基于关系网络的PageRank算法在禁毒情报上的应用研究
2019-06-03刘昊,徐鹏
刘 昊, 徐 鹏
(天津市公安局网安总队, 天津 300384)
0 引言
随着网络的飞速发展,互联网被广泛应用于生活的方方面面,在常见的格式化信息产生的同时,文本信息也呈几何级增长。面对大量能体现人的行为和思想的文本数据,如何根据自身需求进行准确解析并分类,快速准确地获取高质量的信息,成为文本信息处理技术面临的迫切需求[1]。
在禁毒领域,情报分析是指情报分析人员利用各种工具和方法,对毒品相关的情报信息进行整理、分析,从而得出相关情报产品的过程[2]。随着移动互联网的繁荣,犯罪分子为了逃避法律的制裁不断更新犯罪方式和手段,将犯罪活动转移到各个社交平台上。如何在海量文本信息中准确找到涉毒嫌疑人便成为当前禁毒情报分析面临的一个难点[3]。传统的禁毒情报文本分析算法是根据文本中词的词性来进行词语相似度计算,从而确定词语相似度,然后根据词语相似度进行简单的加权平均从而得出涉毒案件的相似度值。这种判断方式在计算时所有词性相同的词的权值都为1,因而对“吸”、“嗑药”等涉毒关键词未能起到重视,而对于一些“说”“吃饭”等正常词的权值太大。
针对以上出现的问题,结合实战经验以及算法研究,本文将TF-IDF(term frequency-inverse document frequency)统计方法、层次分析法(Analytic Hieracrchy Process,AHP)和PageRank算法引入到禁毒情报群聊涉毒嫌疑人分析中。通过利用涉毒情报中无痕入群获取的群聊文本及关系,分析文本语义信息,挖掘群聊人员的话题点;使用层次分析法对文本信息中的相关人员进行权值计算;进而以关系网络中的好友关系为链接,以人员权值为权重,针对涉毒嫌疑,使用PageRank算法进行排序,找到其中潜在的重点涉毒人员。该算法克服了传统禁毒情报文本分析算法没有权重和PageRank算法主题漂移的问题,对研究新的涉毒情报文本分析模型和设计涉毒人员挖掘算法具有重要意义,可以为涉毒案件提供重要线索,有效简化办案难度、节省办案时间,具有很高的应用价值。
1 文本分析与层次分析法
1.1 文本分析
文本分析的应用前景广阔,即对文本这种非结构化的数据进行分析,从中挖掘出有价值的信息。其关键指标是相似度,文本相似度可以度量文本之间的匹配程度,相似度越大,文本在语义上越接近[4]。
1.1.1 文本分词
