融入汉字字形特征的中英神经机器翻译模型
2019-06-03蔡子龙熊德意
蔡子龙,熊德意
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
作为世界影响力最大的英语和世界人口使用数量最多的汉语,它们之间相互翻译的需求是巨大的。构建更加出色的机器翻译系统,不仅能创造庞大的经济价值,更能产生打破语言障碍、促进全球文化交流的社会价值。由早期基于规则的机器翻译[1],到之后基于统计模型的机器翻译[2],再到现在基于神经网络的机器翻译[3],翻译技术不断取得新的突破,模型性能也不停地提升。
基于神经网络的机器翻译简称神经机器翻译,是Sutskever等[3]在2014年提出的一种基于编码器—解码器结构的翻译模型。与统计机器翻译相比,该方法生成的译文具有流利度高的特点。2015年,Bahdanau等[4]在此基础上引入了注意力机制,使得神经机器翻译生成的译文全面超过统计机器翻译,神经机器翻译因此成为机器翻译中最热门的研究方法。到目前为止,已经有很多学者对神经机器翻译模型提出了优化方法,例如Tu等[5]在2016年提出的对神经机器翻译覆盖度进行建模的方法,Wang等[6]在2017年提出基于统计机器翻译推荐的神经机器翻译模型。然而,很少有针对具体语言特征尤其是汉语这种形态丰富的语言设计相应的融合方法。
汉字是一种形声字,其一半表音、一半表意的特殊结构,使得汉字本身含有丰富的语义、语音和句法信息。例如,“江” “河”“湖”“海”四个字,都有共同的偏旁部首“ 氵”,表示它们具有和“水”相关的含义。“打”“抓”“挠”“推”这四个字,有共同的偏旁部首“扌”,表示它们是动词。“乙yǐ”“亿y씓忆y씓艺yì”这四个字都含有相同的子字“乙”,表示它们的发音都基于“yi”。对于学习汉语的人来说,丰富的字形信息不但可以帮助他们更快地记住汉语单词,而且能够帮助他们更好地理解汉语知识。受此启发,本文在Marta R.等[7]工作的基础上,提出新的将汉字字形特征融入中英神经机器翻译的方法,与基准系统相比,该方法在NIST评测集上获得平均1.1个BLEU[8]点的显著提升,有效地证明了汉字字形特征可以对神经机器翻译模型起到促进作用。
本文其他部分组织如下: 第1节介绍神经机器翻译的相关知识;第2节介绍神经机器翻译和语言特征结合的相关工作;第3节详细说明如何将汉字字形特征融入中英神经机器翻译;第4节介绍实验;第5节对本文提出的融合方法进行详细分析;最后一节总结工作,展望未来。
