基于降噪自动编码器的语种特征补偿方法
2019-05-15苗晓晓
苗晓晓 徐 及 王 剑
1(中国科学院声学研究所语言声学与内容理解重点实验室 北京 100190)2(中国科学院大学 北京 100190)
语种识别(language identification, LID)是指自动判定给定语音段,从该语音信号中提取各语种的差异信息,判断语言种类的过程[1].人类的听觉系统是世界上最准确的语种识别系统.经过短时间的训练学习,人们能够快速准确地判定语种类别.即使是不熟悉的语种,人们也能对其语种与所知道的语种做出一个粗略的判断.语种识别的目标是将这种能力赋予计算机使语种分类自动化.根据测试集语种类别,可以将语种识别任务分成闭集语种识别和开集语种识别.闭集的训练集语种类别包含所有测试集语种类别,而开集的训练集并没有包含所有测试集语种类别[1].近年来,语种识别技术在这2个任务上已取得了长足的进步.然而仍有很多不足,尤其是面对短时语音段语种识别、高混淆度的语言识别、大量集外语种任务时.本文主要针对闭集语种识别问题展开研究.
传统的语种识别技术可分为基于音素层特征和基于声学层特征.基于音素层特征的语种识别技术是将音素层特征作为识别依据,主要考虑了不同语种有着不同的音素集合,音节和音素出现的频率有很大差异,以及音节和音素的组合大不相同等因素.一般通过音素识别器,先将语音信号解码为音素序列或者音素网格.在建模阶段,通常为每个语种建立N元文法(Ngram)模型或者N元文法统计量模型[2].常用的方法有音素识别后接N元文法模型(phoneme recognizer followed by language model, PRLM)[2]、并行音素识别器后接语言模型(parallel phone recognition followed by language modeling, PPRLM)[3-4]和并行音素识别器后接向量空间模型(parallel phoneme recognizer followed by vector space model, PPRVSM)[5]等.基于声学层特征的语种识别技术依赖于声学层特征.通过对语音信号分帧、变换提取声学层特征,采用概率统计或鉴别性方法对其建模.常用的声学层特征有美尔频率倒谱系数(Mel-frequency cepstral coefficient, MFCC)[6]、感知线性预测系数(perceptual linear predictive, PLP)[7]、滑动差分倒谱(shifted delta cepstrum, SDC)[8]等.主流系统有混合高斯模型-全局背景模型(Gaussian mixture model-universal back-ground model, GMM-UBM)[9]、高斯超向量-支持向量机(GMM super vector-support vector machines, GSV-SVM)[10]和基于全差异空间的(total variability, TV) i-vector系统[11]等.
近几年,深度神经网络(deep neural networks, DNNs)[12]模型在语种识别任务上得到快速发展.一方面从前端特征提取层面,蒋兵等人[13]利用DNN强大的特征抽取能力,提取了深度瓶颈特征(deep bottleneck feature, DBF);另一方面从模型域出发,Lei等人[14]提出了基于DNN的TV建模策略.
此外也出现了基于深度学习的端对端语种识别系统,摒弃了传统的语种识别系统框架.2014年Google的研究人员[15]将特征提取、特征变换和分类器融于一个神经网络模型中,这是端对端系统首次被成功应用于语种识别任务.随后有研究人员在此基础上发掘了不同神经网络的优势,包括延时神经网络(time-delay neural network, TDNN)[16]、长短时记忆递归神经网络(long short term memory-recurrent neural network, LSTM-RNN)[17].2016年Geng等人[18]利用注意力机制模型(attention-based model),结合LSTM-RNN搭建了端对端语种识别系统,也取得了不错的语种识别性能.2018年Jin等人[19]提出了基于LID-net、LID-bnet的端对端语种模型,并利用LID-net模型提取统计量,对比原有的DNN-TV系统,从网络中间层中获取LID-senone特征,证明了这个特征更具有语种区分性.同年Cai等人[20-22]提出了一种基于可学习的字典编码层的端对端系统,从底层声学特征直接学习语种类别信息,摒弃了声学模型,也取得了较优的识别性能.
Vincent等人[23]于2008 年提出降噪自动编码器(denoising auto-encoder, DAE).该神经网络用于抑制输入信号中的噪声因子,能够有效加强系统的鲁棒性,广泛应用于语音增强[24]、语音信号去混响[25]等领域.2015年Yamamoto等人[26]首次将DAE应用于短时说话人识别,2017年Yang等人[27]在此基础上,改进并提出了基于DAE的短时说话人i-vector补偿技术,取得了较好的说话人识别性能.
