基于视觉特征的网页信息抽取方法研究
2019-06-03王宪发俞晓明程学旗
王宪发,郭 岩,刘 悦,俞晓明,程学旗
(1. 中国科学院大学 计算机与控制学院,北京 100049;2. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190)
0 引言
互联网在我国已成为人们生活中不可或缺的一部分。互联网上存在着海量的数据,且每天都在爆炸式增长中。这些信息既丰富又实时,是信息检索、数据挖掘等很多网络应用的基础数据。对这些数据进行深入的分析,可获得很多更有价值的深层信息。然而,由于数据非常庞大,网页本身又不是结构化的数据格式且包含噪音信息,故我们需对网页进行信息抽取,提取网页中的关键信息并将其转化为结构化数据再应用于后续的数据分析等工作。
目前,学者提出的大部分抽取方法都是基于HTML源码或者基于将源码解析后生成的DOM树,使用网页的文本特征或结构特征进行抽取。事实上,网页还有一类非常重要的特征可以用于信息抽取,即为视觉特征。视觉特征同时表明了网页内容的重要性,如部分新闻网站会将重要的头条事件放在醒目的位置并用大号字体加粗或高亮,部分论坛网站会将热门的帖子置顶或高亮。因此,利用这些视觉特征进行网页信息抽取能够更好地模拟人对网页内容的识别,进而提高抽取效果,这是仅基于HTML源码或DOM树无法达到的效果。近些年来,已有学者提出了一些基于视觉特征的抽取算法。如VIPS[1]、VIDE[2]等方法,相比于传统的基于HTML源码和DOM树的抽取方法来说,这些方法不依赖于具体的网页编程语言,且更加契合HTML这种帮助表现和展示的语言。但这些方法存在以下两个问题:
(1) 通用性较差: 大多数方法是基于视觉特征,使用启发式规则对网页进行分块,但由于网页的形式是十分多样化的,这些方法并不是十分通用。
(2) 实用性较差: 因经过浏览器渲染解析的时间成本较高,获取网页快照等视觉特征需要消耗的时间过长,故目前基于视觉特征的信息抽取方法的抽取效率过低,导致无法很好地应用在工业界。
针对以上两个问题,我们做了深入研究。首先,通过观察,我们发现同一类型的不同网站的数据区域对应的网页元素具有相似的视觉特征。如图1是来自两个论坛网站页面中的帖子记录。从图中可发现它们在视觉特征上十分相似。如作者信息、发帖时间、帖子正文等信息在页面中的相对位置均十分相似。因此,本文利用不同网站的视觉特征的相似性,提出一种基于视觉特征的使用有监督机器学习的网页信息抽取框架WEMLVF(Web Extraction by Machine Learning and Visual Features),该框架具有良好的通用性。本文通过论坛网站和新闻评论网站的信息抽取实验,验证了框架WEMLVF的有效性。然后,针对实用性差的问题,本文使用框架WEMLVF,分别提出基于XPath和基于经典包装器归纳算法SoftMealy的自动生成信息抽取模板的方法。这两种方法使用视觉特征自动生成信息抽取模板,但模板的表达并不包含视觉特征,使得在使用模板进行信息抽取的过程中无需提取网页的视觉特征,从而显著提升了信息抽取的效率,实验结果验证了这一结论。

