基于字典学习和ADMM的地震数据重建
2019-06-04韩立国
李 慧,韩立国,张 良,贾 帅
(吉林大学地球探测科学与技术学院,吉林长春130026)
重建缺失的地震数据是一个重要的研究课题,传统的重建方法有波动方程法[1]、预测滤波法[2]和数学变换法[3]等。波动方程法通常需要先验参数信息,这限制了它在实际工作中的应用。预测滤波法重建的地震数据一般存在误差较大的问题。数学变换法包括了采用固定基和字典学习两类方法,固定基重建计算速度较快但是缺乏对不同的地震数据进行自适应稀疏表示的能力[4-6],字典学习能够对不同的地震数据进行有效的稀疏表示,但是训练字典较为费时[7-9]。
近十年发展起来的压缩感知理论[10-11]对地震数据的重建工作有着重要的指导意义,压缩感知理论表明:在信号具有稀疏性的情况下,采集少量的样本通过非线性重构算法可以重建完整的信号。目前,压缩感知理论在地震数据处理中已取得了较大进展:HERRMANN等[12]提出了基于压缩感知理论的curvelet变换方法,成功重建了缺失的地震数据;ZHANG等[13]提出了基于压缩感知的傅里叶变换重建地震数据的方法;LIANG等[14]提出了在压缩感知理论下采用shearlet变换重建缺失地震数据的方法。在压缩感知中,稀疏基的选择十分重要,直接影响到地震数据的重建精度[15]。字典学习能够根据不同的地震数据训练出相应的稀疏表示字典,ZHOU等[7]通过字典学习方法实现了混采数据分离,ZHU等[16]将字典学习方法引入地震数据去噪中,取得了良好的效果。
