可动态自适应主题爬虫的研究∗
2019-06-01肖新凤李石君陈亚辉刘倍雄刘永明
肖新凤 余 伟 李石君 陈亚辉 刘倍雄 刘永明
(1.广东环境保护工程职业学院 佛山 528216)(2.武汉大学 武汉 430079)
1 引言
通用搜索引擎逐渐暴露出其专业性不强、搜索结果过于宽泛的缺点。针对于通用搜索引擎的这些弊端和不足,相关学者专门提出了限定在某一特定主题的垂直搜索引擎的解决方案。垂直搜索引擎更专注于特定主题,搜索结果更为细致。是传统的通用搜索引擎的延伸以及互补方案,有效地解决了通用搜。而作为垂直搜索引擎中重要的技术——主题爬虫(topical crawler),主题爬虫是指采用了主题搜索算法的爬虫,在爬行的过程中,可以仅对主题相关的页面进行抓取[1]。业界中对主题爬虫算法的相关研究主要集中在以下四个方面:页面的主题判别;URL重要度排序;领域主题模型的表述;主题资源的覆盖率;传统的主题爬虫使用预先训练好的主题模型算法来判断所抓取得到的目标网页是否主题相关。然而,在实际的状况中,互联网中的各类信息也在始终不断发生着变化,相关领域可能会不断涌现出新的知识和名词,静态的主题模型对动态的网络信息往往无能为力。其次,用户在定义主题时本身就可能存在着领域概念涵盖不全,子领域信息不足等问题。
传统的主题爬虫在面对动态变化的互联网时存在着主题知识涵盖不全、领域知识更新以及主题资源中心转移等问题。针对传统的主题爬虫所存在的不足,本文提出了一种可动态自适应互联网信息的主题爬虫。本文所涉及工作及贡献主要分为三个方面:
1)本文提出了一种可动态选择种子URL的TopicHub算法。主题爬虫在每次抓取任务结束后,基于本次抓取得到的主题页面集构建出站点的主题资源图,同时使用Tarjan算法和缩点的技巧减小图的规模,根据节点的主题特征和链接结构选择出站点THub页面集,最终将各个站点的THub页面集进行合并和排序,作为下次增量抓取的入口链接集。
2)针对于静态本体库所存在的主题信息涵盖不全、领域知识变化更新等问题,本文提出了一种可动态扩充领域语义信息的SDTP算法。结合静态本体库与主题的动态语义来描述主题模型,并根据抓取的主题页面抽取出新的领域名词以扩充主题信息,最终利用相应的算法计算得出网页的主题相似度。
3)基于本文提出的两个算法:TopicHub算法和SDTP算法实现一个可动态自适应的主题爬虫系统TDA-Crawler。该主题爬虫有效地解决了传统的主题爬虫在面对动态变化的互联网信息时存在的不足之处。
2 相关工作
早在1999年,Soumen Chakrabartia等提出可以使用分类器作为主题爬虫中网页主题相关性的判断依据,并抽取出网络拓扑的重要节点,开启了使用机器学习的方法指导主题爬虫的先河[2]。Junghoo Cho等指出在主题爬虫中URL的抓取顺序对于最终的结果有着重要的影响[3]。在该算法中,将Best-first算法的思想应用到主题爬虫的爬行中,有效地解决了传统的广度优先抓取存在的不足。P.De Bra和 Michael Hersovici等分别提出了 Fish Search 算法[4]和 Shark Search 算法[5]用于计算页面的主题相关度。