图1 不同论坛页面的帖子记录
1 相关工作
网页信息抽取是信息抽取中一个非常重要的研究领域。对网页信息抽取的技术有很多种分类方法[3-5]。我们按照是否使用网页的视觉特征对抽取技术进行分类,主要分为不使用网页视觉特征的方法和基于网页视觉特征的方法。
对于不使用网页视觉特征的方法,大多都是基于HTML源码或者基于将源码解析生成的DOM树,然后利用DOM树的结构特征或是使用自然语言处理的方法对网页进行信息抽取。根据是否使用模板,我们可以将抽取的方法分为模板相关和模板无关两类抽取方法。模板相关的方法主要有基于包装器归纳的SoftMealy[6]、STALKER[7]等,以及自动生成模板的RoadRunner[8]等方法,基于模板的网页信息抽取方法在模板的生成和维护方面都是费时费力的,人工难以满足实际需求。模板无关的方法如MDR[9],在DOM树中寻找相似的重复串来定位数据区域,如郗家贞[10]等提出的一种基于时间串的论坛信息抽取方法Tristor,该方法主要是基于时间串进行聚类来定位记录区域,以及使用机器学习的方法如CRF[11]和神经网络[12]、决策树[13]等对网页进行抽取,但这些算法对数据的假设较高,抽取精度不高,效率较低。
基于视觉特征的网页抽取方法包括基于视觉分块的VIPS、VIDE等,但由于网页形式的多样化,且提取视觉特征的效率较低,导致这些基于分块的方法并不是十分通用。近几年,相继有学者提出基于网页在视觉上的相似度,使用卷积神经网络的方法,通过对网页快照进行训练来对网页进行抽取,如Zehuan Cai[14]等提出了使用卷积神经网络定位数据块的位置;Tomas Gogar[15]等提出了Text Map;Jin Liu[16]等提出通过R-CNN的方法在网页快照中定位数据节点。这些方法在对模型未见过但是视觉上相似的网站中的抽取准确率较高,但这些方法在训练时只考虑了网页快照的特征,而没有使用网页元素,即DOM树节点的特征,而且卷积神经网络的训练速度较慢,故在实际工程中并不适用。
2 基于视觉特征的网页信息抽取方法
