基于数据自适应加权的叠前深度偏移成像方法
2019-06-04吴成梁王华忠胡江涛马建波
吴成梁,王华忠,胡江涛,马建波
(1.波现象与智能反演成像研究组(WPI),同济大学海洋与地球科学学院,上海200092;2.油气藏与开发工程国家重点实验室,成都理工大学,四川成都610059;3.中国石油化工股份有限公司中原油田分公司物探研究院,河南濮阳457000)
随着“两宽一高”地震数据采集技术的发展和进步,油气地震勘探逐步进入了高分辨率、高保真的反演成像阶段,同时对偏移成像技术要求也越来越高。Bayes估计理论提供了地震波反演成像的基本思想。无论是去噪、偏移成像,还是层析建模等方法技术,都可在(也应该在)Bayes反演框架下讨论,因为地震数据总受随机噪声的干扰,且实测数据总是不完全。
根据Bayes估计理论,假设给定的正演算子能够预测观测数据,在预测噪声和反演解具有先验统计分布特征(一般为高斯分布或广义高斯分布)基础上,定义一定范数意义下的预测误差,寻找预测误差最小的反演解。根据统计分布特征,一般数据误差采用L2范数,模型约束采用L1或Cauchy范数等。若预测噪声为高斯分布,此时的Bayes估计可以在最小二乘意义下实现;进一步地,根据正算子的线性与否,选择用线性最小二乘方法或非线性最小二乘方法求解反演问题。
反问题的本质是Bayes框架下的后验概率密度最大化的决策或估计问题。更具实际计算可行性的使代价函数最小的优化问题的解是反问题的本质。再进一步可落实到算子投影上,TARANTOLA[1]定义了参数空间及其对偶空间、数据空间及其对偶空间,原空间与对偶空间由协方差算子联系在一起,由伴随算子实现数据空间向模型空间的映射,得到模型参数的估计结果。从原空间到对偶空间的投影过程为数据和模型的特征表达过程。模型协方差算子包含地下介质的结构特征信息,体现了模型不同点之间的联系。数据协方差算子包含了观测数据中相干信号的统计特征,高维数据的投影过程等价于数据的特征提取过程,通过对数据进行预处理,可以提取数据中的相关特征。然而在实际应用中很难得到关于数据和模型的协方差(逆)算子,也没有具体的解析公式,如何合理利用数据和模型的协方差(逆)算子成为了研究的重点。
在Bayes反演框架下,TARANTOLA[1]全面深入地分析了地震波全波形反演(FWI)的理论问题。理论上,FWI能够获得地下全波数带参数场分布。然而经典的FWI是强非线性反演问题,实际地震数据的地震波FWI受多种因素(比如:缺失低频长偏移距数据、子波未知、正演算子无法模拟所有波现象、数据噪声类型未知等)的制约,因而会出现收敛到局部极值或者不收敛的情况。解决此类问题的基本办法是将这个强非线性问题转化为一系列线性问题或一个较凸的问题求解[2]。最小二乘逆时偏移(LS_RTM)[3-5]是FWI中典型的线性化子问题,是在背景速度固定的情况下,根据模拟数据与观测数据的波形差异估计地下介质的高波数扰动。从反演的角度理解,常规的叠前深度偏移成像(PSDM)可以认为是最小二乘偏移成像的第1次迭代结果。在FWI和LS_RTM中,学者们对模型参数的正则化[6-7]进行了深入探讨,提出了很多有效的方法,促进了成像质量的提高。但是,他们对数据正则化的关注不充分,如何将数据质量的信息融合在成像过程中以进一步提高成像质量,是一个值得重视的问题。