BOYD等[17]提出了交替方向乘子算法(ADMM),该方法能够有效地处理稀疏反演问题。STERNFELS等[18]提出了在压缩感知理论下采用ADMM进行奇异值阈值的地震数据去噪方法。HARIKUMAR等[19]提出了采用ADMM更新过完备字典,并在处理变化幅度大的信号时取得了良好的效果。ZHOU等[20]将采用ADMM更新过完备字典的方法成功地应用于混采数据分离中。
本文在压缩感知理论下提出了一种基于字典学习和ADMM的地震数据重建方法,首先对缺失的地震记录进行字典学习得到稀疏表示字典,然后根据炮记录中地震道的缺失情况设计采样矩阵,接着建立相应的L1范数约束模型,最后采用ADMM进行求解得到重建的地震数据。用正演模拟数据和实际地震资料验证了本文方法的有效性。
1 基本原理
1.1 压缩感知
地震数据的重建问题可以表示为:
(1)
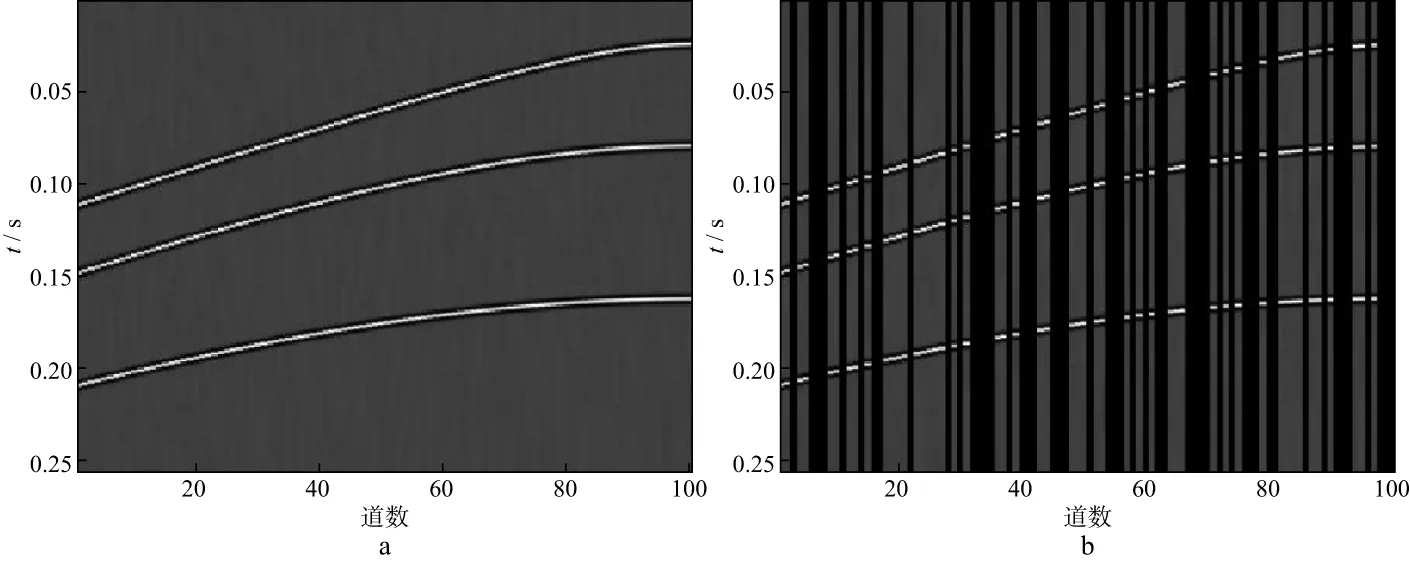
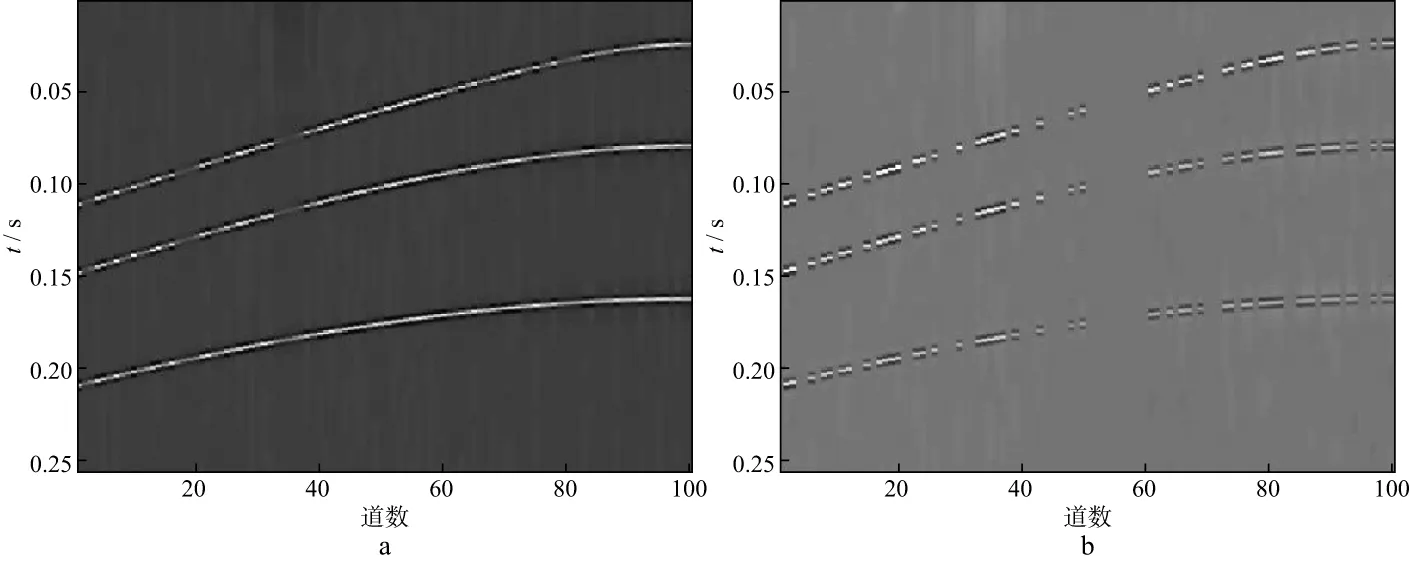
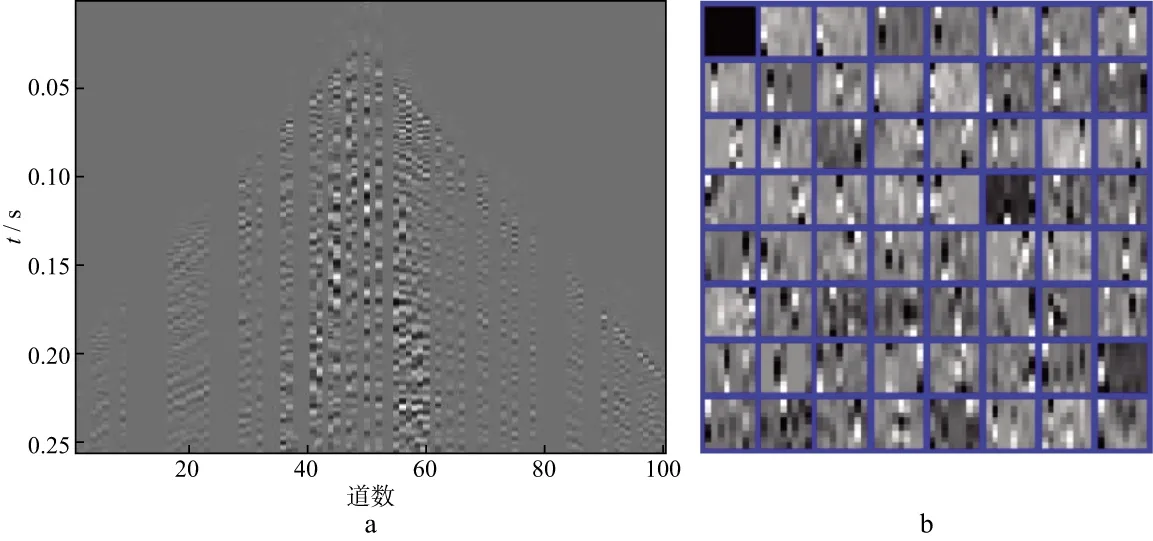
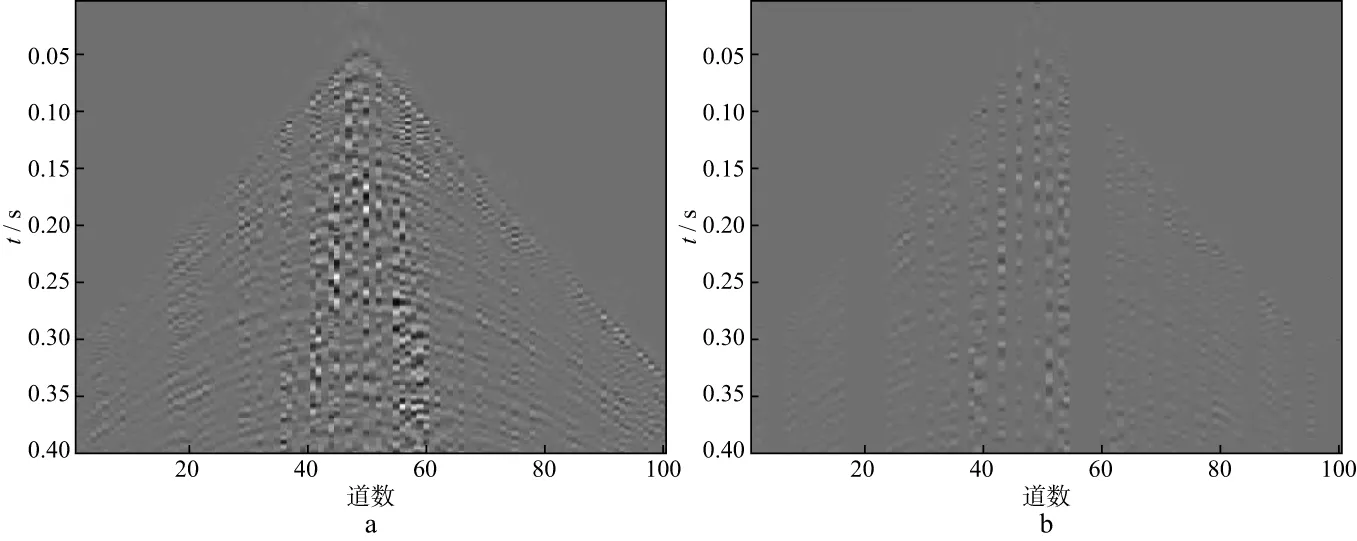
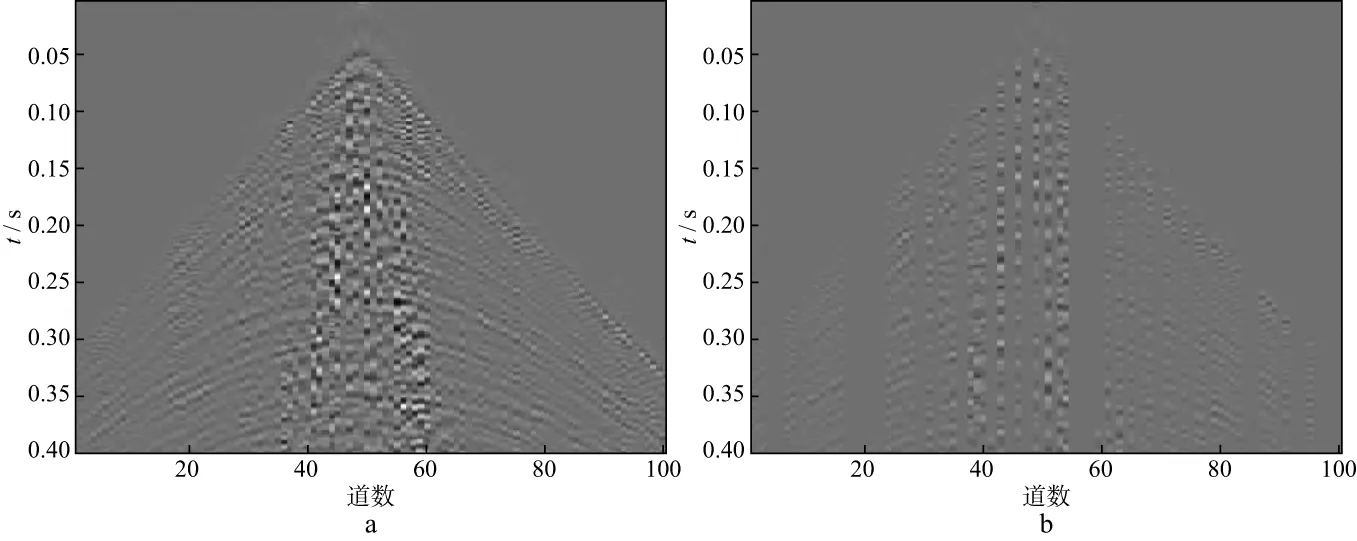
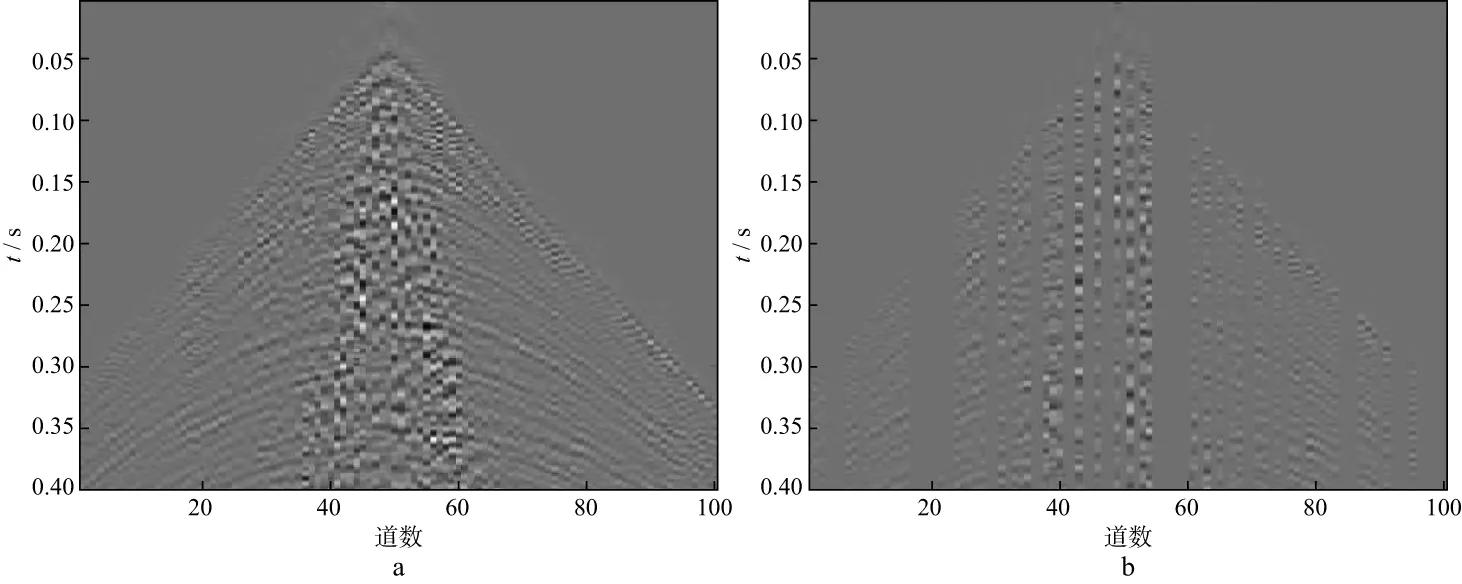
式中:y∈RM表示原始未缺失的M维地震数据;x∈RN表示N(N 采用训练得到的过完备字典D(D∈RM×N且M (2) 公式(2)是一个欠定问题,压缩感知理论指出,当信号的稀疏度为r,并且φD满足有限等距性质(restricted isometry