深度学习在医学图像分析中的应用研究综述
2019-05-31黄江珊王秀红
黄江珊 王秀红
(江苏大学科技信息研究所 镇江 212013)
1 引言
人工智能的发展,最早可以追溯到公元前的联想主义心理学理论,到近现代,该理论被多位哲学家或心理学家补充完善,并最终引出了Hebbian学习规则,成为神经网络的基础。深度学习是当今最广泛使用的模式识别方法,其特点就在于“整个程序都是可训练的”。卷积神经网络、深度信念网络、堆叠自动编码器等都是深度学习框架的一种,它们构成了深度学习的三大基础结构网络。与此同时,随着医学影像设备的完善,CT(电子计算机断层扫描)、MRI(核磁共振成像)、X光片、B超、彩超等医学图像大量产生,形成丰富的医学图像资源。但目前大量的医学检验结果、医学图像等内容都只是简单的储存起来,不能被直接提取、统计和分析,很多患者数据特别是医学图像数据没有被有效利用,造成严重的资源浪费,临床工作者也很难从以往珍贵的患者图像数据中发现疾病的发展趋势和其中隐含的规律。所以,将深度学习模型应用到医学图像分析中来,基本流程如图1,挖掘其内含的有价值的医学信息,有着巨大的应用价值和应用前景[1]。

图1 基于深度学习的医学图像分析一般流程
2 在医学图像领域主要应用到的深度学习算法
2.1 卷积神经网络
卷积神经网络属于前馈神经网络,是将输入的影像像素矩阵经过一层过滤器,挑选出特征,再透过池化层,针对输入特征矩阵压缩,让特征矩阵变小,降低计算的复杂度。
卷积神经网络由一个或几个卷积层和顶端的全连通层(对应经典的神经网络)、关联权重和池化层构成。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更优的结果。
2.2 堆叠自动编码器
自动编码器(Auto-encoder,AE)是一种单隐含层的无监督学习神经网络,堆叠自动编码器是由简单结构叠加起来的深层网络,自动编码器的训练过程使用逐层预训练算法,即通过重构误差来进行训练。堆叠自动编码器由Bengio学者提出,其基本元件是自动编码器,它包含输入层、隐藏层和输出层,三层之间逐级连接。自动编码器模型将训练目标设为拟合输入数据,即设定网络输出等于输入,随后使用反向传播算法训练。虽然自动编码器模型的训练过程基于有监督学习算法,但并不要求原始数据有分类标签,因此整个训练过程仍是一个无监督学习过程。
堆叠自动编码器的构建过程是训练得到第一个自动编码器后,将其隐藏层作为输入,用同样的方法可训练第二个自动编码器,依次类推可训练得到多个自动编码器。依次将多个自动编码器堆叠在一起,便构成堆叠自动编码器模型,此时堆叠自动编码器的最后一层是输入数据经过多次变换处理后得到的抽象特征。最后再根据问题不同设定,连接不同的输出层,通过有监督学习算法训练输出层的权值,从而得到最终分类结果。
2.3 深度信念网络
深度信念网络是由多个受限制玻尔兹曼机(RBM)叠加而成的深度网络。它通过无监督预训练和有监督微调来训练整个深度信念网络。预训练时用无标签数据单独训练每一层受限制玻尔兹曼机,通过自下而上的方式,将下层受限制玻尔兹曼机输出作为上层受限制玻尔兹曼机输入。当预训练完成后,网络会获得一个较好的网络初始值,但这不是最优的。再采用有标签数据去训练网络,误差自顶而下传播,一般采用梯度下降法对网络进行微调。深度信念网络的出现是深度学习的转折点,目前深度信念网络已应用于语音、图像处理等方面,尤其是在大数据方面。
2.4 三种深度学习模型的发展历程
本文将卷积神经网络、堆叠自动编码器、深度信念网络三种深度学习模型映射在一个二维空间里,纵轴按照时间顺序探索三种模型的发展历程,具体如图2所示。
