基于深度置信网络的Android恶意软件检测*
2019-05-27欧阳立芦天亮
欧阳立,芦天亮
(中国人民公安大学 信息技术与网络安全学院,北京 100076)
0 引言
最近十年,互联网尤其是移动互联网出现了井喷式发展,智能移动设备的数量急速增长,移动软件得到了广泛的推广和应用。目前已经有多家科技公司推出了自己为移动智能设备开发的操作系统,而Android在各种移动智能设备操作系统中占据了最大份额,是目前用户量最大且增长速度最快的移动智能设备操作系统[1]。Android操作系统是一种基于Linux的操作系统,由Google公司和开放手机联盟领导及开发,其源代码开源,相比于其他智能终端上的操作系统,具有完全的开源性,并且Android应用市场复杂多样,使得Android恶意软件的数量快速增长,许多Android恶意软件带有恶意代码,诱导用户安装木马,下载大量新的恶意应用,消耗手机流量,发送扣费短信,造成了严重的安全威胁,其中有些本身不携带恶意代码的Android应用软件,通过申请过多与不当的权限来获得相关信息,实现其搜集用户隐私的目的。
Android恶意软件的检测技术主要分为静态检测和动态检测[2-3]。静态检测是指在不执行应用软件的情况下,判断应用软件中是否含有恶意代码,静态检测通过对应用软件进行反编译等方法,快速提取应用软件的静态特征并进行检测,缺点是检测模式的扩展性差;动态检测是指在Android应用软件执行时识别Android恶意代码,能够全面监控应用行为,准确率较高,缺点是运行时占用资源较多,效率较低,并且难以检测出从未出现过的Android应用软件。由于上述问题的存在,机器学习技术开始在Android恶意软件检测领域得到应用,机器学习技术区别于传统的分析方法,具有预测能力强、扩展性强的特点,避免了传统分析方法效率低、扩展性差等问题[4-5]。
深度学习(Deep Learning,DL)区别于传统机器学习方法,通过深层非线性网络结构,组合低层具体特征来形成高层抽象特征表示,进而发现输入数据分布式特征表示,具有从样本集中学习数据的本质特征的强大能力。深度置信网络(Deep Belief Network,DBN)作为深度学习的深度生成模型之一,得到了广泛的应用。
本文结合Android应用软件特征,采用基于深度置信网络的深度学习模型进行特征分析:首先结合Android应用软件来获取全面的应用软件特征;然后利用深度置信网络挖掘高层抽象特征,通过基于深度置信网络的深度学习模型对Android恶意软件进行检测。
1 相关工作
1.1 使用静态和动态分析检测
最初,Android恶意软件检测是基于静态检测,通过反汇编来实现静态地检测Android应用软件。ENCK W等[6]通过反汇编Android应用软件,分析其源代码来发现代码漏洞,YANG W等[7]提出AppContext静态检测框架,AppContext根据触发安全敏感行为的上下文对应用程序进行分类。动态检测技术通过在沙箱或者真实环境下应用软件来获得信息从而进行检测。DroidScope[8]可以在受保护的运行环境下动态检测应用软件。DINI G等[9]提出动态检测框架MADAM,能够在Android内核层和用户层监控应用软件。
1.2 使用机器学习检测
对于静态检测和动态检测而言,只能人工地生成和更新Android恶意软件检测模式,这促使机器学习开始应用于Android恶意软件检测问题。DroidAPIMiner[5]通过机器学习算法来分析API级别的Android应用特征。ZHAO K等[10]提出了基于特征频率的特征选择算法。在传统的机器学习算法中,SVM算法被常用于基于特征选择的Android恶意软件检测[11-12]。由于传统的机器学习算法通常都是浅层架构,无法有效地通过关联特征对Android软件进行高层次的表征,因此,研究人员尝试通过深度学习模型进行Android恶意软件检测[13]。
2 特征提取
