引起的边界动作出现概率陡然升高的问题,ISAE通过引入重要性采样来解决边界动作行动策略与目标策略不一致的问题,同时引入了L参数用于保证数据的上下界不会相差过大。将 ISAE运用到 PPO中,并在MuJoCo平台进行对比实验。实验结果表明,与GAE相比,ISAE能够提高值函数的准确性,且具有更快的收敛速度。
2 相关理论
2.1 马尔可夫决策过程
强化学习通常将问题建模成一个马尔可夫决策过程(MDP, Markov decision process)[21]。本文使用一个无限有折扣的MDP,该MDP可以表示为一个五元组M=<S,A,T,R,γ>,其中,S表示所有状态的集合;A表示所有动作的集合;T:S×A×S表示状态转移概率,表示在状态做出动作到达下一状态的转移概率;R表示奖赏函数,R(st)表示在状态st获得的立即奖赏;γ∈(0,1)表示折扣因子,表示对未来奖赏的重视程度,γ越大,说明当前的MDP越重视长期回报。
在强化学习中,agent的当前状态根据策略π在状态st选择动作at,与环境交互获得奖赏R(st)∈R并到达下一状态st+1。agent到达st+1后重复上述步骤,则可获得当前轨迹的累计折扣奖赏通过定义状态动作值函数来确定动作的好坏,以更好地进行策略改进。
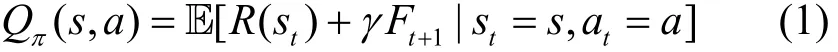
2.2 通用优势估计器
为了解决深度强化学习中的信用分配问题,Ho等[16]提出了通用优势估计器,将TD(λ)的思想运用到优势函数估计器中,优势函数定义为
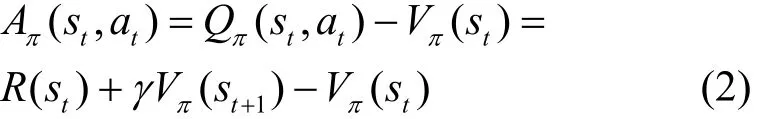
优势函数能够直观地表示动作的好坏,使用式(4)作为目标函数能够大幅提高算法的收敛速度。为了构造GAE,定义n步优势目标函数为

GAE通过加权平均的方式将一步优势目标函数到n步优势目标函数进行融合,即

GAE解决了信用分配问题,在实际使用中可以根据需求调整λ的大小,当λ=0时,相当于把一步优势作为估计器,此时方差小但引入了误差;当λ= 1时,意味着将累计优势作为估计器,此时没有引入误差但方差大[22]。人们可以通过调整GAE的λ参数使算法在方差与误差之间进行权衡,从而达到更好的效果。
2.3 近端策略优化
近端策略优化在置信域策略优化的基础上进行了简化,并提出了新的损失函数,如式(5)所示。

其中,T表示目标损失函数;θ表示深度网络参数;表示新旧策略动作概率的比值;表示目标优势函数,在PPO中使用GAE作为;є表示超参数,用于限制策略的更新幅度,一般取值为0.1或0.2;clip函数的作用是将rt限制在[1-є ,1+є]区间内。PPO利用clip函数限制策略改进,实现了一种近似置信区间的方法,同时简化了算法,提高了算法的灵活性和计算效率。
PPO在连续动作任务中的表现超过了TRPO,说明简化后的算法不仅降低了计算复杂度,同时还提高了收敛速度。图1展示了PPO在连续动作任务中所使用的网络结构。