本文首先从概率论的角度讨论了Bayes框架下的地震波反演成像问题,说明了观测噪声为高斯白噪的情况下,Bayes估计可以在最小二乘意义下实现;分析了吉洪诺夫(Tikhonov)正则化与Bayes估计的等价性;重点分析了连接原空间与对偶空间的协方差算子的作用,证明了数据特征表达和模型特征表达的必要性;从加权最小二乘误差泛函角度分析了数据协方差(逆)算子的作用,初步探讨了数据协方差(逆)算子在偏移成像中的应用;提出了采用倾角扫描和动态时间规整算法来估计数据加权系数;最后,理论和实际数据的数值实验结果表明数据协方差(逆)算子能够有效提高成像质量。
1 Bayes框架下的地震波反演成像
地震波反演成像建立在Bayes框架下估计理论基础之上。整个地震数据处理与反演成像过程(去噪、偏移成像、速度分析、层析建模等)都可认为在此框架下实现[8-9]。
实际地震数据是一个随机过程,实测到的地震数据则认为是该随机过程的一次具体实现。因此,可以将观测的地震数据视为一组随机信号,其具有均值、方差等统计特性,满足一定的概率分布。同样地,反演的地下模型参数也被认为是随机的。假设有模型空间M和数据空间D,在其定义的联合空间M×D上,有同时反映观测数据d以及模型参数m信息的联合先验概率密度ρ(d,m),同样有反映联系观测数据与模型参数物理规律的概率密度Θ(d,m)。利用Bayes公式,可得出联合空间M×D上的后验概率密度σ(d,m):
(1)
其中,k为归一化常数,μ(d,m)为联合空间中关于观测数据与模型参数的均匀概率密度函数。均匀概率密度函数与坐标系统有关,表示特定数据和模型参数化下(选定的坐标系统)概率空间中单位区域内的概率密度函数,代表了对模型空间与数据空间的参数化认识。
进一步地,关于模型空间的后验概率密度σM(m)以及关于数据空间的后验概率密度σD(d)可由边缘概率密度公式计算得到:
假设数据空间与模型空间为两个独立空间,联合空间中的均匀概率密度μ(d,m)为:
(4)
其中,μD(d)和μM(m)分别表示关于观测数据和模型参数的均匀概率密度函数。(4)式表示模型空间中的模型参数化与数据空间中的数据参数化无关。
假设观测数据与模型参数之间的先验信息无关,公式(1)中的联合先验概率密度ρ(d,m)变为:
(5)
其中,ρD(d)和ρM(m)分别表示关于观测数据和模型参数的先验概率密度函数。