网页的特征包含很多,不同网页的特点也不同。启发式规则无法完全通用,且针对不同网站提出各种不同的规则是十分费力的事情。有监督机器学习[17]是一种机器学习的方法,与无监督机器学习不同。它基于提供的包含标注样本的输入输出来学习一个映射函数,而无监督机器学习的样本不包含标注信息。在有监督的机器学习中,每个样本都包含一个期望的输出(标记),模型通过对样本进行学习得到一个映射函数来对新的样本进行预测。通过有监督的机器学习的方法能够帮助我们从这些特征中自动学习网页的潜在规律来帮助完成抽取。对于不同类型的网页,我们只需要使用不同的训练集即可实现不同类型网页的抽取。
因此,本文提出一种基于网页视觉特征的使用有监督机器学习的网页信息抽取框架WEMLVF。该框架主要结合网页的视觉特征和结构特征,包括但不限于网页元素对应矩形区域的位置、大小、长、宽等视觉特征,以及网页节点相似度等结构特征,对元素节点进行标注是否是数据节点,生成训练数据,使用机器学习模型进行训练得到网页元素分类器。在定位网页数据节点后,再使用基于DOM树的抽取算法抽取出结构化数据。
图2为WEMLVF的框架图。该方法将以网页源码解析后生成的DOM树上的节点作为样本,通过对样本标记0/1表示是否是要抽取的数据区域,将网页抽取问题转化为一个传统的二分类问题(即判断每个DOM树节点是否是数据区域),利用机器学习的方法训练生成网页节点的分类器来定位要抽取的网页数据区域。具体方法的流程如下:
(1) 解析网页源码生成Dom树,并进行预处理;
(2) 使用启发式规则召回候选节点;
(3) 获取候选节点的视觉特征与结构特征,包括但不限于网页快照,网页元素的位置、大小、长、宽等视觉特征,以及网页节点相似度等结构特征;
(4) 对数据区域所在节点进行标注;
(5) 使用机器学习模型进行训练得到网页节点分类器;
(6) 使用分类器定位网页数据节点后,再使用基于Dom树的抽取算法或基于视觉特征的启发式规则抽取出结构化数据。
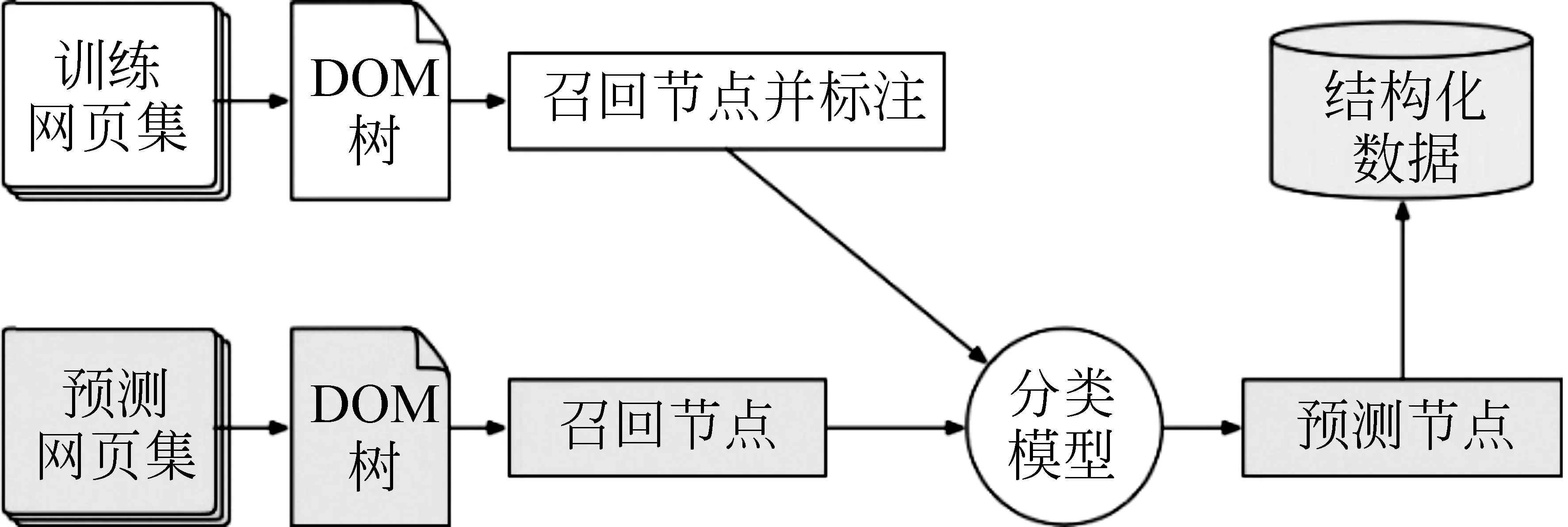
图2 框架WEMLVF流程图
该算法提出的是一套抽取方法框架,该框架具有良好的通用性,针对不同的应用场景,仅需调整框架中的一些处理方法即可满足需求。可调整的部分如下:
(1) 解析网页源码生成Dom树,针对不同类型的网站,我们可以使用不同的预处理方法,包括删除无用标签、删除不可见节点等。
(2) 使用启发式规则召回候选节点。我们可以针对不同的应用场景,使用不同的启发式规则对节点进行召回,如本文后续对论坛页面和新闻评论页面使用基于时间串的方法召回候选节点。
(3) 获取候选节点的视觉特征与结构特征。我们可以针对具体的应用场景,提取不同的能够区分和帮助我们找到记录节点的特征,包括视觉特征及网页HTML的结构特征。
(4) 对数据区域所在节点进行标注。我们需要针对具体的问题来对需要寻找的节点进行标注。在本文后续的内容中,我们希望得到一个二分类器用来判断某个节点是否是我们要抽取的记录节点。因此,我们在标注时是对节点标注为0/1,表示是否是要抽取的数据区域。
