基于DPI 和BP 神经网络的P2P 流量识别研究
2019-05-17万建伟胡勇
万建伟,胡勇
(四川大学电子信息学院,成都 610021)
0 引言
在过去的十几年里,对等网络P2P(Peer to Peer)技术在各个领域里得到了广泛的应用。P2P 技术的使用,使得网络用户在作为客户端的同时也成为了服务端,能够给网络中的其他节点提供服务,共享信息。因此,采用P2P 技术的应用软件因受到用户的欢迎而快速发展。研究表明,60%的互联网流量都是P2P 流量。P2P 协议传输的数据具有传输速度快、容量超大等优点,它极大地方便了用户,但与此同时,由于缺乏有效的监管,P2P 应用也给网络服务管理带来了一些问题,例如,众多的网络用户同时使用P2P 流量会造成网络堵塞、占用带宽,这会加大网络开销。并且P2P 流量在传播的过程中,可能会携带木马病毒、诈骗信息,容易造成网络安全问题;还有部分P2P 应用软件为了抢占客户资源,恶意侵占网络带宽,大大降低了网络空间的整体利用效率,破环了网络运营环境。
随着P2P 流量的急剧增多,网络管理员如何更加有效监控P2P 流量成为了一个形势严峻的问题。而要处理好这个问题,必须对P2P 流量进行识别研究,只有识别控制该流量,才能最大化地利用网络资源,提升整个网络的使用效率,P2P 流量的识别研究是网络安全研究领域的热点。
1 P2P流量的检测方法
P2P 流量识别技术主要包括:基于固定端口的识别、基于深度包检测技术(Deep Packet Inspection,DPI)、基于流量统计特征和机器学习的识别方法。
基于固定端口的识别方法是最常用、最基本的识别方法,其原理是通过分析报文段的报头,获取传输层的端口号信息,识别流量类型。该识别方法在使用固定端口号的应用程序上有着很高的识别率,方法简单、识别速度快。但是这种方法对未知端口和协议不适用。
基于DPI 技术的流量识别方法不仅分析数据包中源、目的地址和源、目的端口,还要分析应用层的数据。获取数据包之后,通过DPI 技术识别载荷里面的特征字,识别出对应类型的流量。DPI 主要是一种对应用层载荷特征进行识别的技术,它基于特征字符串以及行为模式。但是,随着互联网技术的发展,DPI 方法在检测流量的过程中出现了一些问题,例如,当P2P应用更新时,检测分析过程中的特征库没有及时更新,则无法检测出该应用。并且,该方法也不适用于检测使用加密的应用程序。
基于流量统计特征的识别方法在文献[1]中有提及,该方法在分析P2P 协议工作原理的基础上,提出了区分P2P 流量的几个统计特征,如节点的链接不稳定性、节点发现模式、远端IP 分布广度。基于流量统计特征的识别方法识别度好且效率高效,这是由于该方法选取了良好的流量特征,成功克服了基于效载荷方法成本高、无法识别加密流量的局限性,但是它不能辨别出具体的P2P 流量。
