基于词向量的国际业务实时推理模型*
2019-05-27张轼坤高列宁周云康
张轼坤,沈 峰,高列宁,周云康
(1.交通银行软件开发中心(上海),上海 201201; 2.武汉理工大学 经济学院,湖北 武汉 430070)
0 引言
随着“一带一路”战略的发展,我国加快了对外开放的幅度,越来越多的企业加入了全球化国际化“朋友圈”。随之而来是国际贸易业务量的增长,而银行作为企业的国际贸易服务机构,通过加入环球同业银行金融电讯协会(Society for Worldwide Interbank Financial Telecommunications,SWIFT),提供了国际结算、国际清算、担保、贸易融资、国际汇款等专业金融服务。相对于以发送SWIFT报文为主的进口业务,出口业务流程是从接受SWIFT报文开始,由国际业务专业人员逐字检查各类SWIFT报文域信息,并结合各类国际惯例人工分析SWIFT报文内容,审核无误后再进行下一步业务操作。以上国际业务操作环节中,存在着人工审核报文、人工审单、人工录入、人工反洗钱等一系列亟待解决的服务效率低下问题,其中SWIFT报文分析是各环节的第一个重要步骤。
目前国内银行的SWIFT报文业务处理系统只负责报文域的解析,即直接将报文域信息映射到业务系统页面,报文内容的分析工作还是由人工处理。国际业务专业人员须根据当前业务产品类型(如国际结算的信用证、托收、保函业务)依据国际惯例处理业务,包括英文版UCP600(跟单信用证统一惯例)、ISBP745(国际标准银行实务)、URC522(跟单托收统一规则)、URR725(银行间偿付统一惯例)、URDG758(见索即付保函统一规则)、ISP98(国际备用信用证惯例)等。另外,国际商会每年对全球提交的各类案例发布两次官方意见,也是国际业务专业人员处理业务、与同业交涉业务时参考的重要依据,目前国际商会正式出版了1995年以来的官方意见(ICC Opinions),共约30万字英文。如何从复杂繁多的国际惯例中快速定位关键信息,如何结合当前业务实际场景快速整理摘要,将它们整合成有价值的参考信息,是提高国际业务SWIFT报文处理效率的关键。
交通银行于2018年5月31日决定正式启动新的集团信息系统智慧化转型工程,即“新531”工程。通过整体布局、系统规划我行的智慧化转型方向,加快创新发展。为适应全行智慧化发展战略,提升国际业务服务和管理能力,本研究针对国际业务领域专业化特点,利用机器学习方法,通过对SWIFT报文语料的统计和计算,得到语料信息的TF-IDF值,结合GLoVe算法实现SWIFT报文业务领域特征的词向量提取;使用seq2seq模型结合attention机制实现业务摘要的自动组装;利用Google的word2vec模型对国际惯例语料进行学习,将词语映射到k维向量空间进行向量运算,通过向量空间上的相似度保留词汇语义上的相关度;最终结合报文解析、业务清分、规则库等业务系统功能构建国际业务实时推理模型,并试验验证实时推理模型在实际业务SWIFT报文处理的有效性。
1 基于词向量的国际业务实时推理模型构建方法
1.1 词向量模型
本研究通过在Python平台上使用Google开源工具word2vec[1]产生词向量(distributed representation),其基本思想是通过训练将每个词映射成K维实数向量(K一般为模型中的超参数),通过词之间的距离(比如cosine相似度、欧氏距离[2]等)来判断它们之间的语义相似度,word2vec采用一个三层的神经网络(包括输入层、隐层、输出层),选用skip-gram模型[3]训练数据,如图1所示[4],其核心思想是根据中心词来预测周围的词。

