基于关键词加权的法律文本主题模型研究∗
2019-06-01张扬武李国和王立梅
张扬武 李国和 王立梅
(1.中国石油大学(北京)地球物理与信息工程学院 北京 102200)(2.中国政法大学法治信息学院 北京 102249)(3.中国石油大学(北京)石油数据挖掘北京市重点实验室 北京 102200)
1 引言
随着移动、高速、大数据存储的互联网时代的到来,信息和数据的组织和管理将会越来越困难,也将越来越重要,如何推荐用户所需的信息成为当前技术研究和应用的迫切要求。主题模型是一种文档-主题、主题-词的三层贝叶斯概率生成模型,当前在内容推荐、话题跟踪、信息检索、社交分析以及文本分类聚类等领域有着广泛的应用。建立统一的司法信息资源是我国大数据战略在司法领域的内容,司法业务信息资源分类与管理技术是实现智慧司法的重要基础和前提。虽然我国法律体系不是判例法,但是参考已有类似判例,既可以维护法律的权威性,又可以避免法官滥用自由裁量权,同时,也大大降低了对有限的司法资源的浪费。司法资源信息化需要构建以审判为中心的智慧司法业务协同技术体系,建立智慧司法业务协同支撑平台,强化检察权、审判权、执行权相互配合和制约的信息能力。因此,有效利用已有的法院的裁定书、判决书以及电子文书进行判例推荐,在诉前可以为当事人提供咨询意见,在诉中为律师提供辩护建议,在判决时为法官提供裁判参考。
2 相关工作
Blei等2003年提出LDA(Latent Dirichlet Allocation)主题模型[1]。主题模型是一种多项式分布的概率生成模型,多项式分布的参数符合Dirichlet分布,并且后验分布和先验分布是一对共轭分布。在生成一篇文档的某个词时,通过一定概率选择了某个主题,然后从该主题中以一定概率选择某个词,反复重复这个过程便生成了一篇文档。为了解决主题之间的关联问题,Blei于2006年提出模型相关主题模型(Correlated Topic Models,CTM)[2],将多项式概率的参数分布从Dirichlet分布修改为逻辑正态分布(Logistic Normal Distribution)。为了考虑时序变化对主题生成的影响,Blei又提出了动态主题模型(Dynamic Topic Models,DTM)[3]。
一般的主题模型根据贝叶斯概率假设生成文档[4],每个词表现为统计上的某种参数分布,通过后验分布,重新调整参数估计。但是在法律文本中,一些重要位置上出现的关键词对法律资源分类起着重要作用。Yao等提出文档中的每个词对文章的描述能力是不一样的[5],区别每个词对文章的贡献是必要的,Chew提出对关键词的合理加权将会更加突出对文本描述能力强的词语在主题分布中的贡献[6]。Huang提出一种主题模型和向量空间模型相结合的主题发现方法,在线性加权后计算文本相似度[7]。
主题模型可以根据文档词语生成潜在的主题分布,这是一种词袋模型[8],文档中的词具有相同的语义权重[9]。词汇具有同义性、近义性和多样性,如果不对重要词进行强调,简单地以概率抽取全部词,将会导致主题分布具有一定的局限性[10~11]。很显然在法律文本中,应当在统计概率的基础上,使有些关键词具有比其它词更高的权重[12~13]。提出一种基于关键词加权的法律文本主题模型,从词-主题的分布中,将关键词所属的最大主题进行标记,然后在文档-主题分布中,将出现关键词的文档的标记主题加权,计算加权后的文档-主题分布的相似度,进行主题推荐。
3 加权主题模型
3.1 LDA模型
LDA是一种从隐含主题中生成词的独立重复实验的概率模型[14],其过程如图1所示。图1中wm,i为文档中生成的可以观测到的词,α是文档到主题Dirichlet分布的超参数,M为文档总数,θm是第m次文档独立抽样的主题分布参数,也就是第m篇文档的在主题上的多项分布参数。zm,i是第m文档的第i位置的词的隐含主题编号。β是主题到词Dirichlet分布超参数,K为主题总数,φk是在第i个位置上隐含主题为k的词抽样的多项分布参数。图中箭头表示条件概率,θm,zm,i和φk都是潜在变量,方框表示独立重复实验,M和N为实验次数,Nm为第m篇文档中的词的数量。
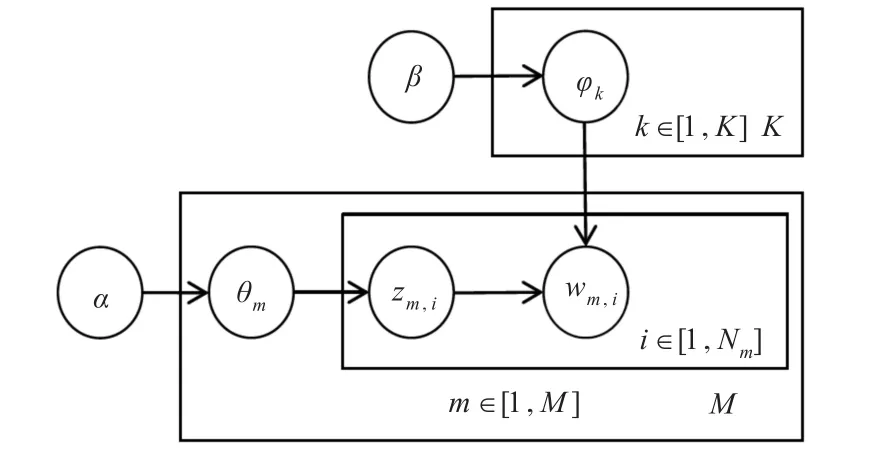
图1 LDA模型
主题模型需要求解每个词的隐藏主题,根据贝叶斯后验概率和边缘概率密度计算,整个文档生成所有单词的概率为
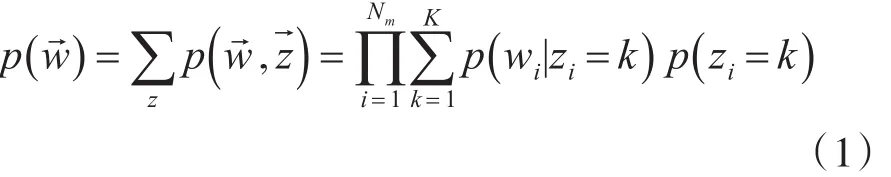
上式问题陷入项KN难题,难以直接求解。求解目标是K维概率分布,采用完全条件概率,在K维向量里轮流每个维度循环的方式进行迭代,最后达到收敛状态,这就是吉布斯采样。
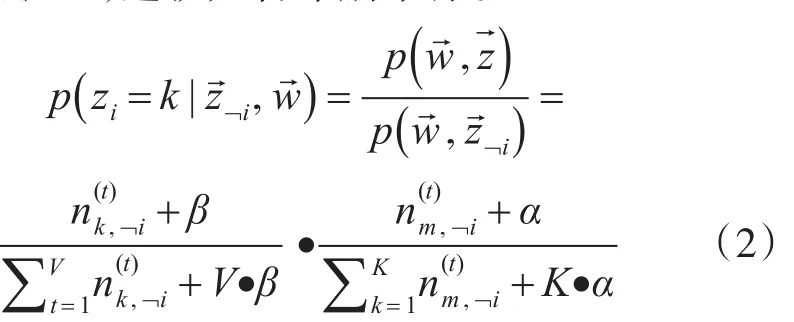
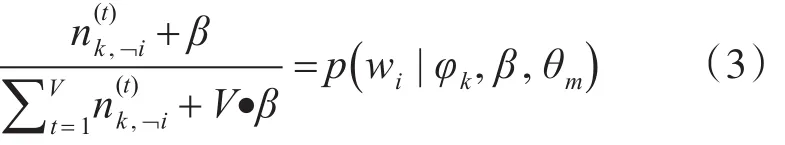
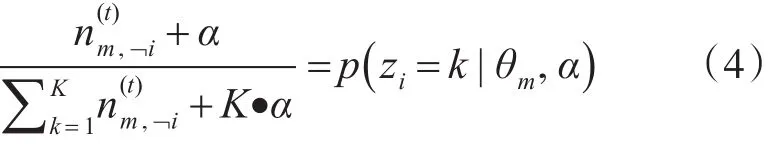
按照上式进行采样,对第m篇文档wi进行隐含主题标记zm,i,在后验分布后,作概率参数估计,即:
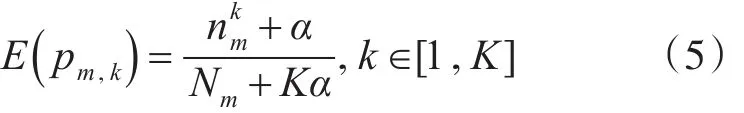