早在1980年,Fukushima[2]就已经开始研究卷积神经网络,首次提出了基于感受野的理论模型Neocognitron。到1995年,以Lo为代表的学者们把卷积神经网络应用到医学图像分析中。而第一次将其成功应用到现实生活中是LeNet程序的面世,其主要用于手写数字识别方面[3]。尽管前期在医学图像领域取得了不小的成就,但在多样的新技术产生与核心计算机系统的发展取得显著突破前,卷积神经网络的使用仍没有遇到发展的契机。关键性的转折点是AlexNet在图像网带来的挑战中以绝对性优势战胜了诸多竞争者[4]。随后,卷积神经网络在医学图像领域内的研究一直在进行,3D-CNN模型通过随机对角Levenberg-Marquardt法来优化训练运用到视频分析[5],相关深度模型的使用取得了巨大的进步[6],与此同时,开发了金字塔卷积神经网络(PCNN)对图像进行处理[7]。随后,Simonyan[8]等学者基于AlexNet,着手研究卷积神经网络的深度,开发了VGG网络。到基于计算机视角ResNet网络结构[9]出现的时候,卷积神经网络已成为高级上等的技术。
2006年,Hinton在Science杂志提出了深度信念网络的概念,成功地利用贪心策略逐层训练由限制玻尔兹曼机组成的深层架构;PCD学习算法的提出促进了深度信念网络的发展[10];卷积深度信念网络(CDBN)[11]是一个分级生成模型,可以扩展到现实的图像大小,可以对全尺寸图像执行分层(自下而上和自顶向下)推理;稀疏深度信念网(SDBN)开发后主要用于图像处理[12];随后,增强深层信念网络(BDBN)出现[13],用在统一的循环框架中迭代地执行三个训练阶段。通过提出的BDBN框架,可以学习和选择一组有效表征相关面部外观/形状变化的特征,以统计方式形成强大的强分类器。
自动编码器模型发展至今,不断丰富和完善,从1986年Rumelhart提出的自动编码器,到后来的堆栈自编码器、稀疏自动编码器、降噪自动编码器、收缩自动编码器、卷积自动编码器、拉普拉斯自动编码器等等,一直都处在发展改善中。
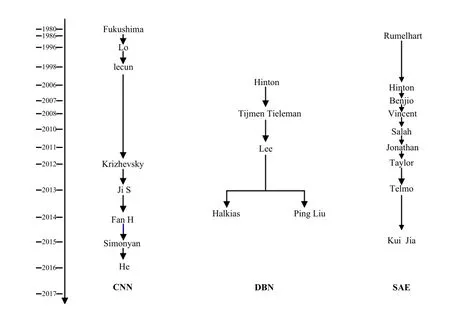
图2 三种深度学习模型的发展历程
3 深度学习算法在医学图像分析领域的应用现状
通过大量的文献调研,我们对深度学习模型在医学图像分析领域的诸多应用进行整理,并在此基础上突出一些关键的应用领域,进而讨论深度学习基本模型存在的问题。
3.1 卷积神经网络模型应用现状
卷积神经网络在医学图像领域拥有大量的研究成果,是应用范围最广的一种模型,国内外专家团队运用该模型在人体的各个部位均有研究。本文主要针对卷积神经网络模型在脑、眼、胸三个人体部位医学图像的应用进行整理、概括。
将卷积神经网络模型运用在医学图像识别中,可追溯到1995年,将双重匹配方法和人工视觉神经网络技术融合,用于肺结节检测。该神经网络技术通常适用于灰度成像中医学图像的识别,通过在DEC Alpha工作室的测试显示了人工视觉神经网络技术在临床环境中的潜在应用[14]。此后,卷积神经网络在医学图像中的应用慢慢开展起来。
在运用卷积神经网络进行图像分割方面,香港中文大学的Hao Chen、Qi Dou等人进行了一系列的研究,先是提出VoxResNet残差网络,探讨了体积脑分割任务中的深度残差学习,并将其扩展到用于处理体数据的3D变体。此外,还提出了VoxResNet的自动上下文版本,以进一步提升低级外观信息,隐式形状信息和高级语境集成的性能。该团队的这项工作揭开了3D深度学习的潜力,从而提高了体积图像分割的识别性能[15]。接着,他们提出了一个基于3D 卷积神经网络的框架,用于异常计算机断层扫描CT体积的肝脏自动分割。通过3D深度监督网络(3D DSN)来生成高质量分数图,并利用条件随机场模型进一步进行轮廓细化,此方法能够让肝脏分割更加准确[16]。随后,他们利用3D卷积神经网络自动检测来自磁共振图像中的脑微血管,提出了一种从SWI图像自动检测脑微血管的高效稳健的两阶段框架,以此提高3D CNN对体积医学数据的检测与分割能力[17]。随后,该团队提出了一种利用三维卷积神经网络在体积计算机断层扫描中自动检测肺结节假阳性减少的新方法,并进一步提出了一种简单而有效的策略来编码多层面的语境信息,以应对随着肺结节的巨大变化而难以模拟的挑战[18]。
