对抗样本在自动驾驶领域应用现状
2019-05-31崔岳
崔岳
[提要] 对抗样本是指通过添加干扰产生能够导致机器学习模型产生错误判断的样本。过去几年人工智能学者取得巨大的突破,深度学习更是让冷冰冰的机器“耳聪目明”,不仅能够从视频中认出猫,还能识别路上的行人和交通信号灯。科学家和工程师在图像、语音、自然语言处理等方面取得突破性进展,某些领域AI已经超越人类。然而,研究者也发现,基于深度神经网络模型的系统,很容易被对抗样本欺骗愚弄。在自动驾驶领域,研究对抗样本的攻击和防御情况,对自动驾驶行业的发展具有深远影响。
关键词:对抗样本;自动驾驶;机器学习;神经网络
中图分类号:TP3-05 文献标识码:A
收录日期:2019年1月10日
一、对抗样本与对抗攻击
从2013年开始,深度学习模型在多种应用上已经能达到甚至超过人类水平,比如人脸识别、物体识别、手写文字识别等等。在这之前,机器在这些项目的准确率很低,如果机器识别出错了,没人会觉得奇怪。但是现在,深度学习算法的效果好了起来,去研究算法犯的那些不寻常的错误变得有价值起来。其中一种错误就叫对抗样本。
对抗样本是机器学习模型的一个有趣现象,攻击者通过在源数据上增加人类难以通过感官辨识到的细微改变,但是却可以让机器学习模型接受并做出错误的分类决定。一个典型的场景就是图像分类模型的对抗样本,通过在图片上叠加精心构造的变化量,在肉眼难以察觉的情况下,让分类模型产生误判。如图1所示,对于一张熊猫的照片,分类模型可以正确地将其分类为熊猫,但是在加上人为设计的微小噪声之后,虽然人眼是对两张图片看不出分别的,计算机却会以99.3%的概率将其错判为长臂猿。(图1)
图1 对抗样本导致图像错误识别图

研究者们认为,大多数机器学习算法对于对抗干扰很敏感,只要从图像空间中精心选取的方向增加轻微的干扰,就可能会导致这个图像被训练好的神经网络模型误分类。这种被修改后人类无法明显察觉,却被机器识别错误的数据即为对抗样本,而这整个过程就可以理解为对抗攻击。
基于对抗样本的此种特性,它的存在对于机器学习领域的发展是有潜在危险性的。例如,在自动驾驶领域,攻击者可以通过对抗样本的方法攻击汽车:只要将自动驾驶汽车需要识别分类的标识进行对抗攻击,让车辆将停车标志解释为“行驶”或其他标志,就能让汽车进行错误判断。这对于自动驾驶领域的发展无疑是不利的。因此,研究对抗样本的攻击与防御方式对自动驾驶领域的发展具有重大意义。
二、对抗样本在自动驾驶领域研究现状
2016年5月7号,在美国的佛罗里达州,一辆特斯拉径直撞上一辆行驶中的白色大货车,酿成了世界上自动驾驶系统的第一起致命交通事故。照理说,特斯拉配备的是当今最顶尖的自动驾驶技术,对这里的人工智能来说,区分好一朵白云和一辆白色大货车,不该是最起码的要求吗?事实却是,人工智能在很多地方都不如三岁的小孩,而且很容易被愚弄,黑客们也正在利用这一點。
(一)自动驾驶领域的对抗样本。除了基于深度神经网络模型的分类系统,很容易被对抗样本欺骗愚弄以外,近期的研究也发现,对抗样本还具有一定的鲁棒性。研究人员将对抗样本打印到纸面上,仍然可以达到欺骗系统的效果。也就是说,对抗样本可以通过打印等手段影响我们生活的真实环境中的。
对于汽车自动驾驶系统,攻击者可以通过这样的手段生成一个禁止通行标志的对抗样本,如图2所示,虽然在人眼看来这两张图片没有差别,但是自动识别系统会将其误判为是可以通行的标志。当自动驾驶系统和人类驾驶员同时驾车行驶时,这足以造成灾难性的后果。(图2)
图2 正常的交通停止标志(左)及其对抗样本(右)图

