DBSCAN聚类算法的参数配置方法研究
2019-05-17宋金玉郭一平
宋金玉,郭一平,王 斌
(1.解放军陆军工程大学 指挥控制工程学院,江苏 南京 210007;2.解放军陆军工程大学 教学考试中心,江苏 镇江 212000)
0 引 言
全球知名咨询公司麦肯锡称:“数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。”但现实生活中,人们常常抱怨“数据丰富,信息贫乏”。这是因为在海量的数据中,存在大量无用甚至错误的“脏数据”,根据“垃圾进,垃圾出(garbage in,garbage out)”[1]原理,低质量的数据难以提供有价值的信息,反而会带来负面影响,会因各种数据/信息质量(data/information quality,DQ/IQ)问题给用户带来麻烦甚至损失[2-4]。
数据质量低的一个方面就是数据异常,即数据集中出现明显区别于其他正常数据的数据。由于数据异常往往使数据表现为孤立点[5],也称之为离群点或异常点。这些数据可能是需要消除的错误数据,也可能是重要的报警点,预示出现问题或者发生了重要变化。
离群点检测(又称为异常检测)是找出其行为不同于预期对象的过程,通过检测并去除数据源中的这些孤立点可达到消除数据异常的目的,从而提高数据源的数据质量。
数据挖掘技术中的聚类分析工具,可以用于离群点(噪声)检测。聚类分析采用某种算法将大的数据集合根据数据相似性把所有数据划分成簇,即采用相似度进行归类,相似度较高的归为一类,明显不属于任何一类的单个(或少量)数据集可认为是异常数据。聚类算法有很多种,其中基于密度的方法(density-based method)考虑数据集中的每个对象,根据一定距离内数据密度来划分簇数,数据比较密集的可以被认为一个簇,而比较稀疏的区域则被认为是噪声。
有代表性的基于密度的全局邻域(density-based spatial clustering of applications with noise,DBSCAN)算法将数据空间中的数据抽象为数据点,通过计算点之间距离和点密度来进行聚类,可将噪声或离群点从簇内分离。在DBSCAN算法使用中,需设置邻域阈值(Eps)和点数阈值(Minpts)两个参数,根据参数将有一定密度的区域划分为簇,且聚类结果对参数值敏感。
目前已有许多文献对Eps和Minpts参数值的设定方法进行了研究。对于密度均匀的数据,文献[6]通过分析数据的统计特性来自适应确定Eps和Minpts。对于不同密度数据的聚类,文献[7]采用自适应的Eps参数;文献[8]根据基于网络与基于密度的聚类算法间的等效规则来计算不同密度的密度阈值;文献[9]提出基于数据分区的PDBSCAN算法;文献[10]提出基于网格分区来确定Eps的方法。
文中根据数据的统计特性,利用图表的可视化结果,提出了一种确定DBSCAN算法参数的方法。
1 DBSCAN聚类算法的分析与实现
由于数据集中相似重复记录的个数是不确定的,因此,要求聚类算法应具有能够发现任意形状簇的能力。DBSCAN算法[11]可将具有足够高密度的区域划分为一个簇,簇数事先是不确定的,点的邻域的形状取决于两点间的距离函数dist(p,q),对象间的距离是根据对象的属性值计算得来的。因此,聚类结果取决于选择哪些属性变量、采用何种距离度量以及如何计算度量的属性。
下面介绍用来描述算法的相关概念[12]。
(1)距离。
对象间的距离采用求数据相异度的方法。假设X1,X2代表数据集中的两个数据对象,n是参与计算的数据对象的属性个数,每个数据对象用n维向量(Xi1,Xi2,…,Xin)表示,X1k,X2k分别为两个数据点的第k维坐标。d12是两点间距离,有多种形式的距离度量可采用。如欧几里德函数,则d12可由如下公式计算:
(1)
其中,d12就表示这两个数据对象的相异度。当两个对象越相似或接近时,d12值越接近0,而当两个对象越不相同或相距较远时,d12值越大。还可以根据每个属性的重要性为其赋一个权重。
(2)邻域、密度、核心点、边界点。
数据集中任意一点的邻域记为NEps(p),是数据集中与p点的距离小于给定Eps的点的集合。
NEps(p)={q∈D‖dist(p,q)≤Eps}
(2)
邻域中点的个数称为该点的密度,若其大于或等于给定的最小值MinPts,则称点p为核心点,否则称为边界点。
(3)直接密度可达、密度可达、密度相连。
数据集中任意两点p,q,如果q∈NEps(p),且|NEps(p)|≥MinPts,则称点q是从点p关于Eps和MinPts直接密度可达的。
如果p,q两点间存在一个点的序列p1,p2,…,pn,且p1=p,pn=q,pi+1是从pi直接密度可达的,则称点q是从点p关于Eps和MinPts密度可达的。
如果存在一个点o,q和p都是从点o关于Eps和MinPts密度可达的,则称点q是从点p关于Eps和MinPts密度相连的。
(4)簇。
数据集中基于密度的簇是基于密度可达的最大密度相连的点的集合。簇中的任意两点是关于Eps和MinPts密度相连的。
给定参数Eps和MinPts,DBSCAN算法的实现就是生成相应的簇。DBSCAN算法从任意点p开始,检索所有从点p关于Eps和MinPts密度可达的点。如果p是核心点,就生成一个关于Eps和MinPts的簇;如果p是边界点,且没有从p密度可达的点,算法就去处理数据集中的下一个点。算法实现的流程参见图1。
相比其他聚类算法,例如基于层次的算法等,DBSCAN算法的优点是可以发现数据集中任意形状的簇,它的聚类速度比较快,聚类能力也很强。但必须为每个簇指定恰当的Eps和MinPts,及每个簇中的至少一个点。由于很难事先获得数据集中所有簇的相关信息,DBSCAN算法实现时对所有簇采用相同的全局参数值Eps和MinPts,但把确定参数的任务留给用户,而且算法生成的结果对参数是敏感的。如若根据数据集中存在的比较密集的区域,选取了一个较大的Minpts值,那么数据集中其他区域会因为密度不够大而不能被划分成簇,会造成噪声点过多现象;若根据数据集中存在的比较稀疏的区域,选取了一个较小的Minpts值,那么整个数据集很容易直接被划成一个大簇,参数值的微小变化往往会导致差异很大的聚类结果。

图1 DBSCAN算法流程
2 DBSCAN聚类算法的参数配置
传统DBSCAN算法中Eps和Minpts两个参数是根据经验设置的,并根据聚类结果进行调整。这样做显然盲目性大,工作量也大,而且效果也不一定好。因此,文中提出了一种参数的判断方法,该方法的主要思想是根据数据集本身的统计特性以及图表的可视化结果由人工来选择参数。
2.1 Eps参数的确定方法
首先按式1计算数据对象间的距离,得到距离矩阵Distn×n。
Distn×n={dist(i,j),1≤i≤n,1≤j≤n}
(3)
其中,n是数据集D中的数据对象个数,每个元素表示对象i到对象j的距离。
求出矩阵后,将行向量按升序排序。这样,每行就是相应数据点到其他所有点距离的一个排序。则矩阵Distn×i中第i列的数据的意义是距每个数据点最近的第i个距离值的集合。为观察取不同i值(如1,2,…,7)时数值集合的统计特点,绘制图形,其中图2是距离值的概率密度分布曲线,图3是对第i列数据进行升序排序后的曲线。数据采用的是随机生成的含有150个数据点的二维数据集Dataset1。
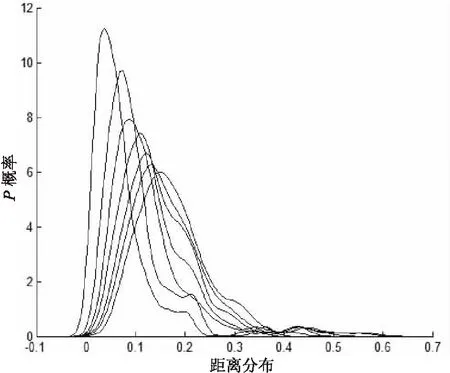