图1 skip-gram模型
以一条UCP600国际惯例为例,假设中心词是tenor,窗口长度为2,则根据tenor预测左边两个词和右边两个词。这时,tenor作为神经网络的input,预测的词作为label。图2中窗口长度为2,中心词从左往右移动,遍历所有文本。每一次中心词的移动,最多会产生4对训练样本(input,label)。
word2vec考虑到了当前词的上下文信息,由此学习到的词向量包含了丰富的语义和语法关系。本研究将UCP600、ISBP745、URC522、URR725、URDG758、ISP98共计5万条惯例信息作为word2vec的训练数据集Data_icp。训练模型选用skip-gram,得到模型BITS2vec。
1.2 基于GLoVe词向量+seq2seq模型+attention机制的自动摘要构建模型
Global Vectors for Word Representation[5](简称GLoVe)是斯坦福大学NLP组2014年提出的一种非监督学习算法[6],通过对语料库的“单词-单词”共现矩阵[7]进行聚合,得到的表示形式展示了单词向量空间的线性结构。本研究通过使用GLoVe算法工具初始化SWIFT报文语料的共现矩阵,并训练得到SWIFT报文GLoVe词向量。
seq2seq模型[8]本质上是一种encoder-decoder框架[9],Encoder通过学习输入将其编码成一个固定大小的语义向量S,继而将S传给Decoder,Decoder再通过对语义向量S的学习来进行输出。但
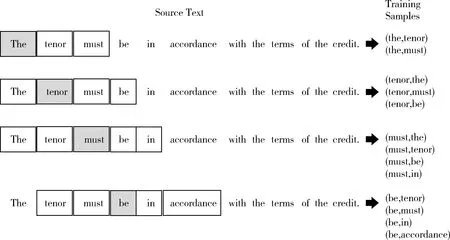
图2 word2vec训练样本产生过程
是因为语义向量S是固定长度,Encoder无法将整个输入序列信息压缩进去,会导致语义向量无法完全表示整个序列的信息,使得Decoder在一开始就没有获得序列足够信息,解码质量要打一定折扣。为了解决该问题,attention机制[10]被提出,该机制在产生输出时,会产生一个关注度权重C来表示接下来输出时需要重点关注输入序列的哪些部分,然后根据关注的区域来产生下一个输出,如此反复。
如图3所示,本研究通过将SWIFT报文GLoVe词向量作为Encoder的输入序列,随后加载attention机制,计算Encoder中每个RNN(Recurrent Neural Netword,循环神经网络[11])单元的输出同当前单元Decoder端的输出的余弦相似度[12],再将Encoder的RNN单元输出同各自余弦相似度进行加权向量和,得到当前RNN关注度C,最终再输入到Decoder中训练产生SWIFT报文语料摘要。

图3 基于GLoVe词向量+seq2seq模型+attention机制的自动摘要构建模型
1.3 业务规则引擎
业务规则引擎[13]是一个软件模块,它基于规则编程,将规则运用于推理数据,主要功能是接受数据输入、解释业务规则,并根据业务规则做出相应的决策。本研究通过将我行国际业务产品的业务需求和国际惯例整理成XML格式业务规则,可根据接受到的业务关键字自动匹配不同的业务产品所适用的业务规则,并最终提供当前SWIFT报文的业务规则参考信息,采用业务规则引擎的基本结构如图4所示。

图4 业务规则引擎基本结构
本研究共计整理了我行49大类国际业务产品业务规则和6类国际惯例规则,规则数据采用DB2数据库的形式保存,业务规则模块采用XML格式的方式编写,因XML方式技术较成熟,本文不再赘述。但对规则编写形式做简要描述,例如,原始业务需求为:如果当前SWIFT报文所对应业务存在一张汇票多笔提单的情况,需要根据信用证要求的船公司数量和货物港口地理位置情况,计算汇票付款期限,并提供相关日期计算国际惯例参考信息。需要转化为规则编写形式,如图5所示。