(5) 使用机器学习模型进行训练得到网页节点分类器。对于不同的特征类型,我们可以使用不同的机器学习模型。对于连续型的数值特征(如节点对应的矩形区域的高度、宽度、字体大小等),我们可以使用逻辑回归、决策树、BP神经网络等模型,如本文之后使用了BP神经网络来训练网页节点的分类器;对于网页快照类的图像特征,我们可以使用卷积神经网络等模型。
(6) 使用分类器定位网页数据节点后,再使用基于DOM树的抽取算法抽取出结构化数据。在本章后续部分,我们使用了基于DOM树的方法结合基于视觉特征的启发式规则来抽取了论坛、评论页面的发布时间、作者和正文。
2.1 论坛页面、新闻评论页面的信息抽取
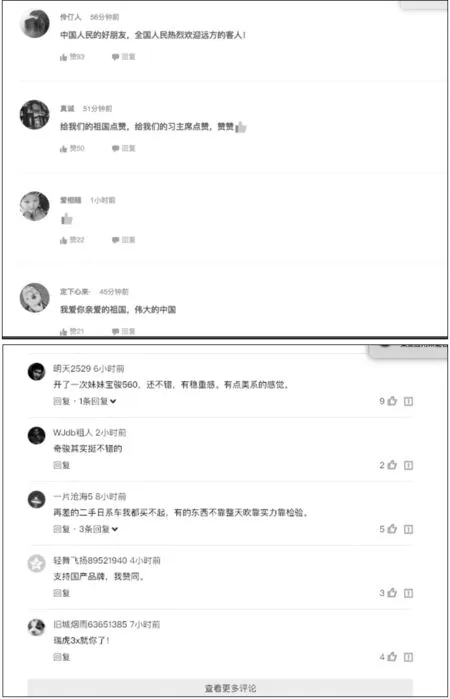
图3 新闻评论页面示例
通过观察论坛帖子页面和新闻评论页面,我们发现这些记录在视觉特征上十分相似。如图3所示,上边是腾讯新闻的评论页面,下边是今日头条的评论页面。我们总结了一些不同论坛网站中的帖子记录和新闻网站的评论记录在视觉特征和网页结构特征上的一些共性,总结如下:
(1) 记录居中,不同的论坛网站的帖子和新闻网站的评论信息在页面中均处于页面的中间位置。
(2) 记录的宽度相似。
(3) 均包含时间串,且时间一般具体到分钟。如2018/3/4 00:00,时间串一般位于帖子的顶部或底部。这是非常重要的一个特点,我们将利用这个特性来召回可能是记录的那些节点。
(4) 在网页HTML源码中一般是兄弟关系,Tristor算法便是基于这个特性来对记录节点来定位的。
(5) 记录一般完整的包含在一个标签节点下,记录的标签一般为
- 、
因此,利用上述共性特征,我们提出基于框架WEMLVF的论坛网页和新闻评论页面的信息抽取算法,算法的主要步骤遵循框架WEMLVF的主要流程。

在召回候选节点部分,我们发现多数论坛网站和新闻评论网页的记录大都包含时间串,且位于同一个父亲节点下。部分论坛网站的主帖与跟帖不在一个父亲节点下,如图4。最后,我们使用算法1对节点进行召回。算法主要是使用由文本节点的字体和字体颜色拼成的字符串来作为key,算法实际是按key对兄弟节点进行聚类,寻找出现类别大于1次的所有兄弟节点来召回,而对于只出现一次的我们单独进行处理。
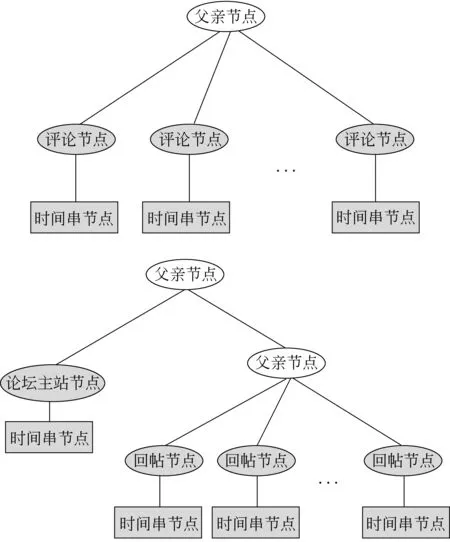
图4 记录节点DOM树结构
在特征与模型方面,由于论坛网站和新闻评论页面在视觉特征方面存在一些差异,特征无法完全通用。而且,对应的噪音信息也不同。因此,我们除了总结上述共性特征,还分别对论坛网站和新闻评论页面提取个性化特征。
基于论坛网站的特性,我们提取以下特征:
(1) 节点在网页快照中对应的矩形框的宽度和高度。