1 神经机器翻译
本文研究的神经机器翻译指的是一种端到端的基于双向循环神经网络的机器翻译。该翻译模型将源端句子X=(x1,…,xTx)作为输入,将目标端句子Y=(y1,…,yTy)作为输出,其中,xt和yt′分别代表源句子符号和目标句子符号。端到端的神经网络由编码器和解码器两个部分构成。

图1 基于双向循环神经网络的编码器

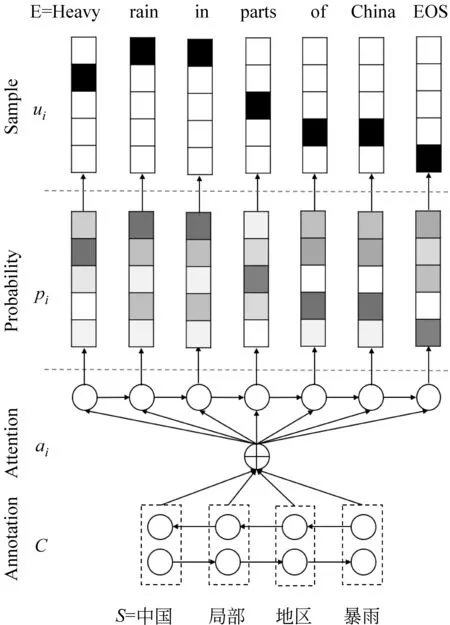
图2 基于双向循环神经网络的解码器
如图2所示,解码器基于源端句子的上下文向量C计算所有可能翻译结果的条件概率分布。给定某一具体的翻译,其条件概率的计算如式(3)所示。
(3)
式(3)中,给定源端句子和目标端已生成的单词,计算当前时刻单词的概率,如式(4)所示。
(4)
其中,ey(yt′-1)表示的是前一时刻单词的词向量,ct′可由式(5)计算得到,表示的是依据解码端前一时刻单词向量以及相对应的隐藏层向量,对源端上下文向量C计算权重后进行累加求和,权重的分配使得解码端每一时刻生成的单词能够捕捉到更多关于源端句子中对应单词的信息。源端句子中第t个位置的单词所对应的权重αt,t′可由式(6)计算得到,其中fscore是带有一个隐层的前馈网络,Z是正则化常量,其计算如式(7)所示。式(4)中的st′表示解码端的隐藏层向量,其更新如式(8)所示。
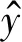
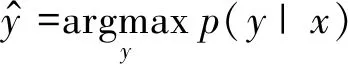
(9)
2 相关工作
虽然端到端的神经机器翻译模型具有很强的学习能力,但是引入外部的语言知识依旧可以帮助模型学到更多有用的知识。
Sennrich和Haddow[10]在2016年提出将神经机器翻译模型中源端的单词向量分成6个部分,分别是单词本身、单词的基本形式、子词标记[11]、形状特征、词性标注[12]及依存句法标签[13]。每种语言特征都有各自对应的索引表,给定一个单词,根据其不同的属性查找与之对应的特征向量,将这些特征向量拼接在一起,形成参与模型训练的词向量。本文和Sennrich等的工作主要存在两个不同之处,第一,本文研究的对象是汉语特征,而他们研究的对象是英语特征。第二,本文不仅使用了向量拼接法作为对比实验,而且提出了新的用汉字字形特征辅助词向量生成的方法。