目前,将降噪自动编码器用于语种识别领域的研究鲜见报道.本文基于国内外关于语种识别和降噪自动编码器的研究,实现了基于降噪自动编码器的语种特征补偿方法.本文的主要贡献有2个方面:
1) 目前的语种识别系统在训练语音与测试语音长度匹配的情况下具有较高的识别率,而当长度失配时,其性能也随之下降.为了解决这个问题,本文提出一种基于降噪自动编码器的语种特征补偿方法,将不同长度的语音特征都映射为固定长度的语音特征,一定程度上解决了长度失配问题.
2) 语音学的研究[28]表明,在世界范围内,几乎没有任何语音拥有相同的音素集合,即使有些语言共用同一套音素体系,音素出现的频率也有所差别.因此在语种识别中,音素作为重要的特征,可以被用来有效区分语种.而事实上,测试语音小于10 s或者更短时,语音的音素分布严重不均衡[29].在这种情况下语种特征的提取也是不可信的,极大地影响了识别性能.基于DAE的语种特征补偿算法,将短时语种特征映射到长时语种特征空间,以得到音素分布更为平衡的短时语音段表示,缓解了短时测试语音音素分布不平衡的问题.
1 相关工作
本文搭建了目前国际主流的2个语种识别系统:基于全差异空间的语种识别系统和基于端对端神经网络的语种识别系统,并以此作为实验的基线系统.二者建模方法有所差异,前者是传统的生成式的建模方法,将GMM均值超矢量映射成低维向量,再利用语种标签信息训练得到后端分类器.而后者在整个训练过程中直接使用深度神经网络进行语种识别,这也是当前语种识别方向的研究热点.
1.1 基于全差异空间的语种识别系统
基于全差异空间的方法首先被成功应用于说话人识别任务[30-31],随后被迁移到语种识别领域[32-33],成为语种识别领域的主流方法之一.基本框架如图1所示:
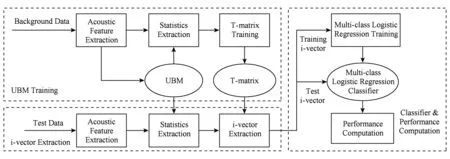
Fig. 1 structure of the GMM i-vector LID system图1 GMM i-vector语种识别系统框图
TV系统通过定义一个低维空间,该空间不区分捕获到的差异信息是否与语种、说话人和信道信息相关,而是将GMM超向量[10]中的语种、说话人变化空间和信道变化空间合并为全差异空间来进行建模.因为强制分离空间的话有可能会因为分离的不正确而丢失重要的信息,这些信息在后端建模中是无法弥补的.为避免有关语种的有效信息丢失,假设所有的空间都被合并成一个统一的空间,由全差异矩阵T来构建.直观上来讲,全差异空间会将高维的GMM超向量M映射成一个低维向量.假设M能被分解为
M=m+Tw,
(1)
其中,m是与语种和信道等无关的超向量,即UBM的均值超向量.因为UBM是由背景数据训练得到的,无任何先验信息,因此可以认为m与语种、说话人、信道等无关.T为全差异矩阵,w是全差异因子,也叫i-vector,是对GMM超向量的低维表示.i-vector作为模型中的隐含变量,满足高斯分布,其后验分布:
w(u)=(I+TTΣ-1N(u)T)-1TTΣ-1F(u),
(2)
其中,Σ是对角协方差矩阵,定义了GMM超向量中未被TV空间描述的噪声部分.N(u)和F(u)每句训练语音在UBM上的Baum-Welch统计量:
(3)
(4)
其中,p(c|·)表示在UBM的第c个高斯上的后验概率;ut表示训练语音u的第t帧特征,共L帧;mc表示在UBM的第c个高斯上的均值向量.
换一种角度理解,TV方法是将每段语音当作独立的个体,认为每段都属于不同的语种,再根据各语音段与UBM均值超向量的差异性得到具有语种区分性的低维因子表示,也可以被认为是一种将语音信号特征映射到一个低维空间的概率主成分分析.
从以上的描述中,可以看出在估计全差异矩阵和提取i-vector的过程中,并没有用到语种类别信息,因此还需要对i-vector进行区分性训练,可以使用逻辑回归作为后端分类器,从而得到包含更多语种信息的i-vector.