中文文本分析的首要问题是解决分词问题,中文分词算法包含基于统计、规则、字符串匹配3种算法。目前国内外的研究工作中,分词技术已经取得一定的成果,并且开发了很多分析工具,如哈尔滨工业大学的LTP和中科院的NLPIR汉语分词系统等[5]。N-gram模型是一种NLP模型,假设当前词只依赖于前n个词,与其它任何词都不存在依赖关系,一个句子的概率是句中各个词的概率之积,其基于大量的语料,来判断一个句子或词语的合理性,进而将词语切分出来。
1.1.2 词项权值
在向量空间模型中,可用TF-IDF权重表示词的重要程度。TF-IDF是一种在文本分析中的常用关键词提取算法,是词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)的综合表达。
TF,用于表示某个词在文档中出现的频率,简称词频。TF的计算公式如式1所示。
(1)
其中,tf(i,p)是文档p中词ti的出现频率,fij表示文档中词的出现次数。
IDF是对词在所有文档中出现过的程度描述。IDF的计算公式为:
IDFi=log(N/ni)
(2)
其中N表示文档总数,而ni表示出现该词的文档数量。从方程可知,ni越大,表示该词的IDF值越小,也就是包含该词的文档数量越大,该词可区分不同文档的可能性越低。
TF-IDF是将词频和逆文档频率相结合,来度量关键词的权重。TF-IDF值越大,说明该词可能是非常好的关键词。其计算方程如下:
W(i,p)=tf(i,p)×log(N/ni)
(3)
W(i,p)为文档p中词ti的TF-IDF权值。
1.2 层次分析法
层次分析法(AHP) 是在20世纪70年代由美国运筹学家萨蒂教授首先提出,该方法将定性分析和定量分析相结合,具有层次化、系统化的特性,针对特别棘手的涉及定性分析的问题,其分析效果显著。该方法将问题包含的因素分为目标层(总目标)、准则或指标层(选择为实现总目标而采取的各种措施、方案所必须遵循的准则)、方案层(用于解决问题的各种措施、方案等),并在这3个层次的基础上,进行相关分析。层次分析法的流程为:建立相关模型;构造成对比较阵;计算权向量并做一致性检验;计算组合权向量并做组合一致性检验[6]。
针对一个问题,使用层次分析法进行分析,首先要做的就是建立一个层次模型,见图1。以对问题的深入分析为基础,将问题自顶向下分为总目标、各层目标、评价准则与候选方案。对于层次模型中的所有层次,分别依次将该层与前一层相比较,根据某个准则,定量分析每个因素对前一层的影响程度。在此基础上,确定所有因素对问题的重要程度并对其进行排序。枚举可能的解决方案,针对每种方案,确定该方案对问题的权值,得到最终的决策结果。
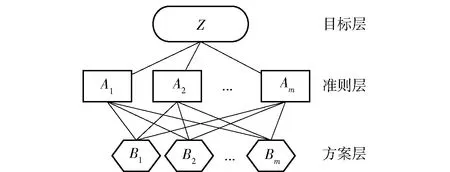
图1 层次结构模型
2 关系网络与PageRank算法
