一种航天器图像分类模型快速学习方法
2019-06-10叶志鹏
叶志鹏,贾 睿,杨 勇,齐 欢,梁 浩
(北京宇航系统工程研究所,北京 100076)
0 引言
近年来,智能航天器正在越来越多地吸引航天从业者的关注[1]。图像识别是航天器智能化的主要条件之一,同时也是计算机视觉、机器学习和模式识别等领域的重要研究课题。随着计算技术及图像传感器的快速发展,拓展了图像采集方式并促进了视觉领域的发展,越来越多的设备具有了获取图像的能力,掀起了设备智能化的浪潮。然而,受限于当前航天器中飞控机的计算能力,目前流行的深度学习模型通常需要海量的数据和存储空间以及大量的计算资源进行长时间的模型训练,若在航天器中应用,需要专用计算设备,增加了航天器的成本和起飞质量。同时,空间场景随着时间推移千变万化,通过解决快速在线训练问题,能够使航天器具有自主目标识别的能力,对空间环境具有更好的适应性。因此,在软件层面提出一种能够根据实际应用灵活调整的快速图像分类方法是十分必要的。
1 研究背景
计算机视觉是实现机器智能的基本途径,其基本载体为图像。计算技术及图像传感器的快速发展为图像的获取与分享提供了极大的便利,图像数据的规模呈现爆发式增长。从行星光学图像获取到深空探测,从视频监控到预警侦察,图像及图像处理技术无所不在。
图像分类是计算机视觉、机器学习和模式识别领域的热门领域之一,在航天领域也得到了广泛的应用[2-5]。图像分类的过程如图1所示。图像分类由分类器学习和测试两部分组成。学习时,利用由图像中提取的特征信息训练分类器,形成分类规则。测试时,每个待识别样本均被描述为一组特征矢量,分类器根据学习到的分类规则判断特征矢量的类别。因此,图像分类可以看作是完成“特征空间”到“类别空间”映射的过程。
图像分类经过多年的发展,提出了很多有效的学习模型[6],包括BP网络[7]、支持向量机[8]和深度学习网络[9]等。BP网络利用样本集训练网络,从而获取其中的规律,能够以任意精度拟合任意函数,且学习规则简单易实现,获得了广泛的应用。但神经网络也具有明显的缺点,如训练效果受限于网络规模、参数设置理论不完善,导致神经网络收敛速度满、分类性能受过拟合效应影响。由于这些问题难以克服,相关研究的热度逐渐降低,研究人员的目光投向了支持向量机。支持向量机利用和函数通过映射的方式对非线性问题进行分类。支持向量机的优点在于具有完备的理论基础,并且适用于小样本学习问题,同时具有较高的学习效率,因此自提出以来得到了广泛的应用。上述两种分类模型均为有监督学习模型,不足之处在于进行学习的前提是需要专家提供样本的类别信息。深度学习方法是对传统神经网络方法的再发展,在语音识别、人工智能等领域取得了很多举世瞩目的成就,是目前图像分类领域最前沿的研究内容之一,深度学习方法认为多层神经网络的训练难度可以通过无监督方式有效克服。深度学习可通过学习深层非线性神经网络,将低等级特征映射到更高等级形式的特征,并从中学习具有层次结构的特征,不仅保留了传统神经网络能够以任意精度逼近复杂函数的优点,而且解决了传统神经网络方法参数调校的难题和容易出现的过拟合问题,显著提高了图像分类的准确性,自提出以来得到了学术界广泛重视,各类研究与应用层出不穷。但是深度学习的缺点也十分明显。首先,深度学习方法弱化了图像特征提取,导致学习过程需要海量的数据才能够获取较为满意的结果,学习效率较低;其次,学习过程需要耗费大量的计算资源,具有极高的时间和空间复杂度,很难在资源受限的箭载计算机上部署,通常需要额外的专用硬件才能够完成分类任务,增加了飞行成本。
本文针对航天器图像分类问题,结合聚类和支持向量机给出了一种箭载计算机图像分类器快速学习方法。
2 算法
本文针对图像分类器学习问题,提出了一种快速分类器训练方法,弱化了有监督学习方法对于样本类别的依赖性。首先,利用聚类方法将未标注样本集根据样本相似性聚成n个散列桶,进行标注后利用散列桶中的样本有针对性地训练支持向量机并完成细分类获取图像的具体类别。具体过程如图2所示。