1.2 基于端对端神经网络的语种识别系统
近年来,深度学习在语音信号处理领域中得到了快速的发展,基于端对端神经网络的语种识别系统也逐渐成为主流.它摒弃了传统的全差异空间建模的方法,在训练过程中将特征提取、变换以及后端分类器融于一个神经网络中,引入语种标号进行区分性训练.相比传统的TV系统,端对端网络有2个优势.1)运用了区分性的建模方法,在整个网络的训练过程中,企图寻找不同类别之间的最佳分类面,并没有侧重去拟合数据的分布.2)直接利用语种标签信息,不断优化网络参数,使得所提特征更具语种特性.而TV建模仅仅在后端分类器的训练过程中引入了语种标签信息.由于研究时间过短,端对端网络还有许多可改进的空间,是当前的研究热点之一.
本文实现了文献[20-21]提出的一种新的端对端语种识别系统,它结合了卷积神经网络(convolu-tional neural network, CNN)在帧级特征上强大的建模能力和时域平均池化层(temporal average pooling, TAP)将帧级特征转换到句级特征的池化能力.该系统被称为CNN-TAP,基本框架如图2所示.

Fig. 2 Structure of the CNN-TAP end-to-end LID system图2 CNN-TAP端到端语种识别系统框图
具体来说,CNN-TAP包含一个基于卷积层的前端特征提取器,设语音信号的声学特征为x1,x2,…,xT,共T帧.其中xT表示第T帧特征经过非线性变换映射后,得到的特征包含更多语种信息;接着利用池化层得到句级特征表示,经过TAP层后,不同长度的输入语音得到了固定维度的句级向量表示;最后得到类别后验概率p(ki|x1,x2,…,xT),ki表示第i个类别.
2 语种特征修复
本文所提出的语种特征补偿方法框架如图3所示.首先从语音信号分帧、变换得到底层声学特征;之后利用1.1节描述的基线系统提取原始i-vector;同时按照2.1节所提出的方法计算音素向量;将拼接后的i-vector和音素向量,送入基于DAE的语种特征补偿处理单元映射得到补偿后的i-vector,详见2.2节;最后将补偿后的i-vector和原始i-vector分别送入后端分类器得到分数向量,并将其在得分域融合.
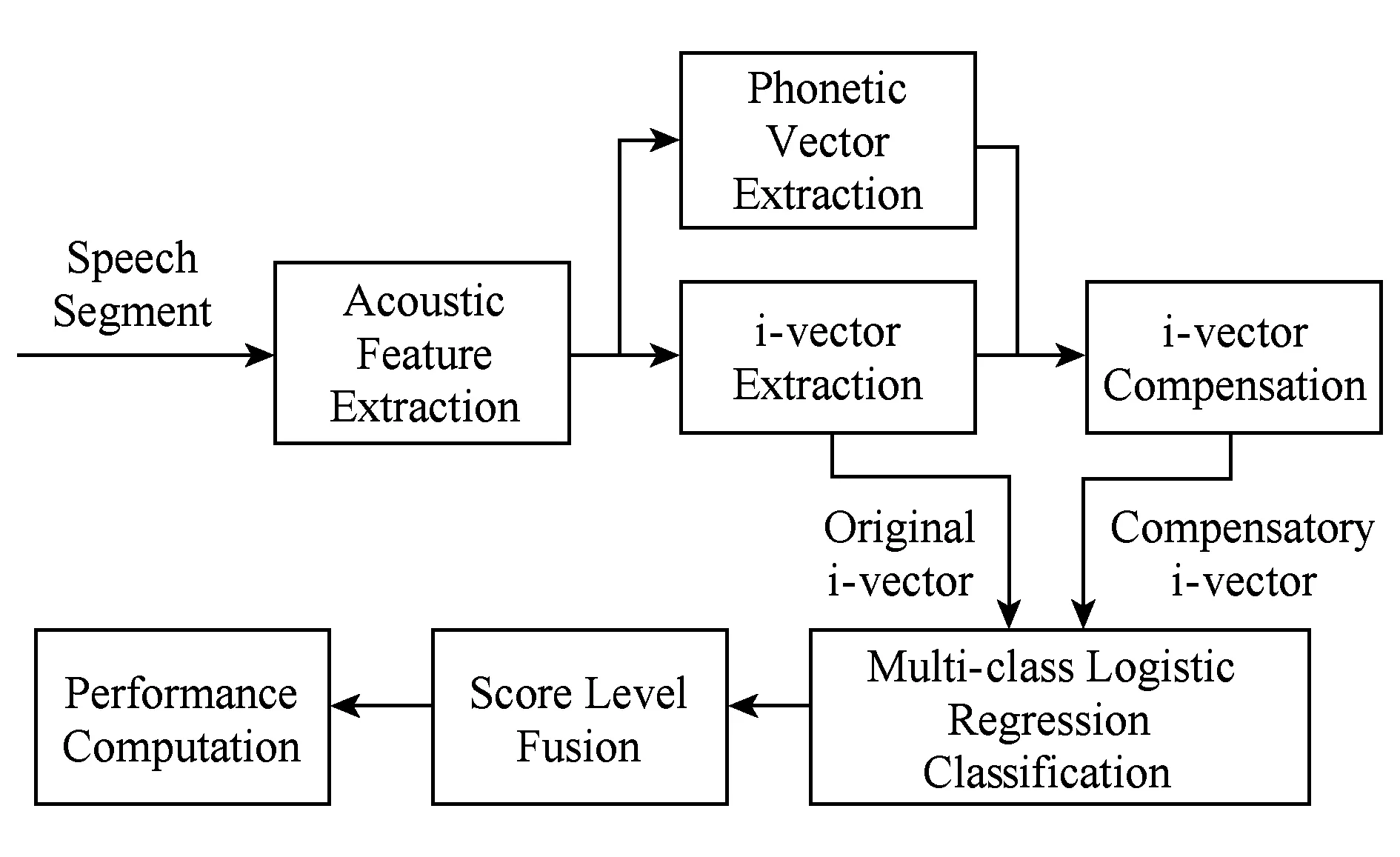
Fig. 3 Structure of DAE based i-vector feature compensation图3 基于DAE的i-vector补偿结构框图
2.1 音素向量