Dai和Cai[14]在2017年提出利用汉字的字形特征对单词向量进行初始化。Dai等的思想和本文是一致的,均认为汉字丰富的字形信息可以帮助理解汉语知识。不同点在于: ①本文简单地将汉字字形矩阵以行的方式拆开,重组成一维的词向量,而Dai等是用卷积神经网络从汉字字形中提取更加细粒度的特征作为单词的词向量; ②本文研究的对象是神经机器翻译,而Dai等则是将字形特征用于语言模型和分词任务。
Kuang等[15]在2018年提出了将汉字偏旁部首融入神经机器翻译模型的方法。他们将中文端的词向量分成三个部分: 第一部分是单词本身对应的向量;第二部分是组成单词的字符向量之和;第三部分是构成字符的偏旁部首向量之和。这种方法使得词向量不仅具有传统的“单词”和“字符”级特征,而且具有更加细粒度的“汉字偏旁部首”级特征。本文和Kuang等提出的方法相同点在于都是将汉字的形体特征融入神经机器翻译,不同点在于Kuang等提出的“汉字偏旁部首”级特征是相对离散化的,而本文提出的“汉字字形特征”保留了完整的汉字形体。
3 字形特征融合方法
本文研究的对象是中文到英文的神经机器翻译。其中,中文端以汉字字符为单位对句子进行切割;英文端以单词为单位对句子进行切割。中文端以字符为单位对句子进行切割有以下三点好处: ①中文不存在空格符,以字符为单位可以省去分词处理; ②中文常用字3 755个,不常用字3 008个,合计6 763个,以字符为单位可以解决汉语端未登录词问题; ③方便设计字形特征融合方法。
在本文之前,Marta R.等已经展开了汉字字形特征和神经机器翻译模型相结合的工作。虽然她们在中文到西班牙文的翻译任务上取得了不错的成绩,但是依然存在一些问题。为此,本文提出新的字形特征融合方法。3.1节主要介绍如何获得汉字的字形特征;3.2节详细描述字形特征融合的三种方法;3.3节对比分析三种字形特征融合方法的优缺点。
3.1 汉字字形特征
在神经机器翻译中,单词以词向量[16]的形式进行表征。汉字是方块字,其点阵图像如图3所示。为了从汉字的点阵图像中获取到与词向量形式一致的信息,本文采用Marta R.等的方法,简单地将汉字的点阵图像以行的方式拆开,拼接成一维向量,并把它作为汉字的字形特征。

图3 16×16的“汉”字的点阵图像
3.2 字形特征融合