地球物理反演(包括其它基于数据的反演)的本质都是从数据中学习到有用的信息并据此得到客观认识。实测数据和要估计参数之间存在一定的关系是反演的基础,若二者没有关系或关系极弱,则不可能从实测数据中得到要估计的参数信息。据此,联合概率密度Θ(d,m)可用关于模型参数的均匀概率密度函数及其对应的条件概率密度函数来表示:
(6)
其中,θ(d|m)为在给定的模型参数m的条件下能够预测观测数据d的条件概率密度函数,表示要反演的参数与实测数据之间存在的关系。均匀概率密度函数μM(m)的引入表示模型参数的选择与地震数据的理论预测无关。
因此,关于模型空间的后验概率密度σM(m)变为:
(7)
(8)
此时的估计结果是用后验概率密度函数得到的加权平均结果。只有当后验概率密度函数是单峰的,譬如高斯或广义高斯,此期望值才有意义。
(9)
方差越大,参数估计的精度在概率意义上越低。
显然,从概率论的角度看,利用公式(8)进行参数估计是合理的。但是目前缺乏有效的方法计算高维模型参数的联合后验概率密度函数。(8)式定义的积分也需要巨大的计算量。为此,将求后验概率密度函数的期望值转为求取使得后验概率密度最大化的模型参数估计结果作为反演解:
(10)
由于公式(7)中的后验概率密度函数较为复杂,无法直接求解该式对应的最优化问题。需要进一步引入先验信息。
首先假设模型空间M和数据空间D均为线性空间,而且模型参数和观测数据在M和D中的采样没有先验认识,则均匀概率密度函数为:
(11)
假设联系观测数据与模型参数之间的物理规律不确定性可以忽略,则:
(12)
假设关于模型参数m的先验信息是具有高斯分布的概率密度函数,则:
(13)
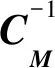
假设数据空间中数据d与实测数据dobs之差满足高斯分布:
(14)
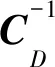
融合上述假设后,模型空间的后验概率密度σM(m)变为:
其中,S(m)为误差泛函。由单调性可知,后验概率密度函数最大化等价于误差泛函最小化:
(16)
进一步地,误差泛函有以下形式:
(17)
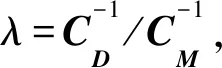
基于Bayes估计理论可以从概率统计的角度理解反演成像,对反演结果进行精确评价。数据协方差(逆)阵和模型协方差(逆)阵携带了数据和模型参数的不确定性信息,据此可以更方便地进行正则化处理。另外,只有当观测数据与模型参数之间存在弱非线性关系,后验概率密度函数为高斯或广义高斯分布时,后验概率密度最大化以及据此发展出的代价函数最小化的方法才有可能用于实际计算。线性的或非线性的最小二乘方法是最基本的算法。
2 数据协方差与模型协方差
从以上分析可以看出,(15)式和(17)式中的数据协方差CD与模型协方差CM在模型参数的优化求解中具有特别重要的意义,关于数据和模型参数的先验信息很多都蕴含在这两个协方差算子中。所谓关于数据的正则化和关于模型参数的正则化处理主要在于如何利用好这两个协方差矩阵。