2.1 社交关系网络
自上个世纪70年代以来,集社会学、数学、人类学、通信等学科理论,发展出一个新的科学研究分支,即社交关系网络。社交关系网络一般指基于社会关系以及兴趣爱好等形成的一种错综复杂人际关系网络,网络中涉及多种交织错杂的群体互动行为。直观上,社交关系网络反映出通过各种途径建立起来的人际关系。此外,网络中还包含着人类社会行为特征、行为规律等信息。社交关系网络基本组成要素是节点和边,分别对应着人、人与人之间的复杂关系。因为人所具有的固有属性——社会性,所有网络中呈现一些差异性的结构,比如“小世界”“同配性”等。针对社交关系网络,大多是研究节点和节点之间的连接规律,对应于现实社会中的人与人之间的复杂社会关系。通过对关系网络的研究,来进一步得到其背后隐含的本质特征[7]。在寻找网络社交关系中关键节点方面,许多学者早就应用了PageRank算法。朱颢东等人根据微博社交关系网络对PageRank算法进行改进从而对微博用户影响力进行排序,寻找其中的微博社交网络中影响力大的用户等。
俗话说“物以类聚,人以群分”,在一定程度上,社交网络是对拥有共同兴趣爱好等的人类群体的抽象描述,他们的社会活动深受相似的自然环境、社会环境,特别是成长环境的影响。在违法犯罪领域,尤其如此,其中最明显的就是涉毒。由于涉毒行为是受到法律严重制裁的犯罪行为,因此,涉毒人员为了逃避法律的惩罚而表现出更严重的“小世界”现象,即涉毒人员的涉毒行为只在固定的社交范围人员内进行。现在涉毒人员为了隐蔽涉毒行为而利用即时通讯软件进行联系,因而建立了网络社交关系,所以确定某个涉毒人员后对其所处的社交社区进行分析,很容易找到其他的涉毒人员。
2.2 传统PageRank算法介绍
PageRank算法最早是由谷歌公司的两位创始人Larry Page和Sergey Brin于1998年在《大规模超文本网络搜索引擎的剖析》一文中提出的一种排序算法。之后,PageRank排序算法再结合以其他相关算法,在Google搜索中得到应用,取得巨大成功[8-11]。
PageRank算法有两个基本假设:①如果一个网页通过连接,被很多其他网页所引用,则说明该网页重要,其PageRank值则会较高。此外,如果一个PageRank值很高的网页通过链接被其他网页所引用,那么引用的网页,会因为引用了高PageRank值的网页,其自身的PageRank值也会有一定程度的提高。②如果用户浏览到某个网页,然后顺着网页链接向下浏览而不回退到上一个网页时,则此网页PageRank值则是一个网页的被浏览的概率。
基于以上两个假设,可通过以下方程计算得到网页的PageRank值:
(4)
其中,PR(A)表示网页A的页面级别,即PageRank值,Ti(i=1,2,3,…,n)表示拥有指向A网页的链接的其他网页,PR(Ti)即Ti网页的PageRank值,C(Ti)为网页Ti的出栈链接数量;为了防止网页之间出现悬挂链接而导致维泰概率无法收敛的情况,引入了阻尼系数d,表示用户继续访问当前网页的概率,大小介于0到1之间,一般d取值0.85;1-d表示从当前访问网页随机访问其他网页的概率。为了使PageRank算法的工作原理能够得到完全性地解释,假设有A、B、C、D 4个网页,其连接关系见下图:

图2 网页相互连接图
假设这4个网页的初始PR值均为0,阻尼系数取标准值0.85,则这4个网页的PR值为:
PR(A)=0.15+PR(C)=0.277 5
PR(B)=0.15+PR(A)/3=0.192 5
PR(C)=0.15+PR(A)/3+PR(B)+PR(D)
=0.447 5
PR(D)=0.15+PR(A)/3=0.192 5
以上对PageRank算法的基本原理进行了分析。由此,可以知道PageRank算法是一种基于网页间的链接来对网页进行评分的算法,从而在查询时推荐与主题文本相似度高的网页。因此延伸为使用Page-Rank算法对群聊人员进行涉毒嫌疑度评分,进而找到涉毒嫌疑度高的人员。
3 基于PageRank算法的禁毒情报分析
PageRank算法在网页排序上已得到广泛应用,此外,许多学者将其运用于其他方面,比如微博用户的影响力排序[12-13]等。本文将PageRank算法应用于涉毒群聊文本中群聊涉毒嫌疑度的计算当中。首先,针对不同地区、不同内容的群聊经过数据过滤和切词处理后用TF-IDF找到群聊文本中的关键词,利用关键词的维度计算得到群聊人员的权重;最后使用人员权重根据群聊人员社交关系作为PageRank算法的链接,从而达到找到群聊中嫌疑涉毒人员的目的。整体思路如图3所示。
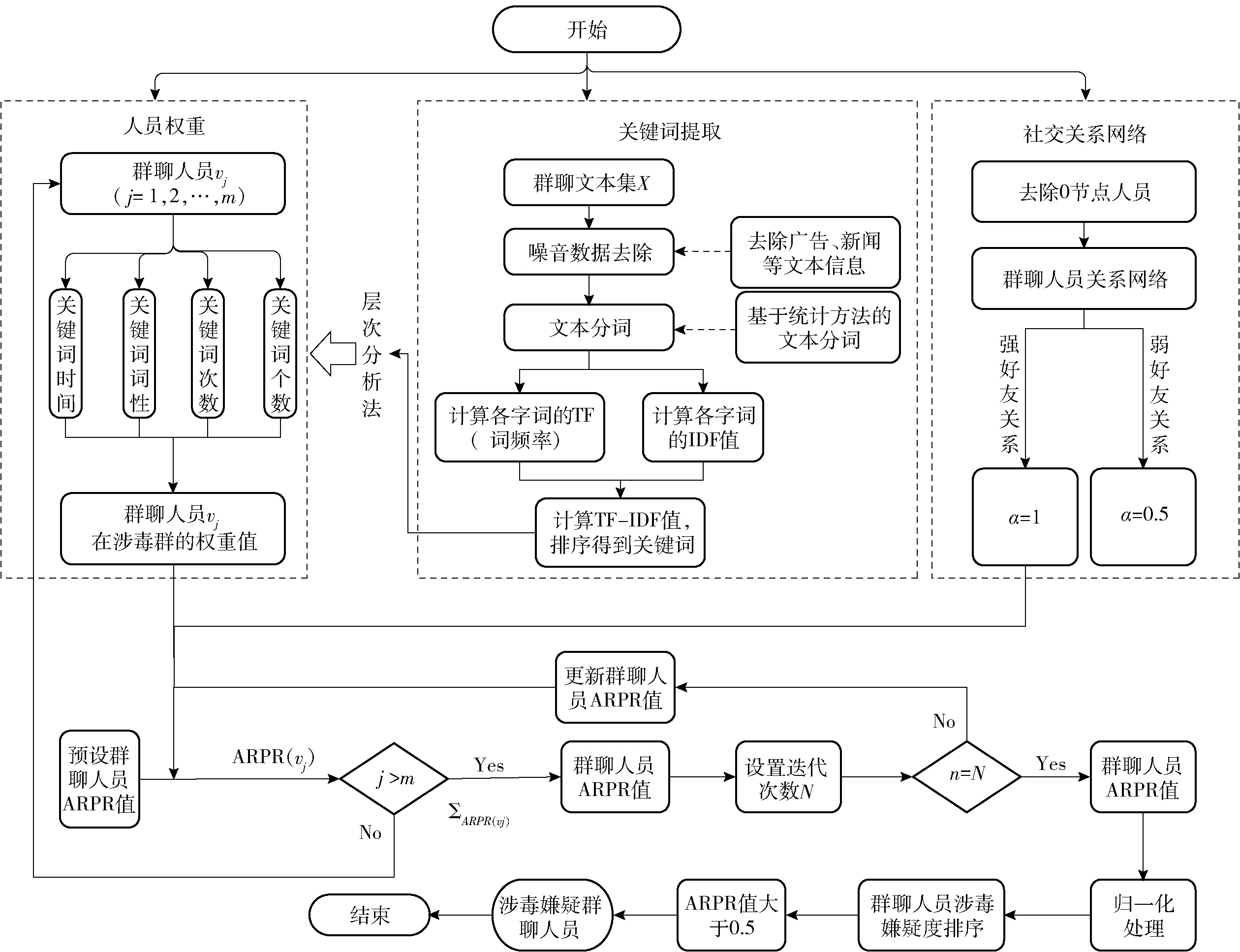
图3 涉毒人员推荐设计思路
针对涉毒情报中的文本数据,其主要分析流程为以下5步:
① 数据源:数据是文本分析工作的基础,来自专网业务系统的文本数据、通过无痕加入涉毒群获取的聊天及关系数据等文本数据。本文所建立模型的数据为IM等即时通讯软件的群聊数据。
② 文本预处理:整理分析所获得文本数据,去除文本中的停顿号、表情符号等,并通过切词等相关算法将中文文本数据转化为计算机可识别的结构化数据。
③ 数据归类:将群聊数据按群进行分类。将原始数据中聊天群按主题进行分类,找出其中的涉毒主题类下的所有人员以及所有文本。