为了便于阐述,本文将Marta R等提出的字形特征融合方法称为完全替代法。如图4所示,该方法将神经机器翻译模型当作“黑盒子”,仅用汉字的字形特征(图中深色部分)对源端字符向量进行初始化,模型的其余部分保持不变。

图4 完全替代法
汉语中存在形态极为相似,但意思完全不同的汉字,例如,“人”“入”。使用完全替代法,将会使得同形不同义的汉字字符得到几乎一样的向量表征。为了对这些汉字加以区别,本文提出了部分替代法。如图5所示,该方法仅把汉字的字形特征作为字符向量的一部分,同时,使用正则分布对字符向量的其他部分进行随机初始化。
图5 部分替代法
传统神经机器翻译模型中的字符向量完全是基于目标端句子的翻译损失进行更新的。这种方式得到的字符向量是一种语言模型向量。如图6所示,本文提出辅助学习法,将汉字的字符向量Vc(图中浅色向量)和字形特征向量Vs(图中深色部分)相关联,使得汉字的字符向量既有传统的基于神经网络的语言模型特征,又包含汉字的字形特征。
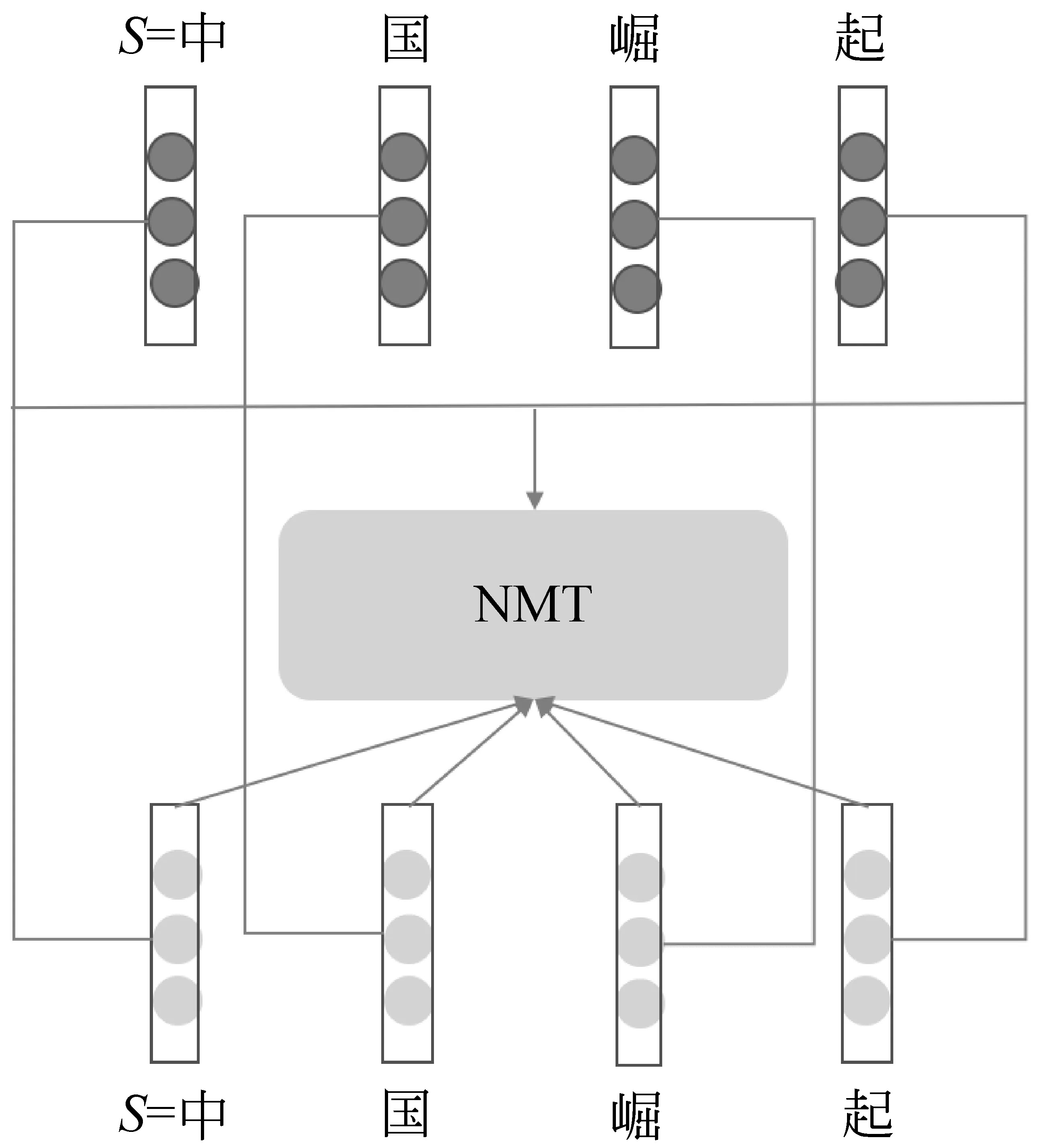
图6 辅助学习法
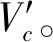
(12)
3.3 融合方法比较
Marta R等提出的完全替代法是一种词向量初始化方法。该方法利用汉字字形特征对字符向量进行初始化,改变了字符向量的起始状态,从而使得神经机器翻译模型向着更好的方向去优化。和Marta R等的方法相比,本文提出的部分替代法也是一种词向量初始化方法,不同点在于,完全替代法没有考虑到汉语中存在的同形不同义的问题,而部分替代法将随机初始化和字形特征初始化结合使用,保证了字形过于相同的汉字其字符向量依然存在不同的地方。
无论是Marta R等提出的完全替代法,还是本文提出的部分替代法,都是直接使用汉字字形特征对字符向量进行初始化。这种简单的初始化方法存在两个问题: ①汉字的字形特征向量是一种基于图形的空间向量,而神经机器翻译模型中的字符向量是一种词嵌入向量,两者不在同一维度空间;②从整个训练过程来讲,初始化字符向量是一种静态方法,该方法只是改变神经机器翻译模型中字符向量的起始状态,并不能保证汉字字形信息能够始终作用到字符向量的训练中去。为了解决这两个问题,本文提出辅助学习法。首先,通过使用神经网络,将字符向量映射到汉字字形特征空间,使得它们可以在同一空间维度下进行比较;其次,将字符向量和字形特征向量之间的距离作为模型的一种损失,使得汉字字形特征参与模型的整个训练。