与此同时,随着对主题爬虫算法相关研究的日趋成熟,许多学者越来越注意到使用静态的主题爬虫模型已无法满足领域知识的变化。Wu等尝试将遗传算法应用到主题爬虫的搜索策略中,根据种群的平均适应度,设置动态适应度函数和遗传算子,以此保证主题爬虫可具有一定的动态适应性[6]。针对于主题爬虫信息的不足,李东晖等提出了可根据网络信息主题自动扩充的无监督的主题网络爬虫[7]。傅向华、冯博琴等实现了一种主题爬虫的在线增量自学习,并以此不断地改善主题评估器[8]。Chang Su等提出了一种高效的基于本体自学习的聚焦爬虫[8]。吴永辉等提出了一种站点排序和种子URL选择的相关算法,可以基于动态选择出热点的种子站点,将选择出的站点列表作为新的种子URL列表[10]。Priyatam等提出利用Twitter中用户发出的链接作为种子URL的筛选池,利用URL构成的图模型来计算页面相似度的方法[11]。
针对传统的主题爬虫的不足Zheng等利用句法依赖分析来改进聚焦爬虫的爬行[12],利用TF-IDF算法和句法共现来抽取关键字,并使用链接锚文本与上下相结合的方法来评估一个URL的优先级。2016年Seyfi等提出T-Graph准则。由T-Graph实现的主题爬虫相比于传统的主题爬虫,召回率提高了接近 50%[13]。Dilip等提出了SAFSB算法用来解决主题的爬虫本体自学习[14]。Hussain等提出了一种无监督的方法,利用基于词汇的本体学习框架和混合语义相关概念,将网页与元数据进行距离匹配,计算其主题相似度,最终实现了一个可自适应语义的主题爬虫[15]。
此外,在主题爬虫中,往往需要反复对互联网进行增量抓取。在传统的实现中,用户往往一次性指定种子URL后,以后每次的增量抓取都从种子URL作为初始入口进入。然而,随着抓取内容和抓取范围的不断扩张,在增量抓取过程中,依然由固定的种子URL出发使得距离种子URL距离过远的主题页面更新速度缓慢,且不利于发现新的关键资源。因此,本文在着力于解决主题爬虫的领域模型的表述和页面主题判别算法同时,研究了主题爬虫在动态网络环境下的主题模型的动态变化,提出了一种可自适应互联网中动态信息的主题爬虫算法。该算法从种子站点的再选择和主题知识的自演变两方面实现主题爬虫的动态适应。
3 源URL的动态更新策略
在实际情况中,用户为主题爬虫所提供的源URL往往质量不高。同时,由于互联网信息的动态变化和网页的持续增加,一方面有可能会有新的优质源URL,另一方面用户先前定义的源URL有可能在新的网络环境出现重要度下降的现象。基于此,本文提出TopicHub算法,用以表示页面在整个主题网页集中的重要度,同时基于TopicHub算法在主题爬虫的网页集中动态地选择出新的源URL。
3.1 TopicHub算法的定义
在本文中,我们把主题爬虫中一个优质的源URL对应的页面称为THub页面。一个THub网页应该具有以下特性:
1)指向大量的主题相关的页面。在HITS算法[18]中称这种页面为Hub页面,通常在现实世界中体现为导航式网站或者目录型页面。
2)指向的页面更新频繁或者所属的站点网页更新频繁。
3)本身就是主题相关度很高的网页。