④ 文本关键词分析:使用TF-IDF框架找到文本中的关键词。
⑤ 人员权重分析:根据关键词的维度,通过层次分析法(AHP)对群聊人员进行相关分析。
3.1.1 涉毒关键词筛选
一段话中的关键词代表了一个人想表达的主题思想以及说话内容,因而文本分析中的关键词识别及权重设置是文本识别的关键点。针对短信、IM群聊等文本信息,根据其聊天内容首先进行文本分词,然后通过TF-IDF方程,来设置关键词权值,从而得到文本中的关键词。
中文分词3种方法中,基于统计的匹配方法分词结果和分词速度都能达到让人满意的程度,因此本文采用基于统计的分词方法。使用基于隐马尔可夫假设的N-gram模型进行文本分词;在语料库的选择上,采用中国科学院的跨语言语料库和哈尔滨工业大学的对外共享语料库的并集,通过对禁毒情报文本信息的初步分词,发现以下问题:
① 有的句子分词效果杂乱,有些词没有实际意义,而有的词是犯罪分子涉毒行话、暗语;
② 一些分词错误,如“兰州拉面”是一个品牌,一个整体,但分词分开为“兰州”和“拉面”。
针对这些问题,首先,手动扩充语料库,将所掌握的涉毒行话、暗语加入到词典中;其次,对分词后没有实际意义的词语和符号进行停用,比如“的”“啊”等词语。
使用TF-IDF公式(公式3)计算N-gram模型切出的词语的权值。对于文档p来说,TF-IDF公式对词语权值的判定方法如下:
① 如果某个词在文档p中出现较频繁,而该词出现的文档较少,则该词的TF-IDF值就会很高。
② 如果某个词在文档中出现较频繁,而该词出现过的文档数量很多,则该词的TF-IDF值一般。
③ 如果某个词在文档p中出现较频繁,并且出现过的文档数量较多,则该词的TF-IDF值较低。
④ 如果某个词在文档p中较少出现,而出现过的文档数量较少,则该词的TF-IDF值一般。
通过TF-IDF公式,得到文档中出现的词的权值,选择其中权值大的词作为后续分析的涉毒关键词。针对一些与涉毒有关的暗语,我们进行了分类,部分结果如下:
海洛因:白粉,四仔,四号等;
冰毒:冰,白料,玻璃,合成等;
摇头丸:摇*,糖,朱*力,*仔;
可卡因:可乐,生*,熟*等;
鸦片:黑*,福寿糕;
吸毒用语:溜冰,嗑药,嗨*等。
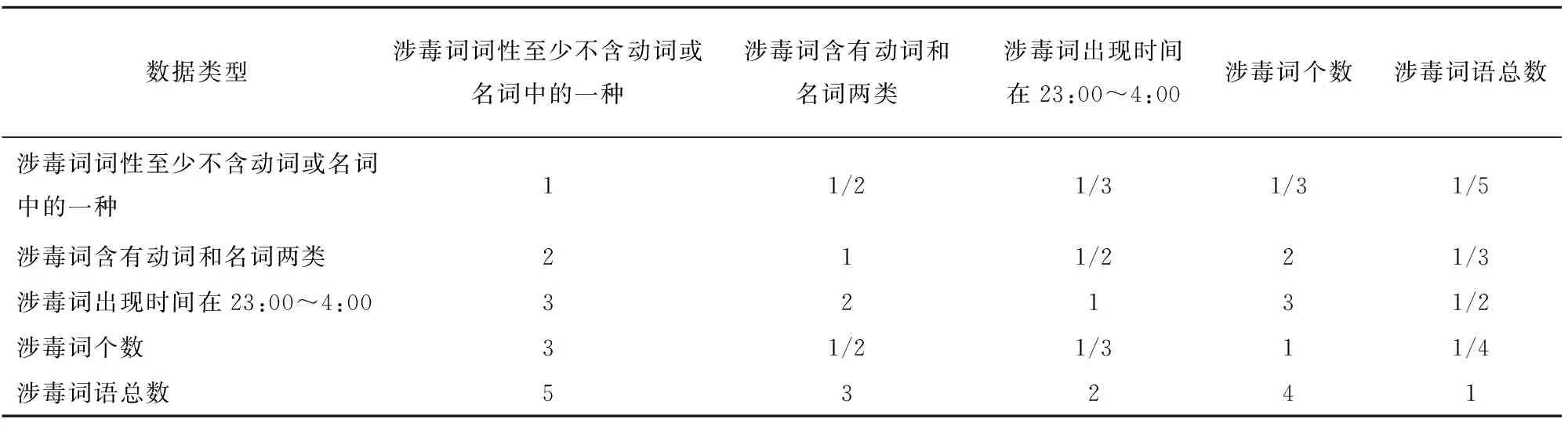
表1 各因素对人员权重的重要性分析
3.1.2 构造人员权重
不同的因素对判断一个人的涉毒权重值影响很大,采用层次分析法来确定聊天人员的涉毒权重值,其中选择了涉毒词词性至少不含动词或名词中的一种、涉毒词含有动词和名词两类、涉毒词出现时间处于23:00~4:00、涉毒词个数和涉毒词语总数这5个维度。如:某人在2016年6月30日23点36分于某群说“我是来找玻璃的,求玻璃”,其中涉毒关键词是玻璃,时间是2016年6月30日23点36分,词性为名词,总数为2次,个数则是这段话出现1个涉毒关键词。