除了在图像识别、图像分割上的应用,基于卷积神经网络进行图像分类已有研究。荷兰奈梅亨市Radboud大学医学中心诊断图像分析小组提出了一个基于多流多尺度卷积网络的深度学习系统,可以自动分类与处理相关的所有结节类型,并通过分析给定结节的任意数量的2D视图来学习3D数据的表示[19]。该深度学习系统在分类结节类型方面超越了经典机器学习方法的性能,证明了深度学习模型的可用性与精确性。
在临床图像数据集训练方面,Mark Cicero等学者将2005至2015年间的35 038例患者的胸部X光片输入GoogleNet,采用卷积神经网络模型对3个图形单元进行训练,并对2 443张X光片的测试集进行网络性能评估,CNN识别灵敏度高达93.6%,进一步证明目前深入的卷积神经网络架构可以用适度大小的医疗数据集进行培训,以在胸部X光片检测和排除常见病理学中达到临床可用性[20]。该实验在以往研究的基础上,证实了深度学习运用到医学图像分析的高灵敏度和临床可用性。
国内对卷积神经网络模型在医学图像分析领域的应用还处在初步的理论探索阶段,试图用实验的方法验证深度学习模型用于单一疾病图像分割的准确性,李雯基于CNN对肝脏肿瘤自动分割,将手工提取特征与自动学习特征的肿瘤分割统计结果进行对比,得出运用CNN自动学习的特征用于肿瘤分割效果更好、准确性更高[21];将深度学习模型与传统算法相比,能很大程度提高辅助诊断系统的准确率、灵敏度和特异度[22]。国内这方面的研究从2015年开始兴起,但由于医院数据不对外公开以及建立的模型识别精度较低等原因,还停留在初步的模型研究以及临床可用性是否可行的阶段。
3.2 深度信念网络模型应用现状
深度信念网络相较于卷积神经网络而言,国内外应用的领域相对较窄,而国内研究起步较晚,集中在近五年,研究成果较少,主要集中于人体的脑部、胸部以及心脏部位。
关于运用深度信念网络对医学图像进行训练,Tom Brosch等人通过使用深度信念网络组成的深度生成模型来降低输入图像的维度,可以实现高达128×128×128分辨率的3D医学图像的训练,以及让深度信念网络学习低维脑体积检测与人口统计学和疾病参数相关的变异模式[23]。
而在特征提取方面,Walter H L Pinaya等人训练了一种称为深度信念网络的深度学习模型,从脑形态测量数据中提取特征,并进一步分析了首例精神病患者的分类表现,通过改进神经形态计量分析,得出深度学习可以提高我们对精神疾病(如精神分裂症)的认识[24]。
关于图像特征学习,卷积分类限制波尔兹曼机器的出现,进行了在CT图像中提供肺组织分类和气道检测的特征学习实验。两种应用表明歧视性学习可以帮助无监督的特征学习者学习针对分类进行优化的过滤器[25]。
在实验数据集测试方面,Sun Wenqing教授等人测试了使用深层学习算法进行肺癌诊断的可行性,并与肺图像数据库联盟数据库进行了比较,还设计了一个具有28个图像特征和支持向量机的方案[26]。
运用深度信念网络,对医学图像进行自动分割,Tuan Anh Ngo与Gustavo Carneiro 等人将深度学习和水平集合结合在一起,用于心脏左心室的心脏电磁共振数据的自动分割,产生一种需要较小训练集的方法,并产生了准确的分割结果。试验中使用MICCAI 2009左心室分段挑战数据库(包含15个训练序列,15个验证和15个测试)的方法,在半自动化问题和最新状态下获得最准确的结果[27]。
总体而言,深度信念网络在临床医学图像上一直有所应用,但并不像卷积神经网络模型一样成为医学图像分析的应用主流,但它从语音识别、图像处理、自然语言处理到图像处理、语音信号处理,再到今天的图像处理反映出深度信念网络应用重点的转移。