此外,种子站点以及URL的爬行顺序对于主题爬虫的质量具有极大的影响,在Web网络中主题相关页面指向的网页通常情况下大多数也都是与主题相关。因此URL抓取顺序的先后往往决定着主题页面是否尽快地能被抓取到。
由于互联网信息过于庞大,对于互联网拓扑图往往难以进行分析和计算。在本文中采用了一种三阶段的节点重要度计算方法——TopicHub算法,用来减少网络节点重要度的计算复杂度:
阶段1:计算每个站点的重要度,并统计各个站点的数据信息;
阶段2:在每个站点内部求出THub页面集及其页面重要度;
阶段3:对各个站点的THub页面集进行合并和排序。
3.1.1 站点重要度TSI值的计算
首先我们将抓取到的网页集δ,按URL域名的划分方法,将网页集划分为到各自的站点集S中,其中S∈δ。
本文将从网站更新频度、主题信息和链接结构等方面综合考量一个站点的重要度。在本文中,使用TSI表示一个站点的重要度,其计算方式如式(1)所示:
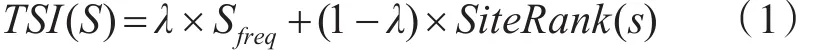
其中TSI(S)指的是网站S的重要度。Sfreq指的是站点更新频度,其计算方式如式(2)所示。该属性在表示站点在单位时间段内新增网页的数目。本文在考虑新增网页数目的同时,也考虑了新增网页中主题相关网页的比例。
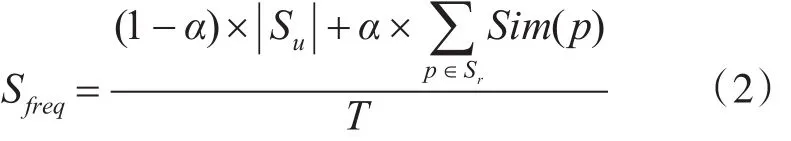
在式(2)中,Sr指的是本次抓取过程中该站点更新的主题相关的网页集,其中 p∈Sr;Sim(p)指的是网页p的主题相关度,该主题相关度由主题相关度算法计算得到;Su指的是本次抓取新增的非主题相关的网页集,而 ||Su则表示该网页集的大小;T指的是从上次抓取到本次抓取所用的时间,以天为单位;α为权重参数,表示站点更新频度中主题因素的占比大小,取0<α<1。
SiteRank(S)是基于PageRank在描述站点重要度方面的改进算法,其计算方式如下:
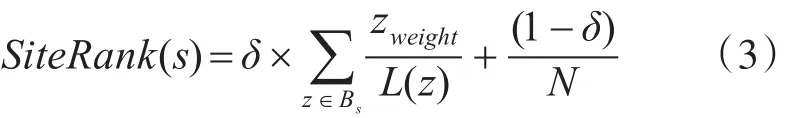
类似于PageRank算法[17],在式(3)中,表示指向站点S的站点集合。L(Z)表示站点Z的出链总数即出度值,N表示站点的总数,δ是阻尼系数,表示跳转到网站的概率。
与PageRank算法在初始化阶段,为每个节点设置了一个统一的随机值作为初始值不同的是,在SiteRank算法中每个站点的初始值为其站点更新频度Sfreq,由式(2)计算所得到。与PageRank算法相似,经过不断的迭代计算,每个站点的THS值将趋于稳定。通过使用式(1)在网页集中进行计算,我们可以得到各个站点的重要度THS值。
3.1.2 站点内THub节点的选取
对主题爬虫某个站点的网页集进行站点内THub节点的选取时,对站点网页集进行剪枝,去掉主题无关的页面。在本文中,我们只选择主题相关页面及其入链集和出链集。对于站点s,我们将其中所有的主题相关页面以及其中每个页面p的入链集 Γ-(p)和出链集 Γ+(p),将与其构成子图Gs=(V,E)。本文首先从主题相关度和链接结构两方面计算了主题资源图中各个节点的重要度,接着对图模型进行计算,选择出主题资源图中具有代表性的节点集,即THub页面集。
1)节点重要度