首先,从算子投影的角度,引入数据和模型参数的原空间以及它们各自的对偶空间。假设M和D为线性空间,M*和D*分别为其对应的对偶空间,m∈M,d∈D,m*∈M*,d*∈D*。令L为从模型空间映射到数据空间的线性算子,即:
(18)
LT定义为从D*映射到M*的线性算子,存在如下的对偶内积关系:
(19)
假设在线性空间Z中存在一个加权算子W,该算子是一个线性、对称、正定的映射算子,它将线性空间Z中的元素z映射到其对偶空间Z*中。线性空间Z中任意两个向量u,z的标量积定义为:
(20)
由加权算子W建立了原空间与对偶空间的映射,其中,W算子的逆算子C=W-1称为协方差算子。令z与z*分别为原空间Z与对偶空间Z*的两个元素,则有:
(21)
因此,可以说协方差矩阵将一个线性空间投影到其对偶空间中。而转置算子定义了从数据对偶空间向模型参数对偶空间的映射关系。标量积的定义引入了协方差算子,建立起原空间的元素到对偶空间元素的映射关系,反之亦然。
从映射的角度看线性反演,核心是建立起原数据空间向原模型参数空间的映射关系。这需要引入伴随算子的概念。L的伴随算子L*定义为从原数据空间D映射到原模型参数空间M的线性算子,且对所有的元素m∈M和d∈D满足:
(22)
经过标量积和转置算子的运算可得到:
(23)
因此伴随算子为:
(24)
最终从原数据空间D映射到原模型参数空间M的映射过程(图1)为:
(25)
据此可以看到,数据和模型的协方差(逆)算子连接起了原空间与对偶空间的桥梁。
接着从线性反演的角度来进一步理解协方差算子。假设联系数据和模型之间的正问题是线性、确定性的,此时正问题(12)式变成公式(18),则对应的Bayes估计后验概率密度为:
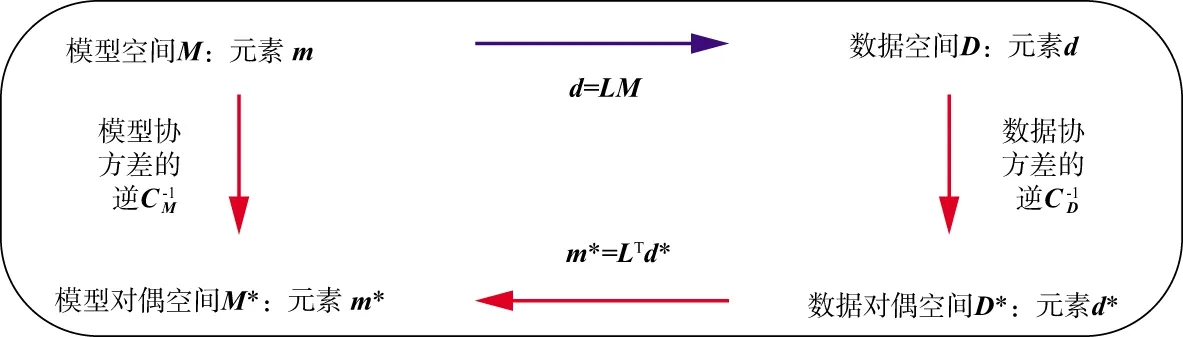
图1 原空间与对偶空间关系示意图解
(26)
误差泛函为:
(27)
对误差泛函求导:
(28)
对应的法方程为:
(29)
法方程的解为:
(30)
已知协方差阵是对称正定阵,可以对其进行正交分解。数据协方差阵对数据向量进行变换可以认为是对数据进行了特征表达。模型参数对应的协方差阵具有同样的作用。因此,可以认为对偶空间是特征数据和特征模型参数各自形成的线性空间。特征数据和特征模型参数之间的关系更紧密、或者更线性、或更弱非线性。转置算子建立起它们之间一对一的投影关系。这对提高反演结果的稳定性非常有益。这是反演问题中正则化处理最本质的内涵。
分别对模型和数据的协方差阵做正交分解:
(31)
其中,U和V分别为左奇异向量和右奇异向量,Σ为奇异值组成的对角矩阵。
整理(31)式,得到特征表达后的解为:
(32)
分析(32)式,得到以下认识:
1)Vd算子是将数据向量d投影到正交坐标系中进行特征提取,相当于对数据进行预处理,提取数据中的相干信号;在高维数据中,可认为是对数据进行方向谱分解,等价于提取局部平面波过程。