而后出现了大量的基于机器学习的识别方法,主要包括支持向量机、决策树以及基于神经网络的识别方法。该类方法不再依赖于单个应用程序的特征,而是对基于流的传输层特性进行分析,进而识别P2P 应用,该方法可以解决深度包检测技术不能识别应用层加密流量和应用更新的问题。文献[2]提出了基于支持向量机(SVM)的识别方法,其改进模型有:基于SVM的遗传算法[3],基于SVM 的粒子群优化算法[4]和基于SVM 的人工蜂群算法[5]等。该方法是一种有坚实理论基础的新颖的小样本学习方法,它不仅算法简单,而且十分稳定,但SVM 算法及其改进方法对大规模训练样本难以实施,且在解决多分类问题时存在困难。文献[6]提出了基于BP 神经网络的识别方法,其改进模型有:基于自适应BP 神经网络的识别方法[7]和基于BP-LVQ 神经网络的识别方法[8]。BP 神经网络具有自学习能力,但是该方法存在选择网络结构不唯一的缺点。文献[9]提出了基于决策树(Decision Tree)的识别方法,该方法易于理解和实现,效率高,但是在处理特征关联性比较强的数据时误差比较大。因此,当需要识别流量的数量足够大时,以上方法不能很好地识别出P2P 流量。
文献[10]提出了基于卷积神经网络(CNN)的识别方法,该方法是一种前馈神经网络方法,特别适合图像处理。CNN 在处理高维数据时表现良好,并且无需手动选取特征,训练好权重,特征分类效果好,但是该方法需要调参,需要大量样本,实现起来比较复杂,并且训练所需时间比较久,在进行P2P 流量识别时,该方法不能实时识别出流量类型。
本文结合机器学习利用传输层数据的检测方法和DPI 方法,提出了一种新的识别模型:基于DPI 和BP神经网络的P2P 流量识别模型。该模型很好地弥补了DPI 检测法不能及时识别出更新后的P2P 应用和加密应用的缺点,极大地提升了识别P2P 流量的能力。
2 P2P流量检测新模型
该模型结合DPI 技术和BP 神经网络来识别P2P流量。该模型的检测流程图如图1 所示。

图1 混合检测模型
流量收集模块的功能是捕获流经网络中的流量,当被捕获的流量传到DPI 模块后,该模块提取这些流量的应用层特征,再结合特征库中的特征数据,对提取的特征进行匹配,判断该流量是否为P2P 流量。若是,则标记该流量为已知流量;若不是,则进行下一步操作,将该流量送入基于BP 神经网络模块,做进一步识别。图1 是对此模块的详细说明。
2.1 DDPPII检测模型
深度包检测技术(DPI)通常利用模式匹配算法对数据包有效载荷中协议的关键字进行匹配,从而判断是否属于对应的协议。DPI 技术主要包含两个方面,一方面是匹配算法的选取,另一方面是协议中关键字的提取。协议关键字的提取:有些协议具有唯一标识该数据包对应业务类型的特征串,可以通过搜索数据包中应用层有效载荷的特征串,识别数据包中的协议。部分协议的负载特性如表1 所示。
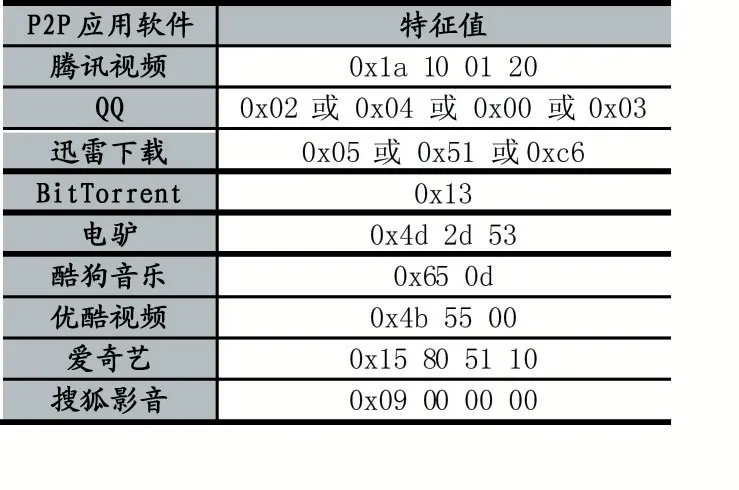
表1 常见的P2P 应用软件特征值
在协议识别过程中,提取特征串的准确度越高,识别的结果越准确。
匹配算法利用特征库中的协议特征字匹配数据包应用层中有效载荷的内容,如果匹配成功,则将该数据包的协议类型对应到协议特征字的应用类型。如使用表 1 中的 BitTorrent 的特征串“0x13Bittorrent Protocol”匹配数据包中有效载荷的内容,如果匹配成功,则认为这个数据包属于BitTorrent 数据包。匹配算法[11]可以分为多模匹配和单模匹配两种,常见的算法有KMP、AC、KR 和BM。特征串的长度与模式匹配算法的时间复杂度有关,当特征串较长时,模式匹配算法的计算速度较慢,这将导致DPI 吞吐量降低。