我们将主题资源图中一个页面p的重要度表示为如下:
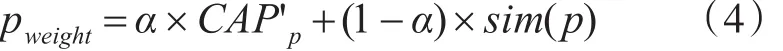
sim(p)表示页面p的主题相似度,CAPp表示页面p的主题聚合度归一化处理后的值,由式(5)计算所得。α表示页面聚合度在页面重要度的比重。
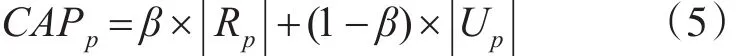
在式(5)中,CAPp表示一个页面的主题聚合度,所谓页面聚合度指的是其指向页面的个数,即外链数。如果指向页面较多,则说明该页面极有可能是索引型页面。我们在考虑页面聚合度的同时,也考虑了主题知识的影响。
其中Rp表示该页面指向的主题相关页面集,则代表其总个数。Up指的是该页面指向的主题无关页面集, ||Up则代表其总个数。β是阻尼系数,表示主题因素在页面聚合度中所占的比重大小,其取值范围为0<β<1。
同时,考虑实际情况下,某些站点可能每张网页的主题聚合度都很大,具体表现为侧栏索引型页面。该类型的页面主体部分为新闻正文,但在左侧栏或者右侧栏拥有大量的指向其他页面的链接,如“热点文章”、“相关文章”等。该类型的页面将会使得该站点各个页面的CAP值普遍偏高。因此,本文需要对页面的CAP值进行归一化处理,其主要方式如式(6)所示。

在式(6)中,CAPavg代表各个节点的CAP值的平均值,CAPmax表示最大的CAP值,CAPmin表示最小的CAP值。
2)最小覆盖集
构建的网络图各个顶点之间有可能出现环图或者分离的子图。我们需要保证最终找的THub页面可以覆盖到站点主题资源图,即从THub页面出发可以到达主题资源图中的任意节点。为此,我们提出了网络图的最小覆盖集的概念。
本文对主题资源图求取THub节点的主要算法流程图如算法1所示:
算法1有向图缩点算法流程
输出:Gs经过缩点后的有向图。
使用算法4-2求取有向图G的强连通分量集δ
Forδiin δ
forvinδi
使用式(4~5)计算得到每一个顶点v的重要度
end for
选择出强连通分量δi的重要度最高的节点vmax
将vmax添加到Vs中
将E中以δi中任一节点为终点的有向边,其终点均改为vmax,构成新的有向边,并将该新的有向边添加到Es中
将E中以δi中任一节点为起点的有向边,其起点均改为vmax,构成新的有向边,并将该新的有向边添加到Es中
end for
forviinVs
forVjinVs
ifei,j∈ Es
将点j以及其所属的边移出图Gs
else ifej,i∈ Es
将点i以及其所属的边移出图Gs
end if
end for
end for
3.1.3 各站点THub页面集的合并及排序
本文使用算法1对各站点计算其内部的THub节点集。在得到各个站点THub页面集之后,需要计算每个THub页面的全局权重,并将其根据词权重进行排序后,统一作为待抓取队列的初始值。其中THub页面的全局权重计算方式如式(7)所示:
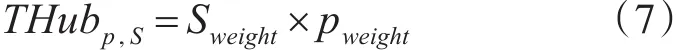
