浅析人工神经网络及其应用模型
2019-05-10李牧樵
李牧樵
摘 要 人工神经网络是人类对计算工具研究领域取得的重要成果,它以模糊处理与形象思维作为研究方向,以神经元模型为基础,配合算法,通过不断的数字化运算,从而让计算机软件具有人脑的信息处理能力,从而完成复杂的非线性任务。文章主要介绍了人工神经网络的概念、特点,神经网络的数学模型,并且分析了人工神经网络发展过程中的几种神经网络及特点,最后对人工神经网络的发展提出了建议。
关键词 人工神经网络;神经元模型;感知器;深度学习
中图分类号 G2 文獻标识码 A 文章编号 1674-6708(2019)233-0137-2
现代电子计算机作为信息处理工具,借助高速数值运算和精确的逻辑运算能力,极大地拓展了人脑的能力,在信息处理和控制决策等各方面为人们提供了实现智能化和自动化的先进手段。然而,半个世纪以来,基于冯氏原理的现代计算机,受限于传统逻辑运算规则,在学习认知、记忆联想、推理判断、综合决策等方面的信息处理能力远不能达到人脑的智能水平[ 1 ]。
近10多年来,基于大数据、深度学习及算力的提高,人工神经网络终于以不容忽视的潜力与活力进入了快速发展的新时期,其运行机制渐趋成熟,应用领域日益扩大,显示了巨大潜力,神经网络及其相关模型赋予了传统计算机新的生命力。
1 人工神经网络概述
1.1 概念
人工神经网络是近几十年来人工智能领域内的伟大发现,其以模仿人脑的神经网络处理问题的行为特征,采用广泛互联的神经元结构,以一定的规则进行学习,并根据学习结果进行推理判断,从而达到处理信息的目的。网络中的神经元个数越多,记忆、识别的模式也就越多。它是对人脑的模拟、延伸和扩展,是人工智能学科的重要分支。
1.2 特点
人工神经网络由大量神经元广泛互连,神经元集信息存储、处理为一体,具有空间上分布存放,时间上并行处理的特点。分布式存储使得网络具有良好的容错性,当网络中部分神经元损坏或输入模糊、残缺、变形信息时,信息仍可存取,重建、联想记忆,给出次优逼近解,类似人脑回忆时的从部分信息恢复全部信息的能力。虽然每个处理单元功能简单,但神经元的并行处理使得网络具有较快的速度并呈现出丰富的功能。神经网络具有自学习和自适应的能力。当环境变化时,经过一段时间的训练或感知,神经网络能自动调整网络结构参数,掌握其中的潜在规律,并推算输出结果[2]。
1.3 神经网络的数学模型
神经元是神经网络的基本器件,又称为“节点”。它是对生物神经元的信息处理过程进行抽象,并用数学语言予以描述。目前神经元模型是由线性元件及阈值元件组成,是大多数神经网络模型的基础。工作原理可参看图1所示。
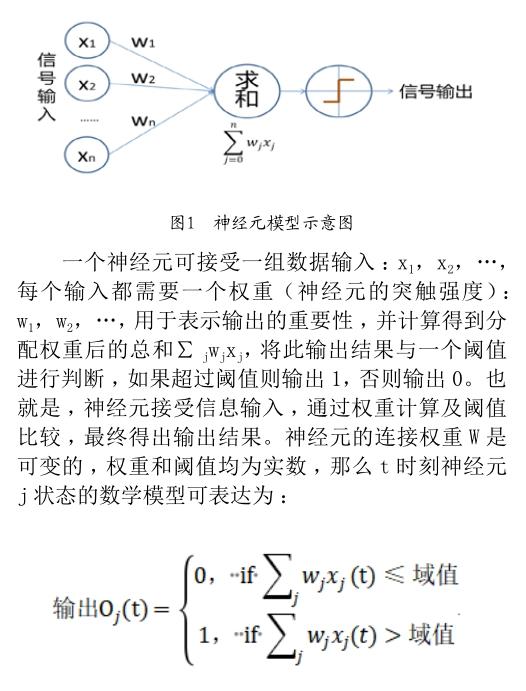
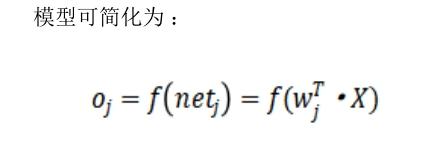
神经元的信息处理特征不同,采用的变换函数也就不同,常用的变换函数有:阈值变换、非线性变换、分段线性变换和概率型变换函数。将大量神经元按一定规则连接在一起,并且各神经元的连接权可按一定规则变化,这就构成了人工神经网络模型。按照网络拓扑结构,人工神经网络模型可分为层次型结构和互连型结构。根据内部信息的传递方向,人工神经网络模型可分为即前馈型网络和反馈型网络。实际应用的神经网络可能同时兼有其中一种或几种形式。
1.4 神经网络学习
不论是任何复杂的任务,神经网络对问题的解算需要不断对大量样本进行学习训练,从而改变网络的连接权值,使得网络的输出不断地接近期望的输出结果,改变权值的具体规则也被称为学习算法。神经网络的学习算法主要分为两类:监督学习和无监督学习。
监督学习也称有导师学习,其训练方法为:采用纠错规则,将实际输出与参照信息(教师信号)进行比较,不相符合时,则根据差错的方向和大小调整权值,以使下一步的输出结果更接近期望值。经过学习训练,当网络对于各种给定的输入均能产生期望的输出时,可认为网络已在导师的训练下“学会”了训练集中的知识和规则。而相反的是,无监督学习需要神经网络自身设计类别并完成归类,例如,给出一堆由两种水果组成的“水果堆”,但是不知道是哪两种水果,神经网络需要自己完成分类任务。
2 典型神经网络
2.1 感知器及其衍生神经网络