综上所述,在使用DPI 技术识别有特征字的协议时,可以准确、可靠地识别相应协议流量,但是特征库需要随着协议的更新而不断更新。
2.2 基于BBPP神经网络的检测模块
BP 神经网络在模式识别、数据压缩和函数逼近等领域有着广泛的应用。图2 展示了BP 神经网络对已有数据进行训练、建立流量分类器的过程,图2 对未知流量分类进行了解释。
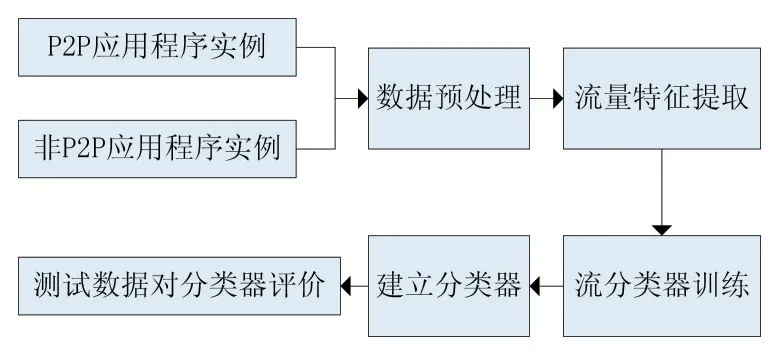
图2 流量分类器的建立过程
首先,选择部分常见的P2P 应用(例如BitTorrent、腾讯视频、酷狗音乐等)和部分非P2P 应用(例如FTP、网页浏览、DNS)的数据作为训练数据和测试数据集。实验中,为提高对一些非常见流量的识别度,将选择等量的应用程序实例。
其次将这些应用程序进行预处理,提出数据流的特征属性,如流持续的时间、流中发送/接收数据包的个数、流中发送与接收数据包个数的比值等。接着选择流量特征。
特征选择也叫特征子集选择,是指从众多特征中选出可以使系统获得最优化特征子集,去除冗余特征的过程。通过这种方法可以提高数据质量。本文通过使用WireShark 工具对采集的P2P 流量数据样本进行分析,同时结合Moore 数据集(该数据是由英国剑桥大学的Moore 等在一天的10 个不同时间段采集经过网络出口的所有双向流量数据所得到的,该数据集包含了377526 个流量样本,由十个集合构成,其中每一条的数据流样本又包含248 个属性特征。)中的大量属性特征进行比较,最终将用作P2P 流量识别依据的流特征向量定义为:

其中,各分量分别对应一个流量特征:多连接性特征(mip)、多端口性特征(mport)、远端地址端口统一性特征(raup)、数据包净荷长度标准差(stddev)、大小数据包交替出现次数(swf)和净荷长度大于零的数据包个数(pcnt),这些特征分别从不同的视角阐述了P2P 流量与非P2P 网络流量的差异,虽然单个特征不足以用来准确识别P2P 流量,但是多个特征的组合则产生累加效应,从而提高识别准确率。
接着将训练数据输入BP 神经网络检测模块,建立分类器。在整个训练过程中,选取包含P2P 应用和非P2P 应用的46500 条数据流量,验证方法采用十折交叉法,用于提高准确度。
BP(Back Propagation)神经网络的学习过程包含前向传播和反向传播两个部分,它是目前应用最为广泛的神经网络之一。前向传播将输入神经元的阈值整合进隐层权值向量中,逐层传播。当输出层的实际输出和期望输出不符时,进入误差反向传播,将误差分摊给输出层和隐含层的所有处理单元,逐层修正权值和阈值,反复迭代。通过这种方法,可以大大降低误差。图3 中是一个三层BP 神经网络的结构图。

图3 三层BP神经网络
本文使用三层神经网络进行训练和测试,选取输入神经元的个数为6,即样本数据会话流的6 个属性特征。输出神经元是输入流量的对应类别,取值为0 或1,结果为1 则判定输入流量为此类别,反之,则不是。通过多次训练比较,确定隐含层神经元的个数为11。
最后验证分类器的精确度,所用的数据为测试数据集。
