基于FastDFS的数字媒体系统设计与实现技术研究
2019-05-17张祥俊伍卫国
张祥俊,伍卫国
(1.西安交通大学 软件学院,陕西 西安 710000;2.西安交通大学 电信学院,陕西 西安 710000)
0 引 言
高性能计算机已跨入了E级计算时代,数字媒体产业作为信息技术和人文艺术结合的内容创意产业已成为最活跃的高性能计算应用之一,用户众多。数字媒体作品的制作中,计算机3D技术的作用愈加重要,3D建模和渲染成为全球电影、动漫工业界关注的核心技术[1]。动漫作品团队使用渲染农场后处理好的数据需要存放在一个共享的平台[1],而在此平台上对数据的安全有效管理成为目前需要考虑的问题。因此,在渲染流程处理中的数据量很大,众包模式下的数据安全性、可靠性、高效存储、便捷管理是一个问题,为了节约成本,使用统一的开放平台接口处理渲染数据的问题也亟待解决。
FastDFS是一种分布式存储系统,特点在于以中小文件为载体[2],同时配合NGINX,两者作为图片服务器提供对应的在线服务,客户端使用API读写文件,基本解决了大容量存储的问题,并且这套高性能的文件服务器集群可以提供文件上传、下载等操作。虽然FastDFS能满足高性能的存储,但是针对渲染流程中海量媒体的管理需求,还没有办法完全达到。首先,FastDFS不支持断点续传,在大文件上传时,一般采用切片上传形式;第二,FastDFS对文件的上传版本没有控制,客户端上传的文件都保存在服务器中,没有进行版本化的管理;第三,完成一个数字产品所需要的数据量很大,同时资产数据的个数也很多,为了能够方便管理,需要有每个客户所上传的目录分级,而FastDFS不能完成这一点;第四,近年来,文创众包走进了大众视野,在此新制作模式下,多个制作团队之间需要资源共享与权限控制,显然当前的FastDFS无法满足这种多租户的存储即服务的需求。因此希望可以通过容器技术Docker支持多租户,实现用户环境隔离;第五,在数据安全方面,自动化恢复机制不完善:如果storage的某块磁盘故障发生,且故障时间较长,只能手动恢复原有数据并且换磁盘;需要预先准备好热备磁盘,否则很难立即向外提供正常服务。不能自动化恢复会增加管理员的运维成本。国内的FastDFS与Google FS相似,具有存储小文件优化和简洁的特性,比较mogileFS,维护和使用体验更好的开源分布式文件系统[3]。主要用于大中网站,为文件上传和下载提供在线服务。所以在负载均衡、动态扩容等方面都支持得比较好,但是截止目前,运用FastDFS进行存储,并在其基础上管理媒体资产的系统还未出现典型代表。
基于此,文中提出了一种利用容器化技术在给定时间进行数据同步的机制,保证整个存储集群满足高性能存储的数据可靠性要求,同时由于容器的多租户技术[4],具备了很好的隔离性。最后对其进行实验验证和测试。
1 系统基本结构
1.1 系统结构
海量媒体数据管理功能负责存储传输海量场景数据,由tracker集群和存储集群组成。tracker集群负责管理数据的元数据信息,具有文件分块/多副本/版本控制等功能,媒体作品创作端读写文件时首先和tracker集群通信完成元数据操作,随后将数据通过restful API对象接口传输到存储集群。具体使用场景如图1所示。

