基于Bi-IndRNN的恶意URL分析与检测∗
2019-05-13王欢欢田生伟禹龙彭咏芳裴新军
王欢欢,田生伟∗†,禹龙,彭咏芳,裴新军
(1.新疆大学软件学院,新疆乌鲁木齐830008;2.新疆大学网络中心,新疆乌鲁木齐830046;3.新疆大学信息科学与工程学院,新疆乌鲁木齐830046)
0 引言
随着互联网技术的不断发展,网络已经渗透了人们的生活,网页链接更是与日俱增,恶意URL的检测变的越来越重要且更加困难.在经济利益的驱使下,恶意URL 发展快速且变化多种多样,对于个人的隐私和财产安全已经构成了严重威胁.近年来,利用网络恶意盗取个人信息和财产的案件频发,因此加强反恶意URL研究对于网络的健康发展已刻不容缓.如何有效的检测恶意URL已成为一个重要的研究课题,而以往的研究主要是基于传统的算法模型,发展进展受限,发展空间较小[1,2].深度学习的兴起带来了新的发展机遇,不仅影响着传统算法模型的学习,而且广泛应用于自然语言处理、语音识别、图像处理等方面,同时也应用于网页检测的领域中.在深度模型中,IndRNN可以很好地处理步较长的序列.利用IndRNN可以保留长期记忆、处理长序列,IndRNN还可以很好地利用relu等非饱和函数作为激活函数,并且训练之后非常鲁棒.通过调节基于时间的梯度反向传播,可以有效地解决梯度消失和爆炸问题.而双向IndRNN基本思想是分别向前和向后呈现每个序列到两个单独的隐藏状态以捕获过去和未来的信息.然后将两个隐藏状态连接起来形成最终输出,从而提供更全面的信息,多方位进行训练、检测网页URL.本文在现有的研究成果之上,进行了基于Bi-IndRNN算法的恶意URL分析与检测的研究.通过提取主机信息特征和URL信息特征,进行特征融合之后,用来训练Bi-IndRNN算法模型.
1 国内外研究现状
针对恶意URL识别问题,国内外的研究人员提出多种识别技术和解决方案.其中国外的Justin Ma[3]等人使用统计学方法来发现恶意web站点URL的基于词汇和主机的属性、基于自动化的分类,提高了准确率,但是此方法无法处理数百万个功能随时间而变化的URL.Daiki Chiba[4]等人开发并评估了基于机器学习技术的轻量级和扩展的检测方案.研究的目的不是提供有效检测基于Web的恶意软件的单一解决方案,而是开发一种补偿现有方法缺点的技术.Daiki Chiba[5]等人利用了IP地址比其他指标更加稳定的特性,通过分析IP地址功能,提出了基于字节的提取、基于扩展字节的提取和基于位串的提取这三种从IP地址提取特征向量的方法,选择用SVM证明有效性,但是由于良性网页位于恶意网页使用相同网络托管服务上,因此此方法会把良性网页检测为恶意网页.Ismahani Ismai[6]等人提出了一种新的Snort恶意软件特征检测方法,将其纳入朴素贝叶斯模型训练中,采用IP地址分段、地位判定的分类方法,证明了所提出的工作在分组层次上导致低特征搜索空间进行有效检测,以无状态级别检测恶意网页与状态级别类似的准确性是可行的,但是此方法仍处于探索阶段,因此测试并不是实时进行.FEROZ[7]等人构建了一个可靠的URL分类框架,提取和使用16个手动选择的词法和基于主机的功能,分类器的弹性也通过使用随机采样来验证.MOlalere[8]等人提供了一个实时系统Monarch,它可以在URL提交到Web服务时对其进行爬虫,并确定这些URL是否指向垃圾邮件,证明Monarch可以提供准确的实时保护,但是垃圾邮件的底层特性并不能在Web服务中推广.目前国内的沙泓州[9,10]等人提出了一种自学习的轻量级网页分类方法SLW.SLW首次引入了访问关系的概念,使其具有反馈和自学习的特点.SLW从已有的恶意网页集合出发自动发现可信度低的用户和对应的访问关系,从而进一步利用低可信度用户对其他网页的访问关系来发现未知的恶意网址集合.林海伦[11]等人提出了一种通过建立3-gram为词项的倒排索引快速计算恶意URL的段模式,该方法通过基于Jaccard的随机域名识别技术来判定随机域名产生的恶意URL.然而,此方法只通过简单的Jaccard指数检测包含随机域名的恶意URL的方式还不够完善.刘燕兵[12]等人设计了一种适合于大规模URL过滤模型的多模型匹配算法,该算法在经典的SOG算法基础上,针对URL规则的特点,提出了最优窗口选择和模式串分组规约这两种优化技术.然而,URL等真实模式串并不满足经典串匹配算法,设计主要基于“模式串和文本字符服从均匀分布”的假设,并且主要在随机数据集上进行评测的条件.周浩[13]等人利用决策树的方法对大量的恶意网页与正常网页进行深入分析,除了考虑网页自身特征之外,选取了多种新的特征来检测恶意网页,包括Google PageRank值[14]及搜索结果数[15]、Alexa流量信息[16]、域名信息[17]、WOT声誉值等.王秋实[18]等人利用基于客户端蜜罐的动态分析方法实现了利用API HOOK以及Sandbox技术的挂马网页验证系统和利用BHO技术的HTTP木马网络追踪系统.传统的恶意URL检测大多基于黑名单[19,20]、信誉系统[21]、主机[22,23]、词汇、蜜罐技术[24]及入侵检测技术[25],本文提出一种基于Bi-IndRNN的恶意URL检测算法.
本文的主要贡献如下:
1.本文提取了主机信息特征,并且筛选出URL信息特征.随后,将筛选后的URL信息特征和主机信息特征进行有效的特征融合,并且使用Bi-IndRNN模型进行检测.
2.将Bi-IndRNN算法用于恶意URL分析与检测,利用分类算法对提取的特征进行训练,筛选出有效特征.通过特征融合,并构造出恶意URL的分类器.使用构造好的分类器对恶意URL进行检测、分类,提升了恶意URL检测的自动化程度和准确率.
2 算法模型
2.1 特征分析
提取的特征直接影响了恶意URL检测的准确度和精度,因此特征起着至关重要的作用.本文在提取主机信息特征的基础上又提取了URL信息特征.
2.1.1 主机信息特征
基于主机的功能从URL的主机名属性中获得,这可让我们知道恶意主机的位置、身份以及这些主机的管理风格和属性.本文提取的主机信息特征包括百度权重、百度收录量、360权重、360收录量、搜狗权重、搜狗收录量、ALEXA排名、建站时间、网页IP、360快照日期、搜狗快照日期、导出链接等共20种.表1列举了20个可提取的特征.