Android应用软件的特征主要分为静态特征和动态特征,静态特征是指在不执行应用软件的情况下,使用反编译等方式提取待分析软件的特征,主要包括权限信息和调用的敏感API信息;动态特征是指Android应用软件执行时获取的反映应用软件行为的特征。
相比于动态分析,静态分析所需的系统资源小,速度快,适合大规模的特征提取,因此本文采用静态分析的方法提取特征,并基于静态特征构造特征集,如图1所示。提取的特征包括Android应用软件的所请求的权限和敏感API。

图1 Android应用软件的特征提取
为了得到Android应用软件特征,对其安装文件(.apk文件)进行解压,获得两个重要的文件,分别为AndroidManifest.xml和classes.dex文件。AndroidManifest.xml文件是系统清单文件,定义了应用软件的权限、组件等信息,对AndroidManifest.xml文件进行解析,得到Android应用软件申请的权限,例如,android.permission.camera是Android应用软件申请使用照相机权限。通过解析AndroidManifest.xml文件,得到了Android应用软件总共120个权限。通过baksmali工具对classes.dex文件进行反编译解析,可以得知哪些API接口被调用,例如,chmod是用于改变用户权限的敏感API。通过解析classes.dex文件,得到了总共59个敏感API。
通过上述过程,构建了总共有179个特征的Android应用软件特征集,每个Android应用软件都对应着一个179维的特征向量V={0,1,1,0,…},特征向量每一个维度的值都是二值的,当该应用软件包含该特征时,则该维度为1,否则,该维度值为0。
3 Android恶意软件检测算法
本文提出了基于深度置信网络(Deep Belief Network,DBN)的Android恶意软件检测算法,提取了权限和敏感API等179个特征,使用深度置信网络来构建深度学习模型,并对Android应用软件进行检测。采用权限类特征和API类特征可以更为全面地描述Android应用,采用DBN网络学习特征的深层结构,可以更好地表征和检测Android恶意软件。Android恶意软件检测框架如图2所示。
3.1 基于深度置信网络的深度学习模型
在目前的深度学习理论中,深度置信网络(Deep Belief Network,DBN)是应用较为广泛的一类深度学习框架。深度置信网络分为两部分,底层部分由多层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)单元堆叠而成,上层部分为有监督的网络层,用于微调整体架构。相较于其他深度学习框架(循环神经网络、卷积神经网络等),DBN算法的优势在于,针对Android应用软件的特征向量的学习速度更快,性能更好,因此采用基于DBN的深度学习框架对Android恶意软件进行检测[14-18]。
DBN分为两部分,一部分由若干RBM堆叠而成,一部分为有监督的后向传播(Back Propagation,BP)网络,结构如图3所示。在图3中,V表示可视层的节点值向量,H表示隐藏层的节点值向量,在堆叠的RBM中,除了最底层和最顶层,每一层的RBM中的隐藏层即是上一层RBM的可视层。W为权值矩阵,用于表示可视层和隐藏层之间的映射关系。两层相邻的RBM之间采用贪心算法,使得权值矩阵W在初始化时达到局部最优。V0为底层RBM的初始特征向量,在向上的无监督转化过程中,从具体的不易分类的特征向量转化为抽象的易于分类的组合特征向量。RBM网络通过调整自身层内的权值矩阵Wi,使得该层特征向量的映射达到局部最优。而BP网络通过有监督地训练,微调DBN网络。由于DBN网络的主要工作在于训练特征向量的权重表示,仍然需要通过分类算法对Android应用软件进行分类,本文采用支持向量机(Support Vector Machine,SVM)算法作为模型的分类算法。