在式(7)中,THubp,S表示属于站点S的THub页面的综合重要度。Sweight表示该页面所属站点的站点重要度,可由式(1)计算得到。 pweight表示该页面的页面重要度,由式(2)计算得到。THub页面的全局权重计算方法非常简单,考虑了自身页面重要度及所属站点的重要度两方面。
我们首先在各个站点的THub页面集内部进行计算重要度和排序操作,接着对各个站点的有序的THub页面集进行归并排序,最终得到一批页面集或者URL集。该URL集合作为新的种子站点列表,将会被用来初始化主题爬虫再次抓取时的待抓取队列。
3.2 TopicHub算法的分析
上述三阶段的TopicHub算法将站点重要度和页面重要度分开计算,得到一批Thub页面作为新的种子站点。采用上述的三阶段算法相比于传统的全网络型算法来说具有以下优点。
1)相比于全局型算法来说,三阶段算法所建立的网络拓扑图规模较小,可以大大减少其图运算的时间。
2)在站点内部求取THub页面集,可以使得各个站点并行计算。在求取站点内部页面集时,不需要其他站点参与计算,在实际情况下,在各站点内部THub页面集时可以利用多线程或者分布式技术加快运算速度。
4 领域主题的动态自适应策略
随着互联网信息不断发生着变化,相关领域可能会不断涌现出新的知识和名词,静态的主题模型对动态变化的网络信息往往无能为力。其次,用户在定义主题时本身就可能存在着主题模型不够全面,存在外延词匮乏、子领域信息不足等问题。仅仅用静态领域本体库来作为页面主题相关性的考量标准,丢失了主题的语义信息。静态领域本体库的质量完全依赖于领域专家构建的优劣,容易造成领域词不全面、新领域词的出现。同时,也忽略了非领域词对主题信息的影响。本文利用静态领域本体库来识别网页的主题相关性,可以作为主题爬虫的辅助手段,弥补仅仅从语义对页面的主题相关度进行计算,所造成的噪声现象。利用主题相悖词集来去除那些包含相悖词的网页。利用静态主题相似度,来计算页面和领域本体库的匹配程度。在对页面的主题相关度进行评价时,加入了语义因素的考虑。同时实现了可以自动扩充领域相关词的算法。
4.1 动态语义相似度的计算
本节提出了一种基于TF-IDF以及网页标签的关键词权重计算方法,使用动态语义向量的概念,提出了一种从主题网页集中增量补充领域主题名词的方法,并基于Word2vec获取网页的文档向量[16],计算其与动态语义向量的余弦相似度,继而得到网页文本文档的动态语义相似度。
4.1.1 词语权重计算
本文在计算网页文本中的权重时,除了使用传统的TF-IDF算法外,也考虑到现实情况下,关键词在网页中所属的标签或者位置的不同,也往往可以表示权重的大小。在考虑HTML标签对关键词因素的影响时,我们结合HTML标签的语义特征,从中提取了词语的权重信息。本文主要考虑了<title>、<meta>、<h>、<a>、强调型几类标签。也从所在的网页位置中,提取了文本的权重信息。
利用式(8)来计算词语的权重,如下所示:

该权重计算公式即考虑了词语的传统文本处理中的TF-IDF权重,也考虑了网页中特有的语义信息和权重信息。
4.1.2 领域名词的识别和抽取
互联网信息也在不断发生着变化,主题爬虫所关注的领域中,可能会不断涌现出新的知识和名词。另一方面,静态主题本体库本身就可能存在着领域概念涵盖不全的问题。
