带有GRU 单元的通用句嵌入算法研究
2019-05-17毛玉婷
毛玉婷
(四川大学计算机学院,成都 610065)
0 引言
语言是人有别于其他物种的本质特性。在所有生物中,只有人类才具有语言能力。人类的多种智能都与语言有着密不可分的联系。人们通过语言来表达想法进行沟通,也通过文字来传播记载知识经验。在计算机科学领域,这也是人工智能的一个重要课题。而所谓的自然语言处理,其本质是理解自然语言中所想要表达的意思和情感,并转化成机器所能理解的形式。
最早的自然语言处理方向的研究是1949 年,由美国人威弗提出的机器设计方案。20 世纪60 年代,国外开始出现对机器翻译方向研究热潮,但是由于在当时语言处理的理论与技术均不成熟,所以没有能够取得较大突破。进入90 年代以后,自然语言处理领域开始有了新的突破。在系统输入方面,要求能够处理大规模大数量集的真实文本,而不是仅仅停留在少数词条上面。处理文本:要求机器能够处理大规模文本,并且从理解,筛选出对实际应用有用的信息。在面对大量文本以及大量工作量的需求下,单纯的统计学方法已经不能满足人们对于自然语言处理方面的需求,因此引入了多种机器学习的方法来对文本进行训练,最早这个想法是由Bengio 在2003 年提出,通过输入词向量,并最大化连续单词出现概率来构造损失函数。而这个模型的第一步就是已经进行过处理的词嵌入表达。所谓的词嵌入与句嵌入其实是对自然语言处理问题中各种下层问题所进行的预处理。通过各种方法对语料进行预处理,将词语和句子转化成通用的包含语意或者情感信息的定长向量,供机器翻译,简单问答,情感分析等其他自然语言处理下层任务使用。
在自然语言处理方向,对语料库的处理主要分为三个层次:文档段落、句子,以及单词。目前已开发出了多种使用向量表达单词的算法。但单词的向量表达还不足以满足自然语言处理中情感分析,简单问答等多种复杂的任务。句嵌入是在句子层面,对词嵌入的进一步概括。从主观上理解,句嵌入算法相较于词嵌入算法能够更好地理解整句话的中心思想与情感。
目前主流的句嵌入算法采用的多为有监督学习机制,其优点是所得训练结果更准确,但同时,带有标签的语料库需要耗费大量的人力劳动,也不利于语料库的及时更新。同时,有监督学习算法多针对与某一具体任务,不具有通用性。因此如何使用无监督的方法学习能过准确表达句意的向量空间成为本文的主要研究方向。
最近的学习句子向量空间表达的方法可以概括为两类:①从句子中的词向量入手,映射到句向量空间。例如平均词向量算法对每个单词求平均,得到整个句子的向量表达;②直接通过神经网络训练词向量。另外,在研究词向量与句向量表达算法时,大家所普遍认可的理论基础是:相似的词语/句子拥有相似的上下文。基于这个假设,可以通过核心词汇预测上下文的概率(skip-gram)或者基于上下文词汇来预测核心词(CBOW)。本文也基于这个假设,通过编码器-解码器模型去学习句向量表达,并通过句向量预测其上下文句子。通过最大化真实上下文出现的概率来构建损失函数,并通过自然语言的多任务来对比评价本文的训练结果与其他句向量的优劣。
1 算法实现
(1)总体模型描述
在自然语言处理方向,对语料库的处理主要是在词、句子、段落文档等三个层次上进行。目前在词的层面有非常丰富的无监督模型,例如skip-gram、CBOW,等等。本文借鉴了skip-gram 等词嵌入模型,旨在构建一个在多种自然语言处理任务中能够通用的无监督句嵌入模型。同时,根据语料库中固定窗口大小的上下文信息,来构建算是函数,对向量值进行修正,称他为SRWC(Sentence Representation With Context)。
构建过程主要分为两步:①通过编码器-解码器模型对语料库中的单个句子进行训练;②结合固定窗口下的上下文信息对句向量进行修正,通过最小二乘回归构建损失函数,得到最终结果。
编码-解码模型中的编码具体指的是迭代句子中的每个词将其映射到句向量中的过程。而解码指的是,使用编码步骤生成的句向量来预测该句子周围其他句子的句向量。目前,有许多现存的编码器-解码器模型可供选择,例如:RNN-RNN、LSTM-LSTM。编码后的句向量甚至可以通过注意力机制而动态变化,从而只考虑在给定时间中相关词汇。本文选择了带有GRU(重置门与更新门)的RNN 编码器与解码器。它与原生的在神经机器翻译中所使用的RNN-RNN 编码解码器几乎相同。GRU 在构建模型句向量时性能与LSTM 几乎一样好,但是计算过程相对于LSTM 简单,因为GRU 只需要考虑重置门与更新门两个门就可以了。虽然本文中使用了RNN 来对句子进行编码解码,但在实际过程中,也可以选用其他编码器-解码器模型来进行训练。
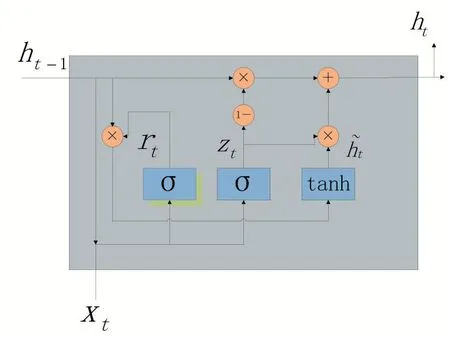
图1
图1 中GRU 单个神经元示意图,从t-1 时刻到t时刻的状态。rt为t 时刻的重置门,zt为t 时刻的更新门,ht为t 时刻所预测的隐藏状态。在t 时刻,输入上一个时间的输出ht-1与当前时刻的词向量xt,实际输出值为当前真实隐藏状态ht,并用作下一次迭代的输入。GRU 的更新门与重置门可以在一定程度上解决RNN 梯度消失问题。
(2)编码过程
假设固定窗口大小为3,则有三元组(si-1,si,si+1)分别表示语料库中三个相连的句子,其中将si看成中心词对其进行编码。si-1与si+1作为si的窗口上下文,可在解码阶段通过si的向量表示进行预测。一个句子si中有N个词,将其表示为w1i,w2i,…,win。在 RNN 的第 t 次迭代中,编码器更新隐藏层hti,它是 w1i,w2i,…,wti的词序列的表达。因此,第N 次迭代以后hni,即为整个句子的表达。
公式如下:

其中 rt表示 t 时刻的重置门,zt表示更新门,ht表示t 时刻所预测的隐藏层。更新门和重置码都是独热码,只包含0 和1。
(3)解码过程
借鉴词嵌入算法skip-gram 的想法,能够使用中心句si来预测其上下文的依据是,认可带有相似语义和相似情感的句子拥有相似的上下文的常识。现已知有三元组(si-1,si,si+1),利用编码阶段生成的句子si的隐藏层hi,来推测si-1与si+1的隐藏层。
解码的过程与编码的过程类似,是在已知编码过程里输出hi的条件下,进行GRU 迭代。与编码过程有区别的地方是,解码过程中引入Cz,Cr,C 三个矩阵,分别表示重置门、更新门,与预测隐藏状态的偏移量。在三元组(si-1,si,si+1)里,编码器有两个,一个是求si+1的编码器,另一个是求si-1的。下面公式表示的是求si+1的过程,si-1以此类推。

则在si+1中,第t 个词 wti+1的出现的条件概率可以表示为:

则目标函数可定义为最大化si+1与si-1的对数似然概率,即最小化它们的倒数:
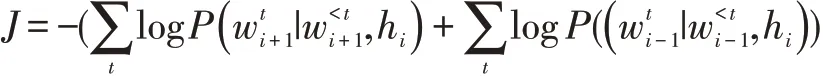
2 语料库的选择与模型训练
使用了 BookCorpus dataset(Kiros et al,2015)中7000 本英文小说,包含4 千5 百万条有序句子。针对初始状态下模型冷启动问题,使用大小为5 万的大小写敏感的词汇表来解决。
在实际训练中,使用语料库中连续的一组句子构造一个小型的批处理。对于每一个句子,他的小组中的所有句子被认为是句子分类的候选库。这样的方案效果同随机抽样和选择当前输入句的最邻近句子效果是近似的。在预测测试集上的准确度时,包含一些超参数,例如学习速率,批处理每组大小以及上下文窗口大小等。例如当上下文窗口为3 的时候,对于每一个给定的句子,预测其前一个句子和后一个句子。使用大小为400 的批处理小组,且使用Adam 优化的梯度下降算法进行实验。所使用的RNN 编码解码器都是单层的,且利用GRU 神经元来编码RNN 的梯度消失问题。使用统一的Xavier 初始化方法初始化GRU 单元的权值,所有门的偏移量初始为1。词嵌入通过U[-0.1,0.1]进行初始化。通过自然语言中的2 个下游问题:情感分类,语义对比来对句嵌入结果进行评价。
3 结语
本文通过使用GRU 编码解码器实现了无监督的句嵌入算法,其相对于有监督的方法,在自然语言处理方面更具有通用性。在实验过程中,本文实际通过2个自然语言处理的下游任务:语义关联度、情感分类来对比其与有监督句嵌入算法的优劣。结果证明,本文所提出的无监督方法更具有通用性,且能够适用于无标签的大数量集的语料库。