图1 PPO网络结构
图1的输入为84×84×3的RGB三通道图片,PPO网络结构分为两部分:1) 值函数,输入与包含64个神经元的隐藏层全连接,经过 tanh激活函数后再与 64个神经元的隐藏层全连接,最后再经过tanh激活函数后与单个神经元全连接;2) 策略函数,输入与包含64个神经元的隐藏层全连接,经过tanh激活函数后再与64个神经元的隐藏层全连接,最后再经过 tanh激活函数后与对应可控制动作数量的神经元全连接。策略函数输出值作为高斯策略的均值,高斯分布的标准差初始值为 1,作为单独的参数,不随输入的变化而变化,只与训练阶段有关。
3 重要性采样优势估计器
3.1 截断动作带来的问题
在连续动作任务中,通常采用高斯分布作为动作选择的策略函数,即
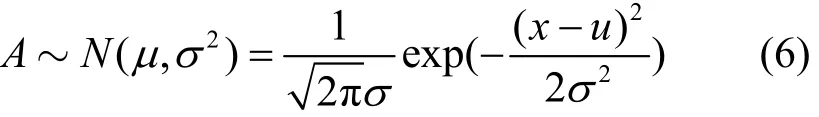
其中,A表示策略选择动作的分布,N表示高斯分布,μ表示高斯分布的均值,σ表示高斯分布的标准差。使用高斯策略的原因主要有两点:1)确定性策略函数由于没有随机的探索动作,容易导致策略进入局部最优,无法学习到最优策略,使用随机的高斯分布作为策略函数能够保证动作空间得到充分的探索;2)连续动作任务无法像离散动作任务那样将所有动作枚举出来,因此采用高斯分布的方式表示策略函数。图2展示了均值为0、标准差为1的高斯策略函数的概率密度。
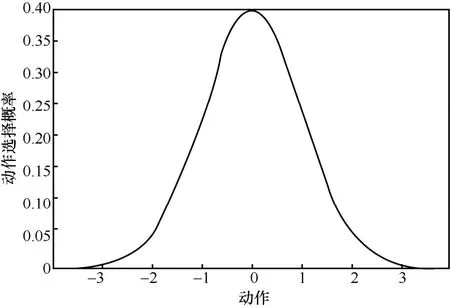
图2 均值为0、标准差为1的高斯策略函数的概率密度
高斯策略函数能够解决连续动作任务中的动作选择问题,但是在 MuJoCo环境中可能会因为截断动作导致性能下降,例如,在HalfCheetah任务中,动作空间为[-1.0,1.0]6,这表示agent需要控制6个范围在[-1.0,1.0]的连续动作。为了保证算法的顽健性,当策略函数给出超出边界的动作时,这些动作都会被约束到范围的边界,即大于1的动作视为1,小于-1的动作视为-1,这会导致边界动作选择的概率大大增加。这种现象会引起2个问题:1)值函数因为边界动作出现概率的升高无法得到准确的评估,使网络的稳定性受到影响,从而导致算法收敛速度变慢;2)策略函数网络通常输出高斯分布的均值,高斯分布的标准差会随着训练的推进逐渐减小,边界动作选择概率的异常升高会导致均值的偏离,从而影响策略函数的改进,导致算法的性能下降。
3.2 构造重要性采样估计器
为了解决截断动作带来的问题,本文引入了重要性采样[23],重要性采样率ρ为

其中,π(s,a)为目标策略,b(s,a)为行动策略。目标策略是算法要评估并计算值函数的策略,行动策略是实际进行动作选择的策略。高斯策略的重要性采样定义为