3.3 堆叠自动编码器模型应用现状
相较于前两种模型而言,堆叠自动编码器模型应用的范围虽然较小,但一直有学者对该模型在医学图像领域内的应用进行理论研究与实验,到目前为止主要集中于数字病理,显微镜,人体的脑部、心脏、肾脏、肝脏以及腹部等部位。
关于图像特征学习,Hoo-Chang Shin、Matthew R.Orton等人的团队测试了深度学习方法在磁共振医学图像中的器官识别的应用,采用概率贴片法进行多器官检测,从深度学习模型中学习了特征[28]。尽管难以获得正确标记的训练数据集和患者数据集中存在内在异常,但这显示了应用于医学图像的深度学习模型的潜力。
运用堆叠自动编码器,将不同层次特征相结合,构建鲁棒模型,Heung-Il Suk与Dinggang Shen两位学者提出的PET的平均信号强度和基于AD / MCI诊断的深度学习特征表征,就是一个很好的例子。他们认为存在潜在的复杂模式,例如低级特征固有的非线性关系。将潜在信息与原始的低级特征相结合,可以高度诊断准确地构建AD / MCI分类的鲁棒模型。同时他们还使用ADNI数据集进行了实验,证明了该方法提高了诊断精度的特征之间的非线性相关性[29]。接着,该团队继续之前的研究,提出了一种基于深度学习的潜在特征表征与堆叠自动编码器,并提出深度学习可以为神经成像数据分析提供新的思路,提出了这种方法对脑部疾病诊断的适用性[30]。随后,该团队又提出一种结合深度学习和状态空间建模的新颖的方法论体系结构,并将其应用于基于rs-fMRI的轻度认知障碍(MCI)诊断,为了验证提出的方法的有效性,他们对两个不同的数据集进行了实验,并与当时最先进的方法进行了比较。此外,该团队还分析了DAE学习的功能网络,通过解码HMM中的隐藏状态来估计功能连接性,并通过图论理论研究了估计的功能连接性[31]。
关于临床数据集评估方面,Michiel Kallenberg等人评估了三种不同临床数据集上的方法,其结果表明,学习的乳房密度分数与手动乳房密度分数具有非常强烈的正相关关系,而且学习的纹理得分可预测乳腺癌。该模型易于应用并推广到许多其他分割和评分问题[32]。
从堆叠自动编码器的应用现状来看,经历了去噪自动编码器、稀疏自动编码器、卷积自动编码器等发展阶段,通过对训练方式的不断改进,对模型结构的不断改良,医学图像识别的精度得到很大的提升,同时与其他深度学习模型相结合使用的趋势也越来越明显,但训练的时间依然较长,除了追求精度的提高,获取大型医学图像数据集进行训练、减少训练时长依然很重要。
综上所述,从目前公开的数百篇研究论文中可以看出,深度学习已经渗透到医学影像分析的各个方面。这种情况发生的非常迅速,是近年来国内外人工智能领域研究的一个热潮。大量的深度学习模型及其改良模型被应用到医学图像分析任务中,早期的研究集中在预先训练的卷积神经网络上,并将其用于特征提取设备上。事实上,这些经过训练的网络可以直接下载并直接应用到任何医疗图像上。此外,已经存在的基于功能的系统可以简单地扩展出更多的特性。
在过去的数年里,终端训练的卷积神经网络模型已经成为医学成像分析的首选方法,这些深度学习模型通常被整合到现有的管道中,取代传统的方法。大多数人认为深度学习运用到医学图像上的一个主要问题是缺乏大型训练数据集,该问题是深度学习算法应用于医学图像数据分析的一个不可忽视的挑战。然而,这种观点是错误的。现如今,在西方的医院里存放着数以百万计的图片,使用PACS系统对数据集进行训练已经是惯例。此外,越来越多的公共数据集也变得可用。在不久的将来,在相对标准的卷积神经网络架构中可以看到大量的数据集,运用深度学习模型对其训练能取得优异的结果。
与此同时,在获取用于医学图像分析的训练数据方面还发现了另外两个挑战。一个是获得医疗档案。这些档案大多位于医院封闭的专有数据库中,隐私法规可能会阻碍数据的公开和获取。另一个挑战是以系统的方式获取注释,比如WordNet图像数据可用于ImageNet层次结构。