语言学研究表明:不同音素集、不同音素的组合及出现的频率表征了不同类别的语言[28].显而易见,音素信息在语种识别中有很重要的作用.本文尝试用较为简单的方法提取语音的音素信息作为辅助信息,增加不同语种之间的区分度.
音素信息的提取过程为:先利用高斯混合模型计算语音信号每帧的后验概率,再将一句话所有帧的后验概率求和取平均作为新的特征,这里称为音素向量,计算为
(5)
其中,pc(u)是训练语音u在UBM的第c个高斯上的后验概率;t表示帧数,共L帧.
2.2 基于降噪自动编码器的i-vector补偿方法
降噪自动编码器是自动编码器(auto-encoder, AE)的改良版,旨在用被破坏的输入数据重构出原始未被破坏的数据,从而提取、编码出具有鲁棒性的特征.在语音信号处理领域,DAE被用于加强语音信号,包括去噪、去混响等.
本文提出基于降噪自动编码器的i-vector补偿方法,结构框图如图4所示.DAE补偿网络的特征向量由语音的i-vectorw(u)和音素向量p(u)拼接组成.输入短时语音语种特征向量x1(u)=[w1(u),p1(u)],标签为长时语音语种特征向量xL(u)=[wL(u),pL(u)].隐层之间的前向传递过程为
xi+1(u)=g(W(i,i+1)xi(u)+b(i,i+1)),
(6)
其中,g()为非线性函数,W(i,i+1)和b(i,i+1)为前一隐层与后一隐层之间的权重参数和偏置参数,最后输出层为补偿语种特征xN(u)=[wN(u),pN(u)],称为补偿向量.wN(u)为补偿后的i-vector,pN(u)为补偿后的音素向量.
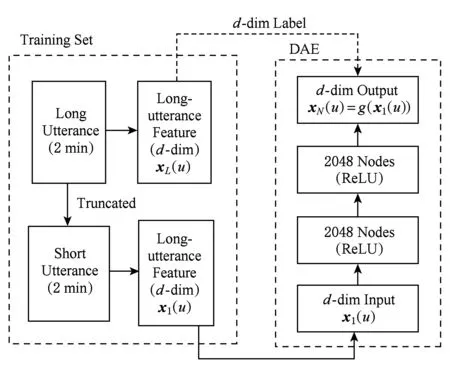
Fig. 4 The diagram for language feature compensation图4 语种特征补偿方法图示
该网络的训练是一种有监督的训练.主要思想是输入被干扰的向量,重构出原始输入.本文实验中输入的是短时语音语种特征,目标向量为长时语音语种特征.训练数据的准备分3个步骤:
1) 提取训练语音Si的i-vector和音素向量,拼接得到目标向量x(Si).训练语音的长度范围是0~2 min;
2) 将训练语音Si分别切成3 s,10 s和30 s,对每个语音段si,j提取i-vector和音素向量,拼接构成短时向量x(si,j);
3) 最终的训练数据对为(x(Si),x(si,j)).通过最小化目标函数对DAE网络进行参数优化.目标函数可以是目标向量和补偿向量之间的均方误差.