本文基于Word2vec计算词语的词向量,通过计算两个词向量的余弦相似度来得到词语之间的关联度或者相似度。并基于Web网页的特性对词语进行加权,通过一种离线知识抽取的方式,提取出有可能是新的领域名词,将其词向量、权重等信息加入动态语义向量中。使用动态语义向量的概念表示主题的动态语义特征。动态语义向量DSV(dynamic semantic vector)的表示方式如式(9)所示:
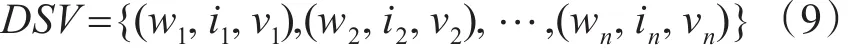
使用式(10)计算新增词的关联度,将主题关联度大于阈值μ的新增词加入主题的动态语义向量中。
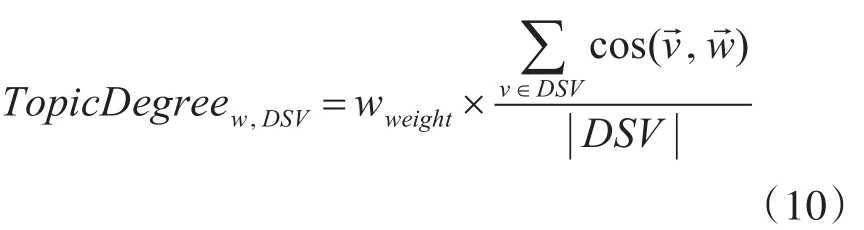
通过计算新增词和每个静态语义向量的相似度之和,然后求其平均值。将该数值与词语的权重信息相结合,继而求得该词语的主题关联度RD。如果RD值大于阈值μ,则判定该新增词属于领域新词,将其词向量、权重信息以及词语本身加入动态语义向量中。
4.1.3 基于Word2vec的网页文本向量表示及相似度计算
在实际情况下,通常将文档以向量的形式表示。基于向量形式来表示文档的方法主要集中在:向量空间模型VSM;Doc2Vec;基于Word2Vec的文档向量表示方法[16]。本文基于Web网络中特有的HTML标签语义以及TF-IDF的加权方法,对单词的词向量进行加权后,转化为文档的词向量。
一个网页的文本信息不仅仅是其网页正文,还包括许多语义信息,如式(11)所示:
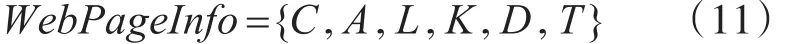
式(11)表明,文本将一个网页的信息归纳为6项。其中C表示网页的正文(content);A表示其父页面指向它的链接的锚文本信息(anthor);L表示每一个HTML标签中所包含的文字(label);K表示<meta name="keywords">中包含的文本;D表示<meta name="description">标签中包含的文本内容;而T则表示网页<title></title>标签中的标题。
使用预训练的Word2vec模型,得到每个词语的词向量。整个文档是由m个单词组成,则文档的词向量组成的矩阵为Am×n,其中m为对应网页文本的单词的个数,n为词向量的维数。在矩阵A中的每一行都代表了一个词语对应的词向量。
我们首先利用式(11)将词向量组成的文档矩阵A,转化为加权矩阵Aw,如下所示。

其中,表示m个词语的权重所组成的对角矩阵,该权重由式(9)计算所得,将其与文档矩阵A相乘,即可得到加权矩阵Aw。将加权矩阵Aw转化为该文档所对应的文档向量C,具体方法如式(13)所示:

ci表示文档向量C中的一项。m表示矩阵A的行数,aj,i表示第j行第i列的元素。通过该公式将各个词语的词向量每一列进行累加,最终得到网页的文档向量。
在得到网页的文档向量之后,我们需要判定网页的主题的动态语义相关性。在本文中,通过计算网页文档向量与主题动态语义向量的余弦相似度来得到网页的动态语义相似度,如式(14)所示:

在式(14)中,DynamicSim(p)表示网页p的动态语义相似度。Cp表示网页p的文档向量,其中每一项可使用式(14)计算所得。DSV表示动态语义向量。最终得到的结果DynamicSim(p)的取值范围为[0,1]之间的小数。
4.2 结合静态本体库和动态语义的主题算法
本文将结合静态本体库方法和动态语义算法,我们将该算法称为SDTP算法,识别所抓取网页的主题相关性。
一个网页的主题相关性如式(15)所示:
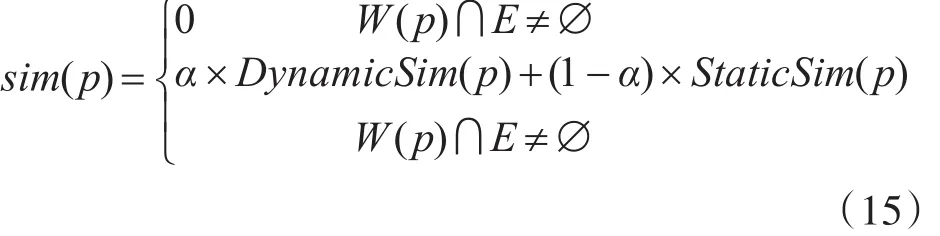
其中DynamicSim(p)指的是网页p的动态语义相似度;StaticSim(p)指的是网页p的静态本体相似度,由式(8)计算所得。W(p)是指网页p经过分词后的词语集合。E指的是本体SDO中的主题相悖词集合。当W(p)∩E≠∅,即网页正文中包含任意一个主题相悖词,则网页的主题相似度为0,判定为该页面属于主题无关页面。当W(p)∩E=∅,即网页中不包含主题相悖词时,则网页的主题相似度将综合动态语义相似度和静态相似度后得出。α是阻尼系数,表明在网页的主题相关度方面,动态语义相似度所占的比重。
5 实验结果及分析
5.1 TopicHub算法的实验结果
根据所提出的优质源URL的特性得知,一个优质的源URL会指向更多的主题相关页面。因此,我们通过更新前后所抓取到的主题相关页面的数目来衡量源URL的好坏,具体如式(16)所示:

在式(16)中,Na表示主题相关页面的数目,T表示单位时间。在本文中,取T为4h。一次单位时间表示一次爬行的过程。
本文将构建一个以“税务”为主题的聚焦爬虫,以中国税网、人民网财经频道、FT中文网以及腾讯财经网作为初始的目标站点。爬虫的初始化URL列表如表1所示。

表1 初始化URL列表
为了验证THub算法的有效性,在主题判别、URL过滤和系统调度方面的实现均保持一致、在进行实验时,尽可能地使两爬虫并行进行,同时将爬虫环境完全隔离的前提下,我们设计了静态源URL爬虫和THub爬虫两个爬虫进行对比实验。为期24h的爬行,分别经历了6次的增量爬行。在THub爬虫的增量爬行过程中,源URL不断发生变化,如图1所示。
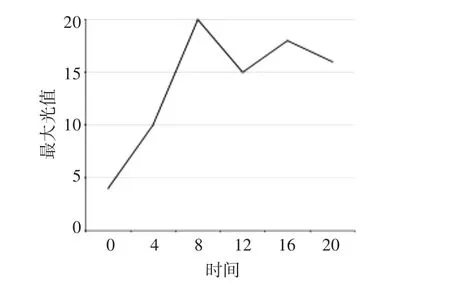
图1 Thub爬虫源URL动态变化曲线图
由图1可以看出,随着每次增量爬取过程中,源URL在不断发生着变化。在时刻12时,此时的源URL列表如表2所示。

表2 动态源URL列表
针对于两爬虫的运行结果,我们统计出两爬虫在各个时间段内的具体数据,并将其绘制成折线图,如图2所示。
在图2所示的结果中,展示了在不同的时间段,静态源URL爬虫和TopicHub爬虫所抓取的新增主题网页数目。在不同的时间段内,互联网的信息变化大小不同,但从图中可以看出,两爬虫的折线趋势基本保持一致。随着时间的增加,各个爬虫所可抓取的主题页面数在不断变少,但总体来说,TopicHub爬虫在抓取的新增网页数目明显多于静态源URL爬虫。
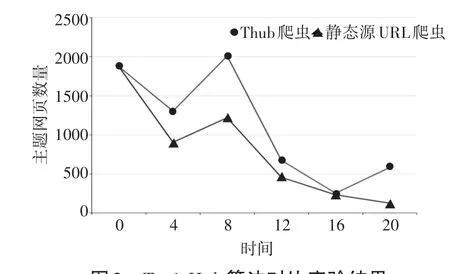
图2 TopicHub算法对比实验结果
5.2 SDTP算法的实验结果