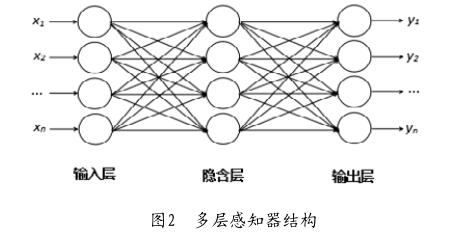
感知器是众多神经网络中最简单的一种神经网络,其也是组成复杂神经网络的基本单元。感知器神经网络模型基于MP模型结构,采用监督学习来逐步增加模式划分功能,达到学习目的,是研究其他网络的基础。感知器能做简单的线性分类任务,无法解决XOR(异或)类的分类任务。于是,出现了多层感知器,在输入与输出层之间增加隐层(一层或多层神经元),构成多层前馈网络,如图2所示。
多层感知器模型利用足够多隐层表达更为复杂的非线性函数,以实现任何模式分类,也包括异或问题。不过,多层感知器模型没有合理解决如何确定权值(学习算法),这一度阻碍了神经网络的发展,直到反向传播(BP)算法出现并应用于多层感知器的训练。
BP算法的基本原理是误差的反向传播,通过输入信息求出输出结果,上层(输入)神经元的状态影响下层(输出)神经元状态。当输出层得不到希望的输出时,则转入反向传播。反向传播用于从下层(输出)向上层(输入)逐层向后传递误差,逐一修正神经元间的连接权值误差。当参数适当时,此网络的实际输出能够以较小的均方误差收敛到期望输出。
BP算法解决了非线性的分类问题,是训练前向多层网络的较好算法。不过,BP算法存在梯度消失问题,即模型训练超过一定迭代次数后容易产生过拟合,使得训练集和测试集数据分布不一致,无法有效学习。这之后出现了不少改进算法,比如增加动量项、自适应调节学习率,引入陡度因子等。
在神经网络的发展过程中,还出现了不少神经网络,如自组织特征映射网络SOM、径向基函数RBF神经网络、Hopfield神经网络等,它们是神经网络发展史的一个个缩影[ 3 ]。
2.2 深度神經网络
大数据时代的到来以及算力的提高,掀起了深度学习浪潮。深度学习能发现大数据中的复杂结构,也因此大幅度提升了神经网络的效果。
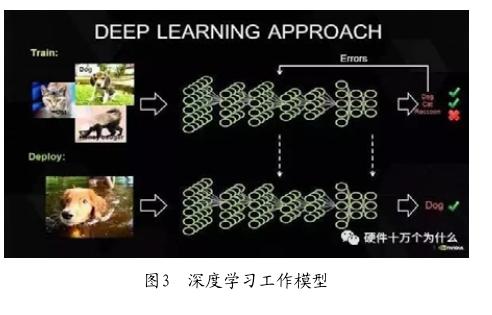
深度神经网络包含多个隐层,每层都可以采用监督学习或非监督学习进行非线性变换,实现对上层的特征抽象。深度神经网络利用逐层特征组合,配合海量的训练数据,来学习更有用的特征,从而提升分类或预测的准确性,即:大量训练数据+特征学习→数据推断。它的工作原理如图3所示。
深度学习一定程度上改善了以往传统BP神经网络在训练中所表现出来的目标函数优化的局部极小、不能收敛到稳定状态等问题,可以忽略局部极值问题对于深层网络的影响。典型的深度学习算法主要包括深信网、深度玻耳兹曼机、栈式自动编码器和卷积神经网络。目前,深度学习兴趣点主要是数据标注的监督学习,而无监督学习和深度学习模型的小数据泛化能力将是今后关注方向。语音、图像和自然语言处理是深度学习应用最广泛的3个领域。
3 结论
目前,在许多任务上,人工神经网络都取得了匹敌甚至超越人类的成果,但也还存在不少亟待攻克的问题。首先,深度学习的训练过程需要大量数据,而人工标注的成本较高,可考虑加强从未标注数据的学习,或者自动生成数据进行训练,如GANs就是一种数据生成模型。其次,基于深度学习的神经网络模型结构相对复杂,数据的训练时间较长,需要消耗的资源巨大,特别在移动设备上无法取得较好的效果,可考虑:
1)直接压缩或设计更精巧的模型,从而简化模型结构;
2)提升算法效率,提高计算质量;
3)提高搭载网络的硬件计算力,缩短处理时间;
4)发挥云计算,使得在小模型上也能跑出大模型的效果;
5)可基于训练和推理的不同特性,实现网络各部分结构化、集成化,提高网络调整的灵活性,便于网络功能扩展[ 4 ]。另外,还可以拓展应用领域,向通用型智能发展。
参考文献
[1]焦李成,杨淑媛,刘芳,等.神经网络七十年:回顾与展望[J].计算机学报,2016,39(8):1697-1716.
[2]韩力群,施彦.人工神经网络理论及应用[M].北京:机械工业出版社,2017:142-148.
[3]王广.人工神经网络发展现状综述[J].中小企业管理与科技,2017(2):165-167.
[4]李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].计算机应用,2016,36(9):2508-2515.