property,RIP)的常数为νr∈(0,1)时: (3) 公式(2)有唯一解,但是通常情况下很难通过公式(3)进行严格验证,而BARANIUK[21]放宽了这一条件,当φ与D不相关时,φD满足公式(3)中条件的概率很大,φD的相关性定义为: (4) 式中:i,j分别表示φD中的行和列。GLEICHMAN等[22]验证了过完备字典和0,1组成的对角矩阵的不相关性,此时,公式(2)可以描述为如下数学问题: (5) (6) 式中:λ为正则化参数。在满足公式(4)的条件下,公式(6)可以改写为: (7) (8) 本文采用了K-奇异值分解(K-singular value decomposition,K-SVD)来获取公式(2)中的过完备字典D,K-SVD是一个字典学习的优化方法[23],它的优化过程可以表示为: (9) 式中:F∈RM×N表示输入的训练样本;A为样本在字典中的稀疏系数;T表示非零元素个数上限;al为A的第l行。首先需要设定一个初始字典,本文的初始字典选取了过完备的DCT字典,如图1所示。 然后,固定初始字典D,输入训练样本F,求出稀疏系数al: (10) 图1 DCT过完备字典 式中:fl为F的列。在求得稀疏系数al的同时,固定al,对字典D进行逐列更新: (11) (12) 与K-SVD采用正交匹配追踪算法求解公式(6)不同,为了提高计算精度,通过对L0约束问题向L1约束问题转化,本文采用ADMM对公式(7)进行求解。 公式(7)是一个凸优化问题,ADMM引入了辅助变量p,h来求解(7)式: (13) 式中:f(h)(h∈R)要求为凸函数并且光滑;g(p)(p∈R)要求为凸函数。