(2) 节点距离页面左侧和顶部的距离。
(3) 令(x1,y1),(x2,y2)表示节点对应矩形区域的左上角和右下角,tnode表示时间串节点,rnode表示记录节点,abs表示绝对值函数,则我们提取,如式(1)所示。
(1)
(4) 统计记录节点下的时间串节点个数。
基于新闻评论网站的特性,我们提取以下特征:
(1) 节点在网页快照中对应的矩形框的宽度和高度。
(2) 节点在网页快照中对应的矩形框的位置,即距离页面左侧和顶部的距离。
(3) 提取节点的宽度与父亲节点的宽度的差,这个主要是用于区分评论记录中的嵌套评论或引用评论。
(4) 节点中所有文字字体尺寸的最大值。
模型方面,考虑到使用的特征均为连续型特征,经过对比,我们选择了使用BP全连接神经网络来进行训练得到网页元素分类器。在实验中,我们使用如图5的网络结构进行训练。

图5 实验网络结构
在最终抽取结构化数据时,由于模型提取了节点的兄弟时间串统计特征,故时间可以直接得到;对于作者信息,我们首先使用正则表达式对作者的URL进行正则匹配。若不存在匹配的结果,则利用节点的视觉信息寻找记录节点中位于最左上角的文字节点作为作者信息;对于正文信息,我们主要使用了基于视觉特征的启发式规则和文本密度的方法进行抽取。令Chari表示节点i下的文本长度,Tagi表示节点i下的标签个数,通过计算每个节点作为根的子树中所有文本的文本长度与标签个数的比值作为当前节点的文本密度,如式(2)所示。
(2)
3 自动生成网页信息抽取模板的方法
在第2节中,我们提出一种基于视觉特征使用有监督机器学习的网页信息抽取框架WEMLVF。该框架具有良好的通用性,但与其他基于视觉特征的信息抽取方法一样,基于该框架的信息抽取算法仍然没有较好的实用性。因为其在信息抽取过程中,首先要花费相当高的时间代价经过浏览器的复杂解析过程获取网页的视觉特征,这一步骤导致基于框架WEMLVF的信息抽取算法在抽取效率方面表现较差。为了提高信息抽取的效率,同时保留算法的准确率,我们希望找到一种在信息抽取过程中能减少或不使用视觉特征的方法。基于模板的信息抽取方法是同时兼具高准确率和高效率的很好的方法之一。模板的生成通常是离线的,不用过多考虑效率问题。因此,我们可以在生成模板时结合基于框架WEMLVF的信息抽取算法,既能充分利用视觉特征,又能保证信息抽取模板的质量。同时,在模板表达时并不使用视觉特征,这样能够在实际抽取过程中完全回避获取视觉特征的步骤,从而达到提高信息抽取效率的目的。
基于以上分析,我们结合框架WEMLVF,提出两种模板自动生成方法,即基于XPath的自动生成网页抽取模板的方法和基于包装器归纳的自动生成网页抽取模板的方法,如图6。在这两种方法中,基于框架WEMLVF的信息抽取算法都在抽取模板生成过程中起到了自动标注网页的作用,即替代了人工标注网页的步骤。