2.3 融合策略
每条语音经过语种特征补偿处理单元后得到2个i-vector:原始i-vector和补偿后的i-vector.为了充分利用这2个特征,本文在模型后端釆用2种融合策略:i-vector融合和得分融合.
i-vector融合方法是将语音信号的原始i-vector和补偿后的i-vector进行线性融合后,再送入后端分类器得到最终的判决结果:
wf(u)=(1-α)w(u)+αwcomp(u),0≤α≤1,
(7)
其中,w(u)是原始i-vector,wcomp(u)是它的补偿i-vector.
得分融合方法是直接在TV模型输出的得分上进行线性融合:
sf(u)=(1-α)s(w(u))+αs(wcomp(u)),0≤α≤1,
(8)
其中,s()为分数后端计算得分的函数.
3 语种特征补偿实验
3.1 实验设置
1) 测试集.从20世纪90年代起,美国国家标准技术研究院(National Institute of Standards and Technology, NIST)组织的语种识别评测比赛(language recognition evaluation, LRE),为语种识别的研究提供了统一的、公共的数据集.本实验采用美国国家标准技术局在2007年闭集条件下的语种识别评测数据集[34].这个测试集包含14个语种:阿拉伯语(Arabic, AR)、孟加拉语(Bengali, BE)、英语(English, EN)、波斯语(Farsi, FA)、俄语(Russian, RU)、德语(German, GE)、印地语(Hindustani, HI)、日语(Japanese, JA)、韩语(Korean, KO)、中文(Chinese, CH)、西班牙语(Spanish, SP)、泰米尔语(Tamil, TA)、泰国语(Thai, TH)和越南语(Vietnamese, VI).其中中文除了包含普通话,还有闽南语、吴方言和粤语.英语除了美国英语外,还包括印度英语.而印地语包括了北印度语和乌尔都语.NIST07的测试数据按照语音的时长分为30 s,10 s,3 s这3种,每种包括2 158条14个语种的语音.
2) 训练集.训练语料主要使用CallFriend数据库[35].该数据库包含12个语种:阿拉伯语、英语、波斯语、法语、德语、印地语、日语、韩语、普通话、西班牙语、泰米尔语和越南语.LRE2007的测试数据还有2个CallFriend 数据库不包含的语种、方言,因此,训练数据在CallFriend数据库的基础上还添加了LRE2003,LRE2005,LRE2007开发集.除此之外还包含2008年说话人识别评测比赛(speaker recognition evaluation, SRE)[36]的训练数据,为该测试提供补充训练数据:孟加拉语,俄语、泰国语、闽南语、吴方言、粤语、阿拉伯语和乌尔都语.训练集的数据分布严重不平衡,英语、中文占所有语料的57.06%.
语种识别的测试标准主要采用NIST-LRE07测试标准平均代价(average cost,C_avg)[34]和错误率(error rate, ER)来评价.另外本文在4.2节中还将提到虚警率、漏警率[34].这些指标从不同角度反映了语种识别系统性能的好坏,它们都是越小越好.C_avg的定义为
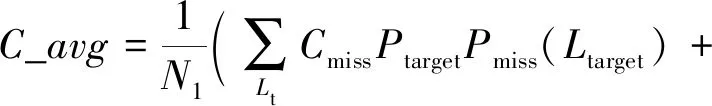
(9)
Pout-target=(1-Ptarget-Pout-of-set)(N1-1)
(10)
其中,Nl为集合中语种总数;Lt和Ln分别表示目标语种和非目标语种;Pmiss(Lt)表示目标语种为Lt时的漏检率;Pfa(Lt,Ln)是目标语种为Lt时的虚警率;Cmiss和Cfa分别是漏检和虚警的惩罚因子;Ptarget为目标语种的先验概率;Pnon-target为非目标语种的先验概率;Pout-of-set为集外语种的先验概率.本论文实验只考虑闭集测试的情况,因此Pout-of-set=0.NIST-LRE07设定Cmiss=Cfa=1,Ptarget=0.5.