表1 主机信息特征Tab 1 Host Information Features

表2 URL信息特征Tab 2 URL Information Features
2.1.2 URL信息特征
因为直接使用原始URL名称在机器学习的角度来说是不可行的,所以必须处理URL字符串以提取有用的功能.本文提取的URL的特征即基于URL文本的属性,表2列举了21个可提取的特征.
2.2 特征融合

表3 特征融合Tab 3 Feature Fusion
为确保恶意URL的分析及网页URL检测准确率的提高,融合主机信息特征、URL信息特征[26−28],伪代码如表3所示.通过融合上述特征之后,训练Bi-IndRNN算法模型得出恶意URL分类的准确率,总体框架如图1所示.

图1 总体框架示意图Fig 1 Overall Schematic
2.3 双向IndRNN
IndRNN可以很好地处理步较长的序列.利用IndRNN可以保留长期记忆、处理长序列,IndRNN还可以很好地利用relu等非饱和函数作为激活函数,并且训练之后非常鲁棒.通过调节基于时间的梯度反向传播,可以有效地解决梯度消失和爆炸问题.其公式为:

其中循环权重u是一个向量,· 表示阿达马积.同一图层中的每个神经元都与其他神经元不相连,通过叠加两层或更多层的IndRNN,可以将神经元连接.对于第n个神经元,隐藏层hn,t可以通过以下公式得到:

其中Wn和un分别表示第n行的输入权重和当前权重.
基本的IndRNN结构示意图如图2所示:
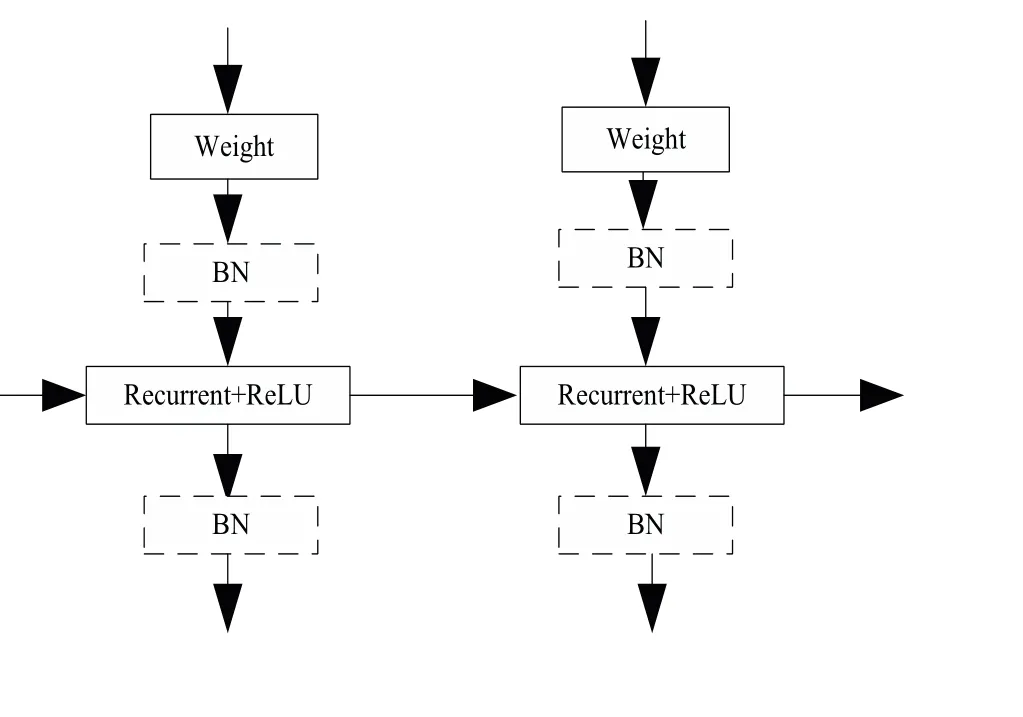
图2 IndRNN结构示意图Fig 2 Schematic Diagram of IndRNN Structure
其中“weight”和“Recurrent+ReLU”表示每一步处理输入的循环过程,ReLU是激活函数.
双向IndRNN基本思想是分别向前和向后呈现每个序列到两个单独的隐藏状态以捕获过去和未来的信息.其中使用前向IndRNN(IndRNNForward,简称IndRNNF)和后向IndRNN(IndRNNBackward,简称IndRNNB),分别从前至后和从后至前的运行以挖掘更加全面的信息,然后将两个隐藏状态连接起来形成最终输出,从而提供更全面的信息.BiIndRNN公式(3)、(4)、(5)如下所示.


其中,Ft表示IndRNNF之后的输出值,表示IndRNNB之后的输出值,Lt表示两个隐藏状态连接起来的最终输出,M1,Mn−1,Mn,Mn+1…等表示特征输入,使用MLP进行特征融合,本文双向独立循环神经网络如图3所示.
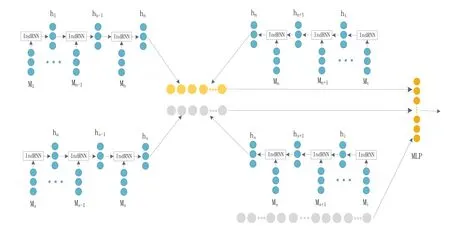
图3 双向IndRNN结构示意图Fig 3 Schematic Diagram of Bi_ZndRNN Structure
3 实验与分析
3.1 实验数据
本文中,实验数据来源于公开数据集PhishTank和爬虫抓取网页URL集合.在PhishTank获取总计13 652条钓鱼网页URL集合,使用领域知识和相关专业知识,爬虫抓取了10 000条合法网页URL集合.
3.2 实验环境

表4 实验环境Tab 4 Experimental Environment
3.3 最优参数的设置
模型参数的设置对于恶意URL检测的效果起着至关重要的作用,本文在大量的实验基础上得到最优参数的设置,如下表5所示.