图6 自动生成模板流程
3.1 基于XPath的自动生成模板方法
经过观察我们发现大部分论坛网站和新闻评论网站的网页源码中的记录节点或其祖先节点标签大多带有class属性。于是,我们基于WEMLVF的预测结果直接生成记录节点XPath以及时间、作者、正文的XPath。同时,得到训练集中每个XPath的出现次数。然后,对集合按照出现次数降序排序,我们即得到对应网页集合的XPath抽取模板。在预测时,我们优先选择出现次数最多的XPath来找到预测节点。
3.2 基于包装器归纳的自动生成模板方法
我们在SoftMealy算法的基础上对网页源码分词后建立有限状态转换器(Finite-State Transducer,FST)来构建抽取模板。在构建FST时,我们可以得到每个标记状态对应的关联规则。统计每一对关联规则(SL,SR),记录他们在所有的训练集中的出现次数c(SL,SR)。然后,在预测时间、作者、正文时,由于算法本身可能存在预测错误的情况,可能会引入标注错误。在FST中进行匹配时,会出现多条匹配路径。一条匹配路径可以表示为:
其中,author、time、content的顺序在不同的网页中可能不同。为了尽可能地减少模型引入的误差,我们找到权重最大的那条路径,路径权重定义如式(3)所示。
(3)
即路径中,所有状态对应匹配的关联规则出现次数之和,见算法2。

4 实验
4.1 实验设计
我们的实验主要是为了验证本文提出的信息抽取框架WEMLVF对论坛、新闻评论网站的时间、作者、正文的抽取效果。目前,提出的基于视觉特征的方法,如VIPS主要是对网页进行分块,但并没有介绍对单条记录的定位以及对时间、作者、正文的抽取方法;经典的全自动信息抽取算法MDR提出了基于网页结构相似性的方法来定位记录区域,但并没有介绍对时间、作者、正文的抽取方法;Tristor算法提出了基于时间串聚类的方法,且介绍了对时间、作者、正文的抽取方法,与我们的目标一致。因此,我们设计了如下的实验:
(1) 对比WEMLVF、MDR和Tristor在节点定位方面的准确率;
(2) 对比WEMLVF和Tristor在时间、作者、正文抽取方面的准确率。
同时,为了验证我们的方法同样能够应用在未知的网站中,我们使用交叉验证的方法,将样本按照网站切分为20折,每次使用其中的19折进行训练,然后对剩下的1折进行预测。
为了验证自动生成模板的方法对论坛、新闻评论网站的时间、作者、正文的抽取效果及效率,我们设计了如下的实验:
(1) 对基于XPath和基于包装器归纳的自动生成模板的方法在抽取的准确率方面与WEMLVF进行了实验对比。