将公式(7)写成ADMM形式: (14) 其增广目标函数为: (15) 式中:τ为增广拉格朗日参数并且大于0,它控制着迭代步长。将公式(15)写成增广拉格朗日函数: (16) 式中:Λ为对偶变量。ADMM的第i次迭代形式为: (17) 其中,I表示单位矩阵,soft为软阈值函数,定义: (18) 本文技术流程实现步骤如下。 1) 输入不完整的地震数据作为训练样本,初始字典选为DCT过完备字典,采用的字典学习方法为K-SVD,输出相应的稀疏字典D。 2) 利用D对地震数据进行稀疏表示,采用ADMM求解基于压缩感知理论建立的数学模型(公式(7))。 本文采用信噪比(RSN)作为地震数据重建性能的判断标准: (19) 图2 模拟数据(a)和随机缺失50%后的数据(b) 对图2b中缺失50%后的模拟数据进行K-SVD训练,可以得到相应的稀疏字典,如图3所示。 对图2b中缺失50%的地震数据进行重建。分别采用curvelet稀疏基和OMP、curvelet稀疏基和ADMM、字典学习和OMP、字典学习和ADMM重建模拟数据的结果及对应的重建误差如图4至图7所示。这4种重建方法的RSN分别为17.7138,21.8057,21.9478,24.9869dB,耗时分别为2.56,4.32,132.48,271.09s。从计算效率看,当需要处理的数据量较大时,会面临耗时过长的问题,若数据量较小且需要高精度时,选取本文方法比较有利。其中,ADMM的正则化参数λ取1,控制步长的参数τ取1,ADMM中的初始a,p,Λ设为0。 从图4至图7可以看出,对于正演模拟数据,基于压缩感知理论的固定基和字典学习方法都可以重建地震数据,而字典学习重建的性能比固定基重建的性能更好,重建误差也小。