在本文中,将SDTP算法与静态本体库、基于VSM和基于Doc2Vec的主题识别算法进行对比。本文的实验基于用户已标注的网页数据集,主题相关页面占据80%,即其中包含2000张非主题相关页面和8000张主题相关页面。将标注网页数据集按照3:2的比率分为训练数据集和测试数据集两部分。使用测试数据集对SDTP算法、VSM算法和Doc2Vec算法进行训练,得到语义向量。在测试数据集中进行评测,得到各个算法的查准率和查全率,实验对比的结果如图3所示。
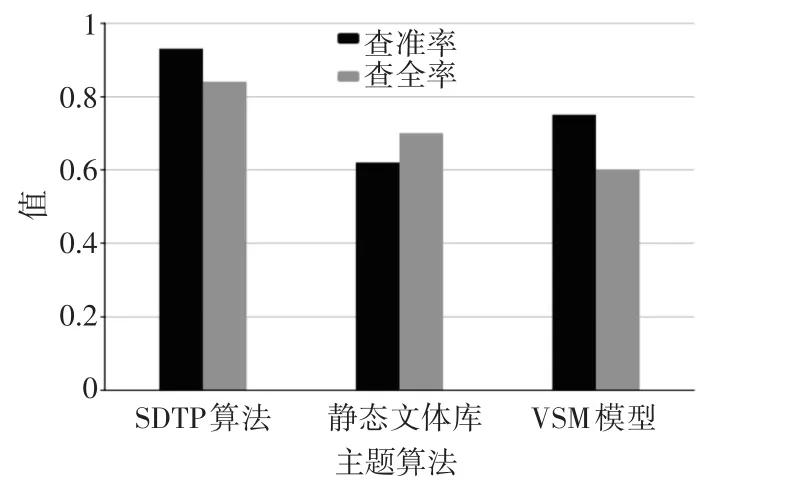
图3 SDTP算法实验对比结果
根据图3可以看出,在税务网页税局数据集中,SDTP爬虫相比于单纯的静态本体库有着明显的优势,查准率和查全率分别提升13%和9%。相比于VSM构建的主题向量,SDTP算法的两项指标分别高出4%和3.2%。
5.3 TDA-Crawler与各爬虫性能对比
将TDACrawler爬虫与基于静态本体库的爬虫、SharkSearch爬虫进行对比,在实验中,每一个爬虫的种子URL设置为一致。实验结果对比图如图4和图5所示。
从图4和图5可以看出各个主题爬虫在随着抓取范围和抓取页面的不断增加,其查准率略微呈现下降的趋势而同时查全率均不断上升,这与实际情况相吻合的。而在图中可以看出,TDA-Crawler的查准率明显高于其他两个爬虫,基于静态本体库的爬虫由于其仅仅使用关键字的匹配原则,在前期抓取过程中,查全率非常高,但是查准率相对而言较低,当爬虫的爬行进行到一定阶段后,查准率和查全率都将受到一定限制。而Shark-Search的爬虫的表现较为中和,缺少TDA-Crawler的动态主题扩充机制,在查准率方面也远不如TDA-Crawler。

图4 各爬虫查准率对比图
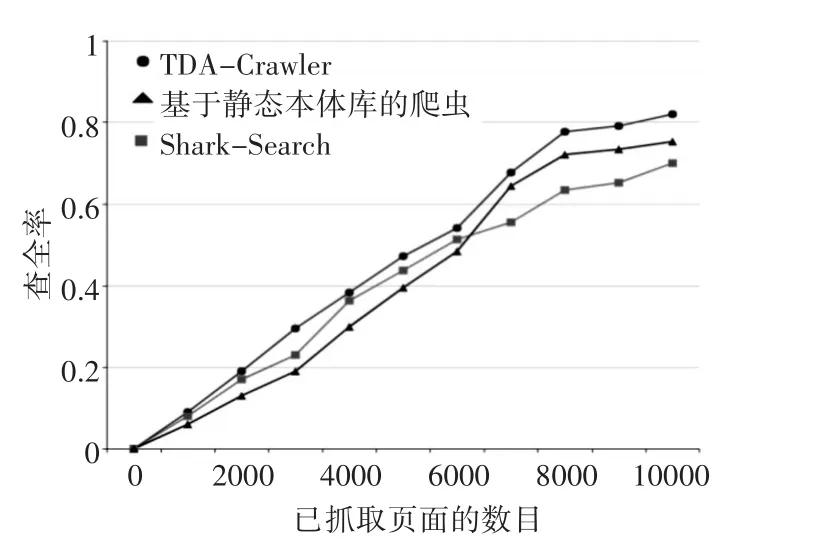
图5 各爬虫查全率对比图

图6 各爬虫抓取效率对比图
图6 看出各个主题爬虫在随着爬虫运行时间的增加,抓取的主题页面数逐渐增加,基于静态本体库的爬虫由于其仅仅使用关键字的匹配原则,在前期抓取过程中可以抓取到更多的页面,但是后期增加趋势放缓。TDA-Crawler在爬虫经历主题动态扩充和源URL的再选择后,在后期的主题页面抓取效率更为突出。
6 结语
本文采用了一种三阶段的算法将站点重要度和页面重要度分开计算,得到一批Thub页面作为新的种子站点。采用上述的三阶段算法相比于传统的全网络型算法来说具有以下优点:相比于全局型算法来说,三阶段算法所建立的网络拓扑图规模较小,可以大大减少其图运算的时间;在站点内部求取THub页面集,可以使得各个站点并行计算。在求取站点内部页面集时,不需要其他站点的参与计算,在实际情况下,在各站点内部THub页面集时可以利用多线程或者分布式技术加快运算速度。
在实际运用中,我们将静态本体库和动态语义向量的方法结合起来,用来判断网页的主题相似度。利用静态本体库专业、权威度高的特征,将网页的文本特征始终与专家提供的静态本体库一致,同时利用计算网页的动态语义相似度,有效地解决了静态本体库概念涵盖不全、非领域词影响不足等问题。TDACrawler的综合性能进行了评估,实验证明,相比于传统的主题爬虫,TDA Crawler在性能和查准率方面均有一定的提高。