(2) 对使用抽取模板的基于XPath和基于包装器归纳的自动生成模板的方法与不使用抽取模板的方法在抽取网页的时间代价方面进行了实验对比。
在测试中我们同样按照网站切分了20折,用其中19折训练,预测剩下的1折。对于剩下的1折,我们将其随机切分成2部分交叉验证。
4.2 实验数据
我们从知名网站“站长之家”中的论坛排行榜和新闻门户排行榜选取了20个国内知名的论坛网站和20个国内知名的新闻门户网站,从中随机选取关键词。在百度搜索时,指定站点(如“key site:www.gusuwang.com”)对每个网站采集了若干个页面,总计有4 164个论坛网页和1 027个新闻评论页面。由此看出数据来源十分多样,且覆盖了国内的主要论坛和新闻门户网站,互联网中每天产生的数据有很大一部分都是来自于这些网站。
4.3 实验流程
我们以腾讯新闻为例,腾讯新闻评论页面中评论部分的HTML源码主要是如下的结构,其中,
…
基于WEMLVF框架,我们使用基于时间串匹配的方法匹配“3小时前”,并召回其所有父亲节点。然后,提取节点的特征并使用模型训练,最终预测得到
//div[@class='comment']/div[@class='comment-user']/div[@class='comment-time']
包装器归纳模板为:
SL=Html(
SR=Html(
)|Html(4.4 实验环境
我们使用phantomJS来采集网页和提取网页的视觉特征。对于模型,使用Keras提供的神经网络框架,构建了三层全连接的神经网络模型。我们的实验在Macbook Pro,3.1 GHz Intel Core i5,16G内存的机器上运行。对于XPath的处理,我们使用了Python的lxml库;对于html源码的预处理和解析,使用了Python的BeautifulSoup库;基于包装器归纳的方法生成模板的实验中,使用了实验室开发的基于SoftMealy的抽取组件mask。
4.5 评价指标
我们主要关注网站的发帖时间、作者、正文,最终对这三个属性分别使用F1值来进行评价。对单个网页,如式(4)所示。
(4)
其中,Ei为模型预测结果,Li为我们的标注集。以网页为单位进行评价,最终我们统计网页的准确率如式(5)所示。
(5)
其中,N为网页的个数。
4.6 实验结果与分析
我们的实验首先比较了WEMLVF与MDR、Tristor在节点定位上的准确率,实验结果如下:
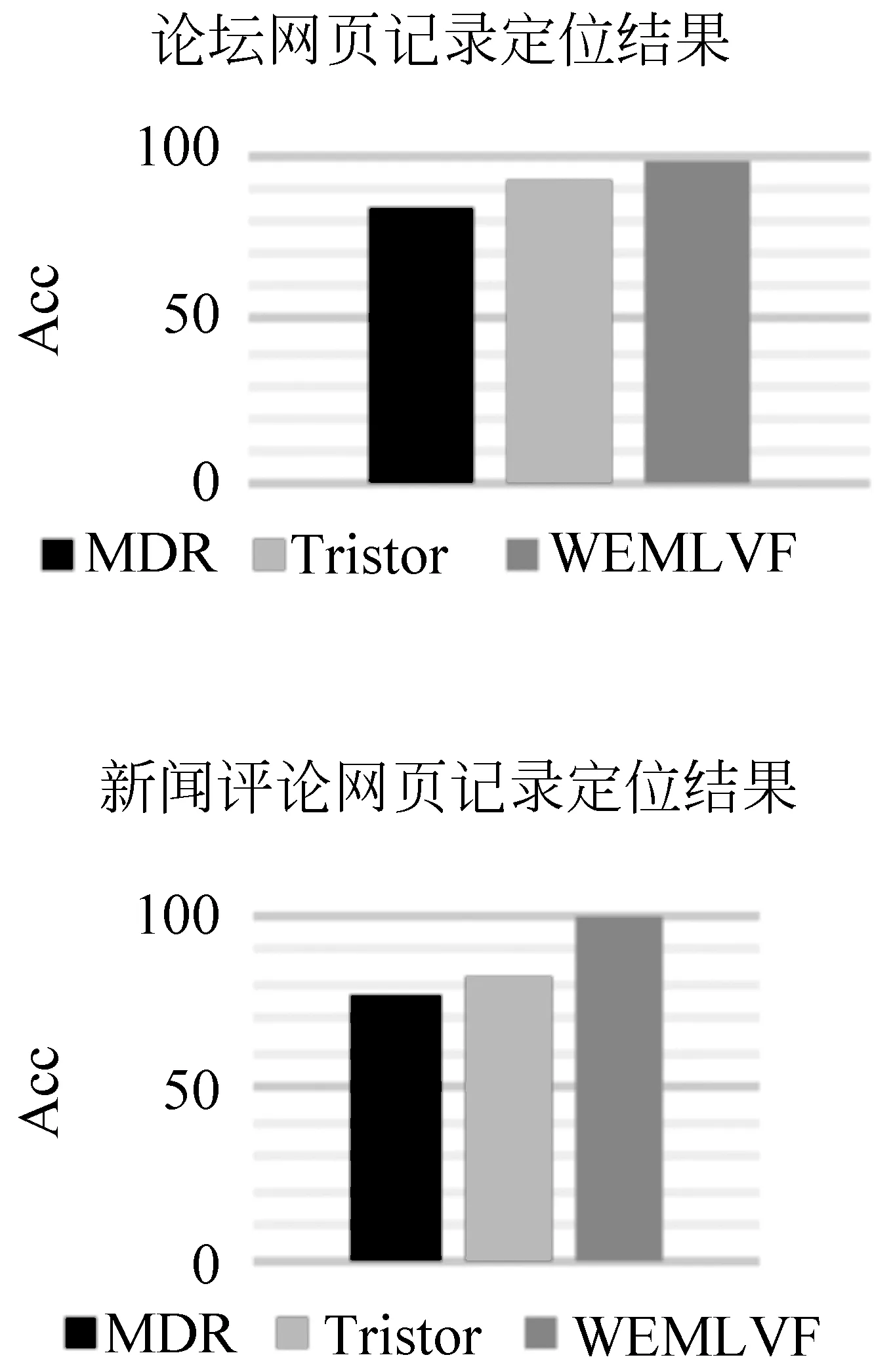
图7 记录定位结果对比
可以看出,WEMLVF在节点定位的准确率上要比MDR与Tristor高。MDR基于网页结构相似度来定位记录节点,对于网页内记录数较少时,无法基于相似度进行定位,故准确率不高;Tristor会先判断页面类型,对于页面内记录较少时会单独进行处理,故效果比MDR好,但仍然有可能定位到噪音信息。