(二)针对自动驾驶领域对抗样本有效性的讨论。在图像识别领域,对抗样本是一个非常棘手的问题,研究如何克服它们可以帮助避免潜在的危险。但是,当图像识别算法应用于实际生活场景下时,对抗样本的有效性是否不会降低,我们是否对真实世界的对抗样本的危害性产生过度担忧?来自UIUC的一篇论文《NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles》提出,应用于停止标志检测的现有对抗扰动方法只能在非常仔细挑选的情况下才有效,在许多实际情况下,特别是无人驾驶不需要担心,因为一个训练好的神经网络绝大部分情况会从不同距离和角度拍摄对抗样本。前面那些实验忽略了现实世界中物体的关键性质:相比虚拟场景下对图片单一角度和距离的识别,在现实世界中,自动驾驶汽车的相机可以从不同的距离和角度拍下物体来进行识别。从移动观察者的角度来看,目前现实世界中的对抗样本不会对物体检测造成干扰。(图3)
图3 实际场景中停车标志都能被正确识别

他们为此在实际环境下做了一系列实验,他们收集了一系列停车标志的图像,然后用三种不同的对抗攻击方法产生干扰样本,同时攻击图像分类器和物体识别器。然后,打印出受到干扰的图像,从不同的距离拍成照片。实验发现,很多图片不再具有对抗性。并检查了不再具有对抗性的图片中原来增加的干扰的受损程度。在大多数情况下,损坏率很高,并且随着距离的增加而增加。这说明在真实环境中,距离的变化会对干扰的效果产生影响。最后,通过一个小实验表明,照片拍摄的角度也可以改变对抗干扰的影响。
如图3所示,实际环境下,在特定的距离和角度下拍摄的带有对抗干扰的停车标志可能会导致深度神经网络物体识别器误识别,但对于大量从不同的距离和角度拍下的停车标志的照片,对抗干扰就无法保证总能愚弄物体检测器了。
为什么能正确识别大多数图片呢?他们认为原因是干扰的对抗特征对受到干扰的图片的大小比较敏感。如果从不同的距离进行识别,自动驾驶汽车就不能得出正确结论。另外,论文中提出了一个关键问题:是否有可能构建出这样的对抗性样本,使得它在大多数不同的距离观察条件下都能让机器错误判断?如果可能,这种对抗特征能够对人类理解深度学习网络的内部表征模式起到巨大的帮助。如果不能,就可以猜测对抗性样本对现实世界包括自动驾驶领域的危害很小,不用过度担忧。
从实验结论来看,现有的对抗性干扰方法用于停车标志的识别时(在他们的数据集和控制试验之下)只在特定场景下适用。这似乎也表明,我们可能不需要担心多数现实场景下的对抗样本问题,尤其是在自动驾驶领域。
此文一发,立马引起了争议。OpenAI在第一时间便在自己的博客上进行了回击,他们认为物理世界是有稳定的对抗样本的。随后,来自华盛顿大学、密西根大学安娜堡分校、纽约州立大学石溪分校、加利福尼亚大学伯克利分校的8名工作人员,他们提出了一种新的攻击算法,而这种算法能够有效地攻击无人驾驶的神经网络。
他们提出了一种新的对抗样本攻击算法——鲁棒物理干扰(RP2):这种算法产生干扰的方式是在不同的条件下拍摄图像。通过此对抗算法,可以产生模拟破坏或艺术的空间约束性干扰,以减少偶然观察者检测到的似然值。他们通过实验展示了此算法所产生的对抗样本通过使用捕捉物理世界条件的评估方法,在各种条件下实现真正的道路标志识别的高成功率。事实上,他们实现并评估了两次攻击,一个是以100%的概率将停车标志错误分类为测试条件下的速度限制标志;另一个是以100%的概率将右转标志错误分类为测试条件下的停车或添加车道标志。(图4)
图4 带有对抗性贴纸的停车标志图

顺着这个思路,研究人员又针对对抗样本对对象检测工具的影响进行了实验。与分类器相比,对象检测工具在处理整个图像面临更多挑战,对象检测工具还需要预测上下文信息,如目标对象在场景中的方位等。这次,如图4所示,是进行实验的实物对抗样本。研究人员展示的是一个叫YOLO的对象检测器,YOLO检测器是一个流行的、实时的先进算法,拥有良好的实时性能。检测的对象是一个现实场景中真正的停车标志,为了更好地测试YOLO的检测性能,研究人员还录制了视频进行动态检测。逐帧分析视频可以发现,YOLO在实验中几乎在所有帧上都完全没有感知到停车标志。可以想象,如果这发生在现实生活中,一辆自动驾驶汽车面对这样一个标志没有正确识别导致没有及时停下来,那之后发生的可能就是汽车相撞的惨剧,造成无法挽回的后果。