2)VL算子是对传播算子进行相应处理,VL对应局部平面波传播算子。(VL)T是对预条件处理后的局部平面波残差(或数据)进行反投影的算子。
3)Umprior算子是将模型参数向量mprior投影到对应的正交坐标系中,等价于在模型参数场中提取线性结构信息。
对数据实施预条件处理,提出特征波[2]的概念,同时配合相应的模型参数特征表达,是反演成像中更为根本的正则化思想。据此可以将一个强非线性问题提成凸问题,或将一个很病态问题提成临近良态问题,降低反问题求解的难度,提高反演成像的精度。
3 数据协方差在反演(偏移)成像中的应用
在地震波反演成像中,人们对模型参数的正则化进行了深入的研究,提出了很多有效的方法,但是对数据的正则化考虑较少。根据前面讨论的基本概念,我们引入数据正则化方法,提出了自适应数据变化的加权叠前深度偏移成像方法。
3.1 加权最小二乘偏移
忽略模型的正则化项,关于数据匹配项的最小二乘误差泛函可写成:
(33)
其中,e表示观测数据与模拟数据的误差(残差)向量。在Bayes反演框架下,误差向量(写成分量形式为:e=(e1,e2,…,eN)为随机变量,该随机变量的协方差矩阵可表示为:
(34)
当误差变量ei(i=1,2,…,N)各分量之间高斯统计无关时,Cee变成Σ,更理想地,变成σ2I。(33)式考虑的就是σ2=1时高斯白噪声情况下的反演成像。根据线性高斯情况下Bayes估计理论假设,对于一般的正问题预测及实际噪声情况,可认为Cee满足经典的正态分布。当反演解趋于(等于)真解时,数据残差满足高斯白噪分布。此时,误差向量e中没有任何有效的信号成分。若正问题不能模拟所有信号成分,或噪声不符合高斯白噪,导致Cee偏离理想的期望情况时,应引入协方差逆算子惩罚掉数据中的相关信号成分以满足上述误差为高斯白噪的假设。因此需要在地震波成像中将(33)式修改为加权最小二乘定义的误差泛函。
加权最小二乘误差泛函可表示为:
(35)
其中,Wd为数据加权函数,表示对数据残差中的不同成分惩罚程度不同,体现了数据残差中不同成分的可靠性。依据上述讨论,最理想的加权函数应取为误差向量e的协方差矩阵的逆矩阵:
(36)
此时,加权最小二乘偏移成像对应的法方程的解为:
(37)
对应的迭代公式可写为:
(38)
其中,k为迭代次数,μk为迭代步长。
然而在实际应用中,很难直接通过数据计算出完整的协方差阵及其逆矩阵。数据协方差(逆)阵是与观测系统有关的矩阵,一般需要根据其物理含义赋予不同的假设形式。
3.2 Beam偏移
(39)
若假设加权系数为对角阵:
(40)
此时数据残差中各个分量之间不相关且权重不同,权系数依据数据中的噪声水平或数据的可靠性选择合适的权重。对于噪声强的数据给予小的权重,可靠性强的数据,给予大的权重。