图1 数字媒体资产在线管理系统结构
1.2 FastDFS分布式文件系统
1.2.1 分布式文件系统概念
Distributed file system(DFS)是指多台计算机协同合作,从而完成文件存储、大数据计算等目标。互联网上的所有资源,最终都会以文件的形式存放在具体的物理机器的存储设备上。存储、读取和管理这些海量的文件依靠单一的机器无疑是不行的,所以分布式文件系统进入人们的视野。
1.2.2 FastDFS的系统架构
FastDFS组成包括跟踪服务器(tracker server)、存储服务器(storage server)和客户端(client)[5]。tracker的工作职责首要是调度,在整个过程中维持storage均衡;第二,作为所有storage server和group的管理者,需要连接每个storage,并得到它们所属group信息,同时获取其周期性心跳。得到心跳信息后,tracker负责建立group与storage serverlist的映射。
storage的责任是提供容量信息和冗余备份;storage server按group分组,同组内可以有多台storage,其中存储的文件有同步备份。按group为单位存储,可以进行隔离应用、服务器负载均衡、获取到副本数等。
client主要是客户端上传下载文件等数据的服务器,即在client上部署自身开发的项目。安装Nginx后,用户发送的请求可以被分发到不同的tracker上。
(1)FastDFS的存储策略。
FastDFS具有大容量存储的特性,其原因是存储节点采用了分组的组织方式。存储系统中包含一个或多个组,组与组之间的文件独立,整个存储系统中的文件容量是将所有组的文件容量累加起来得到的。一个组可以由一台或多台storage组成[6]。当组中增加storage时,系统自动完成同步组内已有的文件,同步结束后,新增服务器会被系统切换上线,并对外提供服务。如果发生存储空间不足或快要使用完的情况,动态添加组即可扩大存储系统的容量[7]。
(2)FastDFS的上传过程。
使用者可以通过upload、download、appendfile、deletfile等基本文件访问接口结合FastDFS进行操作,这些接口是以客户端库的方式提供给用户的。首先客户端发送上传文件的请求给tracker,tracker会分配一个可以存储文件的group,之后再继续分配合适的storage server。确定storage server后,client继而发送写文件请求,storage得到该消息后,将会为文件分配一个数据存储目录[8]。同时文件将得到fileid以作区分,最后生成存储文件的文件名信息。
(3)FastDFS的文件下载。
client端上传文件成功后,通过storage生成唯一文件名,调用download方法访问到该文件并下载。在下载时client可以选择任意tracker server。client发送download请求给某个tracker,请求信息中包含文件全名,tracker从文件全名中解析出文件的Id、所属group、扩展名等信息,之后选择一个storage读请求,提供下载服务[9]。
2 容器环境下的FastDFS器群组织与配置
2.1 环境的配置
docker pull zxj2017/fastdfs:v1
docker network create --subnet=172.18.0.0/16 fastDfsnet
docker run -d --name trackerA-h Server-A --net=fastDfsnet --ip 172.18.0.10--add-host="storageA :172.18.0.12" --add-host="storageB :172.18.0.13"zxj2017/fastdfs:v1 sh tracker.sh
docker run -d --name trackerB -h Server-B --net=fastDfsnet --ip 172.18.0.11--add-host="storageA :172.18.0.12" --add-host="storageB :172.18.0.13" zxj2017/fastdfs:v1 sh tracker.sh
docker run -d --name storageA --net=fastDfsnet --ip 172.18.0.12 -h storageA -e TRACKER_IP=172.18.0.10:22122 -e GROUP_NAME=group1 zxj2017/fastdfs:v1 sh storage.sh
docker run -d --name storageB --net=fastDfsnet --ip 172.18.0.13-h storageB-e TRACKER_IP=172.18.0.11.202:22122-e GROUP_NAME=group2zxj2017/fastdfs:v1 sh storage.sh
环境测试:
进入trackerA,上传文件 查看结果:docker exec -it trackerA /bin/bash
vi /etc/fdfs/client.conf
tracker_server= Server-A:22122
vi test.txt
hellofastDFS
/usr/bin/fdfs_upload_file /etc/fdfs/client.conf test.txt
进入storageA 查看结果:docker exec -it storageA/bin/bash
此时表明FastDFS的容器已经启动成功。
2.2 FastDFS的可靠性解决方案
环境说明:工作服务器A:IP地址 172.18.0.10,操作系统Ubuntu,已建立用户tom;备份服务器B:IP地址 172.18.0.11,操作系统Ubuntu,已建立用户jack(uid 503,gid 503)。
实现目的:每天早上3点,将A服务器上的用户目录/home,自动备份到B服务器的/home/jack/backup-A下,备份增量进行[10],不需要任何用户交互。
配置步骤:
配置备份服务器B。
(1)[root@Server-B ~]# rpm -qa| grep rsync #查看是否有rsync包
rsync-2.6.8-3.1
以上输出说明rsync已经装好了,保证/etc/services有下面的行。
rsync 873/tcp *rsync
rsync 873/udp *rsync
(2)rsync的rpm包本身没有附带rsyncd的配置文件,需要手动创建(/etc/rsyncd.conf)。
[root@Server-B~]#vi /etc/rsyncd.conf
Log file=/var/log/rsyncd.log
[local0]
Comment=back from Server-A
Path=/home/jack/backup-A
Hosts allow=172.18.0.10 127.0.0.1
Read only=false
uid=503 #保证在服务器B的备份操作以jack这个用户进行
gid=503
(3)修改/etc/xinetd.d/rsync,打开rsync服务。
[root@Server-B ~]# vi /etc/xinetd.d/rsync
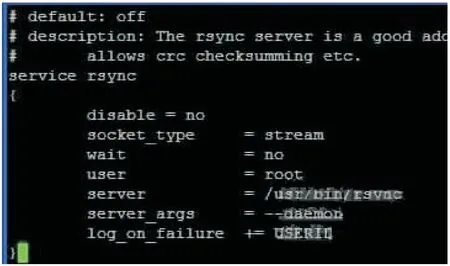
(4)开启rsyncd服务,并设置系统启动时加载rsync服务。
[root@Server-B ~]# /usr/bin/rsync --daemon
(5)检验rsync服务是否启动成功。
[root@Server-B ~]#rsync localhost::