更为有趣的是,这个为YOLO生成的对抗样本同样也能欺骗标准的Faster-RCNN网络。如图5所示,研究人员同样在Faster-RCNN上进行了基于实物的对抗样本动态测试,发现它也很难正确对路牌进行识别。由于是黑盒攻击,Faster-RCNN最终还是识别出了路牌上的STOP标记,看起来不如YOLO实验中那么成功,这也在预期结果之内。虽然这是一次不成熟的黑盒攻击,但随着其他技术的改进,这样的黑盒攻击必将变得更加有效。(图5)
图5

此外,研究人员还发现当YOLO和Faster-RCNN检测到STOP时,相机和路牌的距离往往只有3~4英尺(约1米)了,事实上这么近的距离连触发紧急制动都挽救不回来。
除此之外,近日,谷歌提出了一种生成对抗图像patch的方法,这种方法可以欺骗分类器输出任意选定的目标类。此种方法还可以泛化至现实世界,实验证明可以将patch打印出来,应用到任意的现实场景中,即使在不同光线和方位的条件下,对于分类器仍然能造成对抗效果。如图6所示,patch造成分类器错误识别。(图6)
图6 patch 造成分类器的错位识别图
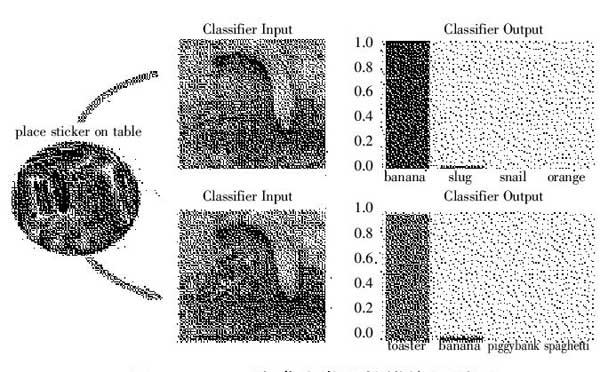
这种攻击方式的出现对对抗样本的研究具有重大意义。因为攻击者构建攻击时不需要知道所攻击的图像是什么。对抗patch被生成之后,可以在互联网上广泛传播,其他攻击者也可以打印和使用。此外,因为这种攻击使用了大幅度的扰动,而现存的防御小幅度扰动攻击的技术可能无法泛化到大幅度扰动的攻击。因此,如何防御这种攻击仍然有待进一步的研究。
三、對抗样本的防御
鉴于数字和物理世界中的这些案例,相关防御措施也是一个广泛研究的课题。虽然人们对对抗样本已经有了更多的了解,甚至找到了抵御攻击的方法,但却还没有一个彻底的解决方案能让神经网络不受对抗样本的干扰。据我们所知,目前发表的对抗样本防御系统在强大的优化攻击面前同样非常脆弱。(图7)
图7 防御对抗攻击的方法分类图
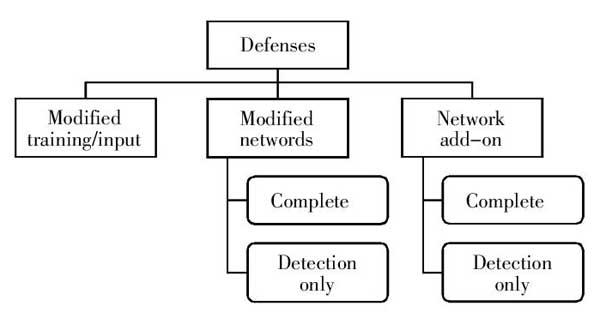
如圖7所示,目前,在对抗攻击防御上存在三个主要方向。其中,不同类型的对抗训练是最有效的方法之一。对抗性训练是一种暴力破解的解决方案。其中,我们只是简单地生成很多对抗样本,并明确训练模型不会被它们中的任何一个愚弄。首先是,Goodfellow等人最早提出用对抗训练提高神经网络鲁棒性。之后,Tramèr等人又将其拓展为合奏对抗学习。再后来,Madry等人也通过迭代训练和对抗性样本提出了鲁棒的网络。找到防御措施的前提是积累大量对抗样本,这不仅能使对应模型的防御效果更佳,如果样本来自不同模型,这样的数据集还能增加多样性,使模型可以更充分地发掘对抗样本的空间。虽然还有其他大量方法,但现有方法在性能上还远远达不到应用标准。
还有一种方式是防御性精炼,这是一种策略。我们训练模型来输出不同类别的概率,而不是将哪个类输出的决策。概率由早期的模型提供,该模型使用硬分类标签在相同的任务上进行训练。这就创建了一个模型,其表面在攻击者通常会试图开拓的方向上是平滑的,从而使它们难以发现导致错误分类的对抗输入调整中作为模型压缩的一种技术而被引入的,在这种技术中,一个小模型被训练以模仿一个大模型,以便节省计算量。
然而,即使是这些专门的防御算法,也可能被拥有了更多计算火力的攻击者轻易破解。之所以难以防御对抗样本,是因为难以构建一个对抗样本制作过程的理论模型。对于包括神经网络在内的许多ML模型来说,对抗样本是对非线性和非凸性的优化问题的解决方案。因为我们没有很好的理论工具来描述这些复杂的优化问题的解决方案,所以很难做出任何理论上的论证来证明一个防御系统会排除一系列对抗样本。除此之外,还因为它们要求机器学习模型为每一个可能的输入产生良好的输出。大多数情况下,机器学习模型运行得很好,但所能处理的只是它们可能遇到的所有可能输入中的很小一部分。