其中,PDF是概率密度函数(probability density function),PDF(st,at)表示状态st选择动作at的概率;CDF是累计分布函数(cumulative distribution function),CDF(st,at)表示状态st选择动作小于或等于at的累计概率;[a,b]表示动作空间的范围,当动作在区间或者区间边界外时,目标策略与行动策略不一致,需要计算相应的重要性采样率,例如当动作在(a,b)中时,目标策略与行动策略一致,则重要性采样率为1。
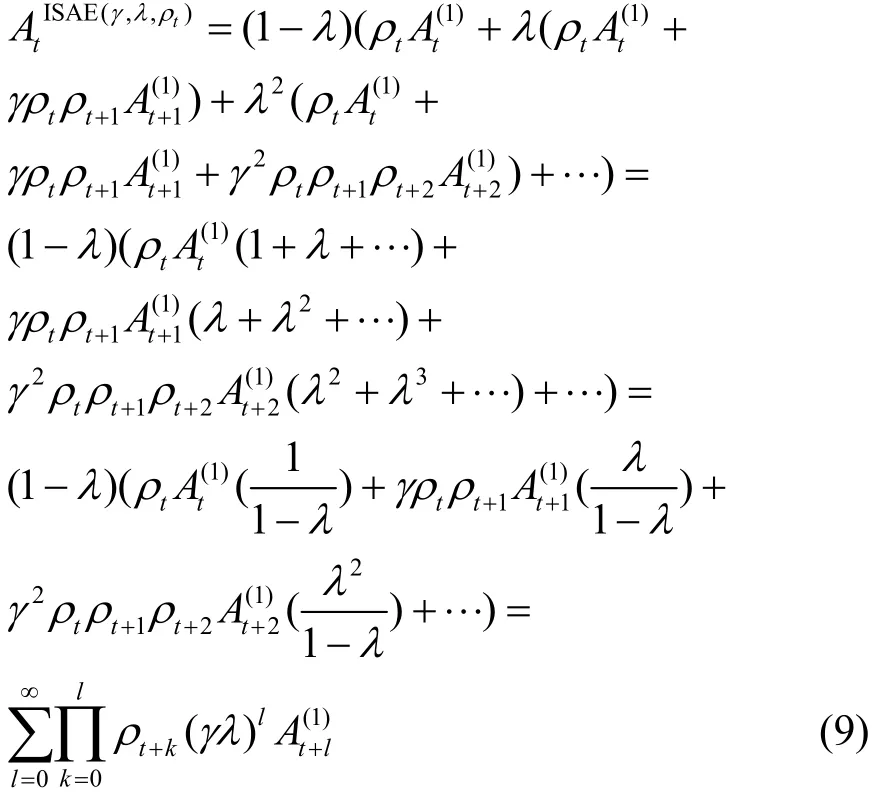
本文将式(8)运用到GAE中,提出了重要性采样优势估计器,并推导出简化后目标函数的计算式为
相较于式(4),式(9)增加了重要性采样的部分,可以计算目标函数。在计算复杂度上,tρ的复杂为O(1)。由于使用批量更新,计算目标函数时可以从后向前计算,这意味每个时间步不需要重复计算后续时间步的重要性采样,每个时间步可以利用后一时间步计算好的数据,因此每个时间步的计算复杂度与 GAE相同,为O(1)。在空间复杂度上,由于需要记录每个时间步的重要性采样率,因此需要增加O(N)的空间。
ISAE主要对目标函数进行改进,接下来分情况讨论ISAE的作用。
1) 当策略生成的动作在动作区间内时,目标策略与行动策略相同,ISAE中的重要性采样为1,此时通过ISAE计算得到的目标值与GAE相同。
2) 当策略生成的动作超出了动作区间时,将会被视为边界动作,若左边界动作a在目标策略下的生成概率为PDF(s,a),那么边界动作的实际生成概率为CDF(s,a),即小于或等于左边界a所有动作生成概率之和,右边界动作同理。这会造成采样生成的样本中边界动作出现的概率异常升高,值函数将会因为边界动作得到大量更新而产生偏移,而在策略梯度中,动作截断则不会体现出来,导致训练过程的值函数与策略不统一。并且值函数的偏移会导致对于动作评估的不准确,从而影响策略改进,使算法收敛变慢。此时,ISAE使用重要性采样,通过降低更新幅度的方式,解决边界动作值函数由于过度采样导致的高估或低估问题,缓解了值函数的偏移。通过这一改进,可以提高值函数的准确性,降低评估误差,使策略能够正确改进。
在实际任务中,通常会有多维的连续动作空间,这意味着策略进行动作选择时超出边界的可能性大大提高,因此在动作空间维数更多的任务中,ISAE的重要性采样机制将会更频繁地使用,算法收敛速度的提升将更加明显。但是由于ISAE限制了边界动作的更新,导致策略向边界动作收敛更慢,因此在最优策略在边界动作的任务中时,算法的收敛速度会有所下降。
综上所述,ISAE在GAE的基础上,限制了对于边界动作的更新,解决了算法因为动作超出边界导致的值函数与策略不统一的问题,提高了算法的收敛速度和收敛精度。
3.3 ISAE的限制参数L
引入重要性采样在一定程度上解决了截断动作带来的不稳定问题,但是过高或过低的重要性采样率同样会影响算法的稳定性。一方面,由于使用批量更新可能产生过高的重要性采样率(ρt>1),经过多轮的累乘会使误差变得十分巨大,这会导致值函数不稳定,且过高的误差会导致训练无法继续进行。另一方面,由于动作选择的随机性以及计算误差,重要性采样率可能过低,影响后续时间步数据的计算,导致信用分配机制失效。