由图3可知,深度学习模型的构建由无监督的预训练阶段和有监督的后向传播阶段两个阶段组成。在预训练阶段,若干RBM分层堆叠,组成DBN网络的基本框架,两层相邻的RBM之间采用贪心算法,使得权值矩阵W在初始化时达到局部最优,通过对比散度(Contrastive Divergence,CD)算法训练每一层的RBM,在后向传播阶段,BP模块以有监督的方式用标记的样本对DBN网络进行微调,最后,分类模块对样本进行分类,结构如图4所示。

图4 深度学习模型的构建
3.2 限制玻尔兹曼机
限制玻尔兹曼机(RBM)由HINTON等提出,由可视单元(visible unit)和隐藏单元(hidden unit)构成,若干可视单元构成可视层,若干隐藏单元构成隐藏层,每个可视单元对应可视层的节点值向量中的一维,每个隐藏单元对应隐藏层的节点值向量中的一维,可视层的节点值向量和隐藏层的节点值向量都是二元多维向量,每一维的节点值取0或1,在可视层和隐藏层之间,可视单元与隐藏单元相互连接,可视层和隐藏层内部无单元连接。
RBM本质上是一个概率生成模型,其训练过程的核心在于求出一个最符合训练样本的概率分布,而由于概率分布的决定性因素在于权值矩阵W,所以RBM的训练目的就是寻找最佳权值矩阵W。假设在RBM中,可视层包括N个二值可视单元,隐藏层包括M个二值隐藏单元,设vi表示可视层中第i个可视单元的值,hj表示隐藏层中第j个隐藏单元的值。给定状态(V,H)下的能量定义如式(1)所示,wij表示可视层和隐藏层之间的映射关系的权值,为了更好地拟合实际函数,在能量的定义公式中加入偏置,bi表示可视单元的偏置,cj表示隐藏单元的偏置。
(1)
RBM处于状态(V,H)的概率为
(2)
由于同一可视层或隐藏层中的单元无连接,由可视层的节点值可计算得隐藏层的节点值:
(3)
RBM是对称网络,所以可以由已知的隐藏层的节点值计算得到可视节点的节点值:
(4)
式(3)和式(4)中σ(x)=1/(1+exp (-x))。
由于对比散度算法(Contrastive Divergence,CD)精度高,计算速度快,本文采用CD学习算法,用于计算权值矩阵W。CD算法利用两个概率分布的“差异性”来迭代更新权值,最终达到收敛。基于CD算法的RBM网络自训练过程如算法1。
算法1 基于CD算法的RBM网络自训练过程
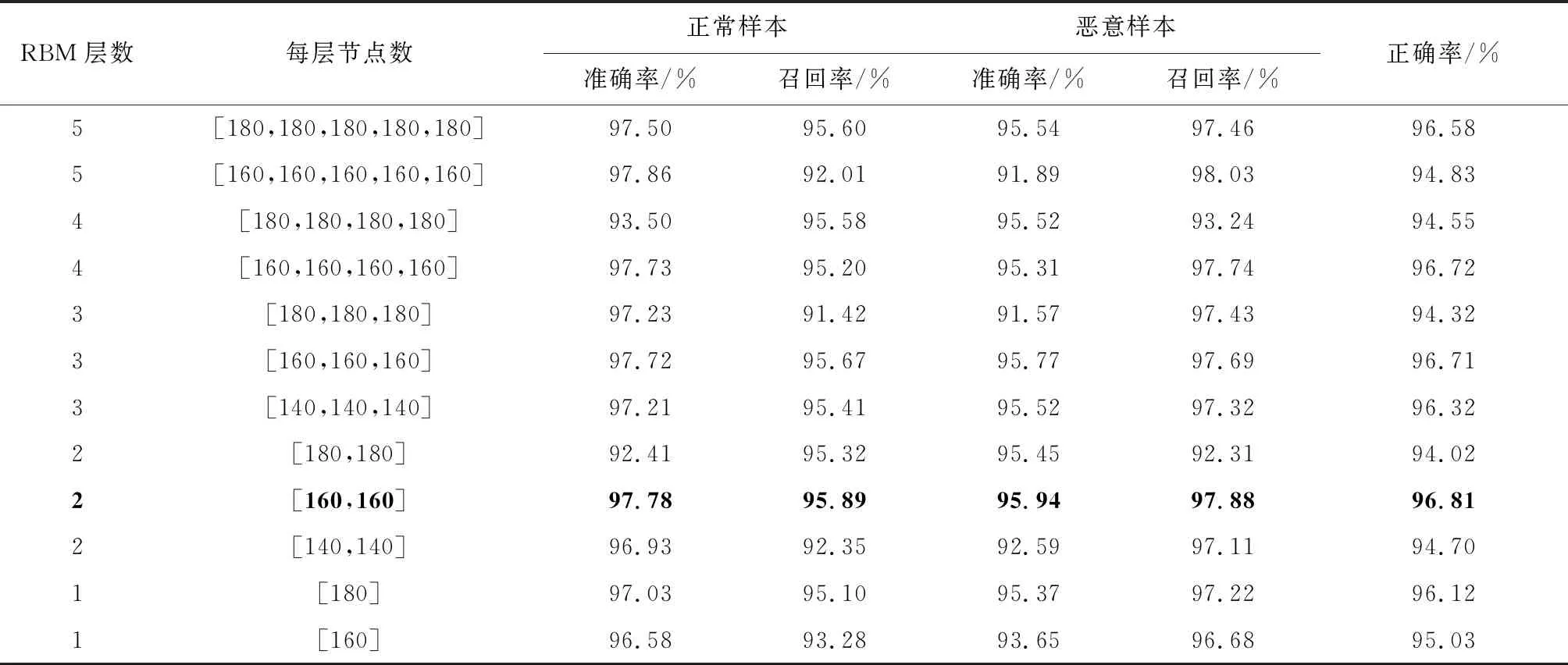
对于样本量为N的训练集中的一个特征向量xn(0≤n (1)n=0 (2)将xn传递到可视层V0,根据式(3)计算隐藏层H0: P(h0j=1|V0)=σ(WjV0) (3)根据式(4)计算可视层得到V1: P(v1i=1|H0)=σ(WTiH0) (4)根据式(3)计算隐藏层H1: (5)P(h1j=1|V1)=σ(WjV1) (6)对于所有节点j,更新权值: Wj←Wj+λ(P(h0j=1|V0)VT0)-P(h1j=1|V1)VT1 若n=N-1,结束,否则n=n+1,转步骤(2)。 后向传播(Back Propagation,BP)网络通过有监督的学习方式,与已标签的应用软件进行结果对比,微调整个DBN网络。本文采用的是BP网络训练方法,节点求值函数选取Sigmod函数。BP网络训练过程如算法2。 算法2 BP网络的训练过程 (1)随机初始化BP网络的参数,读取RBM网络的权值矩阵W,训练步长初始化为N。 (2)前向计算每一层的单位节点值,对第l层的j单位节点,节点值为ylj(n)=∑Wij(n)yl-1i(n),若神经元j在输出层(l=L),令yLj(n)=οj(n),误差ej(n)=dj(n)-οj(n),dj为已标签的结果。 (3)计算δ,将δ后向传递,向下依次微调权值。 对于输出单元: δlj(n)=ej(n)οj(n)[1-οj(n)] 对于隐藏单元: δlj(n)=ylj(n)[1-ylj(n)]∑δl+1k(n)Wl+1kj(n) (4)微调权值 Wlji(n+1)=Wlji(n)+ηδljyl-1i(n) Wlji(n+1)=Wlji(n)+ηδljyl-1i(n) 其中,η为学习速率。 (5)如果n=N,结束;否则n=n+1,转步骤(2) DBN网络的主要功能是训练特征向量的权重表示,在训练好DBN网络之后,与分类模块相结合,共同构成了基于DBN网络的Android应用软件分类模型。 本文分类模块的分类算法采用支持向量机(Support Vector Machine,SVM)算法。SVM算法包括两个阶段:训练和测试。给定训练阶段中的正常样本和恶意样本,SVM找到超平面,该超平面由法线向量ω和垂直距离b指定,该原点将具有最大边距γ的两个类别分开,其中Positive为正常样本,Negative为恶意样本,如图5所示。 图5 SVM算法 在测试阶段,SVM预测模型会将测试集分为两类,线性SVM的决策函数f如式(5)所示 f(x)=〈ω,x〉+b (5) x表示样本集中的代表样本的特征向量,当f(x)>0,将样本判定为正常样本,否则,将样本判断为恶意样本。 本文在Google Play Store共下载得到10 000个 应用软件作为正常样本集。恶意样本集样本数3 938 个,由两部分组成,一部分来自Genome Project(http://www.malgenomeproject.org/),计1 260个,一部分来自VirusTotal(https://www.virustotal.com/),计2 678个,两部分共计3 938个恶意样本。从样本集中随机选取700个正常样本和700个恶意样本,然后将其彻底混合,作为一组数据,总共选取5组数据实验时,从5组数据中选取2组分别作为训练集和测试集。 为了得到基于DBN的深度学习网络的最优参数(RBM层数、每层RBM的节点个数、CD算法的迭代次数等),通过实验来进行确定。在实验中,采用准确率(Precision)、召回率(Recall)和正确率(Accuracy)三个指标来评价对Android恶意软件检测的结果。表1展示了RBM层数和每层节点数对于检测效果的影响。 表1 不同深度学习网络结构的检测结果 从表1中可以看出,当RBM层数为2层、每层节点数为160时正确率最高,达到了96.81%,并且在不同深度学习模型结构中,正确率都超过了94%。 将基于DBN的深度学习模型与传统的机器学习模型得到的检测结果进行比较,结果如表2所示。 表2 不同机器学习算法检测结果 对于大多数传统的机器学习算法(Naïve Bayes、Logistic Regression、KNN、SVM),测试了sigmoid kernel、linear kernel等多种常见的核函数,并选取检测结果最佳的数据作为传统机器学习算法的实验结果。从表2可以看出,在相同测试集下,DBN算法的正确率比SVM高出3.35%,比Naïve Bayes高出11.83%,比KNN高出12.26%,比Logistic Regression高出14.38%, 由此可见,基于DBN的深度学习模型明显优于传统的神经网络模型和机器学习模型,并且由表1可知,即使基于DBN的深度学习模型没有采用最合适的隐层结构,其最低正确率也高于94%。 本文通过提取Android应用软件特征,使用深度置信网络(DBN)对提取的Android应用软件特征进行学习,从而对恶意软件进行表征,设计实现了一种基于深度置信网络的Android恶意软件检测方法。首先,对应用软件进行特征提取,并构建特征向量,本文共提取179个高频静态特征来构建特征向量;然后,从样本集中选择样本构建训练集对DBN网络进行训练;最终通过基于DBN网络的检测模型对Android恶意软件进行检测。从实验结果可以看出,基于DBN网络的深度学习模型明显优于传统的神经网络模型和机器学习模型。 本文研究仍然存在一些不足,需要在以后的工作中进行改进和完善。首先,恶意应用样本量相对较少,采用更大的样本量可以得到更准确的结果;其次,本文提取特征为静态特征,若在特征集中加入动态特征,将会使得结果更为全面准确。3.3 BP网络
3.4 分类算法

4 实验结果及分析
4.1 数据集
4.2 深度学习网络的表现

5 结论