在压缩感知的重建算法中,ADMM重建的性能比OMP重建的性能更优越,无论是在固定基中还是在字典学习中,ADMM重建的误差均小于OMP重建的误差。图8是采用4种方法对不同缺失率的地震数据插值后的信噪比曲线,可以看出,在缺失10%~50%地震数据的情况下,采用本文方法重建的效果比采用其它几种方法的效果好,且有较强的鲁棒性。 图3 模拟数据的K-SVD字典 图4 采用curvelet稀疏基和OMP重建模拟数据的结果(a)及重建误差(b) 图5 采用curvelet稀疏基和ADMM重建模拟数据的结果(a)及重建误差(b) 图6 采用字典学习和OMP重建模拟数据的结果(a)及重建误差(b) 图7 采用字典学习和ADMM重建模拟数据的结果(a)及重建误差(b) 图8 采用4种方法对不同缺失率的地震数据插值后的信噪比曲线 图9a为缺失50%的实际数据。选取100道数据,采样点数为400个,时间采样率为0.001s,道间距为10m,将缺失的实际数据作为训练样本,得到的稀疏字典如图9b所示。 分别采用curvelet稀疏基和OMP、curvelet稀疏基和ADMM、字典学习和OMP、字典学习和ADMM 4种方法对图9a中缺失50%的实际数据进行重建,其结果及对应的插值部分如图10至图13所示。这4种方法的耗时分别为4.15,7.52,182.07,411.30s。其中ADMM中的正则化参数λ取1,控制步长的参数τ取1,ADMM中的初始a,p,Λ设为0。 