表5 最优参数的设置Tab 5 Optical Parameters Setting
3.4 实验结果与分析
本节将从URL信息特征对于实验结果的影响、与最近几年其他人的研究方法进行对比、与其它模型的实验结果进行对比来进行本文的实验结果分析.
3.4.1 URL信息特征对于实验结果的影响
此节进行了不同数据量分别添加或删除URL信息特征的方式进行实验,以得到的恶意URL分类的准确度来说明URL信息特征的重要性.
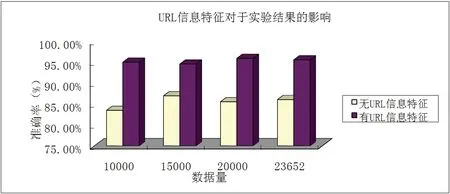
图4 URL 信息特征对于实验结果的影响Fig 4 Effects of URL Information Features On Experimental Results
图中可以看出,当无URL信息特征时,实验中得到的最高准确率为86.96%.而添加URL信息特征之后,实验中得到的最高准确率为95.92%,且不同的数据量都具有更高的准确率,所以URL信息特征对于恶意URL分类的准确度有着至关重要的影响.
3.4.2 方法对比
本节将与近年来使用PhishTank数据集的其他研究进行比较.在相同的数据集下,观察提取的特征的差异,然后分析其他研究的方法,并与本文的恶意URL检测效果进行比较.结果如表6所示.

表6 方法对比Tab 6 Comparison with Methods
Liu G等人[29]提取了关键字、排名和超链接功能.并使用DBSCAN聚类方法查明是否存在对给定网页攻击的网页群集的可能攻击,准确率为91.44%.Fatt等人[30]提出了一种基于网站图标的方法来揭示网站的隐藏身份.根据词汇功能、基于主机的功能和超链接功能用于研究URL,准确度高达97.4%.Dewan等人[31]提出了一个基于实体配置、文本内容、元数据和URL功能的广泛功能集,以实时和零小时识别Facebook上的恶意内容,准确率为86.9%.Jain等人[32]通过自动更新合法站点的白名单来保护用户免受网络钓鱼攻击,该方法的准确率达到86.02%.Jain等人[33]提出了一种基于统一资源定位器(URL)功能的基于机器学习的反钓鱼系统来检测恶意网页,准确率达到91.28%.与上述方法相比,本文提出的基于主机信息特征和URL信息特征的恶意URL检测的准确性得到了提高,本文的准确率达到95.92%.
3.4.3 不同的机器学习模型的实验结果
为验证本文提出的Bi-IndRNN更适用于恶意URL的检测,本节同浅层机器学习模型KNN、高斯贝叶斯、深度学习模型LSTM、IndRNN进行对比,其分类准确率对比如表7所示.

表7 同其它模型对比Tab 7 Comparison with Other Models
根据上述多组实验的可以看出:在同样的特征、实验环境、参数情况下,在不同的数据量时,KNN算法最高的准确率为83.32%,高斯贝叶斯最高的准确率为91.92%,LSTM 算法最高的准确率为94.9%,IndRNN算法最高的准确率为94.56%,而Bi-IndRNN算法最高的准确率为95.96%,且不管处于数据量多大的情况下,Bi-IndRNN算法模型的实验结果均比KNN算法、高斯贝叶斯算法、LSTM算法、IndRNN算法在恶意URL检测准确度和精度方面高,而且有极大的提升.由此,可以看出Bi-IndRNN算法模型能够极大的提高恶意URL检测准确度,从而说明了其有效性.
4 结语
与以往研究的不同点是本文在融合了恶意URL的主机信息特征和URL信息特征的基础之上,应用Bi-IndRNN 算法模型进行检测.并且我们在同样的实验环境、同样的参数下,分别进行特征对比、与其它研究方法进行对比、与不同的机器学习算法模型进行对比,可以看出本文使用的Bi-IndRNN算法明显提高了恶意URL检测的准确率.