分析“人员权重值”的判断矩阵,如表1所示,其中每一个值代表其横向指标相比于纵向指标的标度,即对于总目标,横向指标与纵向指标之间重要性的比较。
由表1即可得到相关的判断矩阵A:

权重分布为WA=[0.071 3,0.148 6,0.249 1,0.114 1,0.416 9]T,且矩阵A的一致性指标CR=0.035<0.1,满足一致性检验。
3.2 构建涉毒人员关系网络
将文本数据按照人员进行分类,如果是IM等群聊信息,分析群聊人员的好友关系,如果群聊人员A其好友中有群聊人员B,而B也添加了A,则A与B建立好友关系,这是一种强关系,在现实生活中可能是朋友关系或者存在相同兴趣爱好的人;如果A添加B,而B没有添加A;或者B添加A,而A没有添加B,则A与B之间是弱好友关系。基于这种好友关系,使用所有群聊人员组建群聊关系网络;如果是短信,若A给B发送信息,同时B也给A发送过短信,则A与B建立强好友关系;但是,如果只有A给B发送信息或者只有B给A发送信息,则A与B建立弱好友关系。对于强好友关系,可将好友之间边的权值设为1,而弱好友关系,好友之间边的权值为0.5。
3.3 涉毒人员推荐模型
将PageRank算法应用于涉毒群聊文本中群聊涉毒嫌疑度的计算当中。使用一个已经破获的贩毒团伙所建立的毒品传播群聊文本数据来验证PageRank算法是否有效。其中大部分涉毒人员的PR值较高,证明PageRank算法应用于涉毒文本分析的有效性;但有几个非涉毒群PR值偏差较大,即出现主题飘移现象。针对出现的问题,对公式(1)进行分析,传统PageRank算法往往采用平均传递法传递群PR值,致使某些和主体存在较大偏差的群获得了较高的PR值,即存在主题漂移现象,因此本文拟结合AHP对PageRank算法进行相关改进。以涉毒关键词维度为AHP准则层,构建群聊人员权值WAHP,设为PageRank算法的权重,并以关系网络中的好友关系为链接,设置为PageRank算法的出度,具体公式为公式(5),称为AHP-Relation-PageRank(ARPR)算法。
(5)
其中ARPR(ui)表示群聊人员ui的涉毒嫌疑度,d为阻尼系数,一般情况下取0.85,WAHP表示AHP建立的人员权重,Nrelation表示与vi建立关系网络的好友数量,ARPR(vi)表示聊天人员vi的涉毒嫌疑度。完整的ARPR算法见表2。

表2 ARPR算法