本文采用2个基线系统:基线1是基于TV空间的i-vector系统,分为前端声学特征提取和后端统计建模2部分.前端底层声学特征采用基于PLP线性扩展的SDC特征,后端建模利用TV建模方法.TV建模中高斯混合数为512,i-vector维数为600,采用逻辑回归分类器.基线2是基于端对端深度神经网络的语种识别系统.与文献[20-21]相似,卷积神经网络采用深度残差网络resnet34,采用交叉熵(cross entropy)准则进行训练,采用随机梯度下降法(stochastic gradient descent, SGD)更新网络参数.Mini-batch大小设为128,每个Mini-batch的帧长范围为[200,1000].共60个epoch,学习率为0.1.
随机选择5 000条训练数据训练高斯混合数为32的UBM,提取32维的音素向量.基于降噪自动编码器的网络输入是632维向量,由600维i-vector和32维音素向量组成.网络共有4层,隐层节点数是2048,网络的结构是632-2048-2048-632.采用最小均方误差准则进行训练.经过对比2种融合策略,实验均采用得分融合策略,α=0.1.关于融合系数α的选取,将在4.2节实验结果中给出验证.
3.2 实验结果
为了验证本文所提算法的有效性,本节将描述多组实验.首先以音素向量作为唯一变量,验证音素向量补偿的效果.表1列出了i-vector直接通过DAE网络映射以及音素向量和i-vector拼接后映射,在不同时长测试语音下的评价指标ER和C_avg的变化趋势.表1中的Direct Mapping表示提取出的i-vector直接经过DAE网络映射.而Concatenate Mapping表示送入DAE网络的特征是音素向量和i-vector的拼接向量.2组实验的唯一变量是音素向量.DAE网络由3 s的短时语种特征和2 min的长时语种特征对训练得到.实验后端均采用逻辑回归分类器.映射后的i-vector和原始ivector按照0.1∶0.9在得分域融合.
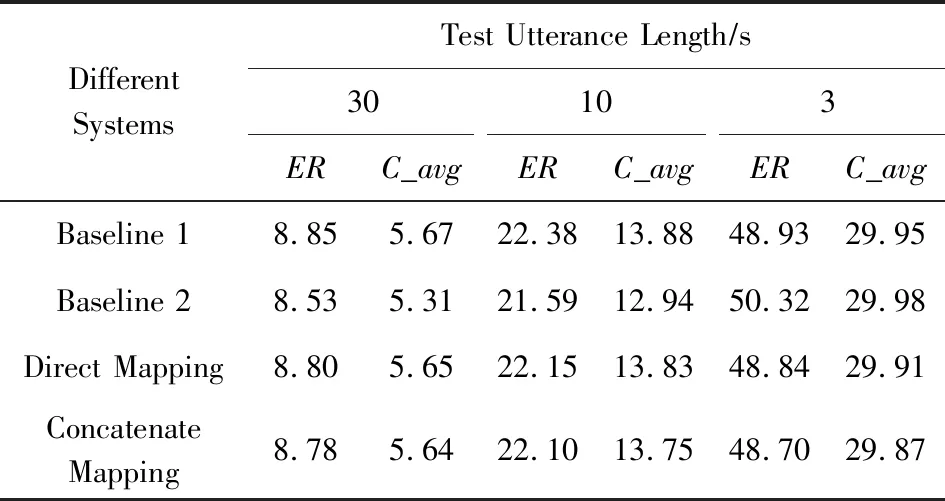
Table 1 The Results of Phonetic Vector Compensation 表1 音素向量补偿性能对比 %
从表1可以看出,相比基线1,i-vector直接映射后的识别性能在3种测试时长上均有提升,尤其是在测试语音时长为10 s和3 s的短时情况,因为本组实验的DAE网络训练数据由3 s和2 min语音对构成,短时测试语音与模型更匹配,性能提升更多.相比基线2,i-vector直接映射和拼接映射后识别性能在3 s的测试时长上也有所提升.音素向量和i-vector合并后,语种识别性能进一步得到改善,说明音素向量有一定的补偿效果.