图2 距离值的概率密度分布曲线

图3 距每个数据点最近的第i个距离值的升序曲线
图2中,曲线均值越大的是对应i值越大的曲线。可以看到,无论i取多少,曲线的分布都大概成泊松分布。曲线右侧,距离比较大的地方(图中接近0.4)密度已变得非常小,这些比例很小却和其他点相比距离明显偏大很多的点,噪声的可能性较大。因此,可以考虑以此来确定Eps参数。
图3中,曲线由下至上依次是i值增大对应的曲线。曲线的趋势大致相同,前期和中间都比较平缓,末端陡峭。可以发现,当i大于4以后,曲线的陡峭点都大概集中在一个区域,即图中圆形标注内。在Martin Ester等的研究[13]中,对此问题也有描述。若取陡峭点对应的距离作为邻域阈值,可以估计,当i大于4以后,对噪声的划分情况是近似一样的,也就是聚类和噪声检测结果趋于稳定。
所以,取i等于4时,曲线的陡峭点对应的距离值作为DBSCAN算法中的Eps参数,即图3中圆圈标注的纵坐标,大概在0.3~0.4之间,与图2的分析一致。
2.2 Minpts参数的确定方法
前面Eps的取值是取距每个数据点最近的第4个距离值集合升序排序后曲线的陡峭点对应的距离值,即假定Minpts为4。但由于第一步需人工参与判断,很可能出现误差,而且固定的Minpts值设定不能保证对任意的数据集检测都有比较好的效果。为了能够更匹配已经确定的Eps值,可根据人们实际中对噪声判断的标准,再重新确定Minpts值。该思想融合了Alex Rodriguez等[14]提出的新型聚类算法的思想,即对于一般数据集,簇中心被局部密度较高的邻居点所包围,而高局部密度的点之间距离比较大。首先,根据2.1中确定Eps的方法得到Eps的值,然后计算每个数据点i的局部密度值ρi,即数据点邻域半径(Eps)内包含的邻居点数,再利用式4计算每个数据点i距更高密度点的距离δi,对于具有最高密度的点,δi的取值为其到数据集中最远点的距离。
(4)
数据集仍采用随机生成的含有150个数据点的二维数据集Dataset1,对每个数据点计算上述两个值,并以点图(如图4)的形式表现,图中的点就是数据集的每个对象。

图4 Dataset1中每个点δi与ρi的函数关系
为了进一步说明该图的意义,又采用随机生成的含有51个数据点的二维数据集Dataset2,计算得到每个点δi与ρi的函数关系,如图5所示。
在图5中,右上角的点δi比较大并且ρi也比较高,应该是一个簇的中心,而图中左边的点ρi非常小、δi又相对比较大的点更多是噪声。根据δi与ρi的函数关系点图,在聚类前,就可以得到数据聚类后的一个大概情况。对于数据集Dataset2,由图5可知数据集大概集中在一个区域,并且有少量噪声点,其中,数据对象点1(图中箭头标注),其ρ为0,并且δ非常大,可以肯定是一个噪声点;数据对象点2和3虽然ρ也比较小,但δ相对不是很大,所以只是有可能是噪声点,因为DBSCAN聚类的簇是密度相连接的点集。若选取Minpts为7(ρ=7),可以预测聚类检测结果,横轴坐标为7右侧的点肯定是核心点,不会是噪声,而左边那些比较稀疏的点则有可能存在要寻找的噪声点。在图4中,可以判断数据集大概集中在两个区域,也有可能存在噪声。若选取Minpts为2(ρ=2),横坐标为2左侧的三个点有可能是要检测的异常噪声点;若选取Minpts为5,横坐标为5左侧的六个点都有可能是要检测的异常噪声点。
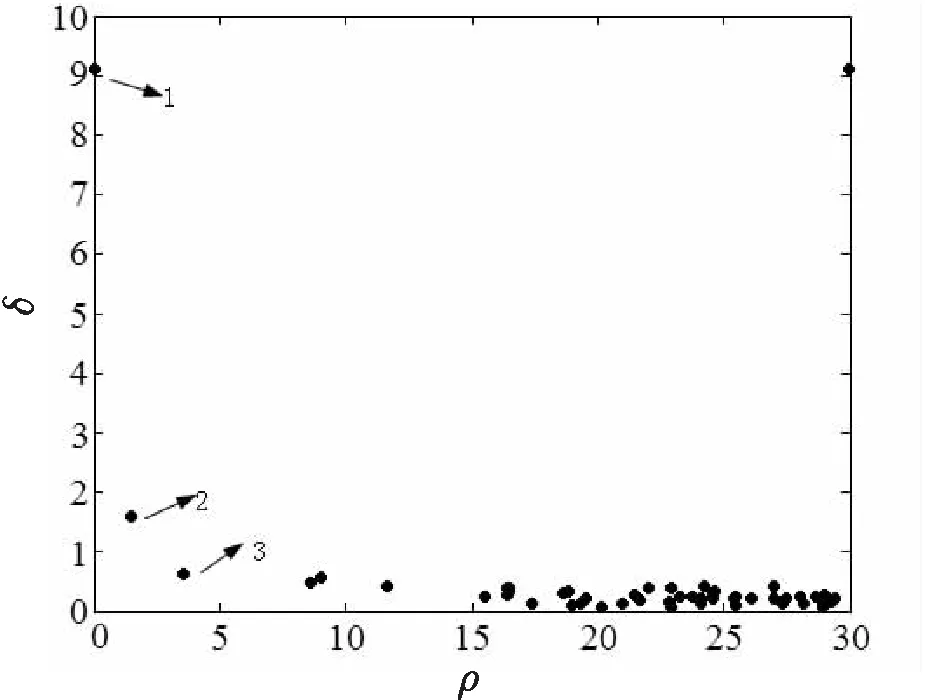
图5 Dataset2中每个点δi与ρi的函数关系
因此,利用δi与ρi的函数关系点图,Minpts值的设置就转换成了ρ阈值的选取问题,可选取图中左边稀疏点和密集点分界处的横坐标(ρ值)。在实际应用中,若对噪声的要求不是很严格,即偏差度不是很大就可以认为是噪声的话,可选取比较大的ρ阈值(Min-pts值);否则,可选取比较小的ρ阈值(Minpts值)。