4 总结与展望
本文详细描述了三种典型的深度学习模型的构造原理,并且以时间为轴梳理深度学习三种主要模型的发展历程,然后,对历年来深度学习在医学图像领域应用的情况进行了整理概括。近年来,随着人工智能研究热潮的到来,运用不断深化成熟的深度学习模型对医学图像进行分割、特征提取以及分类已成为常态,医学图像信息的挖掘与开发不再拘泥于之前简单的单一算法,运用卷积神经网络或结合堆叠自动编码器对大量医学图像数据集进行训练后,可实现对单一病理切片90%以上的识别精度。虽然深度学习模型在临床上的应用已经初步实现,大量训练好的数据集经过测试,证明了深度学习模型与之前的决策树等算法相比,识别的精度更高、效果更优,灵敏度更高,但由于在临床实际应用中,多种交叉性病症的区分难度很大,肿瘤等单一疾病的大小形状也复杂多变,因人而异,影像表现差异大,使得图像分割与识别仍存在较大困难。除此之外,深度学习模型本身也存在着一些问题。
4.1 深度学习模型存在的问题
(1)模型结构单一。自Hinton提出深度学习概念以来,涌现出大量改良且具有一定创新性的深度学习模型,但大部分的模型仍停留在由简单模型叠加而成的深度网络上,提出新颖而更行之有效的深度学习模型是我们更加关注的。
(2)训练方式仍需改进。目前,大部分模型采用的是无监督学习方式,离真正意义上的无监督学习还存在一定距离。
(3)训练时间过长。目前需要深度学习模型解决的问题日益复杂,需要模型参数增加,训练时间增长,所以改良算法,提高训练速度,减少训练时间是十分必要的[33]。
(4)对无标记数据添加标签。无标记数据的迅速增加需要更新的自动添加标签技术,依赖人工逐一将其打上标签已经不能适应现代信息社会的发展[34]。
(5)克服对抗样本。在实际工作中,实际样本的轻微改动都有可能会让分类器将它们划分到错误的类别中,但目前一些常见的正则化方法并不能很好的解决这一问题[33]。
4.2 深度学习前景展望
(1)范围更广泛的跨组织合作。尽管国内外围绕深度学习用于医学图像分析的研究团队和研究机构众多,但是,都是基于自身可获得的患者医学图像数据集开展工作的,计算机领域的专家学者设计的模型需要大量可获得的训练集进行测试,但这些患者数据本身有特殊性,较难获取。所以,医院数据提供者、供应商和机器学习专家之间的合作至关重要,这种协作将解决机器学习研究人员无法获得的数据问题。
(2)需要利用大的图像数据。深度学习自学习过程依赖于非常大的数据集,然而,与其他成像领域相比,对医学图像数据进行注释,将其标签化是不容易的。在现实世界中,可以轻易地将现实世界中的男人和女人进行分辨与划分,然而,将医学数据打上标签,对其概念化是昂贵、繁琐和费时的,因此将共享数据资源提供给不同的医疗服务者是十分有必要的。
(3)深度学习方法的进步。大多数深度学习方法都是在监督的基础上进行的,但是由此需要的标签好的医学数据尤其是图像数据并不总是能轻易获得。例如,在罕见疾病或有资历的专家不在场的情况下,为了克服未标签过的大数据不可用的问题,需要深度学习模型从监督转向无人监督或半监督,又不影响医疗系统的精确性,这是非常困难的。尽管目前众多研究在克服这一阻碍,但还没有提供完整的解决方案,这仍是要努力攻克的一大难题。
深度学习运用到医学图像分析领域在疾病的高精度智能识别、分析及诊断方面具有极大地现实意义和社会价值,已成为近年来的研究热点,而计算机辅助诊断研究是结合临床医学、图像学和计算机科学的一门新兴学科,当前针对医学图像分析和智能诊断的研究正在起步,存在着众多值得挖掘的内容。围绕医学影像数据管理,借助深度学习模型和PACS(影像归档和通信系统)对医学影像进行自动描述和标注,构建医学影像智能数据库,实现当未标注的医学影像输入医疗辅助诊断系统后,可自动生成文字形式的病情描述和诊断结果。可协助医生诊断,削减其读片的时间,提高其判定的准确率和工作效率,降低临床漏检率。