采用式(9)这种累积的方式计算目标函数,过高与过低的重要性采样率同时出现会使批量更新中的数据上下限差距较大,从而导致网络参数波动较大,收敛速度变慢。因此在实际运用中,设定重要性采样上界为 1,下界则引入参数L,L根据具体任务决定。通过将重要性采样率控制在[L,1]中来限制边界动作的更新幅度。
4 实验及结果分析
为了比较ISAE在具体任务中相较于GAE的差异,本文选取PPO算法作为策略梯度优化算法。
4.1 实验环境与参数设置
本文使用MuJoCo平台作为实验环境。MuJoCo是一个物理模拟器,可以用于机器人控制优化等研究。本文选取MuJoCo平台的8个任务,即Ant、Hopper、HalfCheetah、InvertedDoublePendulum、InvertedPendulum、Reacher、Swimmer和Walker2d进行对比实验。表1展示了不同任务输入的状态空间和输出的动作空间,其中,ℝ表示实数。

表1 MuJoCo平台8个任务的状态空间和动作空间
为了更好地对比ISAE与GAE的性能差异,本文的所有算法均使用相同的参数和Adam梯度下降方法。具体参数设置为梯度下降步长PPO超参数є=0.2,MDP折扣因子γ=0.99,GAE与ISAE信用分配参数λ=0.95。网络更新方式为每轮更新使用2 048个时间步的数据,更新分为10个循环,每个循环将2 048个时间步的数据随机打散分成32个Mini-Batch,每个Mini-Batch用64个时间步的数据对网络进行更新。实验一共训练1 000 000个时间步。
在深度强化学习中,使用不同的随机种子进行训练会影响算法的收敛速度和收敛结果,不同环境下的表现体现了算法的稳定性。为了体现不同估计器之间真实的性能差异,本文所有实验均在相同参数下使用20组随机种子进行训练,得到20组不同的数据。训练阶段中将最近100个情节得到的奖赏的平均值作为实验结果。
4.2 超参数对比实验
为了探究ISAE中L参数对估计器性能的影响,使用不同的L在Swimmer环境中进行对比实验,实验结果如图3所示。从图3中可以看出,当L=0.90和L=0.95时算法的收敛速度最快,当L=0.80和L=0.99时性能下降。当L=0时,ISAE中的重要性采样不会受到L参数的影响,最终的结果和3.3节中分析的一致,当不限制重要性采样的作用范围时,会使批量更新中的数据上下界悬殊过大,导致网络参数产生较大波动,从而引起收敛速度的降低。由于L=0.90和L=0.95时两者的性能与收敛速度相近,因此在4.3节的对比实验中使用这2个参数。
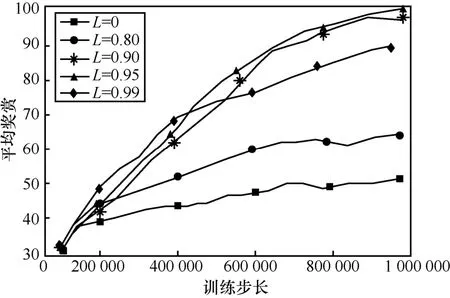
图3 L参数对比实验

图4 3种算法在Hopper、Walker2d、HalfCheetah、Ant任务中的对比实验结果