图2 快速学习过程Fig.2 The fast learning process
样本分类过程如图3所示,利用上述学习过程训练好的分类模型估计待分类样本集中每个样本的类别,获取图像标签。

图3 样本分类过程Fig.3 Sample classification process
2.1 基于聚类的图像散列桶构建
本文采用分类法,通过聚类方法将相似的图像散列到一个桶中,从而提高分类器的训练效率。图像间的相似性利用结构相似性(structural similarity, SSIM)度量[10]。将图像看作两个二维矩阵,对于两幅图像x和y,μx和μy为其平均亮度,σx和σy为标准差,σxy为协方差。C1、C2为常数。
(1)
聚类分析是一种无监督学习方法,即根据一定的度量方法将无标签输入样本数据集合划分为若干个子集的过程。在大数据时代,数据正变得越来越易得。对于图像样本,可利用爬虫程序[11]轻易获取大规模的数据集。然而,数据的标注通常是枯燥和昂贵的,导致采用有标注样本训练分类器的有监督学习方法通常面临样本量不足的问题。因此,无监督学习方法应运而生,较为著名的方法包括聚类分析和部分深度学习方法。本文采用k-means作为聚类分析方法完成无标记样本集的无监督学习。k-means算法的优点在于实现简单,计算和存储复杂度低,无需提供样本类别标签即可进行学习和分类。
在聚类问题中,给定训练样本{x(1),x(2),…,x(m)},k-means算法按下述过程将样本聚类成k个簇。在进行散列时,使用SSIM而非传统的距离度量,能够从均值(图像亮度)、方差(图像对比度)和图像结构3个层次比较图像的相似性,与传统距离度量相比能更有效地反映图像间的相似度,提高了构建的散列桶的质量。
1)随机选取k个聚类质心点mj,j=1,…k;
2)重复下列过程直至所有质心点均不再变化:
①对于每个样例,计算其类别ci

②对于每个类j,重新计算该类的质心
2.2 基于支持向量机的图像细分类
支持向量机是一种有监督学习方法,定义为特征空间上间隔最大的线性分类器。给定一个训练集,SVM的目标是从假设空间中找出一个能够很好地拟合该训练集的模型,从而获得一个决策函数。分类时,利用学习的模型估计待分类样本的类别。SVM的学习策略是将非线性数据映射到高维空间,从而将非线性优化问题转换为线性优化问题,进而寻找高维空间中的最优超平面。超平面是位于两个类别中间、距离两个类别样本点距离相同,能够将不同类别分开的平面。SVM原理示意图如图4所示。

图4 SVM分类原理示意图Fig.4 Principle of SVM classification
对于一个两类分类问题,用x表示数据点,用y表示类别,y={+1,-1}。线性分类器的学习目标是在n维数据空间中找到一个超平面,将两类数据分开。该超平面可线性表示为
ωTx+b=0
(2)
对于样本的分类问题,可通过判断样本属于某个类别的概率进行判别
P(y=1|x;θ)=hθ(x)
P(y=0|x;θ)=1-hθ(x)
(3)
其中,假设函数
(4)
若hθ(x)>0.5,则样本属于y=1的类别,反之属于y=-1的类别。SVM学习的目标是获得θ,满足上述可分条件。定义Lagrange函数
(5)
令θ=maxL(ω,b,α),通过Lagrange乘数法可求解满足约束条件的θ,进而可根据样本属于某一类别的概率判断样本的类别。
2.3 学习方法
传统分类器学习方法利用图像数据集直接训练图像分类器。本文针对航天器图像分类问题,采用分治策略提出了一种分类器快速学习方法。学习时首先利用k-means方法利用结构相似性度量将图像样本集散列为数个类别桶,每个图像样本都对应到一个桶中。接下来对每个桶中的样本训练一个SVM分类器进行分类。该方法具有以下优点:1)能够有效缩小训练样本规模,提高分类器训练速度;2)同一桶内的图像样本具有相似性,不同桶内的图像样本具有较大差异,符合有监督学习分类器训练原则。本文提出的方法与传统分类方法的异同见图5。