随后我们比较了WEMLVF和Tristor对论坛网页和新闻评论网页中记录的时间、作者、正文的抽取准确率,实验结果如下:

图8 WEMLVF抽取结果对比
从实验结果中可以看出,基于视觉特征的抽取算法WEMLVF在帖子时间、作者和正文的抽取上都较Tristor有一定的提升。算法抽取错误的地方主要在于页面评论只有1条时,我们召回了所有的{node | 以node为根的子树包含时间串}。此时,容易引入一些噪声,降低抽取的准确率,如召回了新闻正文的发布时间所在的区域等。另一个主要错误的原因是部分论坛网站的主贴与跟帖的视觉特征不尽相同,如图4所示,部分论坛网站的主帖与跟帖不在同一个父亲节点下。因此,对于部分论坛网站主帖的抽取可能会引入误差。
从图9中可看出,基于包装器归纳的方法和基于XPath两种自动生成模板的方法的抽取效果与WEMLVF相当。基于XPath和基于包装器归纳是两种不同的定位节点方法,因不同网页的HTML源码结构不同,基于XPath的方法使用了网页标签的属性来定位,如class等。而基于包装器归纳的方法使用了左规则和右规则,即节点上下文的标签序列来定位。因此,对于不同的网页两种方法效果有部分差异。
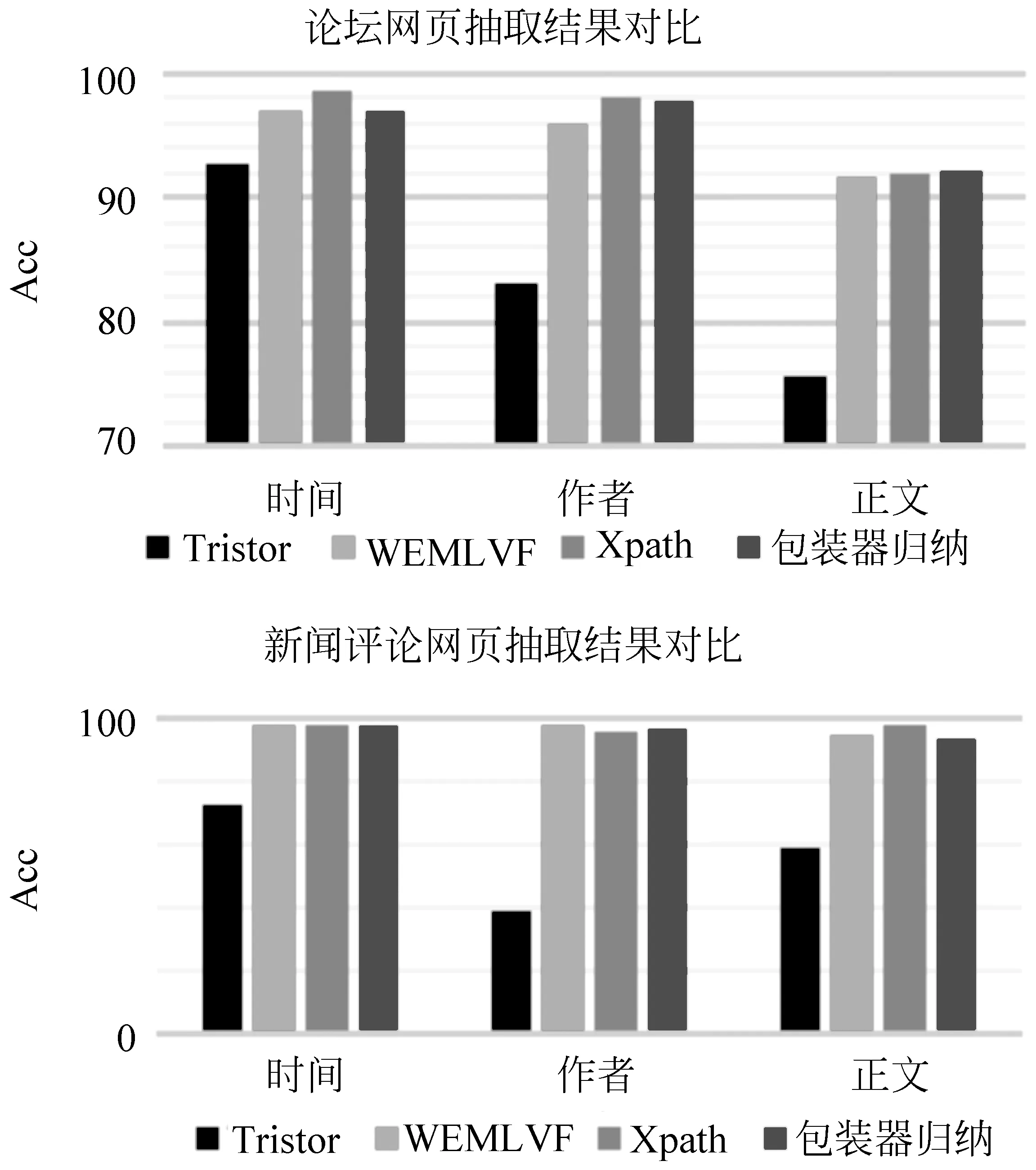
图9 自动生成模板的方法实验结果

算法平均抽取时间/网页WEMLVF4 840ms基于XPath自动生成模板295ms基于包装器归纳自动生成模板105ms
从表1可以看出,自动生成模板的方法对于单个网页抽取的运行时间较WEMLVF有明显提升,因为,在抽取过程中自动生成模板的方法不需要提取视觉特征。基于包装器归纳的方法运行速度比基于XPath的要快,因为基于包装器归纳的方法无需解析HTML源码构建DOM树,只需对网页进行分词得到Token序列来构建FST。
5 结论与展望
本文提出了基于视觉特征的网页信息抽取算法框架WEMLVF,并在论坛和新闻评论网页抽取中进行了实验,验证了该框架的有效性。提出了基于WEMLVF框架,分别使用基于XPath和基于包装器归纳的两种自动生成网页抽取模板的方法,使得在网页抽取过程中不需对网页提取视觉特征,显著加速了网页抽取的效率。通过实验表明,该方法在抽取精度方面能取得与WEMLVF相当的效果,且抽取效率远高于WEMLVF。
在本文的实验过程中,我们还尝试了通过卷积神经网络(CNN)提取网页节点快照中节点对应矩形区域的图片特征。然后,结合所提出的视觉特征共同训练,但最终效果提升不明显。我们希望在未来的工作中能够再对网页快照特征进行更深入的研究,从而在网页信息抽取中更好地利用视觉特征。

3小时前