4 实验
本节分为两个部分,4.1节介绍实验设置,4.2节给出实验结果。
4.1 实验设置
使用从LDC语料库中抽取出来的125万对平行双语句子作为实验数据。其中,中文端约0.46亿个汉字,英文端约0.35亿个单词。将NIST06作为开发集,NIST02,03,04,05,08作为测试集。分别从16×16,25×25的汉字点阵图像中获得256维、625维的字形特征向量。本文使用不区分大小写的四元BLEU值作为实验的评价标准,BLEU值越高,翻译效果越好。
为了加快神经网络的训练,将中文端句子的长度设置为120(有效句子占比99.78%),英文端句子的长度设置为80(有效句子占比99.20%)。将中文端词典大小设置为6 186,英文端词典大小设置为30 000,其中中文端字符覆盖率为100%,英文端单词覆盖率为99.30%,对英文端不在词典内的单词用UNK替代。
将字符向量的维度设置为620,隐藏层向量维度设置为1 000。对于Marta R提出的完全替代法,本文截取625维字形特征的前620维作为字符向量的初始化向量。对于部分替代法,对字符向量的前364维采用随机初始化的方式赋值,剩余部分用256维的字形特征向量进行替代。对于辅助学习法来说,采用256维的字形特征向量辅助学习字符向量。
本文使用名为RNNSearch的神经机器翻译系统作为实验的基准系统。使用GRU[18]学习隐藏层向量,使用Adam[19]对参数进行优化。本文还对输出层采用dropout[20]方法以加强神经网络的泛化能力。本文采用批量式方法对参数进行更新,大小设置为120。本文将束搜索的大小设置为10。
4.2 实验结果
如表1所示,本文从参数大小、训练速度及翻译性能这三个方面,对三种字形特征融合方法进行了比较。除此之外,也对比了基于汉语字符的机器翻译和基于汉语单词的机器翻译之间的差异。
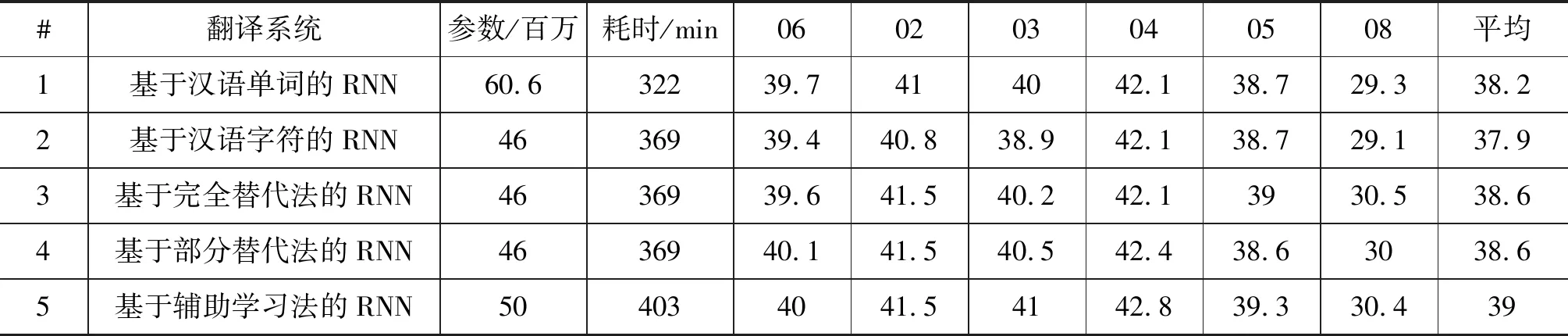
表1 翻译系统比较
参数神经机器翻译模型中,词向量约占参数总量的一半。基于汉语单词的RNN,其源端词表大小设置为3万,故而参数总量最多。基于汉语字符的RNN,其源端词表大小设置为6 186,故而参数总量最小。基于辅助学习法的RNN,在训练阶段,由于字符特征向量参与模型训练,故而参数总量有所增加,但在测试阶段,参数总量保持不变。