图5 规则编写形式
1.4 基于词向量的国际业务实时推理模型
国际业务词向量是SWIFT报文分析的重要工具。不同的报文类型、不同的业务产品适用的惯例也不相同。通过提取SWIFT报文语料词汇分布特点,结合相关算法,可计算得到当前SWIFT报文关键信息,将关键信息输入到相关国际业务词向量库可获取当前业务国际惯例词向量。鉴于此,本研究采用如图6所示的基于词向量的国际业务实时推理模型提供SWIFT报文实时自动摘要和关联国际惯例参考功能。
首先,整理UCP600(跟单信用证统一惯例)、ISBP745(国际标准银行实务)、URC522(跟单托收统一规则)、URR725(银行间偿付统一惯例)、URDG758(见索即付保函统一规则)、ISP98(国际备用信用证惯例)、ICC Opinions(国际商会官方意见)数据集Data_icp,设置word2vec模型参数(包括向量维数size、上下文窗口大小window、是否Cbow模型isCbow),训练成国际惯例专业词向量库模型BITS2vec,并使用GloVe算法训练历史SWIFT报文语料Data_swift_history得到SWIFT报文GLoVe词向量。运用GLoVe词向量加载seq2seq模型和attention机制构建自动摘要模型Auto_summary。词向量库模型BITS2vec和自动摘要模型Auto_summary统一存放在模型库路径以便后续调用。
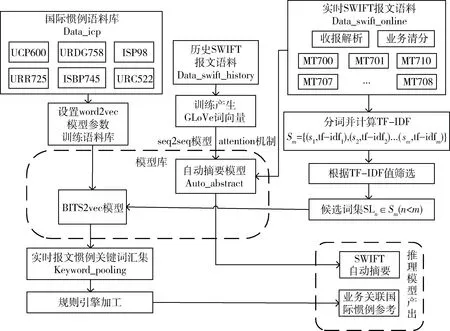
图6 基于词向量的国际业务实时推理模型
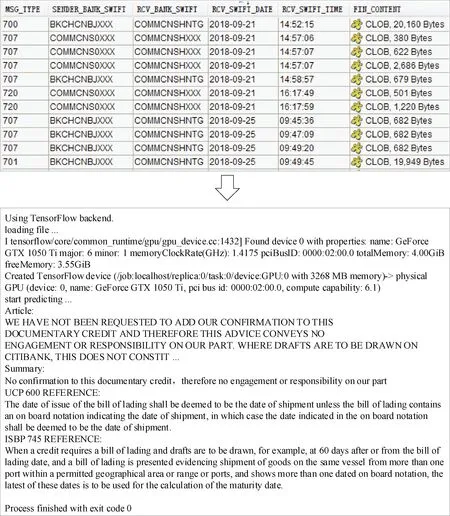
然后,对实时SWIFT报文语料Data_swift_online根据业务类型进行清分,根据报文类型进行解析,并将处理后的语料进行分词,再输入到自动摘要模型Auto_summary,运行摘要模型产出SWIFT自动摘要。同时,推理模型会计算词汇的TF-IDF值[14],获得词集S={(s1,tf-idf1),(s2,tf-idf2) …(sm,tf-idfm)}。通过设定TF-IDF的阈值,筛选得到候选词集SLn={(s1,tf-idf1),(s2,tf-idf2) …(sm,tf-idfn)} (n 国际惯例特征向量可将业务特征映射到高维空间,对惯例表达的有效性,主要体现在语义相近的惯例词汇,其空间距离小。如ship、carrier、master、charterer等运输单据相关的词汇具有较强的语义相似性,其空间距离应该小,相似度应该高,因此可以用于识别国际惯例关联词汇。对采集的5万条国际惯例数据进行处理,去掉停用词汇,设置word2vec模型参数(size:100;上下文窗口大小window:5;是否Cbow模型isCbow:false),运行模型获得国际惯例专业词向量库BITS2vec,每个惯例词汇映射到100维的向量空间,采用基于Python的数据可视化工具t-sne进行降维可视化[15],如图7所示,距离越近表示语义越近。 图7(b)为图7(a)的局部放大显示,可见shipment、order、transport、document、insurance等运输相关惯例词汇在语义上有一定的关联性,在向量空间上相对距离较近,说明了词向量对语义聚合效果比较好。同时可以试验基于BITS2vec输出的100维词向量取词效果,利用similarity函数[16]获取惯例最相似的5个词汇,结果如表1所示。 表1 相似词和相似度示例(top 5) 表1为惯例词汇shipment和payment的排名前5的相似词汇和对应的相似度。以词汇payment为例,利用BITS2vec获得的相似词charges、reimbursement、draft在语义上有较强的关联,为后续的规则库加工提供了可泛化的国际惯例语义关键词集Keyword_pooling。 为了验证推理模型的有效性,本研究选取3万笔历史SWIFT报文语料,并使用GloVe算法训练SWIFT报文GLoVe词向量,加载seq2seq模型和attention机制构建自动摘要模型Auto_summary。 在测试环境将实时接收到的MT700、MT707、MT710等SWIFT报文语料Data_swift_online进行报文清分,解析关键语料信息存放在FIN_CONTENT,并运行推理模型。 推理模型会计算SWIFT报文词汇的TF-IDF值,获得当前SWIFT报文词集S={(s1,tf-idf1),(s2,tf-idf2) …(sm,tf-idfm)}。设定TF-IDF的阈值为0.4,筛选得到候选词集SLn,将候选词集SLn输入到BITS2vec模型得到实时报文惯例关键词汇集Keyword_pooling,继续输入到业务规则引擎库加工,得到本笔业务关联国际惯例参考信息,并结合自动摘要最终得到规整的推理分析产出,输出结果如图8所示。 图8 运行国际业务实时推理模型的产出 从图8可以看出,推理模型抽取了当前SWIFT报文语料的关键信息组成了自动摘要:No confirmation to this documentary credit,therefore no engagement or responsibility on our part(表明当前信用证没有保兑确认,因此无付款责任),从而加快了业务人员对SWIFT报文信息的理解速度。同时,推理模型结合当前SWIFT报文的关键词汇集Keyword_pooling找到了UCP600(跟单信用证统一惯例)、ISBP745(国际标准银行实务)中关于“装运日”(date of shipment)和“汇票到期日”(maturity date)的惯例信息作为业务参考信息,一定程度上方便了银行国际业务专业人员后续审单环节业务处理,提高了业务人员SWIFT报文分析效率。 本研究主要针对国际惯例词汇的特征向量表示,提出基于词向量的国际业务实时推理模型,推理模型融合了BITS2vec词向量模型的语义优势,将国际惯例特征映射到高维空间,实现了惯例词汇在语义空间和向量空间的有效表示。通过GLoVe算法产生SWIFT报文词向量,使用seq2seq模型加载attention机制学习产出报文摘要。利用TF-IDF值在词汇重要程度的度量作用,实时计算获得SWIFT报文语料候选词集,注入到BITS2vec词向量模型,运行规则引擎后生成国际惯例参考信息。通过实验和结果分析,验证了推理模型的可行性和有效性。在下一步研究工作中,将进一步拓展训练数据集,加入SWIFT官方国际业务行业分析报告等语料,训练更广域的语义表示,进一步提升推理模型的国际业务领域可用性。2 试验结果及分析
2.1 词向量模型试验

2.2 推理模型试验
3 结论