图5 本文分类器学习方法与传统方法的异同Fig.5 Difference between traditional and the proposed classifier learning methods dataset
3 实验结果
为了充分评估训练模型的分类效果,本文使用了图像分类领域流行的公开的数据集和自行收集的航天器图像数据集以全面考核分类效果。公开数据集包括PASCAL VOC 2007[12]和Caltech-101[13],各数据集均包含目标类别的标注信息用于训练分类器。PASCAL VOC为图像识别和分类提供了一整套标准化的优秀数据,自2005年起每年举办图像识别挑战赛,吸引了国内外顶尖高校的参与,各种新方法和新模型层出不穷,为图像分类的进步做出了卓越贡献。PASCAL VOC 2007数据集具有完整详细的标注信息,包含20个类别9963幅图像。其中大部分类别包含50幅以上的图像数据,每幅图像的尺寸约为300×200。Caltech-101数据集于2003年由目前计算机视觉领域领军人物Li Fei-fei等创建,数据集组织良好,标注精确,是目前广为使用的图像分类性能评估数据集之一,包含101个类别共9146幅图像。航天器图像数据集包括常见的5种类型航天器共计100幅图像,全部图像收集自公开的互联网图像。测试用DSP为8核心,每个核心可使用1GB内存,时钟频率为800MHz。
实验时将各数据集平均分为训练集和测试集。3种数据集的部分样本示例见图6。通过实验分别对比了单独采用k-means、SVM和本文所提出的分类器学习方法以证明所提方法的有效性。SVM分类器采用LIBLINEAR SVM实现[14]。

图6 图像数据集部分样本示例Fig.6 Samples of image datasets
各数据集总体分类结果见表1,分类性能以均值平均精度(mean average precision, MAP)表示
(6)
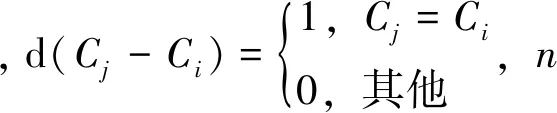

表1 各测试数据集分类结果
从表1结果可以看出,本文提出的分类器学习方法训练的分类器效果优于k-means与SVM分别单独分类的效果,证明了本文提出的粗分类与细分类结合方法是有效的。
图7~图8以混淆矩阵的形式给出了本文所提分类方法在PASCAL VOC 2007和航天器数据集的详细分类结果,图中小于5%的数值均未显示以保证清晰性。对于Caltech-101数据集,由于类别数较多,因此依照惯例给出分类的MAP。从图中可以清楚地看出本文所提出的分类方法各类别的分类正确率及样本误分类情况。

图7 本文方法在PASCAL VOC 2007数据集的详细分类结果Fig.7 Detailed classfication results of the proposed method on PASCAL VOC 2007

图8 本文方法在航天器数据集的详细分类结果Fig.8 Detailed classfication results of the proposed method on spacecraft dataset
表2和表3分别给出了上述方法实时性比较结果。为方便比较,以本文所提方法作为比较的参考值。其中t1=30814.5s,t2=48542.8s,t3=1842.7s;t4=37.51ms,t5=40.12ms,t6=34.46ms。从表中结果可以看出,本文采用的先聚类后分类策略训练耗时和分类性能优于仅采用SVM作为分类器的情况。数据集越复杂,样本类别越多,差异越明显。同时,处理一幅图像的时间稳定在33.33ms(30帧/s)和41.67ms(24帧/s)之间,能够满足实时性要求。结合表1的分类结果可以看出,本文采用的分类方法与k-means分类方法相比,在PASCAL VOC 2007数据集的训练耗时增加54%、分类性能提高了19.1%,Caltech-101数据集训练耗时增加43%、分类性能提高了27.7%,航天器数据集训练耗时增加32%、分类性能提高了20.8%。虽然与k-means相比训练耗时增加,但依然能够满足实时性约束,并且显著提高了分类性能。因此本文提出的方法是有效的,能够满足应用要求。

表2 各方法训练实时性比较(训练耗时)

表3 各方法分类实时性比较(分类耗时)
4 结论
本文提出了一种航天器图像分类器快速学习方法。该方法利用分治策略,通过在聚类方法中引入相似性度量构建图像桶,从而有针对性地训练分类器,能够实现图像分类器的快速学习与分类。通过实验结果可以看出,与传统方法相比,本文所提方法在满足实时性约束的前提下提高了分类效果。