速度本文使用单颗GPU对翻译系统进行训练。基于汉语单词的RNN,由于分词之后,句子的单元数变少了,编码速度加快,因而迭代一轮语料所需的时间最短。基于辅助学习法的RNN迭代一轮语料耗时403min,速度上比基于汉语字符的RNN慢了将近9%,主要原因是需要额外计算字符向量和字形特征向量之间的距离。
性能基于汉语单词的RNN比基于字符的RNN在测试集上平均高出0.3个点。原因可能是和单纯的字符序列相比,文本分词带来了更多的语义知识。基于部分替代法的RNN并没有取得比基于完全替代法的RNN更好的结果,两种方法均比基准系统高0.7个点,可能的原因在于初始化方法是一种静态法,只是改变了模型参数的起始状态,无法参与训练的整个过程,本文提出的基于辅助学习法的RNN取得了最好的结果,平均比基准系统高出1.1个点,比基于汉语单词的RNN高出了0.8个点,比其他两种字形特征融合方法高出0.4个点,证明了该方法能够有效地改进初始化方法中存在的问题。
5 分析
本节从两个方面对辅助学习法的有效性做进一步分析。
5.1 不同句子长度下的翻译性能比较
本节主要探究辅助学习法在不同句子长度下的性能表现。具体做法如下: 首先,将测试集02、03、04、05、08的句子整合在一起;其次,以10个字符单元长度为单位,将句子分到6个不同的区间;最后,用multi-BLEU评测工具对不同区间的句子进行打分。评测结果如图7所示,辅助学习法只有在[10,20]、[30,40]这两个区间内得分略低于完全替代法,其他区间内得分均比完全替代法高,特别是当句子的字符数在50以内时,辅助学习法的翻译性能和基准系统相比有着显著提升,这表明本文提出的辅助学习法确实能够对神经机器翻译模型的翻译结果起到促进作用。
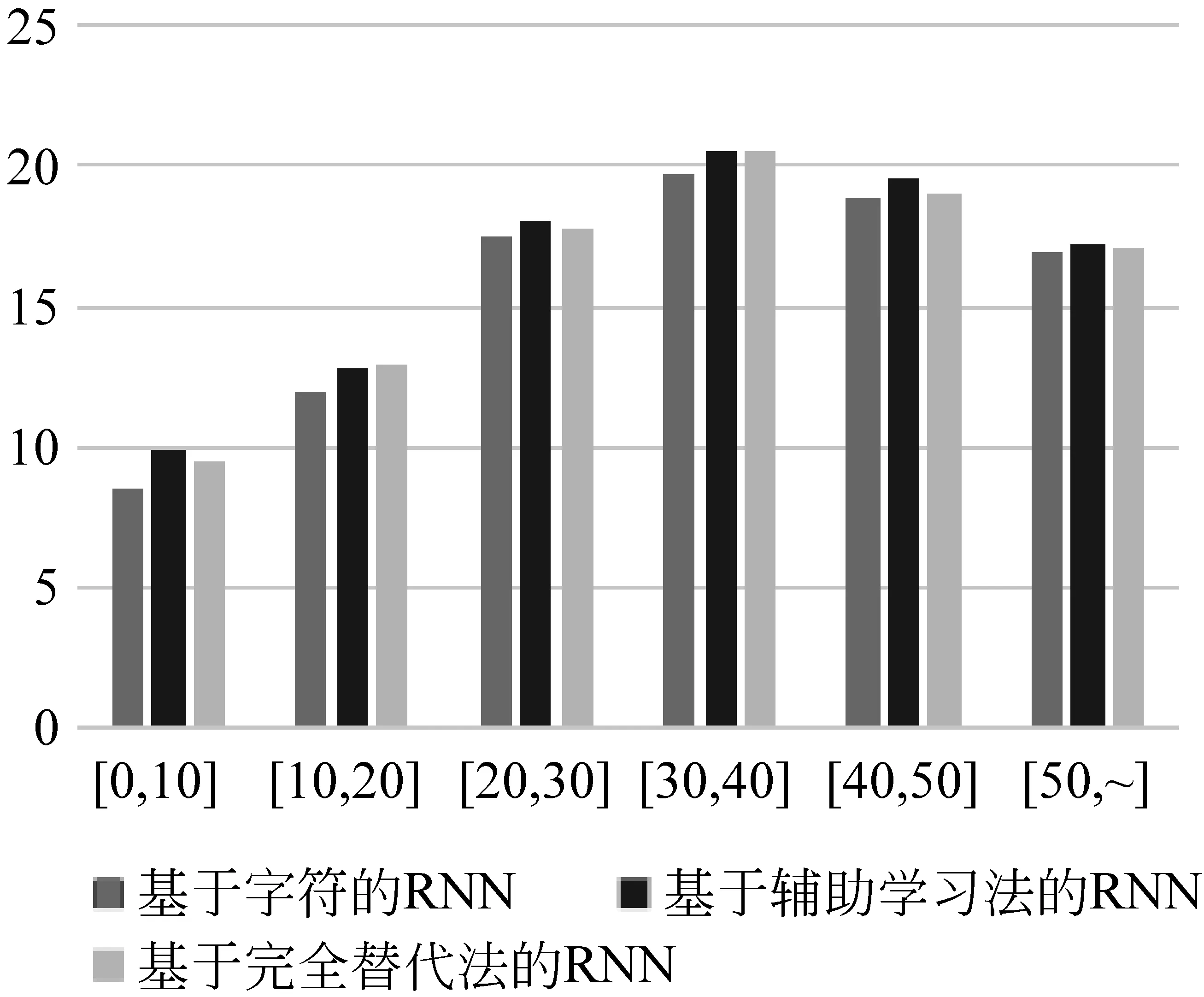
图7 不同句子长度下的翻译性能比较
5.2 字形特征融入程度的比较
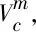

表2 汉字分类结果
6 总结与展望
本文在Marta R.等工作的基础上,提出了新的将汉字字形特征融入中英神经机器翻译的方法。该方法将字符向量和字形特征之间的距离作为模型的一种损失,迫使模型学习到汉字丰富的字形信息,以此提升翻译性能。
本文提出的字形特征融合方法是基于字级别设计的,然而单个汉字并不具备完整的语义。因此,未来工作中,我们会考虑将汉字字形特征融入基于单词的神经机器翻译模型。