图4 ARPR算法六次迭代演示
图4描述了ARPR算法在仅有4个节点包括给定目标节点v的图中的6次迭代过程。对于源节点u,s是π(u,v)的当前估计值,优先级p是残余概率。优先队列算法每次从优先级队列中取出PR最大值进行逆向推送,直至所有节点都满足|π(u,v)-s[u]|<ε,即最终的ARPR估计值与ARPR实际值之间的偏差不超过阈值ε。其中填充灰色的节点表示下一步将要执行优先级传送操作的节点。
4 案例分析
本文使用57个与吸毒或贩毒人员有联系的IM号码,整理这57个IM号码所加入的156个IM群,提取IM群一个月的群聊内容,针对这些群聊文本展开分析。
4.1 涉毒人员权重计算
第1步:去除文本中的停顿号、表情符号等,并将中文文本数据转化为计算机能够识别的结构化数据(共226 960 332条)形成本次分析的数据。
第2步:群聊数据中存在大量重复的广告或者新闻文本,没有分析价值,观察广告。
文本一般较长。抽取2 631 431条数据,分析文本长度分布,如图5所示。假设文本长度符合二项混合高斯分布,通过EM算法估计拟合参数,确定分割阈值为42,即少于42个字为聊天文本,多于42个字为广告、新闻文本。
针对群聊文本去除噪音数据,将超过42个字的文本去除,剩余数据为142 855 496条,数据类型如表1所示。然后对群聊中的涉毒前科人员进行人工打标,共打标110 087个ID,其中有涉毒前科的ID共3 667个。
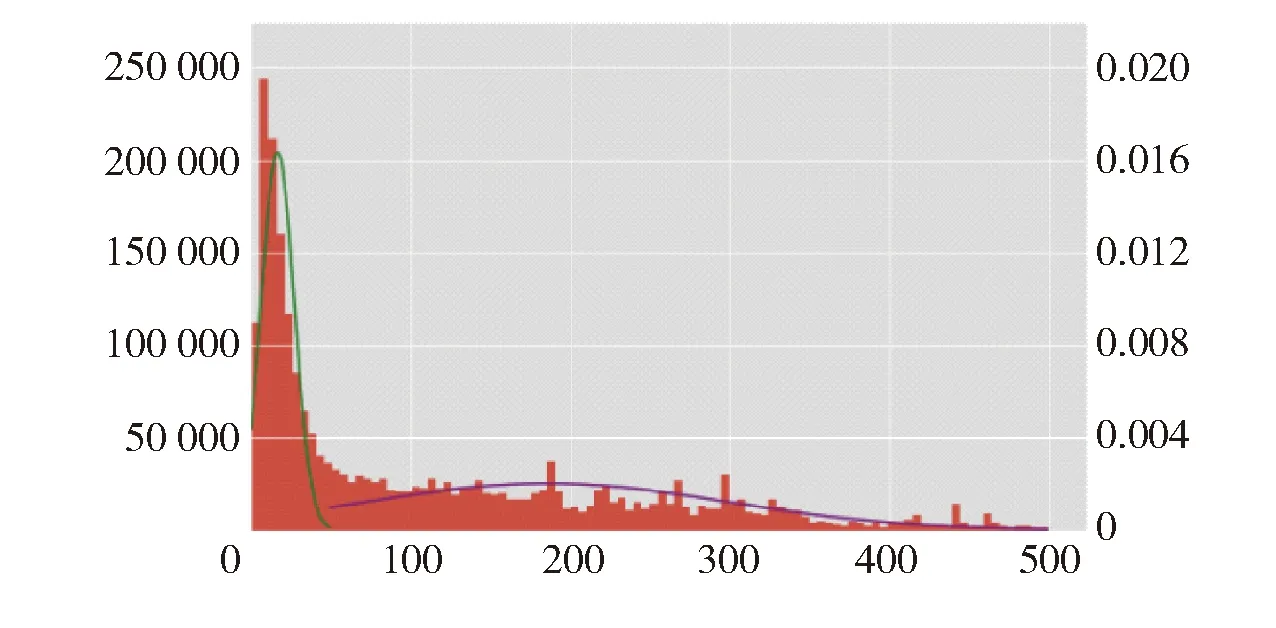
图5 文本信息长度分布
第3步:使用N-gram模型进行文本分词,对于切出来的每个词,使用TF-IDF来计算权值,进而找到可能的涉毒关键词。根据相关经验以及与相关民警求证,将涉毒关键词与相关毒品的联系进行经验分类。

图6 人员关键词权值
第4步:根据聊天文本中是否包含得到的涉毒关键词,对106 420个非前科群聊人员进行了简单的区分,其中未包含涉毒关键词的人员有104 710个,包含涉毒关键词(即有涉毒可能性)的非前科人员有1 710个。根据涉毒关键词5个维度使用AHP对110 087个ID进行人员权重计算,这5个维度的权值非别为WA=[0.071 3,0.148 6,0.249 1,0.114 1,0.416 9]T,综合考虑,得到人员权值,如图6所示。Normal为未包含涉毒关键词的人员权值,Junker为存在涉毒前科的人员权值,Suspects表示包含关键词的非前科群聊人员。可以看到人员关键词权值在一定程度上可以将这3种打标人员进行区分,但位于0~0.5分值的人员太多,无法根据人员关键词得分对其进行进一步区分。