4.3 ISAE与GAE对比实验与结果分析
为了验证ISAE的有效性,本文使用PPO算法作为基础的梯度优化算法,并在8个基准任务中对比ISAE、GAE和CAPG的性能。每个算法在每个基准实验中都进行 20次不同随机的训练,最终结果由 20次的结果取平均得到。首先,在动作空间维度较高的任务中进行对比实验,图4展示了3种算法在Hopper、Walker2d、HalfCheetah、Ant任务中的训练曲线,横坐标为训练步长,纵坐标为最近100个情节的平均奖赏。
将图 4中的动作空间维数的数量从小到大排布,可以看出,2组 ISAE算法的收敛速度与平均奖赏均优于 GAE与 CAPG,并且当动作空间维度大于 2时,ISAE对于算法性能的提升随着动作空间维度的增加而越发明显。例如,在 Hopper任务中,动作空间的维度为3,ISAE在200 000步之前与GAE和CAPG这2种算法并未有较大差距,直到400 000步之后才逐渐拉开差距。但在动作空间维度为6的Walker2d任务中,ISAE在训练截断的最开始便与GAE和CAPG拉开差距,而在动作空间维数更多的Ant任务中,这种情况更加突出。产生这一现象的原因是动作空间的维度越高,策略生成的动作则越多,动作超出边界的可能性就越大。当动作超出边界时,ISAE会利用重要性采样来限制值函数的更新,保证值函数不会偏离策略太远,提高了策略评估的准确性,并从侧面验证了 ISAE的有效性。
接下来,将3种算法在其他4个MuJoCo控制任务中进行对比实验,结果如图5所示,横坐标为训练步长,纵坐标为最近100个情节的平均奖赏。
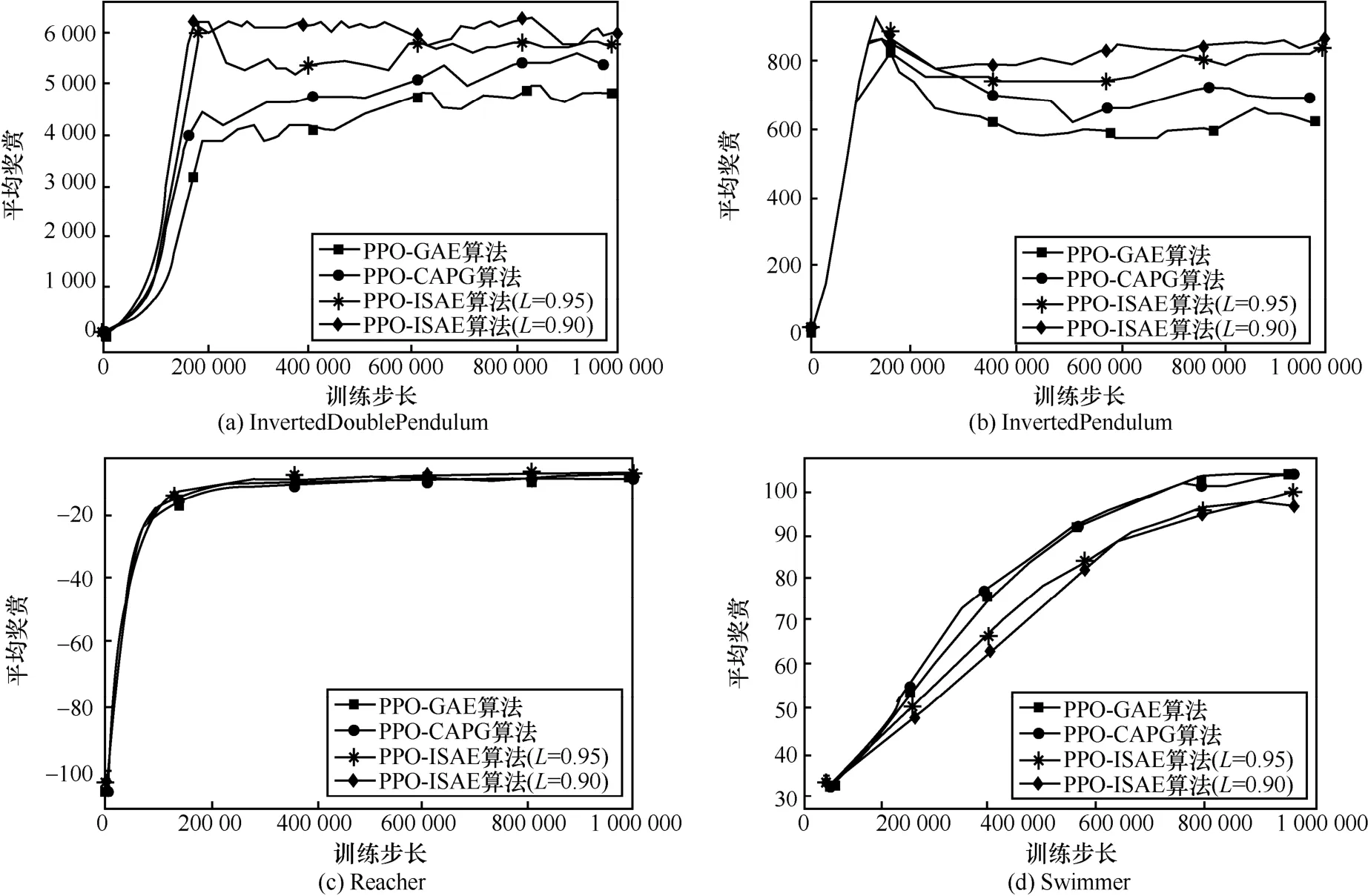
图5 3种算法在其他4个MuJoCo任务中对比实验结果
结合图4和图5可以看出,在Ant、Hopper、HalfCheetah、Walker2d、InvertedDoublePendulum、InvertedPendulum这 6个任务中,ISAE无论是L=0.90还是L=0.95,收敛速度和平均奖赏都要优于GAE和CAPG。不同参数的ISAE在不同的任务中表现得各不相同,这是因为在不同的任务中,最优动作的分布各不相同。某些任务中最优动作更倾向于边界动作,而ISAE则会在一定程度上阻碍策略向边界动作靠拢,这时L=0.95则会更具有优势。在动作空间维度较小的任务中,相较于 GAE和CAPG,ISAE在收敛速度上的优势不够明显,这是因为当动作空间维度较小时,策略生成超出边界的动作概率较小,所以在性能表现上会趋向于GAE,并且会受到任务特殊性的影响。当在某些最优动作倾向于非边界动作的任务中,如InvertedPendulum,该任务由2个部分组成,一个只能水平移动的小车和一端固定在小车中部且可以自由转动的长杆,该任务的目标是控制小车在水平方向移动(动作空间为[-3.0,3.0]1),使长杆尽可能地保持竖立,保持平衡的时间越长,agent得到的奖赏就越大。