鉴于勘探地震中残差向量存在空间相关性(这是地震波场的空间连续性决定的),可以用残差向量相邻道的数据相关性来构造加权函数。直接在时间空间域考察(残差)数据的空间相关性比较困难,一般地,需要在变换域按照特征数据来确定合适的权系数。
根据地震波在地下介质中的传播特征,可以选择用波束合成(Beam Forming)或线性Radon变换的方式构建权函数。该思想利用局部平面波波前到达不同检波器的时差,对观测数据进行时移叠加,使局部平面波相干叠加而其它信号相互抵消,从而去除地震数据中的某些噪声。这就是勘探地震中Beam偏移的思想,可看作将数据向量d投影到正交坐标系中进行特征提取的过程。比如Gaussian Beam偏移[10-12]是在中心射线的傍轴近似展开,采用局部高斯函数计算方式改善焦散、阴影区和临界区振幅计算不准确问题。SUN等[13]采用在局部地震道内进行束叠加后再偏移的方法,提高了成像结果的信噪比和计算效率。
实测地震记录中若存在波动方程无法描述的波现象,将会导致预测误差不符合高斯分布假设。一种有效的做法是将正演算子所能够描述的波现象从观测记录中剥离出来,然后用分离后的波现象进行参数反演[9]。
3.3 自适应数据加权偏移
对比公式(37)与公式(39)可以看出,数据协方差矩阵主要作用在常规偏移成像结果和Hessian矩阵中。LS_RTM是在Bayes反演框架下一种有效的估计模型参数高波数扰动的保真成像技术。理想的LS_RTM需要估计精确的Hessian逆算子并作用到常规的成像结果上。然而由于Hessian矩阵过于庞大,无法直接估计精确的Hessian逆算子。即使可以采用各种迭代法近似求取Hessian逆算子,仍受限于观测数据不完备、正算子不准确以及地震子波未知等多种因素影响,需要付出巨大的计算代价才能收敛,甚至出现不收敛现象。因此本文忽略Hessian矩阵,仅在常规的叠前深度偏移成像中考虑应用数据协方差。此时加权最小二乘法方程的解退化为:
(41)
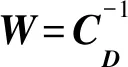
叠前深度偏移成像中误差向量e是观测的地表数据减去背景波场(直达波、透射波等)后的一次波(及散射波)。其中包含相干的波场成分,不是随机噪声,更不是白噪声。此时引入加权函数提高成像质量的物理解释是:We将数据进行了特征表达,各特征成分之间不相关,高斯假设下相互独立,满足了线性最小二乘反演对残差向量的假设,可以得到无偏和方差最小的反演解,这是高质量反演成像的目标。
考虑到数据协方差矩阵逆算子的作用,直接用Cee求逆形成加权系数矩阵不可行。如何合理选择加权算子W是重要的研究内容。利用数据中蕴含的空间相关信息近似地确定加权函数W是基于数据自适应加权的PSDM方法要处理的核心问题。最基本的思想是测量数据中蕴含的相关信息,据此构造加权算子W。
基于上述理论分析,假设加权系数矩阵为对角矩阵,加权系数可由观测波场中的相干成分近似计算。采用倾角扫描和动态时间规整算法确定加权系数,其基本流程为:
1) 在局部的共炮(CS)/共中心点(CMP)道集中提取局部波场;
2) 在选择的局部波场中,采用倾角扫描的方式获取不同道之间的线性相位扰动;
3) 采用动态时间规整算法校正非线性相位扰动;
4) 在拉平后的道集上利用相似系数谱方法估计信息中的相干成分,从而估计出加权系数;
5) 重复步骤1)到步骤4),直到估计出完整的加权系数;
6) 采用公式(41)进行偏移成像。
关于具体的倾角扫描和动态时间规整算法可参考文献[14]。
加权算子的施加方式有:①直接改造叠前数据;②作用于Kirchhoff积分公式中的加权系数上;③改造波场外推成像方法中的相关成像条件。本文仅实现了第一种方法,后两种方法在今后的研究中逐步展开。
3.4 数值实验
3.4.1 模拟数据
采用图2所示单层理论模型模拟数据对本文方法进行测试。图2a为采用有限差分法模拟的单炮记录,共601道,道间隔10m,时间采样点数为5000,时间采样率为0.5ms;图2b为加入随机噪声后的单炮记录,其中信噪比为2;图2c为采用本文方法计算的加权系数,由图2c可以看到,有效信号(相干信号)存在的地方,加权系数接近于1,而在非相干信号区域,加权系数基本为0;图2d为采用数据加权处理后得到的单炮记录,由图2d可以看出,噪声得到了有效消除。图3a和图3b分别给出了数据加权处理前、后的含噪单炮记录局部放大结果。由图3可以看出,原始单炮记录中包含能量较强的随机干扰噪声,经过数据加权处理后,随机干扰噪声得到了消除,较为完整地保留了有效信号。
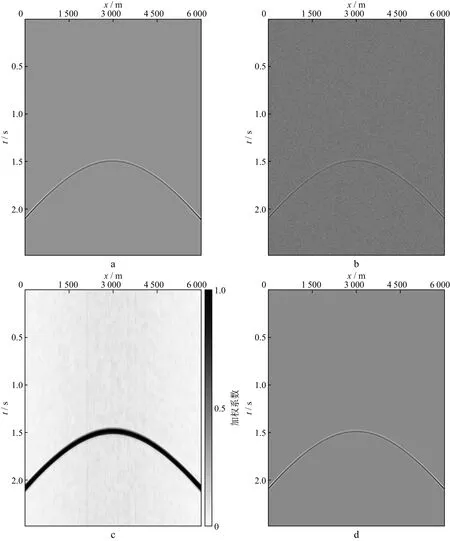
图2 单层理论模型模拟数据测试结果a 原始单炮记录; b 含噪单炮记录; c 采用本文方法计算的加权系数; d 数据加权处理后的单炮记录
3.4.2 实际地震数据
采用某工区二维炮集数据测试本文方法的有效性。图4a为原始单炮记录,可以看到,原始单炮记录中含有较多的相干噪声,深层同相轴被噪声掩盖,无法识别;采用本文方法处理后的单炮记录如图4b所示,可以看出,噪声得到有效去除,无论是浅层还是深层,同相轴连续性更好。对应的偏移成像结果如图5所示。从图5可以清晰地看到,采用本文方法处理后的偏移剖面成像质量得到明显提升,同相轴更加清晰连续,成像剖面上噪声明显减弱。
采用某工区三维CMP道集数据测试本文方法的效果。图6a为原始的CMP道集;图6b为数据加权处理后的CMP道集。由图6可以看出,浅层能量强的同相轴表现出较强的相似性,在处理后的道集中得到增强,而在没有相干信号的地方,原始道集中含有较多的噪声,处理后的道集中噪声得到有效去除。图7为某条测线采用本文方法处理前、后的偏移成像结果。对比图7a和图7b发现,采用本文方法处理后,成像质量得到明显改善。
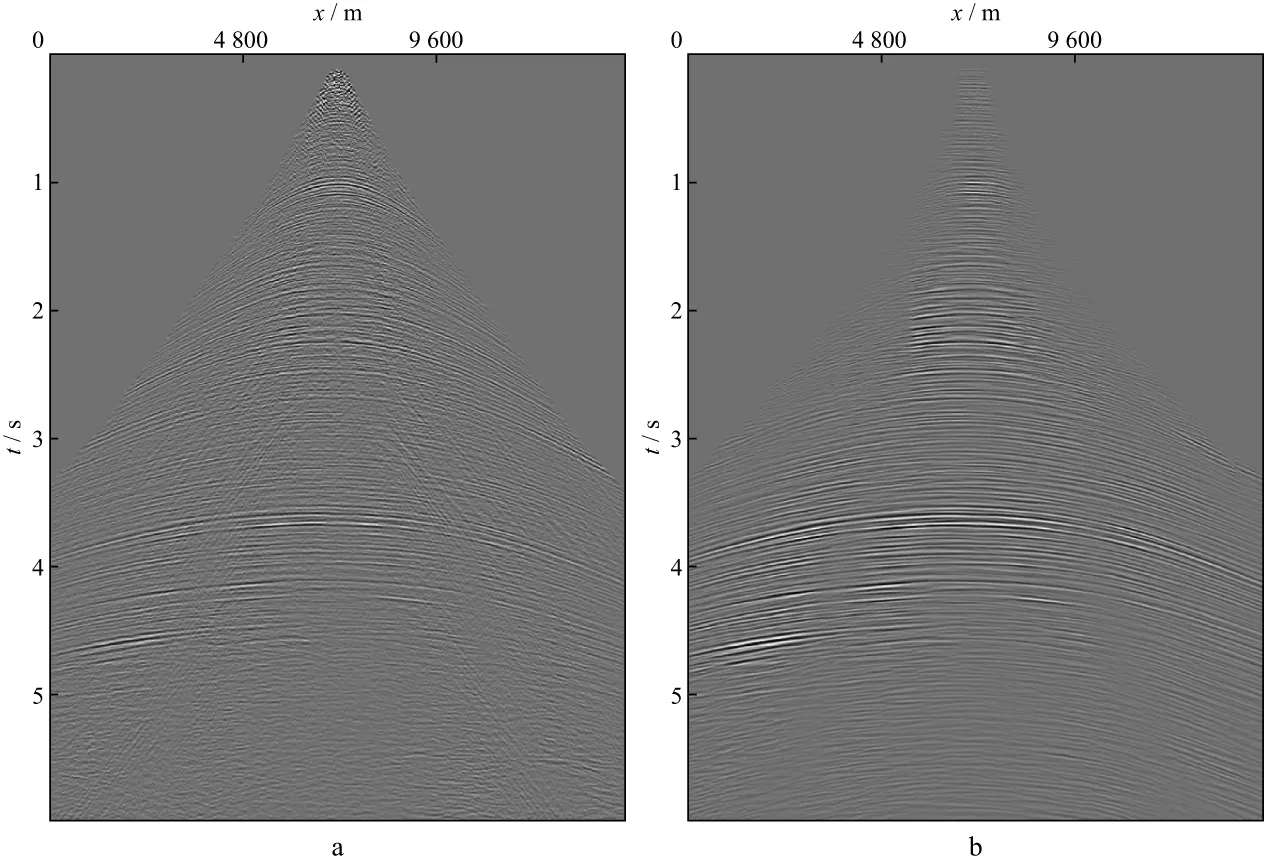