3 数据异常检测分析
下面在美国加州大学信息与计算机科学系的Iris(鸢尾花)数据集上,应用DBSCAN聚类算法对数据进行异常检测分析,检验所提出的参数配置方法的有效性。
首先对数据集进行改造,添加了两个异常点,即补充了第151个数据点(第152行),该数据点因花瓣的长度(12)录入有误,造成异常;修改第70个数据点(第71行),使其class属性值由原数据集中的Iris-versicolor改为Iris-virginica。处理后的Iris(鸢尾花)数据集的部分数据如表1所示,数据集有4个数值型属性,1个字符型属性。
DBSCAN算法通过计算各个数据点的欧氏距离来聚类,要求参与计算的是数值型的属性。但是,在实际中,通常会有字符型属性,若将其舍弃,必然会丧失数据信息的完整性。文中将这类属性分为两类。一类是序数类型属性,比如军衔(少尉,中尉,上尉……)。这类属性的特点是不同属性之间有联系,而且是等距离的。所以,可将其替换为数值1,2,3……。另一类是标称分类属性的,比如国别(中国,美国,俄罗斯……)。若数据中有多个此类型的属性,通常只选取一个有代表性的参与运算。文中是在数据处理中按标称属性产生概念分层的方法。在聚类前,自动按标称属性分区聚类,不同的分区选取不同的参数设定。这样的处理虽然增加了工作量,但是不仅保证了信息的完整性,而且解决了数据密度不均匀却只有一个全局参数设定的缺陷。

表1 待检测的Iris数据集的部分数据
对Iris(鸢尾花)数据集的检测按class属性值Iris-setosa,Iris-versicolor,Iris-virginica进行分区,即分为3个区,对每个分区分别进行算法的参数设置。采用前述的参数配置方法,通过可视化的判定,设置Eps分别取值1.5、0.9、1,Minpts分别取值12、2、2,从程序输出检测结果可以看到,除了检测出之前添加的两个异常点外,还检测出两个异常点,分别是第42个数据点和第61个数据点。在原数据集中找到这两个点并进行人工检查,可以发现第42个数据点的sepal width属性值和其他Iris-setosa类鸢尾花相比是最小的,而且偏差比较大,而第61个数据点的四个数值属性值和其他Iris-versicolor类鸢尾花相比都是比较小的,这也就解释了这两个点被认为是离群噪声点的原因。因此,从数据集的检测结果来看,该方法的参数设置是比较准确的,异常检测的结果也是非常有效的。
为了进一步说明参数设置的准确性,将参数Eps统一取值为1,Minpts统一取值为4,得到的异常检测结果输出了7个异常点,其中一些异常点并不符合对异常点的判断标准。这说明DBSCAN算法对参数是敏感的,当参数设置不合适时,其检测结果也将不准确,也验证了文中算法是有效的。
4 结束语
对数据异常检测问题进行了研究,将基于密度的DBSCAN聚类算法用于数据的异常检测,并针对该算法在应用过程中对参数设置敏感的问题,提出了一种配置算法邻域阈值(Eps)和点数阈值(Minpts)的方法。该方法可根据数据集本身的统计特性以及图表的可视化展示,为算法确定合适的参数。编程实现了DBSCAN聚类算法及辅助参数确定的计算,并利用MATLAB工具进行可视化展现。并在Iris数据集上进行检测,通过对比测试,验证了用该方法进行DBSCAN聚类算法参数的设置是可行的,弥补了DBSCAN聚类算法参数设置单靠经验的传统做法,使得检测结果的准确性和可伸缩性更好。
目前,该DBSCAN聚类算法参数配置方法需要人工参与判定,仍存在一定的人为因素,同时参数判定的过程还比较麻烦耗时,这些都有待进一步的改进提高。