数据的分类过程如图4。通过预处理捕获的46500 条数据流量,获取统计特征,然后筛选出所需特征,再将样本中的流量数据输入分类器,通过输出结果判断流量是否为P2P 类型。

图4 BP神经网络基于传输层检测法
3 实验过程
3.1 实验环境
实验拓扑结构如图5 所示,在实验室局域网环境下,使用3 台均为Win7 系统的客户端,1 台服务器的操作系统使用的是Linux 系统。在Linux 服务器内运行识别P2P 流量的程序Weka3.7。
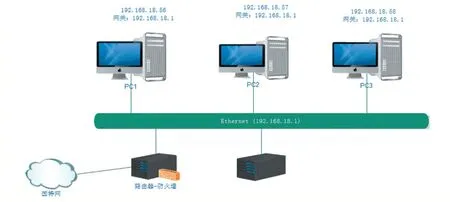
图5 实验拓扑图
3.2 实验方法
方法1:使用DPI 方法,测试应用选择BitTorrent、酷狗音乐、腾讯视频、迅雷、Skype。
方法2:使用BP 神经网络检测方法。
方法3:结合BP 神经网络和DPI 的检测方法。
分别在3 台客户端的虚拟机(VMware 下的Win7系统)上运行P2P 应用软件,PC1 上运行BT 下载以及Skype 聊天;PC2 上运行腾讯视频在线播放以及迅雷下载;PC3 上运行酷狗音乐和 Skype 聊天。BitTorrent、腾讯视频、迅雷、酷狗音乐的应用层特征均为已知,Skype为加密应用软件。同时,在每台PC 上运行网页浏览、FTP 上传等非P2P 流量操作。本实验中,通过3 台客户端来获取数据,以便在较短的时间内得到足够多的数据量,在VMware 环境下可以减少Windows 系统自带的应用软件在运行过程中对采集的数据流量进行干扰。数据采集完毕后,运行Linux 系统中的识别程序。
3.3 实验结果
运行15 分钟后,从程序中得到的实验识别结果如图6 所示。
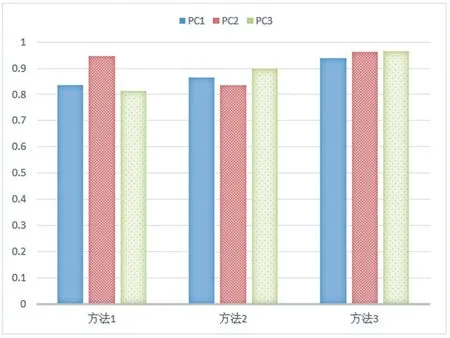
图6 各方法的识别率
由图6 可以看出,DPI 技术在识别P2P 流量时,识别率达到了86%以上;BP 神经网络在识别P2P 流量时,识别率也在85%左右;而结合了DPI 和BP 神经网络的方法在识别P2P 流量时,识别率达到了95%。
整理图表数据,对各方法的平均识别率进行对比,结果如表2 所示。

表2 各方法的平均识别率
由表2 可知,在进行P2P 流量识别时,DPI 的识别率为86.5%,BP 神经网络的识别率为85.3%,结合了DPI 和BP 神经网络方法的识别率为95.6%。
3.4 实验分析
结合图6 和表2 中的数据进行分析可知,基于DPI 的检测方法在识别BT、腾讯视频、迅雷、酷狗音乐和Skype 等应用程序时,其效果和基于BP 神经网络的方法相差较小,这是因为基于BP 神经网络的检测方法在识别BT、腾讯视频、迅雷和酷狗音乐等已知的P2P应用程序时,其表现不及DPI 方法,但是它在识别加密流量Skype 时,性能比DPI 检测法要好;而基于DPI 和BP 神经网络的检测方法结合了两者的优点,在识别已知P2P 应用和加密P2P 应用时都能获得比较好的性能,因此它的识别率很高。
4 结语
本文结合DPI 和BP 神经网络对P2P 流量进行检测。实验证明该方法提升了流量检测的准确度。但由于传统BP 神经网络存在易陷入局部极小值的缺陷,在以后的工作中可以对BP 算法做一些优化,进一步提升P2P 流量检测的准确度。