下面验证补偿网络的有效性.针对不同的测试条件,在训练阶段,长时的训练语料被切割成时长分别为30 s,10 s和3 s的短时语音段,并组成3种时长的短时语音语种训练集合,分别学习对应的补偿网络.表2列出了针对不同测试时长的训练数据分别训练相应的补偿系统,在不同时长测试语音下的评价指标ER和C_avg的变化情况.表2中的30 s compensation表示补偿网络的训练数据是30 s和2 min的训练对.

Table 2 Performance Comparison on Baseline and Compensation System表2 基线系统和补偿系统性能对比 %
从表2可以看出,本文提出的补偿算法在各种测试时长上的识别性能都有提高.尤其是在测试语音时长和训练语音时长完全匹配的情况下,性能提升最大.相比基线1,测试语音时长为30 s,经过30 s补偿网络映射后,错误率相对降低了3.16%;测试语音时长为10 s的错误率经过10 s补偿网络映射后相对降低了2.90%;测试语音时长为3 s的错误率,经过3 s补偿网络映射后相较基线提升不大.这是因为使用3 s时长的短时训练样本由于语音段过短使其在提取i-vector时包含的语种相关信息非常容易受到影响,直接用于网络训练可能导致模型的估计不准确.相比基线2,补偿网络在测试语音时长为30 s和10 s的性能没有提升,但基本可以与基线持平;测试语音时长为3 s的错误率经过3 s补偿网络映射后相对降低了3.21%.总的来说,针对不同测试时长,利用时长互相匹配的训练数据分别训练相应的补偿系统能进一步提升补偿网络系统的性能.
Vincent等人[23]证明了DAE网络的可以对加噪数据进行降噪,得到更加鲁棒的不变性特征,获得输入的更有效表达.文献[22]提到一般情况下,高维的数据都处于一个较低维的流形曲面上,被干扰向量的分布稀疏,远离低维曲面.而DAE网络可以将稀疏的特征映射到更为紧实的低维曲面上.这与本文所描述的基于DAE的补偿网络的主要思想是一致的,短时特征可以被当做是长时特征经过噪声干扰后的数据.补偿网络得输入是短时语音的i-vector,通过学习隐含特征,可以有效重构出长时语音的i-vector.
图5显示出30 s,10 s,3 s测试时长的C_avg随补偿i-vector权重α变化的情况,不同测试时长语音分别经过对应时长的补偿网络,采用式(8)的得分融合策略.
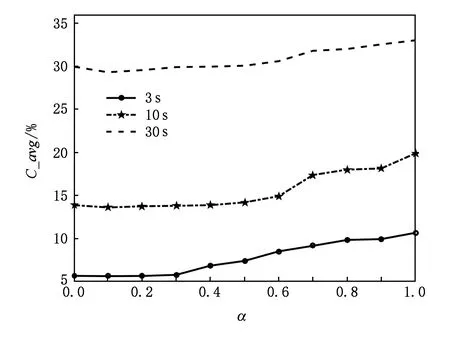
Fig. 5 The variation of C_avg with respect to score fusion coefficient图5 C_avg随得分融合系数变化图
从图5中可以看出,α取0.1~0.2时融合系统的性能稍好于基线1,α=0.1时在3种测试时长下性能最优.这说明基于DAE的补偿网络提供了额外的语言信息,与原始i-vector语言信息互补.