有如下内容表示已经成功启动。

(6)配置ssh的非交互式登录。
>>在服务器A上生成一对密钥(以root的身份执行)[root@Server-B ~]# ssh-keygen -t rsa
>>远程登录到备份服务器B上并且创建.ssh目录
[root@Server-A ~]#ssh jack@172.18.0.11
[jack@Server-B ~]$ mkdir .ssh;chmod 0700 .ssh
>>在A机上执行远程拷贝公钥到B机:
[root@Server-A ~]#scp .ssh/id-rsa.pub root@172.18.0.11: /home/jack/.ssh/authorized_keys
这样,无交互的ssh登录就完成了。
(7)编制备份脚本。
在服务器A上编写一个备份脚本,放置在/home/tom/public_scripts下,名为backup.sh。
#!/bin/sh
TARGET_DIR=backup-A
for SOURCE_DIR in “/home”
do
echo “Backing up $SOURCE_DIR …”
rsyn-au-delete $SOURCE_DIR jack@192.168.1.87:/home/jack/$TARGET_DIR
done
[root@Server-A public_scripts]# chmod 755 backup.sh
该脚本权限设置为755,以便其他用户可访问到。
(8)修改计划任务。
在服务器A上,用root身份执行以下命令,可以设定什么时候执行脚本
[root@Server-A ~]# crontab -e
3* * * * /home/tom/public_scripts/backup.sh
同样的操作在storageA和storageB之间将它们的目录数据采用定时同步,然后对节点的同步进行备份。
3 实验测试
3.1 测试环境
测试节点配置见表1。

表1 测试节点配置

续表1
该系统的测试使用FastDFS tracker服务器,FastDFS storage服务器,Mysql服务器与一台终端进行,安装完成后,可通过上传、下载的命令行进行是否安装成功的测试。图2是测试环境的网络拓扑。
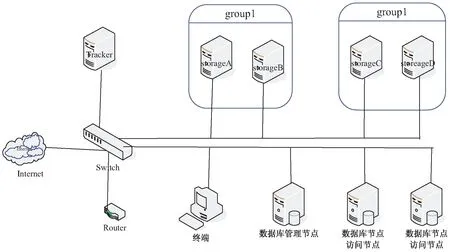
图2 测试环境网络拓扑
由图2可知,因为服务器在FastDFS中担任的角色不同,所以配置启动的服务也不同。首先,在服务器172.18.0.10上对应配置tracker,而在存储服务器的group1对应的172.18.0.12(storageA)和172.18.0.13(storageB)、group2对应的172.18.0.14(storageC)和172.18.0.15(storageD)上配置storage,分成2组。按要求,tracker、storage服务器的配置文件都需要修改后方可运行。根据上节提出的同步目录组问题的设计[11],可知172.18.0.14(storageC)和172.18.0.15(storageD)中还必须配置rsync服务。最后配置启动数据库,包含3台服务器。按照测试环境配置中划分的角色,修改配置文件/var/lib/mysql-cluster/config.ini和/etc/my.cnf。由于条件限制,数据节点和访问节点安装在同一服务器上,先启动管理节点192.168.0.243,再启动数据节点192.168.0.241,192.168.0.242。
3.2 可靠性测试
由部署的测试环境可知,FastDFS组内一般有多台存储服务器,组内设计在group2对应的172.18.0.14和172.18.0.15上配置storage,通过将其中一台存储服务器172.18.0.14以及数据库集群节点172.19.0.12关闭,模拟出分组中一台存储服务器及数据库集群宕机的情况,如图3所示。
第二步登入系统上传一个文件,文件上传成功后保存在FastDFS中的key是:
group1/M00/00/00/ rBIADFsMB9-AQUvBAAAA DT_u2ZM252.txt。由图4、图5可知,当同组内的某台存储服务器宕机时,集群对外提供的服务稳定,并且可将上传的文件同步到在分组中另外一台存储服务器172.18.0.15上。
由测试结果可知,当172.18.0.12宕机时,开启172.18.0.13服务器,可查找到已经同步的文件,集群在某些节点宕机的情况仍可工作,因此系统具备较高的可靠性。
4 结束语
文中提出一种在FastDFS基础上增加新功能的解决方案,以满足平台对海量媒体存储要求的技术,通过容器技术对存储组镜像进行隔离[12-14],结合nginx模块的无缝衔接,跟踪节点和存储节点可以灵活分配。针对FastDFS在数据恢复方面的缺点,提出一种在不同节点上的同步策略,保证了存储系统的可靠性和高效性。实验结果证明了该方法在高性能计算环境下的可靠性和隔离性[15],该技术提高了数字媒体系统在存储方面的效率和灵活性。但是依然有一些不足,比如对于上层的应用程序还可以结合容器编排技术对其进行微服务式的管理,这样可以大大提高整个系统的可靠性。另外,同步策略在同步数据时会给系统的性能带来一些影响,这些问题还需要在今后的研究中继续解决。