任何幅度过大的动作(边界动作)都会使长杆的平衡被打破,所以在大部分状态下的最优动作都不是边界动作。由图5可知,ISAE的参数L=0.90性能表现最好,收敛速度最快。平均奖赏在达到最高点后下降的原因是,当策略收敛到最优时,训练不会立即停止,而后续训练中会因为随机动作导致值函数变化,从而影响到策略。这种情况通常会出现在需要精细控制对随机动作敏感的任务(如InvertedDoublePendulum)中,而在对随机动作不敏感的任务(如 Reacher)中,agent控制手臂使末端到达随机指定位置,到达的时间越短,奖赏越高,任务简单且没有干扰因素,虽然算法很快收敛,但是并没有产生波动,3种算法的性能没有较大差距。但是在最优策略靠近边界动作的任务(如Swimmer)中,GAE与CAPG的收敛速度要稍快于 ISAE。产生这一现象的原因是在Swimmer任务中,agent通过控制2个关节让3节机器人在平地上向前移动,规定时间内向前移动的距离越长,得到的奖赏就越高。该任务的最优策略可以参考蛇的行进方式,2个关节向相反的方向发力,到达极限后调转方向,如此循环往复。这意味着最优策略倾向于选择边界动作,而ISAE会阻碍策略向边界动作收敛,L越小,阻碍的力度越大,所以在图4中L=0.95比L=0.90时收敛速度更快。
4.4 测试集结果
为了验证训练得到模型的有效性,将训练后的模型在对应的任务中使用测试集进行比较,平均奖赏结果如表2所示。
本文实验中所使用的测试集都由 20个随机种子下的100个情节(共2 000个情节)组成,最终的结果则由所有情节的累计奖赏取平均得到。这样做一方面对应之前训练的过程,另一方面保证了对比实验不受随机种子的影响。从表2中可以看出,测试集上的结果与训练阶段的结果基本一致,ISAE在大部分任务中的表现明显优于GAE和CAPG,2个不同参数的ISAE的表现相差不大,从总体上看L=0.90略优于L= 0.95。
5 结束语
本文针对在高斯策略下截断动作带来的收敛速度慢的问题,提出了 ISAE。该估计器在 GAE的基础上,引入了重要性采样。利用边界动作的行动策略和目标策略不一致,计算相应的重要性采样率,并将计算好的重要性采样率运用到GAE中。同时,为了保证网络的稳定性,引入了L参数,通过调节L使算法适应不同的任务。将ISAE应用于 PPO算法,通过对比不同的参数确定了L=0.90和L=0.95,并在MuJoCo平台的8个基准任务上与GAE和CAPG进行对比实验。实验结果表明,ISAE相较于GAE具有更快的收敛速度和更优的收敛结果。
ISAE在大部分任务中的表现都优于GAE和CAPG,但是对于最优策略倾向于边界动作的任务,ISAE由于使用了重要性采样会阻碍策略向边界动作收敛,导致ISAE的收敛速度略慢于GAE和CAPG。未来的工作就是完善ISAE,使其能够适用于边界动作为最优策略的任务,使估计器具有更广泛的通用性。