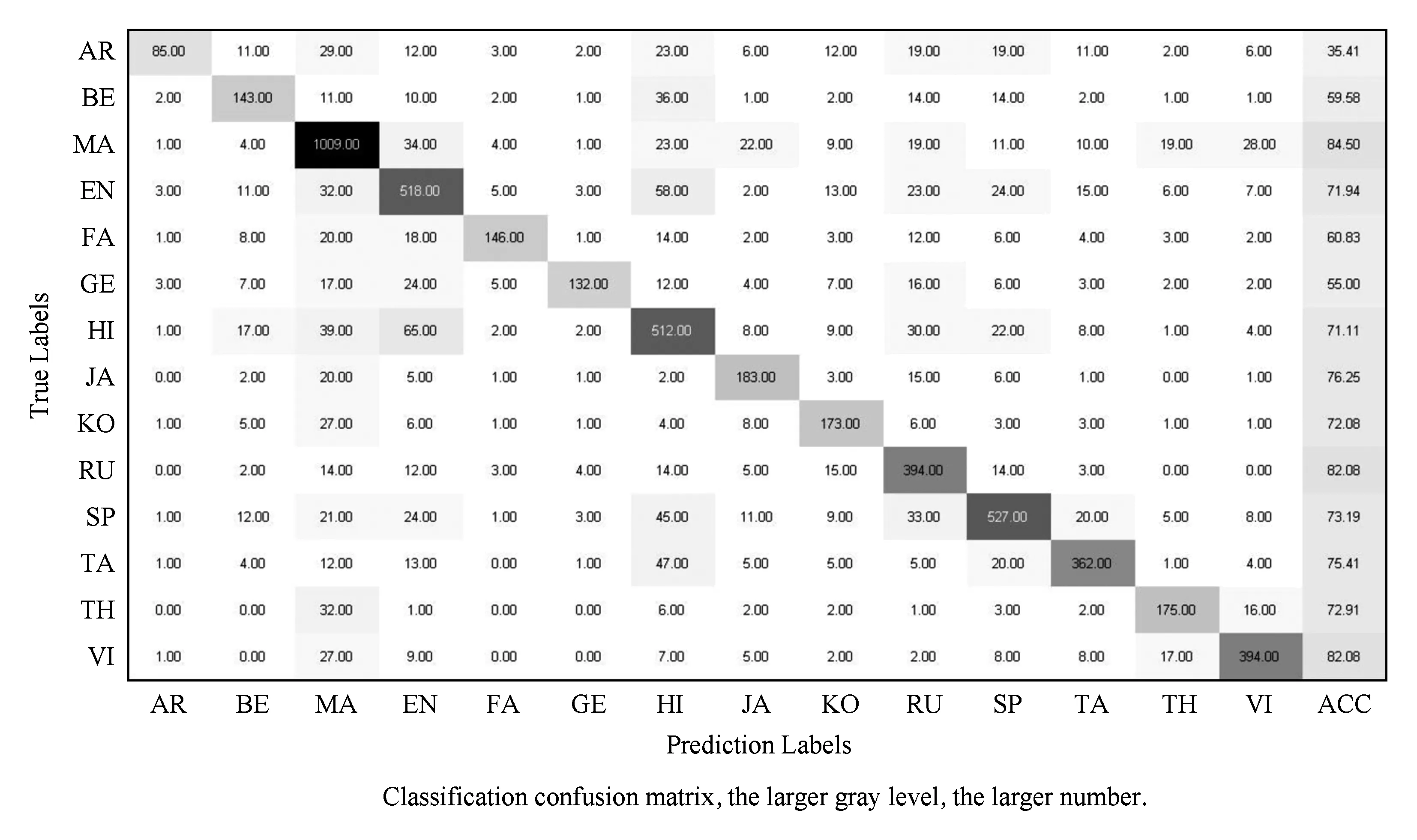
Fig. 6 Classification confusion matrix图6 分类混淆矩阵
混淆矩阵可以很直观地反映出各语种的虚警率、漏警率以及各语种间的混淆程度.本文统计了测试语音在3 s补偿系统上的得分所构成的混淆矩阵.如图6所示,纵轴代表真实类别,横轴代表预测类别.ACC代表该语种识别精度.从图6可以看出,各语种大部分样本都能保证分类正确,彼此间不存在较大的干扰.但是某些类别之间混淆程度较大导致系统的虚警率和漏警率升高.3.1节中提到训练数据分布不均衡,其中MA所占比例最大,它们的识别精度分别为71.94%,84.50%,虚警率为31.02%和22.97%.这是因为这部分语料比重大,在训练阶段系统会侧重优化这些语种的模型,使得最终模型的预测结果有偏差.还有一些语种即使训练语料所占比例不大,却仍存在很高的虚警率,这说明简单的依赖底层声学特征是无法准确地给出易混语种的判别结果.从分析结果可以看出本文提出的模型虽然较基线系统有一定的性能提升,但还存在很大的提升空间.
4 总 结
语种识别系统在训练语音和测试语音长度不匹配时,性能会出现大幅下滑,严重制约语种识别技术在实际中的应用.本文提出基于降噪自动编码器的语种特征补偿方法来解决这个问题.在NIST-LRE07上的实验结果表明,所提出的语种特征补偿算法在30 s,10 s和3 s这3种测试条件下均可以获得不同程度的性能提升.对实验细节的进一步分析表明:目前音素向量提取过程较为简单,并没有充分挖掘出语音的音素分布信息,未能起到较大作用,后期仍有进一步改良的空间.