总而言之,对抗样本对机器学习产品是一个大问题,尤其是在视觉方面,比如自动驾驶汽车。研究人员正努力应对上述问题,但结果证明这很有难度。目前来看,虽然此类攻击只发生在实验室中,没有公开测试,但是我们仍需严肃对待。自动驾驶汽车的视觉系统必须是可靠的。
主要参考文献:
[1]李盼,赵文涛,刘强,et al.机器学习安全性问题及其防御技术研究综述[J].计算机科学与探索,2017.11.21.
[2]Goodfellow I J,Shlens J,Szegedy C.Explaining and Harnessing Adversarial Examples[J].Computer Science,2014.
[3]Liu Y,Chen X,Liu C,et al.Delving into Transferable Adversarial Examples and Black-box Attacks[J].2016.
[4]Cisse M,Bojanowski P,Grave E,et al.Parseval Networks:Improving Robustness to Adversarial Examples[J].2017.
[5]Lu J,Sibai H,Fabry E,et al.NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles[J].2017.
[6]Nguyen A,Yosinski J,Clune J.Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images[J].2014.
[7]Moosavi-Dezfooli S M,Fawzi A,Frossard P.DeepFool:a simple and accurate method to fool deep neural networks[J].2015.
[8]Moosavi-Dezfooli S M,Fawzi A,Fawzi O,et al.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)-Universal Adversarial Perturbations[J].2017.
[9]Fawzi A,Moosavi-Dezfooli S M,Frossard P.Robustness of classifiers:from adversarial to random noise[J].2016.
[10]曹仰杰,贾丽丽,陈永霞,等.生成式对抗网络及其计算机视觉应用研究综述[J].中国图象图形学报,2018.23(10).
[11]Kurakin,Alexey,Goodfellow,Ian,Bengio,Samy.Adversarial examples in the physical world[J].2016.
[12]Eykholt K,Evtimov I,Fernandes E,et al.Robust Physical-World Attacks on Deep Learning Models[J].2018.
[13]Athalye A,Carlini N,Wagner D.Obfuscated Gradients Give a False Sense of Security:Circumventing Defenses to Adversarial Examples[J].2018.
[14]Ivan Evtimov,Kevin Eykholt,Earlence Fernandes,Bo Li.Physical Adversarial Examples Against Deep Neural Networks.2017.