3.2 加权学习模型
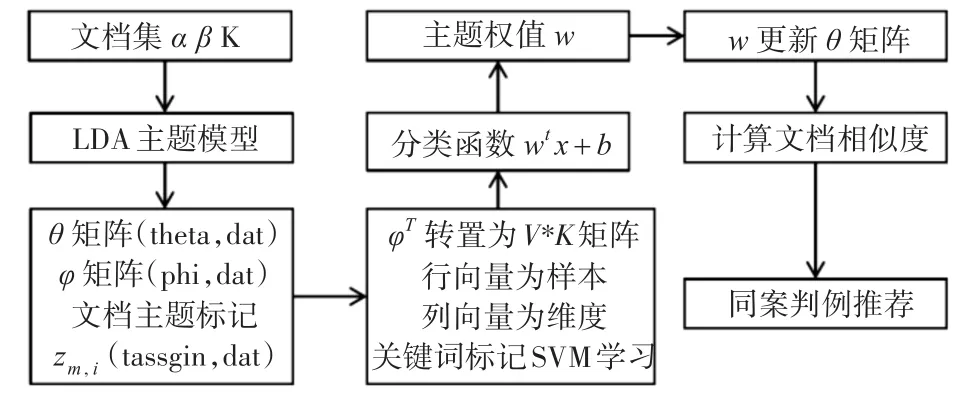
图2 加权学习模型框架
将文档集、超参数α、超参数β、以及主题数K输入给定的LDA主题模型,该模型输出文档到主题分布的θ矩阵、主题到词分布的φ矩阵以及每篇文档的每个词隐含主题标记 zm,i文件[16],加权学习模型框架如图2所示。
其中,θ是M*K矩阵:
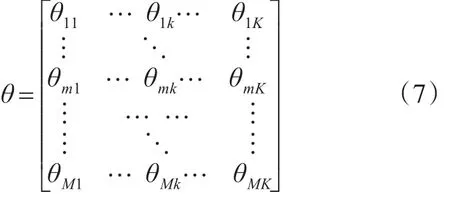
M为文档集中的文档数,K为主题数,θm为某篇文档在各个主题上的概率分布情况,因此:
θ矩阵是从文档到主题的分布,ωkm为第k个主题下抽样为第m篇文档的概率。
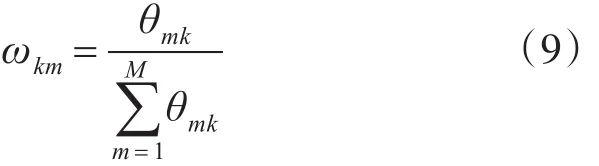
ω为主题到文档的分布,是K*M矩阵。实际上,ω是θT的归一化处理结果,某一主题在所有文档上的概率分布之和为1,即:

在图2中,φ是K*V矩阵:
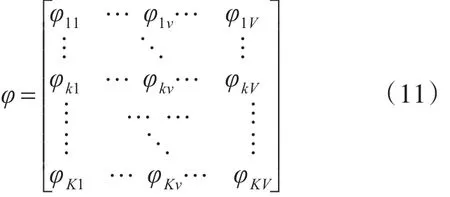
V为文档集中的所有词构成的词典中的词语数,v是词典中的词编号,φk为某个主题在各个词上的概率分布,因此:

φ矩阵是从主题到词的分布,σvk是在第v个词下抽样为编号k主题的概率。

σ为词到主题的分布,是V*K矩阵。实际上,σ是φT的归一化处理结果,某一词在所有主题上的概率分布之和为1,即:

在图2中,φ的转置为φT。在φT矩阵中进行关键词标注,每一行代表一个样本,每一列代表一个特征,将关键词标注为正样本,其他词标注为负样本。将训练数据输入到SVM分类器中[17~18],分类函数为

w是线性分类超平面权值参数,b为分类超平面的截距。x1变量表示第一个主题topic1,xK表示第K个主题topicK,因此:

3.3 文档相似度计算
关键词标注可以根据司法实践经验,也可以通过文档主题推荐。根据两个文档在主题概率上的分布差异的距离,计算文档相似度距离[19],即:
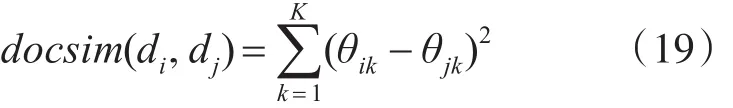
docsim(di,dj)是未加权的文档di和文档dj之间相似度距离计算[20],可以作为关键词标注方法之一。假定第M篇文档为需要匹配的新文档,根据与前M-1篇的文档相似度,计算出最相似的文档dmax,即:

相似度距离值最小的文档为最相似文档,在θ矩阵中找到第dmax行,获得该文档主题分布中的最大概率的主题编号kmax,即:
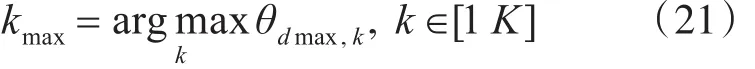
在σ矩阵中找到第kmax列,按照概率大小进行排序,返回前n个词作为关键词进行标注。按照关键词标注以下矩阵,即主题到词分布的转置矩阵φT。然后,将标注后的数据集输入到分类器中进行分类,经过SVM训练后的数据集体现出在不同主题上的侧重,获得权重向量w。最后,计算用w更新后的θ矩阵中的文档相似度距离[20~21],即:
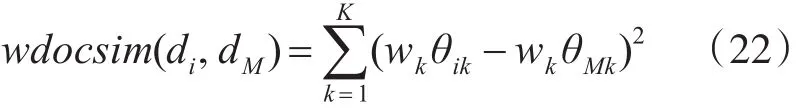
4 实验结果
实验语料集选自Westlaw数据库,文档数为505篇,经过分词后的词典中词数为1985。LDA的模型参数如表1所示。

表1 模型参数
LDA输出θ矩阵,以第505篇文档为新输入文档,按照主题分布计算与其它文本的文本相似度距离,如表2所示。返回的最为相似的文档编号是386,在θ矩阵中查找该文档最大主题编号kmax为第0类。
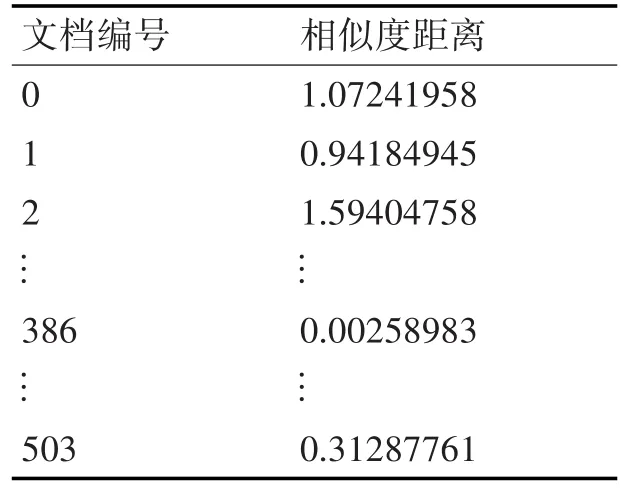
表2 文档相似度距离
σ矩阵中的每一列对应一个主题,按照归一化后的概率进行降序排列,结果是最能表达该主题的词的排序。在σ矩阵中查找第0类主题的top20词,按照top词标记φT矩阵,SVM训练后的权值如表3所示,从中可以看出,权重偏向第0主题。用weight更新θ矩阵,获得加权后的文档主题矩阵θˉ。

表3 SVM训练后的沿主题上分布的权值
困惑度(perplexity)用以评价LDA模型好坏和参数改进的优劣。困惑度越小越好,这说明选择文档的似然函数最大,在一定程度上反应了模型的确定性。困惑度一般按照下式计算:

p(z|d)为文档主题分布,经过计算,未经过加权的文档集的困惑度 perplexity为 23。p(zˉ|dˉ)为加权后的文档主题分布,经过计算,加权后的的perplexity为20。可以看出,困惑度在加权后有着明显改善。
5 结语
法律文书有着与一般文本不同的特点,判例中的时间、地点和法律词汇要比一般词语更加重要。本文提出一种法律文本中的关键词加权的主题模型,在主题模型训练基础上,在词-主题的矩阵中标记那些具有法律意义的关键词,以此作为正类训练,获得这些关键词在主题上的偏好和权重,再将权重更新到文档-主题分布中。实验结果表明,与主题分类模型相比,加权的主题模型具有较好的困惑度,能够在法律文本中过滤掉垃圾词语向量,取得较好的效果,可以提高法律判决文本自动分类的效率。法律文本分类具有交叉性、模糊性和适应性,不同的司法领域对于法律主题存在着不同的理解。因此,不同司法领域下的主题模型的研究将是下一步深入研究的问题和工作方向。