图9 实际数据(a)和相应的字典(b) 图10 采用curvelet稀疏基和OMP重建实际数据的结果(a)及对应的插值部分(b) 图11 采用curvelet稀疏基和ADMM重建实际数据的结果(a)及对应的插值部分(b) 图12 采用字典学习和OMP重建实际数据的结果(a)及对应的插值部分(b) 图13 采用字典学习和ADMM重建实际数据的结果(a)及对应的插值部分(b) 从图10至图13可以看出,压缩感知理论下的固定基和字典学习方法都可以很好地重建实际地震数据,其中,采用字典学习比采用固定基的效果更好,可以对一些细节部分进行较好的重建,而压缩感知理论下重建算法中的ADMM的重建性能比OMP的重建性能更好,无论是能量较强的同相轴还是能量较弱的细节部分都可以得到有效重建。 本文提出了一种压缩感知下基于K-SVD字典学习和ADMM的地震数据重建方法,并建立了技术实现流程。正演模拟数据和实际地震资料测试结果表明,本文方法与固定基地震数据插值方法以及字典学习中常用的OMP插值方法相比,重建精度有很大提高。并且,在地震数据缺失10%~50%时,采用本文方法可以较好地对地震数据进行重建,重建精度较高。但本文方法有耗时过长的缺陷,当面临较大数据量的插值任务时,这一缺陷会更大,如何减少耗时、提高算法的运行效率是下一步的研究方向。
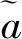
1.2 字典学习





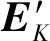
1.3 交替方向乘子算法
2 技术流程

3 模拟数据实验
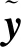





4 实际数据实验

5 结论