4.2 涉毒人员推荐及对比
在上述数据中,选择一个网络关系密切的群组,其中有3个IM群,共涉及305个IM号,包含8个涉毒前科IM号。针对这305个IM号绘制涉毒关系网络,如图7所示。

图7 重点人员社交网络关系和ARPR值
①涉毒关系网络绘制
根据IM好友关系绘制关系网络图。
②网络节点筛选
本文分别使用图中心度算法和ARPR算法来对比验证模型效果。图中心度算法,其原理是计算某个点到其他各点的距离之和,其值越小则总体上说明该点与其他各点越接近,体现了点的邻近分布程度。图中心度算法保留节点间存在3次及3次以上联系并且网络密度值在整个网络密度值中高于50%的节点,然后计算网络节点的中心度。ARPR算法保留节点间存在3次及3次以上联系并且人员权重在0.5以上的节点;以IM好友关系网络为链接,以人员权值为权重,运行ARPR公式,将迭代次数设置为100次,计算网络各节点的ARPR值。
③重点涉毒人员推荐
在图中心度算法中,选择中心度大于0.5的一个关系网络,进行重点涉毒人员推荐展示。在ARPR算法中,选择ARPR值大于0.5的一个关系网络,进行重点涉毒人员推荐展示。
图中心度算法和ARPR算法推荐了8个嫌疑IM号。如表3所示,两种算法推荐出2个相同的前科人员(40632****,35777****),3个相同的非前科人员(71293****,179595****,101230****)。

表3 ARPR算法推荐涉毒嫌疑人员排序
表4为两种算法所推荐的不同涉毒嫌疑IM号。图中心度算法和ARPR算法存在3个不同的重点可疑涉毒IM号,从IM的涉毒关键词、关键词个数和聊天文本来看,ARPR算法推荐重点人员的涉毒可疑程度比图中心度算法更高。从算法效果来看,本文设计的ARPR算法在禁毒情报上的应用效果更加准确。
5 结论
为了解决移动“互联网时代”涉毒情报的数据海量、文本复杂、涉毒人员发现难等问题,本文将PageRank算法引入到群聊人员涉毒评分中,又针对PageRank算法存在的网页权值均分、主题漂移等问题提出将AHP与PageRank相结合的ARPR算法。首先,调用TF-IDF找到群聊文本中的涉毒关键词,根据文本命中的涉毒关键词的5个维度使用AHP设置群聊人员权重,最后根据群聊人员关系网络使用PageRank算法得到群聊人员涉毒嫌疑度得分,并对群聊人员进行涉毒嫌疑度排序和重点涉毒嫌疑人推荐。ARPR算法不仅继承了PageRank算法的核心思想,而且还实现了基于禁毒情报相似度的涉毒人员推荐设计方案。通过实验,ARPR算法的有效性得到了检验,为禁毒情报分析提供了更加可行的算法,具有广泛的应用价值。