图4 采用本文方法处理前(a)、后(b)的单炮记录
图5 采用本文方法处理前(a)、后(b)的偏移成像剖面
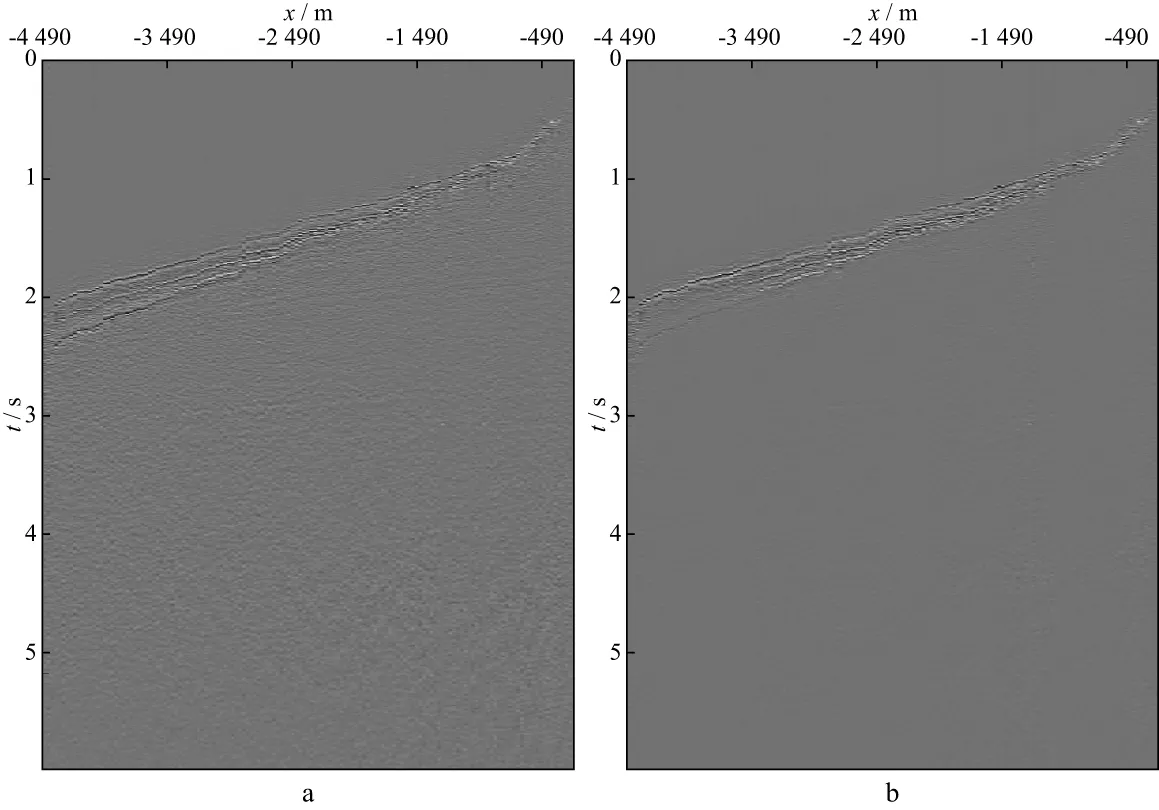
图6 数据加权处理前(a)、后(b)的CMP道集
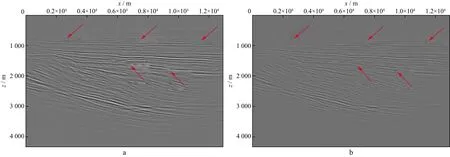
图7 某测线采用本文方法处理前(a)、后(b)的偏移成像结果
4 结论与讨论
“两宽一高”地震勘探的目的是进行更精细的油藏描述。“两宽一高”地震数据采集提供了更完善的地震数据,但是地震波成像技术的发展相对滞后,不能充分挖掘出所采集的巨量数据中蕴含的与储层有关的信息。地震波成像应该逐渐地奠定在Bayes估计理论基础上,从信息综合的角度提高地震波成像的质量。FWI和LS_RTM充分关注了模型参数的正则化,促进了成像质量的提高。但是,对数据正则化的关注有所欠缺,将数据中蕴含的先验信息融合在成像过程中进一步提高成像质量是值得重视的。
为此,本文首先在Bayes框架下讨论了地震波反演成像问题。在地震波正问题(波场和数据间的关系)是弱线性的假设下,反演成像的核心问题是基于后验概率密度最大化原则的参数估计问题。若观测噪声(严格地讲是预测误差)为高斯白噪,模型参数的概率分布为高斯分布情况下,最小二乘估计可以在最小二乘意义下实现。但是,实际数据并不满足上述假设,即预测误差满足有色高斯分布、甚至不满足高斯分布。此时,引入数据协方差(逆)矩阵是提高反演成像质量所必须的。数据和模型的协方差(逆)矩阵连接了各自的原空间与对偶空间,通过协方差矩阵进行数据和模型参数的正交投影,相当于分别对数据和模型参数进行了特征表达。由此可以在数据预条件的基础上提取特征波场,并对模型参数进行特征表达,建立起更为紧密的特征波场与特征参数之间的联系,构建更凸的反问题。这是进行数据自适应加权叠前深度偏移的数学物理理论基础。
本文从最小二乘误差泛函角度分析了数据协方差(逆)算子的作用,指出在地震波反演成像中加权最小二乘引入的必要性。在假设数据协方差矩阵为对角阵的基础上,针对叠前深度偏移成像,提出了一种自适应数据加权的数据预条件处理方法。该方法通过倾角扫描和动态时间规整方法自动计算数据加权系数,将其融合在偏移成像过程中。理论和实际资料测试结果验证了该方法的有效性。
“两宽一高”地震勘探是一项综合性技术,采集技术还有巨大的发挥空间,反演成像技术的差距更大。基于Bayes理论,充分地融合关于数据的先验信息和关于模型参数的先验信息是提高成像质量的必由之路。地震波反演成像中对数据不确定引起的成像结果的不确定性研究还处于初始阶段,本文的研究工作仅仅是较为初步的探索。
致谢:感谢中石油勘探开发研究院及西北分院、中海油研究院和湛江分公司、中国石油化工股份有限公司石油物探技术研究院和胜利油田分公司对波现象与智能反演成像研究组(WPI)研究工作的资助与支持。
